
Das QWEN-Workforce von Alibaba hat gerade FP8-quantisierte Kontrollpunkte für seine neuen QWEN3-NEXT-80B-A3B-Modelle in zwei Nachtraining-Varianten veröffentlicht.Anweisen Und Denken-Ausgelassene Inferenz mit hohem Durchsatz mit extrem langer Kontext und MOE-Effizienz. Der FP8-Repos spiegelt die BF16-Veröffentlichungen wider, packt jedoch „feinkörnige FP8“ -Regewichte (Blockgröße 128) und Bereitstellungshinweise für Sglang- und VllM-Builds. Benchmarks in den Karten bleiben die der ursprünglichen BF16 -Modelle; FP8 wird „aus Bequemlichkeit und Leistung“ nicht als separate Bewertungslauf zur Verfügung gestellt.
Was ist im A3B -Stack?
QWEN3-NEXT-80B-A3B ist eine hybride Architektur, die Gated Deltanet (ein lineares/konv-style-Aufmerksamkeits-Ersatz) mit geschlossener Aufmerksamkeit kombiniert und mit einer ultrasparigen Mischung aus Experten (MOE) verschachtelt ist. Das 80B -Gesamtparameterbudget aktiviert ~ 3B -Parameter professional Token über 512 Experten (10 Routed + 1 Shared). Das Format ist als 48 Schichten angegeben, die in 12 Blöcke angeordnet sind: 3×(Gated DeltaNet → MoE) gefolgt von 1×(Gated Consideration → MoE). Der native Kontext beträgt 262.144 Token, validiert bis zu ~ 1.010.000 Token unter Verwendung von Seilskalierung (Garn). Die versteckte Größe beträgt 2048; Die Aufmerksamkeit verwendet 16 Q -Köpfe und 2 kV -Köpfe bei Head Dim 256; Deltanet verwendet 32 V- und 16 QK -lineare Köpfe bei Head Dim 128.
Das QWEN-Workforce meldet, dass das 80B-A3B-Basismodell QWEN3-32B bei nachgeschalteten Aufgaben zu ~ 10% seiner Trainingskosten übertrifft und ~ 10 × Inferenzdurchsatz über einen 32-km-Kontext hinausgeht-durch eine geringe Aktivierung bei der MOE und bei der Multi-Token-Vorhersage (MTP). Die Unterrichtsvariante ist nicht umsetzt (nein <suppose> Tags), während die Denkvariante standardmäßig Argumentationsspuren erzwingt und für komplexe Probleme optimiert wird.

FP8 veröffentlicht: Was hat sich tatsächlich geändert
Die FP8-Modellkarten geben an, dass die Quantisierung „feinkörnig FP8“ mit Blockgröße 128 ist. Die Bereitstellung unterscheidet sich geringfügig von BF16: Sowohl Sglang als auch VLLM erfordern aktuelle Haupt-/Nachtbaute, wobei Beispielbefehle für 256K-Kontext und optionales MTP angegeben sind. Die Considering FP8 -Karte empfiehlt auch ein Argumentationsparser -Flag (z. B., z. --reasoning-parser deepseek-r1 in Sglang, deepseek_r1 in vllm). Diese Releases behalten die Lizenzierung von Apache-2.0.
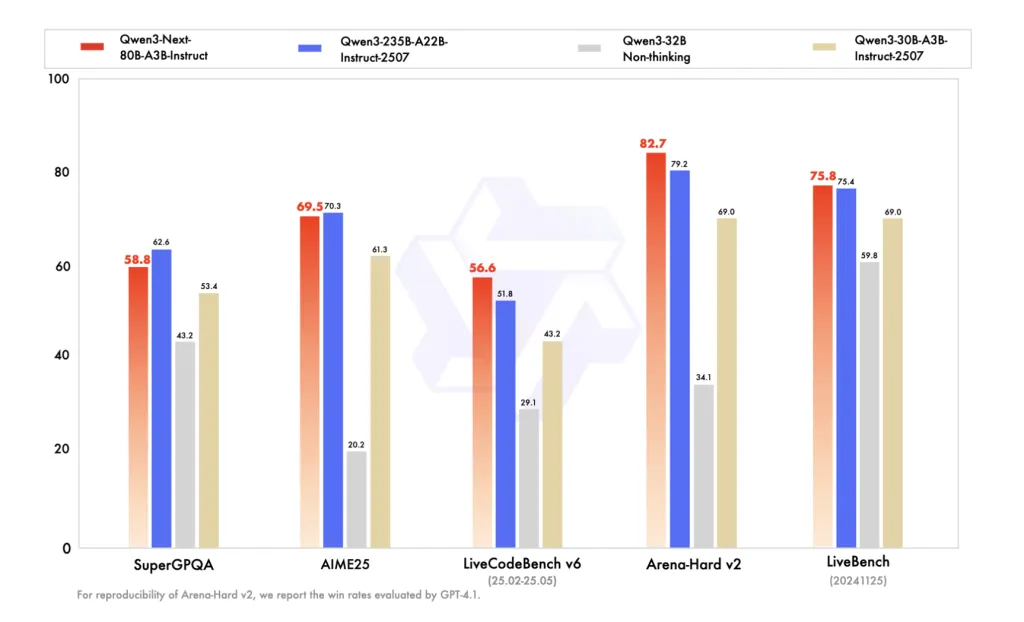
Benchmarks (berichtet über BF16 -Gewichte)
Die Anweisung FP8-Karten reproduziert Qwens BF16-Vergleichstabelle und stellt QWEN3-NEXT-80B-A3B-Struktur mit QWEN3-235B-A22B-Instruct-257 auf mehrere Wissens-/Argumentations-/Codierungs-Benchmarks und bis zu 256K). Die Denkweise fp8 karten listet Aime’25, HMMT’25, MMLU-pro/Redux und LiveCodeBench V6 auf, wobei Qwen3-Subsequent-80B-A3B-Dinking frühere qwen3 Considering-Veröffentlichungen (30b a3b-2507, 32b) übertrifft, und Anspruchsgedanken über die Überschläge über Gemini-2,5-Lash-Considering.
