
https://www.youtube.com/watch?v=4UHYE1TSQP8
In diesem Projekt -Walkthrough werden wir untersuchen, wie Datenvisualisierungstechniken verwendet werden, um Verkehrsmuster auf der Interstate 94 aufzudecken, einer der am stärksten amerikanischen amerikanischen Autobahnen. Durch die Analyse realer Verkehrsvolumendaten zusammen mit Wetterbedingungen und zeitbasierten Faktoren identifizieren wir wichtige Indikatoren für starken Verkehr, die den Pendlern helfen könnten, ihre Reisezeiten effektiver zu planen.
Verkehrsstaus ist eine tägliche Herausforderung für Millionen von Pendlern. Das Verständnis, wann und warum starker Verkehr eintritt, kann den Fahrern helfen, fundierte Entscheidungen über ihre Reisezeiten zu treffen und Stadtplaner zu helfen, den Verkehrsfluss zu optimieren. Durch diese praktische Analyse werden wir überraschende Muster entdecken, die über die offensichtlichen Erwartungen von Rush-Stunde hinausgehen.
In diesem Tutorial werden wir mehrere Visualisierungen erstellen, die eine umfassende Geschichte über Verkehrsmuster erzählen und zeigen, wie die Erkundungsdatenvisualisierung Erkenntnisse ergeben kann, die nur zusammenfassende Statistiken vermissen könnten.
Was du lernen wirst
Am Ende dieses Tutorials werden Sie wissen, wie man:
- Erstellen und interpretieren Sie Histogramme, um Verkehrsvolumenverteilungen zu verstehen
- Verwenden Sie Zeitreihen -Visualisierungen, um tägliche, wöchentliche und monatliche Muster zu identifizieren
- Bauen Sie Facet-by-Facet-Diagramme für effektive Vergleiche auf
- Analysieren Sie Korrelationen zwischen Wetterbedingungen und Verkehrsvolumen
- Anwenden Sie Gruppierungs- und Aggregationstechniken für die zeitbasierte Analyse an
- Kombinieren Sie mehrere Visualisierungstypen, um eine vollständige Datengeschichte zu erzählen
Bevor Sie beginnen: Vorabstrukturierung
Folgen Sie diese vorbereitenden Schritte, um das Beste aus diesem Projekt zu machen:
-
Überprüfen Sie das Projekt
Greifen Sie auf das Projekt zu und machen Sie sich mit den Zielen und Struktur vertraut: Projekt mit starkem Verkehrsindikatoren finden.
-
Greifen Sie auf das Lösungsnotizbuch zu
Sie können es hier anzeigen und herunterladen, um zu sehen, was wir behandeln werden: Lösungsnotizbuch
-
Bereiten Sie Ihre Umgebung vor
- Wenn Sie die DataQuest -Plattform verwenden, ist für Sie bereits alles eingerichtet
- Wenn Sie vor Ort arbeiten, stellen Sie sicher, dass Sie Python mit Pandas, Matplotlib und Seeborn installiert haben
- Laden Sie den Datensatz von der herunter UCI -Repository für maschinelles Lernen
-
Voraussetzungen
Neu im Markdown? Wir empfehlen, die Grundlagen zu lernen, um Header zu formatieren und Ihrem Jupyter -Notizbuch Kontext hinzuzufügen: Markdown -Handbuch.
Einrichten Ihrer Umgebung
Beginnen wir mit dem Importieren der erforderlichen Bibliotheken und dem Laden unseres Datensatzes:
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inlineDer %matplotlib inline Befehl ist Jupyter Magic, die sicherstellt, dass unsere Handlungen direkt im Notizbuch rendern. Dies ist für einen interaktiven Workflow für die Datenerforschung von entscheidender Bedeutung.
