
KI-Agenten verändern die Artwork und Weise, wie wir Technologie nutzen. Mithilfe großer Sprachmodelle können sie Fragen beantworten, Aufgaben erledigen und eine Verbindung zu Daten oder APIs herstellen. Dennoch machen sie Fehler, insbesondere bei komplexen, mehrstufigen Arbeiten, deren manuelle Behebung Zeit und Mühe erfordert.
Das neue Agent Lightning-Framework von Microsoft macht dies einfacher. Es trennt die Artwork und Weise, wie ein Agent arbeitet, von der Artwork, wie er lernt, sodass er sich durch seine eigenen Interaktionen in der realen Welt verbessern kann. Sie können jedes vorhandene Chat- oder Automatisierungs-Setup übernehmen und Reinforcement Studying anwenden, um Ihrem Agenten dabei zu helfen, intelligenter zu werden, indem er einfach seine Arbeit erledigt.
Was ist Microsoft Agent Lightning?
Agent Lightning ist ein von Microsoft entwickeltes Open-Supply-Framework. Es wird verwendet, um KI-Agenten zu trainieren und zu verbessern Verstärkungslernen (RL). Die Stärke von Agent Lightning besteht darin, dass es um alle Agenten gewickelt werden kann, die bereits mit einem beliebigen Framework (wie LangChain, OpenAI Brokers SDKAutoGen, CrewAI, LangGraph oder benutzerdefiniertes Python) mit praktisch null Codeänderungen.
Um es technischer zu gestalten, ermöglicht es ein verstärkendes Lerntraining des LLMwird innerhalb von Agenten gehostet, ohne die Kernlogik des Agenten zu ändern. Die Grundidee besteht darin, sich die Ausführung des Agenten als Markov-Entscheidungsprozess vorzustellen. Darin heißt es: „Bei jedem Schritt befindet sich der Agent in einem Zustand, führt eine Aktion aus (LLM-Ausgabe) und erhält eine Belohnung, wenn diese Aktionen zum erfolgreichen Abschluss der Aufgabe führen.“
Der Rahmen besteht aus a Python SDK und ein Trainingsserver. Binden Sie einfach die Logik Ihres Agenten in eine LitAgent-Klasse oder eine ähnliche Schnittstelle ein, definieren Sie, wie seine Ausgabe (die Belohnung) bewertet werden soll, und schon können Sie mit dem Coaching beginnen. Agent Lightning übernimmt die Aufgabe, diese Erfahrungen zu sammeln, stimuliert den Agenten in Ihren hierarchischen RL-Algorithmus (LightningRL) zur Kreditzuweisung und aktualisiert das Modell oder die Eingabeaufforderungsvorlage Ihres Agenten. Nach der Schulung verfügen Sie nun über einen Agenten, dessen Leistung sich verbessert hat.
Warum ist Agent Lightning wichtig?
Herkömmliche Agenten-Frameworks (z. B LangChain, LangGraph, CrewAI oder AutoGen) ermöglichen die Schaffung von KI-Agenten, die Schritt für Schritt argumentieren oder Instruments nutzen können, aber keine Trainingskomponente haben. Diese Agenten führen das Modell einfach anhand statischer Modellparameter oder Eingabeaufforderungen aus, was bedeutet, dass sie nicht aus ihren Begegnungen lernen können. Herausforderungen in der realen Welt sind bis zu einem gewissen Grad komplex und erfordern ein gewisses Maß an Anpassungsfähigkeit. Agent Lightning behebt dieses Drawback und bringt Lernen in die Agent-Pipeline.
Agent Lightning schließt diese erwartete Lücke durch die Implementierung einer automatisierten Optimierungspipeline für Agenten. Dies geschieht durch die Kraft des verstärkenden Lernens, um die Richtlinien der Agenten auf der Grundlage von Feedbacksignalen zu aktualisieren. Ganz einfach: Ihre Agenten lernen jetzt aus den Erfolgen und Misserfolgen Ihrer Agenten und erzielen möglicherweise zuverlässigere Ergebnisse.
Wie funktioniert Agent Lightning?
Innerhalb des Server-Shoppers verwendet Agent Lightning einen RL-Algorithmus, der darauf ausgelegt ist, Aufgaben und Optimierungsvorschläge zu generieren; Dazu gehören entweder die neuen Eingabeaufforderungen oder Modellgewichte. Nun werden Aufgaben von einem Runner ausgeführt, der die Aktionen und Endbelohnungen des Agenten sammelt und diese Daten an den Algorithmus zurückgibt. Diese Rückkopplungsschleife ermöglicht es dem Agenten, seine Eingabeaufforderungen oder Gewichtungen im Laufe der Zeit weiter zu verfeinern, indem er eine Funktion namens „Automatische Zwischenbelohnung‚, das kleinere, sofortige Belohnungen für erfolgreiche Zwischenaktionen ermöglicht, um den Lernprozess zu beschleunigen.