Trainings- und Nach-Coaching-Signale
Die Serie ist vor dem Coaching auf ~ 15T-Token ausgebildet. QWEN hebt die Stabilitätsergänzungen (null-zentrierte, gewichtsbekannte Schichtnorm usw.) hervor und verwendet GSPO in RL nach dem Coaching für das Denkmodell, um die hybride Aufmerksamkeit + MOE-Kombination mit hoher Paralität zu bewältigen. MTP wird verwendet, um die Inferenz zu beschleunigen und das Sign vor dem Vorabstieg zu verbessern.
Warum ist FP8 wichtig?
Bei modernen Beschleunigern reduzieren FP8 -Aktivierungen/-gewichte die Speicherbandbreitendruck und den ansässigen Fußabdruck gegenüber BF16, wodurch größere Stapelgrößen oder längere Sequenzen in ähnlicher Latenz ermöglicht werden. Da A3B nur ~ 3B-Parameter professional Token Routen leitete, verbindet die Kombination von FP8 + Moe-Sparsity-Verbindungen Durchsatzgewinne in langkontexten Routine, insbesondere wenn sie mit spekulativem Decodieren über MTP wie in den Servierflags exponierten MTP exponiert sind. Die Quantisierung interagiert jedoch mit Routing- und Aufmerksamkeitsvarianten; Die realen Akzeptanzraten für spekulative Dekodierung und Endaufgabegenauigkeit können mit den Implementierungen von Engine und Kernel variieren-daher die Anleitung von Qwen, um aktuelle Sglang/VllM zu verwenden und spekulative Einstellungen zu stimmen.
Zusammenfassung
Die FP8-Veröffentlichungen von Qwen machen den 80B/3B-aktiven A3B-Stack praktisch, um im 256-Ok-Kontext auf Mainstream-Motoren zu dienen, wodurch das Hybrid-Moe-Design und den MTP-Pfad für hohen Durchsatz erhalten bleiben. Die Modellkarten behalten Benchmarks von BF16 von BF16, sodass die Groups die Genauigkeit und Latenz von FP8 auf ihren eigenen Stapeln validieren sollten, insbesondere mit Parsers und spekulativen Einstellungen. Nettoergebnis: Niedrigere Speicherbandbreite und verbesserte Parallelität ohne architektonische Regressionen, positioniert für Lengthy Context Manufacturing Workloads.
Schauen Sie sich das an QWEN3-NEXT-80B-A3B-Modelle in zwei Nachtraining-Varianten-Anweisen Und Denken. Fühlen Sie sich frei, unsere zu überprüfen Github -Seite für Tutorials, Codes und Notizbücher. Fühlen Sie sich auch frei, uns zu folgen Twitter Und vergessen Sie nicht, sich unserer anzuschließen 100k+ ml Subreddit und abonnieren Unser E-newsletter.
Asif Razzaq ist der CEO von Marktechpost Media Inc. Sein jüngstes Bestreben ist die Einführung einer Medienplattform für künstliche Intelligenz, Marktechpost, die sich durch die ausführliche Berichterstattung über maschinelles Lernen und Deep-Studying-Nachrichten auszeichnet, die von einem breiten Publikum technisch intestine und leicht verständlich sind. Die Plattform verfügt über über 2 Millionen monatliche Ansichten und veranschaulicht ihre Beliebtheit des Publikums.