
KI -Modelle werden von Tag zu Tag schlauer – es werden besser geprägt, schneller laufen und längere Kontexte als je zuvor umgehen. Der QWEN3-Subsequent-80B-A3B macht diesen Sprung mit effizienten Trainingsmustern, einem hybriden Aufmerksamkeitsmechanismus und einer ultrasparigen Mischung von Experten nach vorne. Fügen Sie Stabilitätsfokussierte hinzu, und Sie erhalten ein Modell, das schneller, zuverlässiger und stärker auf den Benchmarks ist. In diesem Artikel werden wir die Architektur, die Schulungseffizienz und die Leistung bei den Anweisungen und Denkanforderungen untersuchen. Wir werden uns auch Upgrades in der Handhabung des lang Kontext, der Mehrfachgefahr-Vorhersage und der Inferenzoptimierung ansehen. Schließlich zeigen wir Ihnen, wie Sie auf das Gesicht zugreifen und auf die nächste API von Qwen 3 verwenden.
Verständnis der Architektur von QWEN3-Subsequent-80B-A3B
QWEN3-NEXT Verwendet eine zukunftsgerichtete Architektur, die die Recheneffizienz, den Rückruf und die Trainingsstabilität in Einklang bringen. Es spiegelt tiefgreifende Experimente mit hybriden Aufmerksamkeitsmechanismen, ultra-sparsamer Mischungen der Experten und der Skalierung von Experten und Inferenzoptimierungen wider.
Lassen Sie uns seine Schlüsselelemente Schritt für Schritt aufschlüsseln:
Hybride Aufmerksamkeit: Gated Deltanet + Gated Achtung
Die traditionelle Aufmerksamkeit für skalierte Dot-Produkte ist sturdy, aber aufgrund der quadratischen Komplexität rechenintensiv. Lineare Aufmerksamkeits skaliert besser, kämpft aber mit dem langfristigen Rückruf. QWEN3-NEXT-80B-A3B verfolgt einen hybriden Ansatz:
- 75% der Schichten Verwenden Sie Gated Deltanet (lineare Aufmerksamkeit) für eine effiziente Sequenzverarbeitung.
- 25% der Schichten Verwenden Sie die Commonplace -Gated -Aufmerksamkeit für einen stärkeren Rückruf.
Diese 3: 1 -Mischung verbessert die Inferenzgeschwindigkeit und bewahrt die Genauigkeit des Kontextlernens. Zusätzliche Verbesserungen umfassen:
- Größere Abmessungen mit Gated Head (256 gegenüber 128).
- Teilweise Rotationseinbettungen, die auf 25% der Positionsabmessungen angewendet wurden.
Extremely-Sparse-Mischung aus Experten (MOE)
Qwen3-Subsequent implementiert einen sehr spärlichen Moe Design: 80B Gesamtparameter, aber bei jedem Inferenzschritt nur ~ 3b aktiviert. Experimente zeigen, dass der globale Lastausgleich durchweg einen Trainingsverlust verursacht, wodurch sich die Gesamt -Expertenparameter verringert und aktivierte Experten konstant halten. Qwen3-Subsequent schiebt MOE-Design auf eine neue Skala:
- Insgesamt 512 Experten mit 10 Routed + 1 Shared Knowledgeable wurden professional Schritt aktiviert.
- Trotz von 80B Gesamtparametern sind nur ~ 3b professional Inferenz aktiv und steigern ein hervorragendes Gleichgewicht zwischen Kapazität und Effizienz.
- Eine globale Strategie für das Ladungsausgleich sorgt für die Nutzung von Experten und minimiert die Kapazität der Verschwendung und verringert gleichzeitig den Schulungsverlust, wenn die Anzahl der Experten wächst.
Dieses spärliche Aktivierungsdesign ermöglicht es dem Modell, massiv zu skalieren, ohne proportional zu erhöhen.
