Forscher aus Stanford, EPFL und UNC einführen Schwach-für-Stark-Gebäude, W4Sein neues Reinforcement Studying RL-Framework, das einen kleinen Meta-Agenten darin schult, Code-Workflows zu entwerfen und zu verfeinern, die ein stärkeres Executor-Modell aufrufen. Der Meta-Agent führt keine Feinabstimmung des starken Modells durch, sondern lernt, es zu orchestrieren. W4S formalisiert das Workflow-Design als mehrstufigen Markov-Entscheidungsprozess und trainiert den Metaagenten mit einer Methode namens Reinforcement Studying zur Agenten-Workflow-Optimierung, RLAO. Das Forschungsteam meldet konsistente Zuwächse über 11 Benchmarks hinweg mit einem 7B-Meta-Agenten, der etwa eine GPU-Stunde lang trainiert wurde.
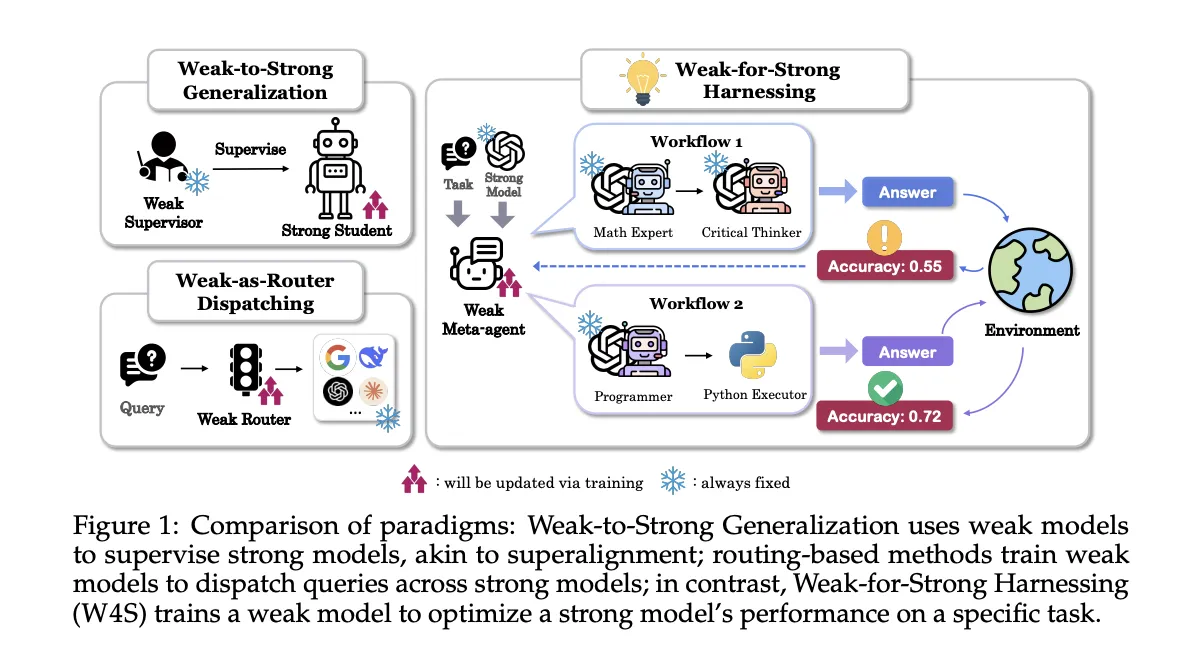
W4S arbeitet abwechselnd. Der Standing enthält Aufgabenanweisungen, das aktuelle Workflow-Programm und Suggestions zu früheren Ausführungen. Eine Aktion besteht aus zwei Komponenten: einer Analyse dessen, was geändert werden soll, und neuem Python-Workflow-Code, der diese Änderungen implementiert. Die Umgebung führt den Code für Validierungselemente aus, gibt Genauigkeits- und Fehlerfälle zurück und stellt einen neuen Standing für die nächste Runde bereit. Der Meta-Agent kann eine schnelle Selbstprüfung an einer Probe durchführen. Wenn Fehler auftreten, versucht er bis zu drei Reparaturen. Wenn die Fehler weiterhin bestehen, wird die Aktion übersprungen. Diese Schleife gibt ein Lernsignal, ohne die Gewichte des starken Ausführenden zu berühren.