visitors = pd.read_csv('Metro_Interstate_Traffic_Volume.csv')
visitors.head() vacation temp rain_1h snow_1h clouds_all weather_main
0 NaN 288.28 0.0 0.0 40 Clouds
1 NaN 289.36 0.0 0.0 75 Clouds
2 NaN 289.58 0.0 0.0 90 Clouds
3 NaN 290.13 0.0 0.0 90 Clouds
4 NaN 291.14 0.0 0.0 75 Clouds
weather_description date_time traffic_volume
0 scattered clouds 2012-10-02 09:00:00 5545
1 damaged clouds 2012-10-02 10:00:00 4516
2 overcast clouds 2012-10-02 11:00:00 4767
3 overcast clouds 2012-10-02 12:00:00 5026
4 damaged clouds 2012-10-02 13:00:00 4918Unser Datensatz enthält stündliche Verkehrsvolumenmessungen von einer Station zwischen Minneapolis und St. Paul auf der I-94 in Westen sowie die Wetterbedingungen für jede Stunde. Zu den Schlüsselspalten gehören:
- Urlaub: Identify des Urlaubs (falls zutreffend)
- Temperatur: Temperatur in Kelvin
- Rain_1h: Niederschlag in MM für eine Stunde
- Snow_1h: Schneefall in MM für eine Stunde
- clouds_all: Prozentsatz der Wolkendecke
- Weather_main: Allgemeine Wetterkategorie
- Weather_Description: Detaillierte Wetterbeschreibung
- Datum_Time: Zeitstempel der Messung
- transport_volume: Anzahl der Fahrzeuge (unsere Zielvariable)
Lernersicht: Beachten Sie, dass die Temperaturen in Kelvin (ca. 288K = 15 ° C = 59 ° F) liegen. Dies ist für den täglichen Gebrauch ungewöhnlich, aber in wissenschaftlichen Datensätzen häufig. Wenn Sie den Stakeholdern die Ergebnisse vorlegen, sollten Sie diese in Fahrenheit oder Celsius für eine bessere Interpretierbarkeit konvertieren.
Erstdatenexploration
Bevor Sie sich in Visualisierungen eintauchen, verstehen wir unsere Datensatzstruktur:
visitors.information()<class 'pandas.core.body.DataFrame'>
RangeIndex: 48204 entries, 0 to 48203
Information columns (complete 9 columns):
# Column Non-Null Depend Dtype
--- ------ -------------- -----
0 vacation 61 non-null object
1 temp 48204 non-null float64
2 rain_1h 48204 non-null float64
3 snow_1h 48204 non-null float64
4 clouds_all 48204 non-null int64
5 weather_main 48204 non-null object
6 weather_description 48204 non-null object
7 date_time 48204 non-null object
8 traffic_volume 48204 non-null int64
dtypes: float64(3), int64(2), object(4)
reminiscence utilization: 3.3+ MBWir haben quick 50.000 stündliche Beobachtungen, die sich über mehrere Jahre erstrecken. Beachten Sie, dass die Feiertagsspalte nur 61 Nicht-Null-Werte von 48.204 Zeilen enthält. Lassen Sie uns untersuchen:
visitors('vacation').value_counts()vacation
Labor Day 7
Christmas Day 6
Thanksgiving Day 6
Martin Luther King Jr Day 6
New Years Day 6
Veterans Day 5
Columbus Day 5
Memorial Day 5
Washingtons Birthday 5
State Honest 5
Independence Day 5
Identify: depend, dtype: int64Erkenntnis Erkenntnis: Auf den ersten Blick denken Sie vielleicht, dass die Urlaubsspalte mit so wenigen Werten nahezu nutzlos ist. Aber eigentlich sind die Ferien nur um Mitternacht im Urlaub selbst markiert. Dies ist ein gutes Beispiel dafür, wie das Verständnis der Struktur Ihrer Daten einen großen Unterschied machen kann: Was so aussieht, als ob fehlende Daten tatsächlich eine bewusste Designauswahl sein können. Für eine vollständige Analyse möchten Sie diese Urlaubsmarkierungen so erweitern, dass sie alle 24 Stunden jedes Urlaubs abdecken.