Trainingsstabilitätinnovationen
Skalierungsmodelle führen häufig versteckte Fallstricke wie explodierende Normen oder Aktivierungssenken ein. QWEN3-Subsequent befasst sich mit mehreren Stabilitätsmechanismen mit mehreren Stabilität:
- Das Ausgangsgating bei Aufmerksamkeit beseitigt Probleme mit geringer Rang und Aufmerksamkeitssenkeneffekte.
- Null-zentriertes RMSNORM ersetzt QK-Norm, wodurch außer Kontrolle geratene Normgewichte verhindert werden.
- Gewichtsverfall bei Normparametern vermeidet ein unbegrenztes Wachstum.
- Die ausgewogene Initialisierung von Router gewährleistet von Anfang an eine faire Auswahl an Experten und verringert das Trainingsgeräusch.
Diese sorgfältigen Anpassungen machen sowohl kleine Exams als auch groß angelegte Schulungen erheblich zuverlässiger.
Multi-Token-Vorhersage (MTP)
QWEN3-NEXT Integriert ein nationales MTP-Modul in eine hohe Akzeptanzrate für die spekulative Decodierung sowie Optimierungen mit mehrstufigen Inferenzverzögerungen. Mit einem mehrstufigen Trainingsansatz übereinstimmt das Coaching und die Schlussfolgerung, um die Nichtübereinstimmung zu verringern und die reale Leistung zu verbessern.
Schlüsselvorteile:
- Eine höhere Akzeptanzrate für die spekulative Decodierung, was bedeutet – eine schnellere Inferenz.
- Das mehrstufige Coaching richtet Coaching und Inferenz aus und reduziert die BPRED-Nichtübereinstimmung.
- Verbesserter Durchsatz mit der gleichen Genauigkeit, very best für die Produktionsnutzung.
Warum ist es wichtig?
Durch das Zusammenweben von hybriden Aufmerksamkeit, die Extremely-Sparse-Moe-Skalierung, die robusten Stabilitätskontrollen und die multi-gepflegere Vorhersage etabliert sich QWEN3-Subsequent-80B-A3B als Modell der neuen Technology. Es ist nicht nur größer, es ist auch intelligenter, wie es Berechnung zuweist, die Trainingsstabilität verwaltet und die Effizienz der Inferenz -Effizienz im Maßstab liefert.
Effizienz vor dem Coaching und Inferenzgeschwindigkeit
QWEN3-NEXT-80B-A3B zeigt die phänomenale Effizienz bei Voraussetzungen und erheblichen Durchsatzgeschwindigkeitsergebnissen bei der Schlussfolgerung für langkontexte Aufgaben. Durch die Gestaltung der Corpus -Architektur und die Anwendung von Merkmalen wie Sparsity und hybride Aufmerksamkeit reduzieren sie die Berechnung der Kosten und maximieren gleichzeitig den Durchsatz sowohl in der Pre -Fill (Kontextaufnahme) als auch in der Dekodierung (Technology).
Trainiert mit einer gleichmäßig abgetasteten Untergruppe von 15 Billionen Token aus dem ursprünglichen 36T-gepflegten Korpus von Qwen3.
- Nutzt <80% der GPU-Stunden im Vergleich zu QWEN3-30A-3B und nur 9,3% der Berechnungskosten von QWEN3-32B, während beide übertreffen.
- Inferenz beschleunigt von seiner Hybridarchitektur (Gated Deltanet + Gated Achtung):
- Vorab-Stufe: Bei 4K-Kontextlänge ist der Durchsatz quick 7x höher als QWEN3-32B. Abgesehen von 32 km ist es schneller über 10x.