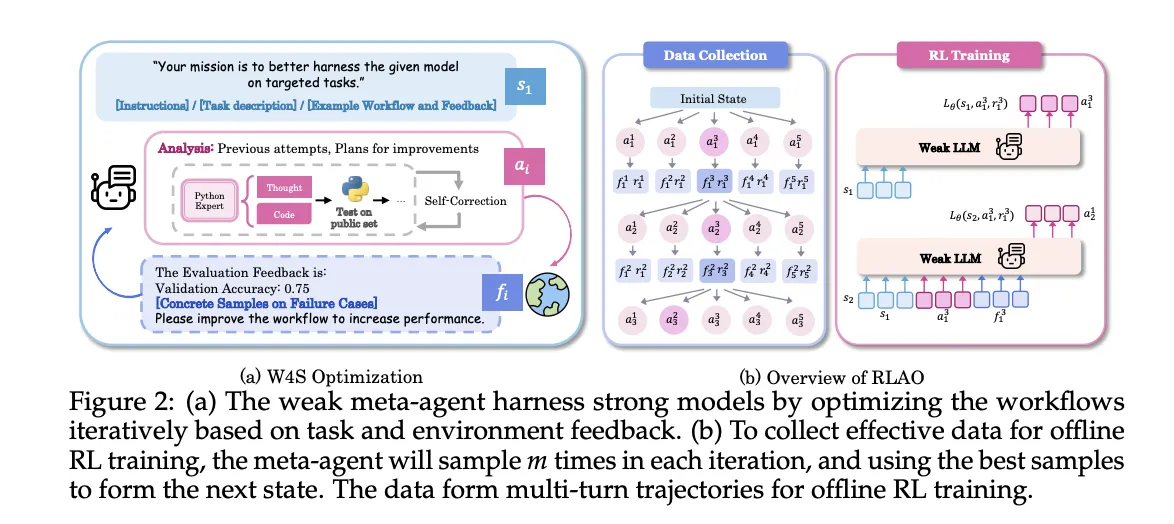
W4S läuft als iterative Schleife
- Workflow-Generierung: Der schwache Metaagent schreibt einen neuen Workflow, der das starke Modell nutzt, ausgedrückt als ausführbarer Python-Code.
- Ausführung und Suggestions: Das starke Modell führt den Workflow für Validierungsproben aus und gibt dann Genauigkeit und Fehlerfälle als Suggestions zurück.
- Verfeinerung: Der Meta-Agent verwendet das Suggestions, um die Analyse und den Workflow zu aktualisieren, und wiederholt dann die Schleife.
Reinforcement Studying zur Optimierung des Agenten-Workflows (RLAO)
RLAO ist ein Offline-Lernverfahren zur Verstärkung über Multi-Flip-Trajektorien. Bei jeder Iteration prüft das System mehrere Kandidatenaktionen, behält die Aktion mit der besten Leistung bei, um den Zustand voranzutreiben, und speichert die anderen für das Coaching. Die Richtlinie wird durch belohnungsgewichtete Regression optimiert. Die Belohnung ist spärlich und vergleicht die aktuelle Validierungsgenauigkeit mit der Historie. Eine höhere Gewichtung wird vergeben, wenn das neue Ergebnis das bisher beste Ergebnis übertrifft, eine kleinere Gewichtung wird vergeben, wenn es die letzte Iteration übertrifft. Dieses Ziel begünstigt einen stetigen Fortschritt bei gleichzeitiger Kontrolle der Explorationskosten.