Untersuchen wir unsere numerischen Variablen:
visitors.describe() temp rain_1h snow_1h clouds_all traffic_volume
depend 48204.000000 48204.000000 48204.000000 48204.000000 48204.000000
imply 281.205870 0.334264 0.000222 49.362231 3259.818355
std 13.338232 44.789133 0.008168 39.015750 1986.860670
min 0.000000 0.000000 0.000000 0.000000 0.000000
25% 272.160000 0.000000 0.000000 1.000000 1193.000000
50% 282.450000 0.000000 0.000000 64.000000 3380.000000
75% 291.806000 0.000000 0.000000 90.000000 4933.000000
max 310.070000 9831.300000 0.510000 100.000000 7280.000000
Schlüsselbeobachtungen:
- Die Temperatur reicht von 0k bis 310 Ok (dass 0K verdächtigt und wahrscheinlich ein Drawback mit der Datenqualität)
- Die meisten Stunden haben keinen Niederschlag (75. Perzentil für Regen und Schnee beträgt 0)
- Das Verkehrsvolumen reicht von 0 bis 7.280 Fahrzeugen professional Stunde
- Der Mittelwert (3.260) und die mittleren (3.380) Verkehrsvolumina sind ähnlich, was auf eine relativ symmetrische Verteilung hindeutet
Visualisierung der Verkehrsvolumenverteilung
Erstellen wir unsere erste Visualisierung, um Verkehrsmuster zu verstehen:
plt.hist(visitors("traffic_volume"))
plt.xlabel("Visitors Quantity")
plt.title("Visitors Quantity Distribution")
plt.present()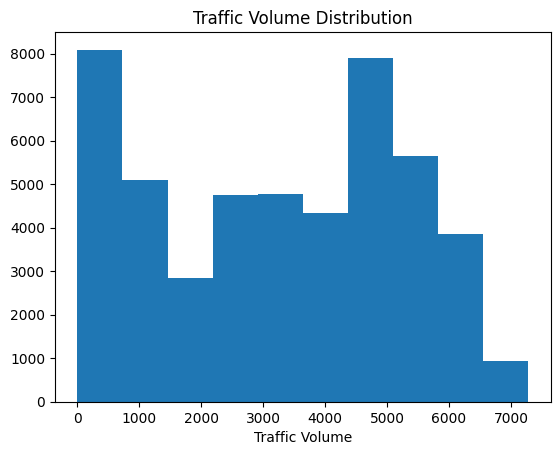
Lernen Sie Erkenntnisse: Beschriften Sie Ihre Äxte immer und fügen Sie Titel hinzu! Ihr Publikum sollte nicht erraten müssen, was es sich ansieht. Ein Diagramm ohne Kontext ist nur hübsche Farben.
Das Histogramm zeigt eine auffällige bimodale Verteilung mit zwei unterschiedlichen Peaks:
- Ein Höhepunkt in der Nähe von 0-1.000 Fahrzeugen (geringem Verkehr)
- Ein weiterer Höhepunkt rund 4.000 bis 5.000 Fahrzeuge (hoher Verkehr)
Dies deutet auf zwei verschiedene Verkehrsregime hin. Meine unmittelbare Hypothese: Diese entsprechen den Tag- und Nachtverkehrsmustern.
Tag vs. Nachtanalyse
Lassen Sie uns unsere Hypothese testen, indem wir die Daten in Tag- und Nachtperioden aufteilen:
# Convert date_time to datetime format
visitors('date_time') = pd.to_datetime(visitors('date_time'))
# Create day and night time dataframes
day = visitors.copy()((visitors('date_time').dt.hour >= 7) &
(visitors('date_time').dt.hour < 19))
night time = visitors.copy()((visitors('date_time').dt.hour >= 19) |
(visitors('date_time').dt.hour < 7))Erkenntnis erteilen: Ich habe mich von 7 bis 19 Uhr als „Tag“ ausgewählt, was uns gleich 12-Stunden-Zeiträume gibt. Dies ist etwas willkürlich und Sie können die Hauptstunden anders definieren. Ich ermutige Sie, mit unterschiedlichen Definitionen wie 6 bis 18 Uhr zu experimentieren und zu sehen, wie sich dies auf Ihre Ergebnisse auswirkt. Halten Sie einfach die Perioden ausgeglichen, um zu vermeiden, dass Ihre Analyse verzerrt ist.