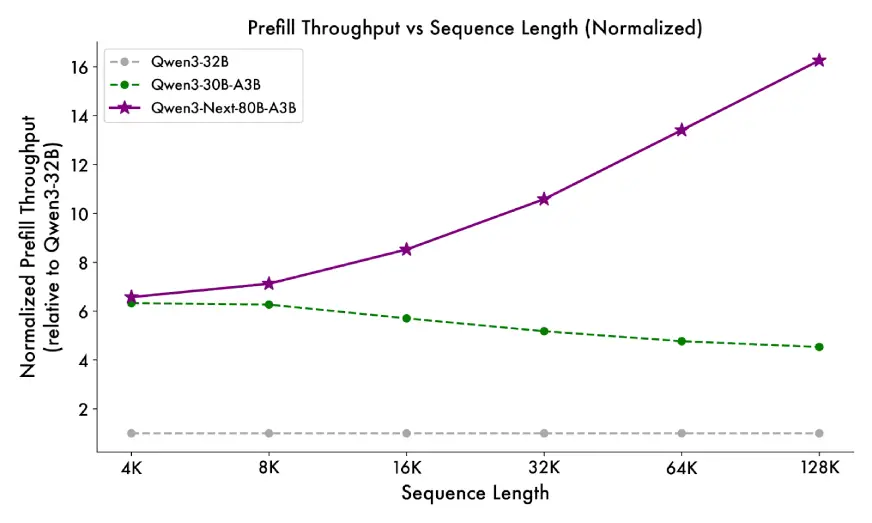
- Decodes -Stufe: Im 4K -Kontext ist der Durchsatz quick 4x höher. Sogar über 32 km hält es immer noch einen 10 -fachen Geschwindigkeitsvorteil.
Basismodellleistung
Während QWEN3-NEXT-80B-A3B-Base im Vergleich zu QWEN3-32B-Foundation nur etwa 1/10, wie viele Nicht-Embedding-Parameter, aktiviert, übereinstimmt oder übertrifft es QWEN3-32B auf nahezu allen Benchmarks und übertrifft QWEN3-30B-A3B. Dies zeigt die Parametereffizienz: weniger aktivierte Parameter, aber genauso fähig.
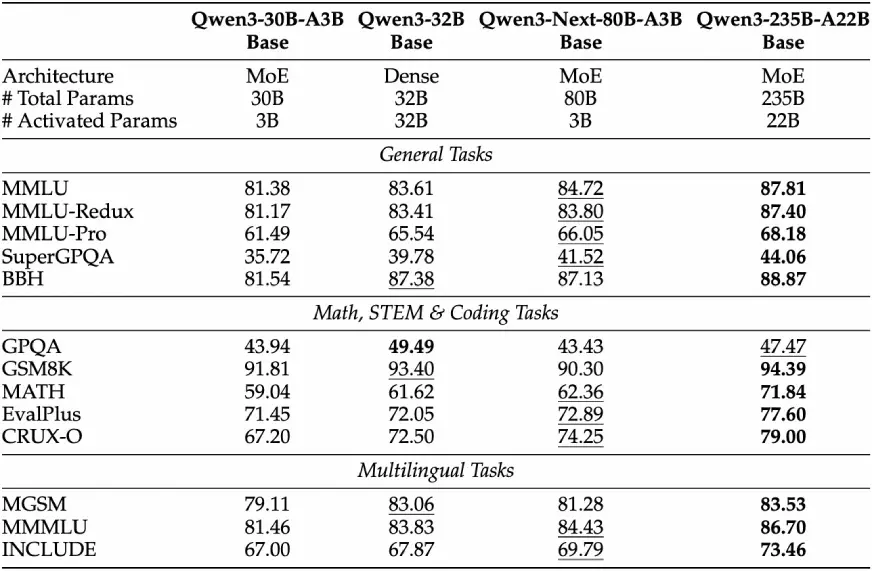
Nach der Ausbildung
Nachdem zwei abgestimmte Varianten von Qwen33-Subsequent-80B-A3B: Unterricht und Denken unterschiedliche Stärken aufweisen, insbesondere für Anweisungen, Argumentation und ultra-lange Kontexte.
Modellleistung anweisen
QWEN3-NEXT-80B-A3B-Instruct zeigt beeindruckende Gewinne gegen frühere Modelle und schließt die Lücke in Richtung größerer Modelle, insbesondere wenn es um lange Kontextaufgaben und -anweisungen geht.
- Überschreitet QWEN3-30B-A3B-Instruct-2507 und Qwen3-32B-Non-Dinking in zahlreichen Benchmarks.