Agent Lightning behandelt den Agentenbetrieb im Wesentlichen als einen Zyklus: Der Standing ist sein aktueller Kontext; Die Aktion ist der nächste Schritt und die Belohnung ist der Indikator für den Erfolg der Aufgabe. Durch die Gestaltung von Standing-Aktion-Belohnungs-Übergängen kann Agent Lightning letztendlich die Schulung für jede Artwork von Agent erleichtern.
Agent Lightning verwendet ein Agent-Disaggregation-Design; dieses getrennte Lernen von der Ausführung. Der Server ist für die Aktualisierung und Optimierung verantwortlich, und der Consumer ist für die Nutzung realer Aufgaben und die Berichterstattung über Ergebnisse verantwortlich. Die Aufgabenteilung ermöglicht es dem Agenten, seine Aufgabe effizient zu erfüllen und gleichzeitig die Leistung durch RL zu verbessern.
Notiz: Agent Lightning verwendet LightningRL. Es handelt sich um ein hierarchisches RL-System, das komplexe mehrstufige Verhaltensweisen von Agenten für das Coaching aufschlüsselt. LightningRL kann auch mehrere Agenten, komplexe Device-Nutzung und verzögertes Suggestions unterstützen.
Schritt-für-Schritt-Anleitung: Schulung eines Agenten mit Microsoft Agent Lightning
In diesem Abschnitt behandeln wir eine exemplarische Vorgehensweise zum Trainieren eines SQL-Agenten mit Agent-Lightning und demonstrieren die Integration der Hauptkomponenten des Methods: eines LangGraph-basierten SQL-Agenten, des VERL RL-Frameworks und des Trainers zur Steuerung von Coaching und Debugging.
Das Befehlszeilenbeispiel (instance/spider/train_sql_agent.py) bietet ein vollständig ausführbares Beispiel, aber in diesem Dokument geht es darum, die Architektur und den Workflow zu verstehen, damit Entwickler sich wohl fühlen können, in ihrem Anwendungsfall einzufrieren.
Agentenarchitektur
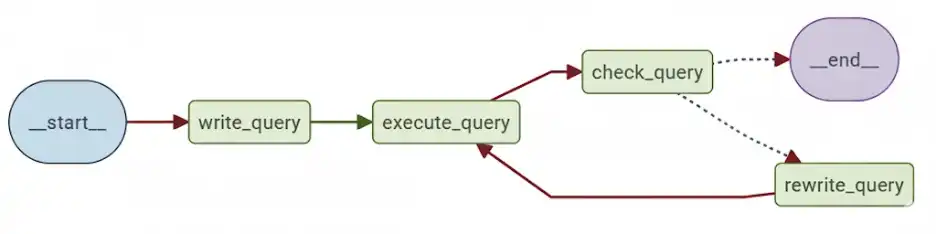
Agent-Lightning arbeitet nahtlos mit Frameworks wie AutoGen, CrewAI, LangGraph, OpenAI Brokers SDK und anderen benutzerdefinierten Python-Logiken zusammen. In diesem Beispiel definiert LangGraph einen zyklischen Workflow, der modelliert, wie ein Datenanalyst iterativ SQL-Abfragen schreibt und korrigiert:
Es gibt vier Funktionsstufen:
- write_query: Nimmt die Frage des Benutzers auf und generiert aus der Textfrage eine erste SQL-Abfrage.
- execute_query: Führt die generierte Abfrage in der Zieldatenbank aus.
- check_query: Verwendet eine Validierungsaufforderung (CHECK_QUERY_PROMPT), um das Ergebnis zu validieren.
- rewrite_query: Wenn es Probleme gibt, schreiben Sie die Abfrage neu.
Die Schleife wird fortgesetzt, bis entweder die Abfrage validiert wird oder eine maximale Iterationsanzahl (max_turns) erreicht ist. Reinforcement Studying optimiert die write_query Und rewrite_query Stufen.
Erstellen des LangGraph-Agenten
Um den Code modular und wartbar zu halten, definieren Sie Ihre LangGraph-Logik separat mit einer Builder-Funktion, wie gezeigt:
from langgraph import StateGraph
def build_langgraph_sql_agent(
database_path: str,
openai_base_url: str,
mannequin: str,
sampling_parameters: dict,
max_turns: int,
truncate_length: int
):
# Step 1: Outline the LangGraph workflow
builder = StateGraph()
# Step 2: Add agent nodes for every step
builder.add_node("write_query")
builder.add_node("execute_query")
builder.add_node("check_query")
builder.add_node("rewrite_query")
# Step 3: Join the workflow edges
builder.add_edge("__start__", "write_query")
builder.add_edge("write_query", "execute_query")
builder.add_edge("execute_query", "check_query")
builder.add_edge("check_query", "rewrite_query")
builder.add_edge("rewrite_query", "__end__")
# Step 4: Compile the graph
return builder.compile().graph()Dadurch wird Ihre LangGraph-Logik von möglichen zukünftigen Updates von Agent-Lightning getrennt und so die Lesbarkeit und Wartbarkeit verbessert.