Lassen Sie uns nun beide Verteilungen nebeneinander visualisieren:
plt.determine(figsize=(11,3.5))
plt.subplot(1, 2, 1)
plt.hist(day('traffic_volume'))
plt.xlim(-100, 7500)
plt.ylim(0, 8000)
plt.title('Visitors Quantity: Day')
plt.ylabel('Frequency')
plt.xlabel('Visitors Quantity')
plt.subplot(1, 2, 2)
plt.hist(night time('traffic_volume'))
plt.xlim(-100, 7500)
plt.ylim(0, 8000)
plt.title('Visitors Quantity: Evening')
plt.ylabel('Frequency')
plt.xlabel('Visitors Quantity')
plt.present()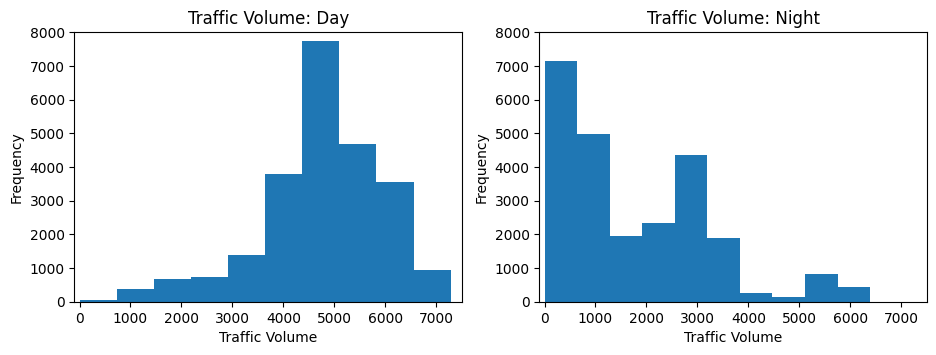
Perfekt! Unsere Hypothese ist bestätigt. Der niedrige Visitors-Peak entspricht vollständig den Nachtstunden, während der Hochverkehrspeak tagsüber auftritt. Beachten Sie, wie ich die gleichen Achsengrenzen für beide Diagramme festlegt – dies gewährleistet einen fairen visuellen Vergleich.
Quantifizieren wir diesen Unterschied:
print(f"Day visitors imply: {day('traffic_volume').imply():.0f} autos/hour")
print(f"Evening visitors imply: {night time('traffic_volume').imply():.0f} autos/hour")Day visitors imply: 4762 autos/hour
Evening visitors imply: 1785 autos/hourDer Tag des Tages ist durchschnittlich quick 3x höher als der Nachtverkehr!