- In vielen Fällen tauscht es quick Schläge mit Flaggschiff QWEN3-235B-A22B-Instruct-2507 aus.
- Über Lineal, ein Maßstab für ultraange Kontextaufgaben, schlägt QWEN3-NEXT-80-B-Instruct Qwen3-30b-A3B-Instruct-2507 unter allen Längen, obwohl es weniger Aufmerksamkeitsschichten hat und Qwen3-235b-A222b-Instruct-2507-Länge auf 256 okay bis zu. Dies wurde für ultra-lange Kontextaufgaben verifiziert und zeigt den Nutzen des Hybriddesigns (Gated Deltanet & Gated Achtung) für lange Kontextaufgaben.
Denkmodellleistung
Die „Denken“ -Model hat die Fähigkeiten zur Begründung (z. B., z. B. Kette der Gedanken und ausgefeiltere Inferenz), auf die auch QWEN3-NEXT-80B-A3B übertrifft.
- Übertrifft die teurere QWEN3-30B-A3B-Dinking-2507 und QWEN3-32B-Pondering mehrmals über mehrere Benchmarks.
- Übertrifft die teurere QWEN3-30B-A3B-Dinking-2507 und QWEN3-32B-Pondering mehrmals über mehrere Benchmarks.
- Kommt dem Flaggschiff QWEN3-235B-A22B-Dinking-2507 in Schlüsselmetriken, obwohl sie so wenige Parameter aktiviert haben.
Zugriff auf Qwen3 als nächstes mit API
Um QWEN3-NEXT-80B-A3B Ihren Apps kostenlos zur Verfügung zu stellen, können Sie die Hub-Face-Hub über die OpenAI-kompatible API verwenden. Hier erfahren Sie, wie es geht und was jedes Stück bedeutet.
Nach der Anmeldung müssen Sie sich mit dem Umarmungsgesicht authentifizieren, bevor Sie das Modell verwenden können. Befolgen Sie dazu diese Schritte
- Gehen Sie zu Huggingface.co und melden Sie sich an oder melden Sie sich an, wenn Sie kein Konto haben.
- Klicken Sie zunächst auf Ihr Profil (oben rechts). Dann „Einstellungen“ → „Zugriff auf Token“.
- Sie können ein neues Token erstellen oder einen vorhandenen verwenden. Geben Sie ihm entsprechende Berechtigungen nach dem, was Sie brauchen, z. B. Lesen und Inferenz. Dieses Token wird in Ihrem Code verwendet, um Anforderungen zu authentifizieren.
Praktisch mit QWEN3 Nächste API
Sie können implementieren QWEN3-NEXT-80B-A3B kostenlos mit dem OpenAI-kompatiblen Kunden von Sugging Face. Das folgende Beispiel für Python zeigt, wie Sie sich mit Ihrem Umarmungs -Gesichts -Token authentifizieren, eine strukturierte Eingabeaufforderung senden und die Antwort des Modells erfassen können. In der Demo füttern wir ein Fabrikproduktionsproblem in das Modell, drucken die Ausgabe und speichern sie in einer Markdown-Datei-eine schnelle Möglichkeit, QWEN3-NEXT in reale Argumentation und Problemlösungsworkflows zu integrieren.