Die Ergebnisse verstehen
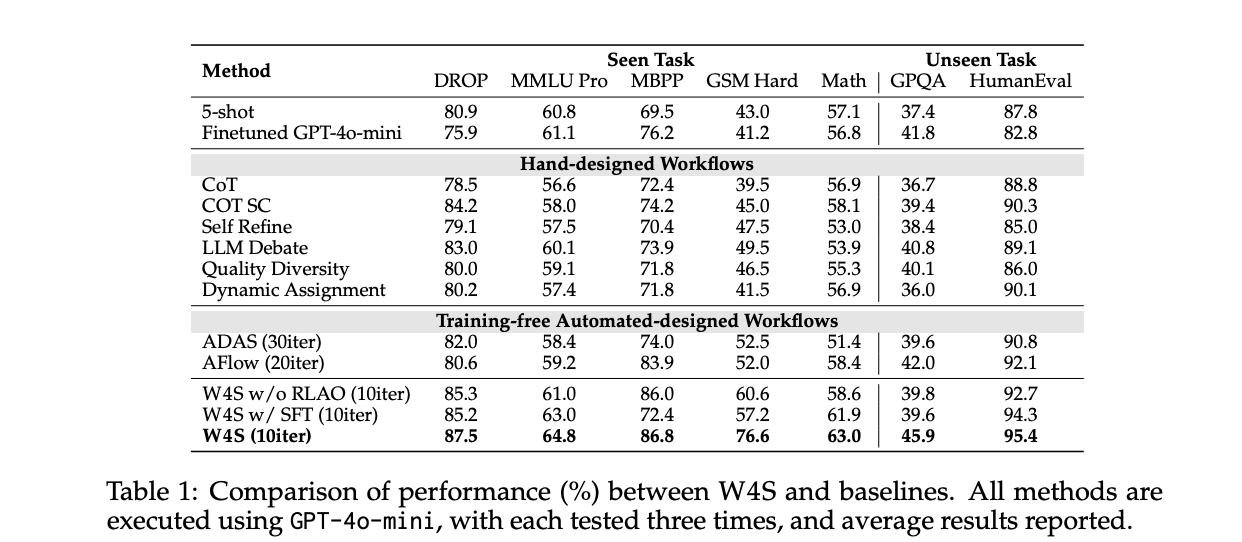
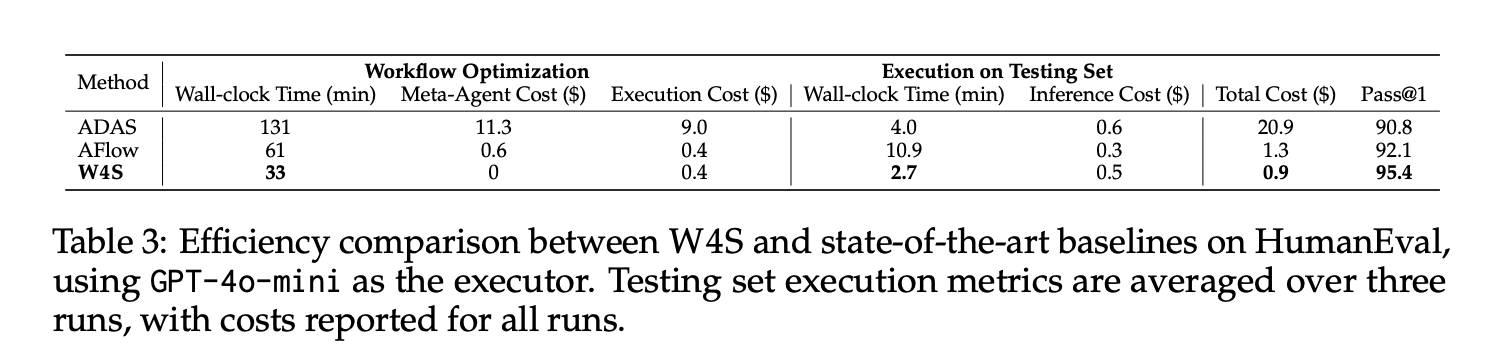
Auf HumanEval mit GPT-4o-mini als Ausführer erreicht W4S Go@1 von 95,4, mit etwa 33 Minuten Workflow-Optimierung, null Meta-Agent-API-Kosten, Optimierungsausführungskosten von etwa 0,4 Greenback und etwa 2,7 Minuten für die Ausführung des Testsatzes bei etwa 0,5 Greenback, additionally insgesamt etwa 0,9 Greenback. Unter demselben Executor folgen AFlow und ADAS dieser Nummer. Die gemeldeten durchschnittlichen Gewinne gegenüber der stärksten automatisierten Basislinie liegen bei 11 Benchmarks zwischen 2,9 % und 24,6 %.