Monatliche Verkehrsmuster
Erforschen wir nun saisonale Muster, indem wir den Verkehr nach Monat untersuchen:
day('month') = day('date_time').dt.month
by_month = day.groupby('month').imply(numeric_only=True)
plt.plot(by_month('traffic_volume'), marker='o')
plt.title('Visitors quantity by month')
plt.xlabel('Month')
plt.present()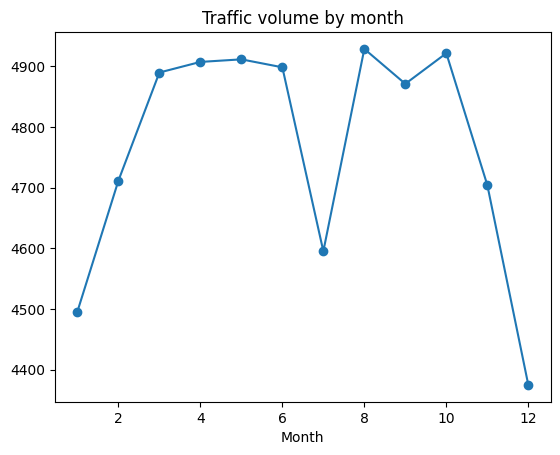
Die Handlung enthüllt:
- Wintermonate (Jan, Februar, November, Dezember) haben den Verkehr insbesondere niedriger
- Ein dramatischer Dip im Juli, der anomal erscheint
Lassen Sie uns diese Anomalie im Juli untersuchen:
day('12 months') = day('date_time').dt.12 months
only_july = day(day('month') == 7)
plt.plot(only_july.groupby('12 months').imply(numeric_only=True)('traffic_volume'))
plt.title('July Visitors by Yr')
plt.present()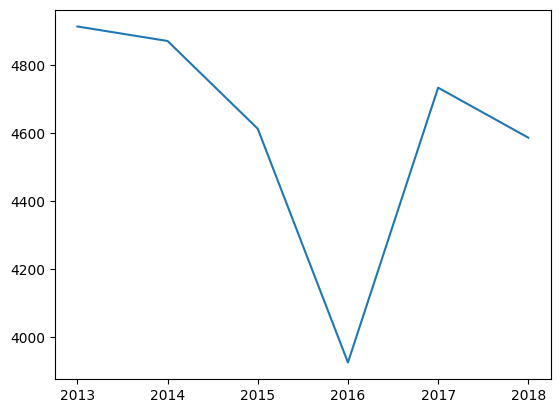
Lerneinblick: Dies ist ein perfektes Beispiel dafür, warum die explorative Visualisierung so wertvoll ist. Im Juli Dip? Es stellte sich heraus, dass die I-94 im Juli 2016 mehrere Tage lang vollständig geschlossen wurde. Diese null-fernstufigen Tage haben den monatlichen Durchschnitt dramatisch heruntergezogen. Dies ist eine Erinnerung daran, dass Ausreißer die Mittel erheblich beeinflussen können, sodass immer ungewöhnliche Muster in Ihren Daten untersuchen können!
Wochentag Muster
Lassen Sie uns wöchentliche Muster untersuchen:
day('dayofweek') = day('date_time').dt.dayofweek
by_dayofweek = day.groupby('dayofweek').imply(numeric_only=True)
plt.plot(by_dayofweek('traffic_volume'))
# Add day labels for readability
days = ('Mon', 'Tue', 'Wed', 'Thu', 'Fri', 'Sat', 'Solar')
plt.xticks(vary(len(days)), days)
plt.xlabel('Day of Week')
plt.ylabel('Visitors Quantity')
plt.title('Visitors by Day of Week')
plt.present()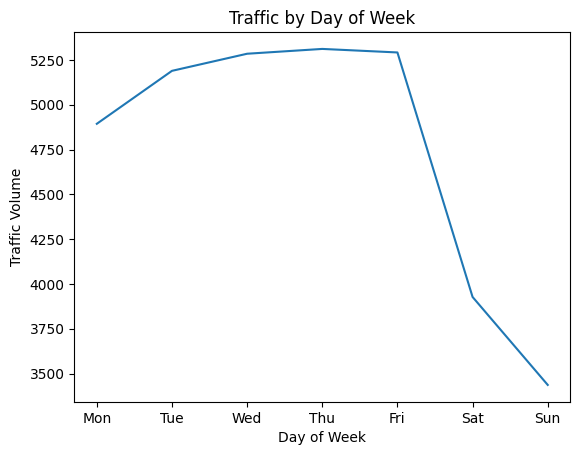
Klares Muster: Der Verkehr am Wochentag ist deutlich höher als am Wochenendverkehr. Dies passt zu Pendelmustern, weil die meisten Menschen von Montag bis Freitag zur Arbeit fahren.