import os
from openai import OpenAI
consumer = OpenAI(
base_url="https://router.huggingface.co/v1",
api_key="HF_TOKEN",
)
completion = consumer.chat.completions.create(
mannequin="Qwen/Qwen3-Subsequent-80B-A3B-Instruct:novita",
messages=(
{
"function": "person",
"content material": """
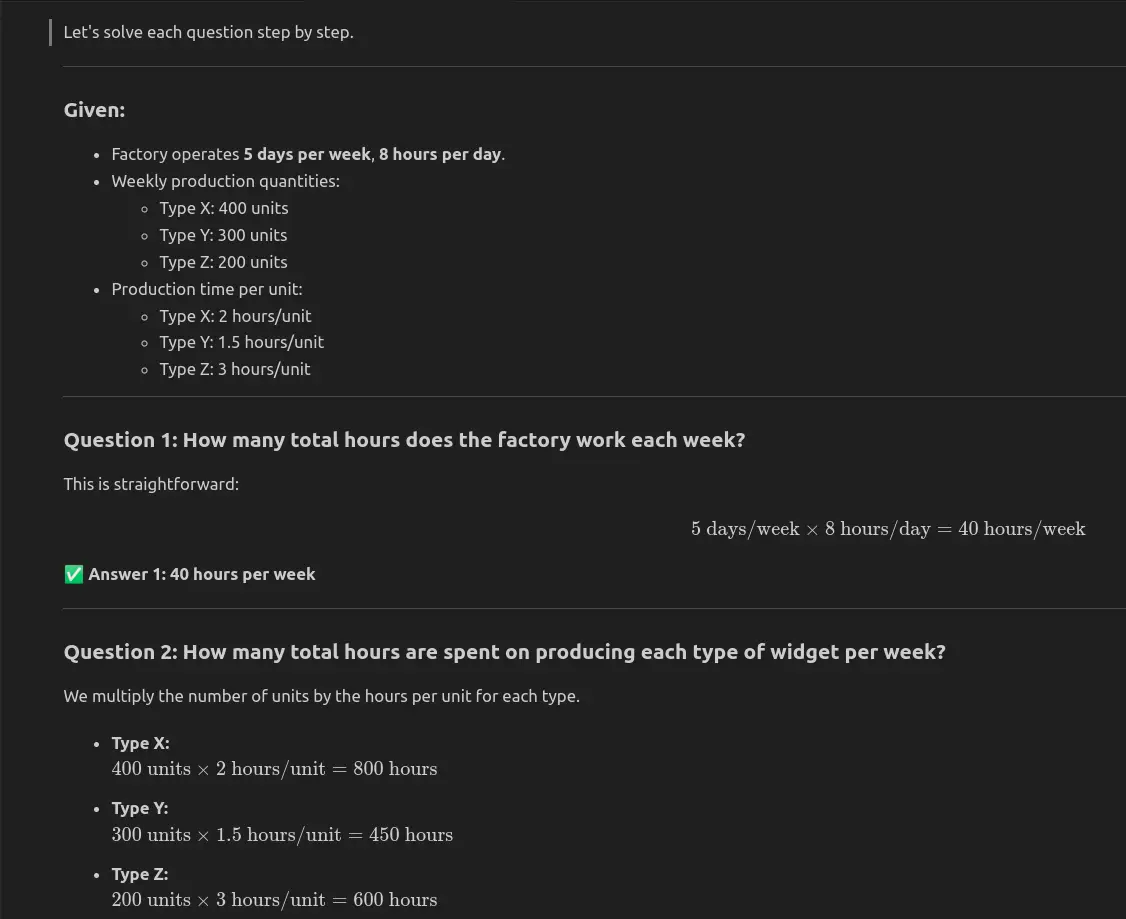
A manufacturing unit produces three forms of widgets: Kind X, Kind Y, and Kind Z.
The manufacturing unit operates 5 days every week and produces the next portions every week:
- Kind X: 400 models
- Kind Y: 300 models
- Kind Z: 200 models
The manufacturing charges for every kind of widget are as follows:
- Kind X takes 2 hours to supply 1 unit.
- Kind Y takes 1.5 hours to supply 1 unit.
- Kind Z takes 3 hours to supply 1 unit.
The manufacturing unit operates 8 hours per day.
Reply the next questions:
1. What number of complete hours does the manufacturing unit work every week?
2. What number of complete hours are spent on producing every kind of widget per week?
3. If the manufacturing unit needs to extend its output of Kind Z by 20% with out altering the work hours, what number of further models of Kind Z will should be produced per week?
"""
}
),
)
message_content = completion.selections(0).message.content material
print(message_content)
file_path = "output.txt"
with open(file_path, "w") as file:
file.write(message_content)
print(f"Response saved to {file_path}")- Base_url = ”https://router.huggingface.co/v1 ″: Gibt dem Routing-Endpunkt von OpenAi-kompatiblem Shopper das Face-Umarmungsend.