Beim Mathe-Switch wird der Meta-Agent auf GSM Plus und MGSM mit GPT-3.5-Turbo als Executor trainiert und dann auf GSM8K, GSM Laborious und SVAMP evaluiert. Das Papier meldet 86,5 bei GSM8K und 61,8 bei GSM Laborious, beide über automatisierten Basiswerten. Dies weist darauf hin, dass die erlernte Orchestrierung auf verwandte Aufgaben übertragen wird, ohne dass der Ausführende erneut geschult werden muss.
Bei gesehenen Aufgaben mit GPT-4o-mini als Ausführer übertrifft W4S die Ausbildung kostenloser automatisierter Methoden, die keinen Planer erlernen. Die Studie führt auch Ablationen durch, bei denen der Metaagent durch überwachte Feinabstimmung und nicht durch RLAO trainiert wird. Der RLAO-Agent liefert bei gleichem Rechenbudget eine bessere Genauigkeit. Das Forschungsteam berücksichtigt eine GRPO-Basislinie auf einem schwachen 7B-Modell für GSM Laborious, W4S übertrifft es bei begrenzter Rechenleistung.
Iterationsbudgets sind wichtig. Das Forschungsteam legt W4S auf etwa 10 Optimierungsrunden an Haupttabellen fest, während AFlow etwa 20 Runden und ADAS etwa 30 Runden ausführt. Trotz weniger Umdrehungen erreicht W4S eine höhere Genauigkeit. Dies deutet darauf hin, dass erlernte Codeplanung in Kombination mit Validierungsfeedback die Suche effizienter macht.
Wichtige Erkenntnisse
- W4S trainiert einen schwachen 7B-Meta-Agenten mit RLAO, um Python-Workflows zu schreiben, die stärkere Executoren nutzen, modelliert als Multi-Flip-MDP.
- Bei HumanEval mit GPT 4o mini als Executor erreicht W4S Go@1 von 95,4, mit etwa 33 Minuten Optimierung und etwa 0,9 Greenback Gesamtkosten und übertrifft damit automatisierte Baselines unter demselben Executor.
- In 11 Benchmarks verbessert sich W4S gegenüber der stärksten Basislinie um 2,9 % auf 24,6 %, während eine Feinabstimmung des starken Modells vermieden wird.
- Die Methode führt eine iterative Schleife aus, generiert einen Workflow, führt ihn anhand von Validierungsdaten aus und verfeinert ihn dann mithilfe von Suggestions.
- ADAS und AFlow programmieren oder durchsuchen auch Code-Workflows. W4S unterscheidet sich dadurch, dass es einen Planer mit Offline-Verstärkungslernen trainiert.
W4S zielt auf Orchestrierung und nicht auf Modellgewichtungen ab und schult einen 7B-Meta-Agenten, um Workflows zu programmieren, die stärkere Ausführer aufrufen. W4S formalisiert das Workflow-Design als Multi-Flip-MDP und optimiert den Planer mit RLAO mithilfe von Offline-Trajektorien und belohnungsgewichteter Regression. Die gemeldeten Ergebnisse zeigen Go@1 von 95,4 bei HumanEval mit GPT 4o mini, durchschnittliche Zuwächse von 2,9 % bis 24,6 % über 11 Benchmarks und etwa 1 GPU-Stunde Coaching für den Meta-Agenten. Der Rahmen lässt sich intestine mit ADAS und AFlow vergleichen, die Agentenentwürfe oder Codediagramme durchsuchen, während W4S den Ausführenden festlegt und den Planer lernt.
Schauen Sie sich das an Technisches Papier Und GitHub-Repo. Schauen Sie sich gerne bei uns um GitHub-Seite für Tutorials, Codes und Notebooks. Sie können uns auch gerne weiter folgen Twitter und vergessen Sie nicht, bei uns mitzumachen 100.000+ ML SubReddit und Abonnieren Unser Publication. Warten! Bist du im Telegram? Jetzt können Sie uns auch per Telegram kontaktieren.

Michal Sutter ist ein Knowledge-Science-Experte mit einem Grasp of Science in Knowledge Science von der Universität Padua. Mit einer soliden Grundlage in statistischer Analyse, maschinellem Lernen und Datentechnik ist Michal hervorragend darin, komplexe Datensätze in umsetzbare Erkenntnisse umzuwandeln.