Stunden Muster: Wochentag vs. Wochenende
Lassen Sie uns tiefer in Stundenmuster eintauchen und die Werktage mit den Wochenenden vergleichen:
day('hour') = day('date_time').dt.hour
business_days = day.copy()(day('dayofweek') <= 4) # Monday-Friday
weekend = day.copy()(day('dayofweek') >= 5) # Saturday-Sunday
by_hour_business = business_days.groupby('hour').imply(numeric_only=True)
by_hour_weekend = weekend.groupby('hour').imply(numeric_only=True)
plt.determine(figsize=(11,3.5))
plt.subplot(1, 2, 1)
plt.plot(by_hour_business('traffic_volume'))
plt.xlim(6,20)
plt.ylim(1500,6500)
plt.title('Visitors Quantity By Hour: Monday–Friday')
plt.subplot(1, 2, 2)
plt.plot(by_hour_weekend('traffic_volume'))
plt.xlim(6,20)
plt.ylim(1500,6500)
plt.title('Visitors Quantity By Hour: Weekend')
plt.present()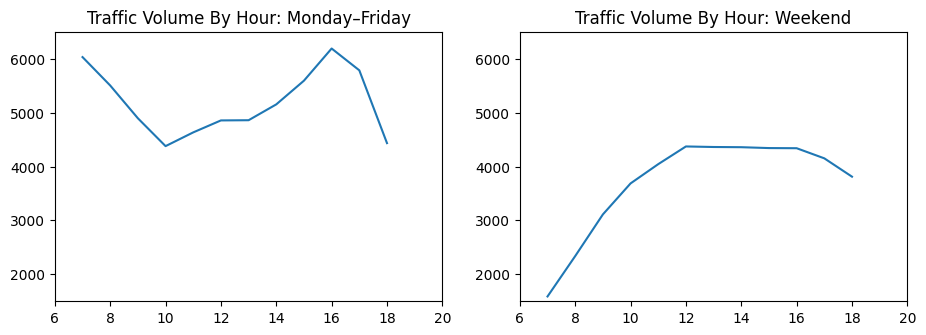
Die Muster sind auffallend unterschiedlich:
- Wochentage: Klarer Morgen (7 Uhr morgens) und Abend (16-15 Uhr) Hauptverkehrszeitspeaks
- Wochenenden: Allmählicher Anstieg des Tages ohne unterschiedliche Gipfel
- Beste Zeit zum Reisen an Wochentagen: 10 Uhr (zwischen den Hauptstunden)
Wettereffektanalyse
Lassen Sie uns nun untersuchen, ob die Wetterbedingungen den Verkehr beeinflussen:
weather_cols = ('clouds_all', 'snow_1h', 'rain_1h', 'temp', 'traffic_volume')
correlations = day(weather_cols).corr()('traffic_volume').sort_values()
print(correlations)clouds_all -0.032932
snow_1h 0.001265
rain_1h 0.003697
temp 0.128317
traffic_volume 1.000000
Identify: traffic_volume, dtype: float64Überraschend schwache Korrelationen! Das Wetter scheint das Verkehrsvolumen nicht wesentlich zu beeinflussen. Die Temperatur zeigt die stärkste Korrelation mit nur 13%.