- api_key = ”hf_token”: Ihr persönliches Umarmungs -Gesichts -Zugangs -Token. Dies autorisiert Ihre Anfragen und ermöglicht die Abrechnung/Nachverfolgung unter Ihrem Konto.
- mannequin = ”QWEN/QWEN3-NEXT-80B-A3B-ISTRUCT: Novita”: Gibt an, welches Modell Sie verwenden möchten. „QWEN/QWEN3-NEXT-80B-A3B-Instruct“ ist das Modell; „: Novita“ ist ein Anbieter/Varianten -Suffix.
- Messages = (…): Dies ist das Commonplace -Chat -Format: eine Liste von Nachrichtendiktieren mit Rollen („Benutzer“, „System“ usw.). Sie senden das Modell, worauf Sie antworten sollen.
- Fertigstellung.Selections (0) .Message: Sobald das Modell antwortet, extrahieren Sie so den Inhalt dieser Antwort.
Modellantwort
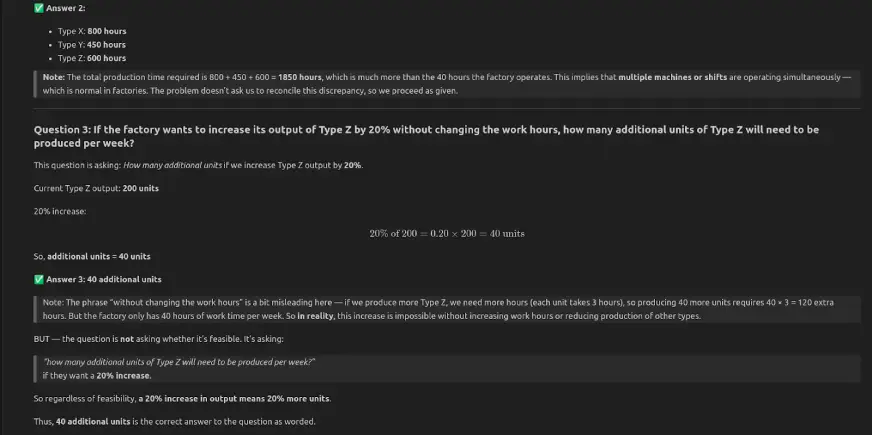
QWEN3-NEXT-80B-A3B-Instruct hat alle drei Fragen korrekt beantwortet: Die Fabrik funktioniert 40 Stunden professional Woche, die Gesamtproduktionszeit beträgt 1850 Stunden und eine Erhöhung der Ausgabe vom Typ Z fügt 40 Einheiten professional Woche hinzu.
Abschluss
QWEN3-NEXT-80B-A3B zeigt, dass große Sprachmodelle Effizienz, Skalierbarkeit und starke Argumentation ohne schwere Berechnungstkosten erreichen können. Das hybride Design, die spärliche MOE und die Trainingsoptimierungen machen es sehr praktisch. Es liefert genaue Ergebnisse in der numerischen Argumentation und der Produktionsplanung, was sich für Entwickler und Forscher als nützlich erweist. Mit freiem Zugang zum Umarmungsgesicht ist Qwen eine solide Wahl für Experimente und angewandte KI.
Hallo! Ich bin Vipin, ein leidenschaftlicher Knowledge Science und maschinelles Lernen, der eine starke Grundlage für die Datenanalyse, Algorithmen und Programmierung maschinelles Lernens und Programmierung hat. Ich habe praktische Erfahrungen beim Aufbau von Modellen, beim Verwalten unordentlicher Daten und die Lösung realer Probleme. Mein Ziel ist es, datengesteuerte Erkenntnisse anzuwenden, um praktische Lösungen zu erstellen, die Ergebnisse erzielen. Ich bin bestrebt, meine Fähigkeiten in einer kollaborativen Umgebung beizutragen und gleichzeitig in den Bereichen Datenwissenschaft, maschinelles Lernen und NLP zu lernen und zu wachsen.
Melden Sie sich an, um weiter zu lesen und Experten-Kuratinhalte zu genießen.