Lassen Sie uns dies mit einem Streudiagramm visualisieren:
plt.determine(figsize=(10,6))
sns.scatterplot(x='traffic_volume', y='temp', hue='dayofweek', information=day)
plt.ylim(230, 320)
plt.present()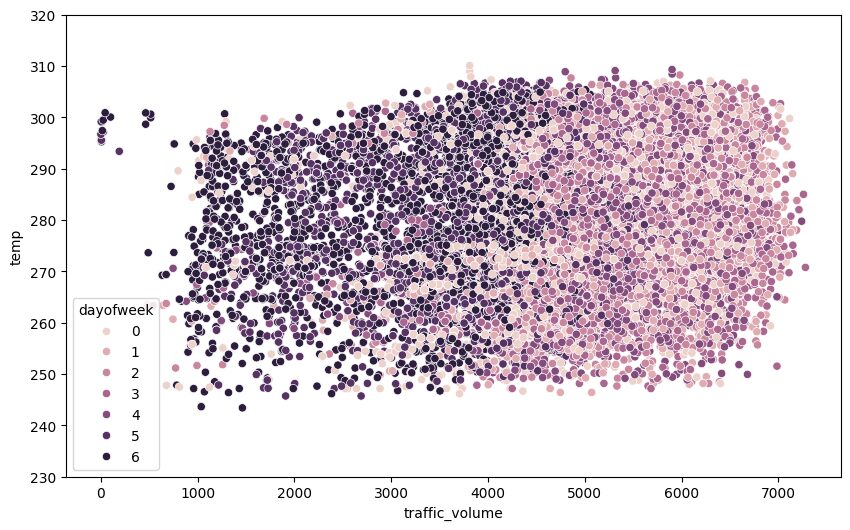
Lernen Perception: Als ich diese Scatter -Handlung zum ersten Mal erstellt habe, conflict ich aufgeregt, verschiedene Cluster zu sehen. Dann erkannte ich, dass die Farben nur unserem früheren Befund entsprechen – Weekends (dunklere Farben) haben einen geringeren Verkehr. Dies ist eine Erinnerung daran, immer kritisch darüber nachzudenken, was Muster tatsächlich bedeuten, nicht nur, dass sie existieren!
Lassen Sie uns bestimmte Wetterbedingungen untersuchen:
by_weather_main = day.groupby('weather_main').imply(numeric_only=True).sort_values('traffic_volume')
plt.barh(by_weather_main.index, by_weather_main('traffic_volume'))
plt.axvline(x=5000, linestyle="--", shade="okay")
plt.present()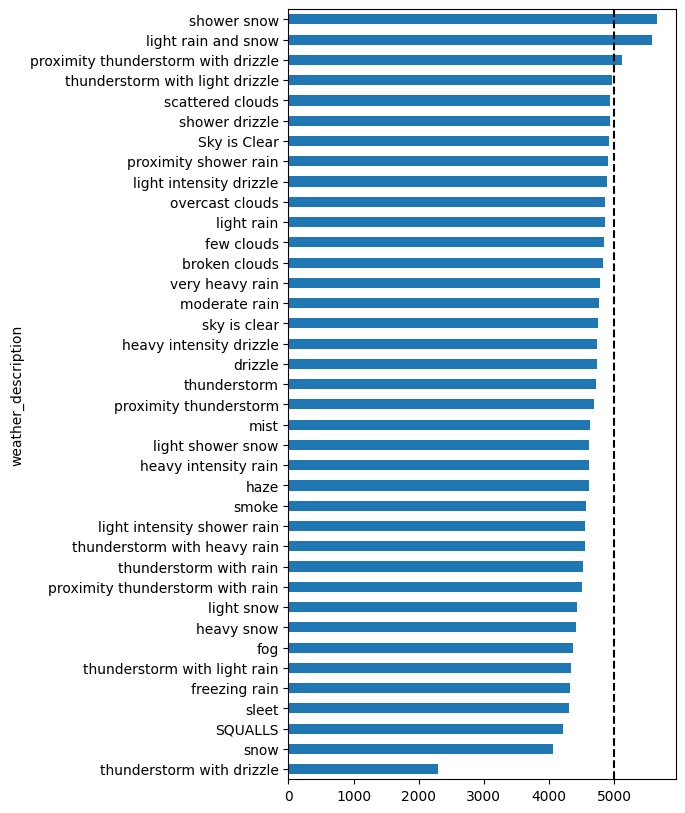
Erkenntnis lernen: Dies ist eine kritische Lektion in der Datenanalyse und Sie sollten Ihre Beispielgrößen immer überprüfen! Diese Wetterbedingungen mit scheinbar hohem Verkehrsvolumen? Sie haben jeweils nur 1-4 Datenpunkte. Sie können nicht zuverlässige Schlussfolgerungen aus solchen kleinen Proben ziehen. Die häufigsten Wetterbedingungen (klarer Himmel, verstreute Wolken) haben Tausende von Datenpunkten und zeigen durchschnittliche Verkehrsniveaus.
Schlüsselergebnisse und Schlussfolgerungen
Durch unsere explorative Visualisierung haben wir festgestellt:
Zeitbasierte Indikatoren für starken Verkehr:
- Tag vs. Nacht: Tageszeit (7 – 19 Uhr) hat 3x mehr Verkehr als Nacht
- Woche der Woche: Wochentage haben deutlich mehr Verkehr als Wochenenden
- Störzeiten: 7-8 Uhr und 16.00 bis 17.00 Uhr an Wochentagen zeigen die höchsten Bände
- Saisonal: Wintermonate (Jan, Februar, November, Dezember) haben niedrigere Verkehrsvolumina
Wetterauswirkungen:
- Überraschend minimale Korrelation zwischen Wetter und Verkehrsvolumen
- Die Temperatur zeigt eine schwache constructive Korrelation (13%)
- Regen und Schnee zeigen quick keine Korrelation
- Dies deutet darauf hin, dass Pendler unabhängig von den Wetterbedingungen fahren
Beste Zeiten zum Reisen:
- Vermeiden: Wochentags Hauptstunden (7-8 Uhr, 16-15 Uhr)
- Optimum: Wochenenden, Nächte oder Mid-Day an Wochentagen (gegen 10 Uhr)
Nächste Schritte
Betrachten Sie, um diese Analyse zu erweitern:
- Urlaubsanalyse: Erweitern Sie die Urlaubsmarker, um alle 24 Stunden abzudecken und die Feiertagsverkehrsmuster zu analysieren
- Wetterdauer: Beeinflusst die aufeinanderfolgenden Stunden Regen/Schnee den Verkehr unterschiedlich?
- Ausreißeruntersuchung: Tauchgang in die Schließung des Juli 2016 und andere Anomalien
- Vorhersagemodellierung: Erstellen Sie ein Modell, um das Verkehrsvolumen basierend auf Zeit und Wetter zu prognostizieren
- Richtungsanalyse: Vergleichen
Dieses Projekt zeigt perfekt die Kraft der explorativen Visualisierung. Wir begannen mit einer einfachen Frage: „Was verursacht starke Verkehr?“ Und durch systematische Visualisierung wurden klare Muster aufgedeckt. Die Wetterergebnisse überraschten mich; Ich erwartete, dass Regen und Schnee den Verkehr erheblich beeinflussen würden. Dies erinnert uns daran, Daten unsere Annahmen in Frage zu stellen!
Weitere Projekte zu versuchen
Wir haben einige andere Projekte zur Walkthrough -Tutorials, die Sie auch genießen können:
Schöne Grafiken sind schön, aber Sie sind nicht der Punkt. Der eigentliche Wert der explorativen Datenanalyse kommt, wenn Sie tief genug graben, um tatsächlich zu verstehen, was in Ihren Daten passiert, mit denen Sie intelligente Entscheidungen auf der Grundlage Ihrer Findungen treffen können. Egal, ob Sie eine Pendler -Planung Ihrer Route oder ein Stadtplaner, der den Verkehrsfluss optimiert, diese Erkenntnisse bieten umsetzbare Intelligenz.
Wenn Sie dieses Projekt versuchen, teilen Sie bitte Ihre Ergebnisse in der Dataquest -Group und markieren Sie mich (@Ana_strahl). Ich würde gerne sehen, welche Muster Sie entdecken!
Viel Spaß bei der Analyse!