Überbrückung von LangGraph und Agent-Lightning
Der LitSQLAgent Die Klasse dient als Verbindung zwischen LangGraph und Agent-Lightning. Es erstreckt sich agl.LitAgentsodass der Runner bei jedem Rollout gemeinsam genutzte Ressourcen (wie LLMs) verwalten kann.
import agentlightning as agl
class LitSQLAgent(agl.LitAgent(dict)):
def __init__(self, max_turns: int, truncate_length: int):
tremendous().__init__()
self.max_turns = max_turns
self.truncate_length = truncate_length
def rollout(self, activity: dict, sources: agl.NamedResources, rollout: agl.Rollout) -> float:
# Step 1: Load shared LLM useful resource
llm: agl.LLM = sources("main_llm")
# Step 2: Construct LangGraph agent dynamically
agent = build_langgraph_sql_agent(
database_path="sqlite:///" + activity("db_id"),
openai_base_url=llm.get_base_url(rollout.rollout_id, rollout.try.attempt_id),
mannequin=llm.mannequin,
sampling_parameters=llm.sampling_parameters,
max_turns=self.max_turns,
truncate_length=self.truncate_length,
)
# Step 3: Invoke agent
outcome = agent.invoke({"query": activity("query")}, {
"callbacks": (self.tracer.get_langchain_handler()),
"recursion_limit": 100,
})
# Step 4: Consider question to generate reward
reward = evaluate_query(
outcome("question"), activity("ground_truth"), activity("db_path"), raise_on_error=False
)
return rewardNotiz: Der „main_llm„Ressourcenschlüssel ist eine kooperative Vereinbarung, die zwischen dem Agenten und VERL besteht, um bei jedem Rollout im Kontext des Dienstes Zugriff auf den richtigen Endpunkt zu ermöglichen.
Belohnungssignal und Bewertung
Der evaluate_query Die Funktion definiert Ihren Belohnungsmechanismus für das RL-Coaching. Jede Aufgabe im Spider-Datensatz enthält eine Frage in natürlicher Sprache, ein Datenbankschema und eine Floor-Reality-SQL-Abfrage. Der Belohnungsmechanismus vergleicht die vom Modell erstellte SQL-Abfrage mit der Referenz-SQL-Abfrage:
def evaluate_query(predicted_query, ground_truth_query, db_path, raise_on_error=False):
result_pred = run_sql(predicted_query, db_path)
result_true = run_sql(ground_truth_query, db_path)
return 1.0 if result_pred == result_true else 0.0Notiz: Der Agent darf während des Trainings niemals Floor-Reality-Abfragen sehen, da sonst Informationen verloren gehen.
Konfigurieren von VERL für Reinforcement Studying
VERL ist das RL-Backend des Agenten. Die Konfiguration wird genau wie ein Python-Wörterbuch definiert, in das Sie den Algorithmus, die Modelle, Rollout-Parameter und Trainingsoptionen eingeben. Hier ist eine einfache Konfiguration:
verl_config = {
"algorithm": {"adv_estimator": "grpo", "use_kl_in_reward": False},
"knowledge": {
"train_batch_size": 32,
"max_prompt_length": 4096,
"max_response_length": 2048,
},
"actor_rollout_ref": {
"rollout": {"identify": "vllm", "n": 4, "multi_turn": {"format": "hermes"}},
"actor": {"ppo_mini_batch_size": 32, "optim": {"lr": 1e-6}},
"mannequin": {"path": "Qwen/Qwen2.5-Coder-1.5B-Instruct"},
},
"coach": {
"n_gpus_per_node": 1,
"val_before_train": True,
"test_freq": 32,
"save_freq": 64,
"total_epochs": 2,
},
}Dies ist analog zu dem Befehl, den Sie in der CLI hätten ausführen können:
python3 -m verl.coach.main_ppo
algorithm.adv_estimator=grpo
knowledge.train_batch_size=32
actor_rollout_ref.mannequin.path=Qwen/Qwen2.5-Coder-1.5B-InstructOrchestrierung des Trainings mit dem Coach
Der Coach ist der hochrangige Koordinator, der alle Teilagenten, RL-Algorithmen, Datensätze und verteilten Läufer verbindet.
import pandas as pd
import agentlightning as agl
# Step 1: Initialize agent and algorithm
agent = LitSQLAgent(max_turns=3, truncate_length=1024)
algorithm = agl.VERL(verl_config)
# Step 2: Initialize Coach
coach = agl.Coach(
n_runners=10,
algorithm=algorithm,
adapter=rewrite" # Optimize each question levels
)
# Step 3: Load dataset
train_data = pd.read_parquet("knowledge/train_spider.parquet").to_dict("information")
val_data = pd.read_parquet("knowledge/test_dev_500.parquet").to_dict("information")
# Step 4: Practice
coach.match(agent, train_dataset=train_data, val_dataset=val_data)Das passiert hinter den Sinnen:
- VERL startet einen OpenAI-kompatiblen Proxy, sodass Arbeit verteilt werden kann, ohne die Anforderung von OpenAI zu implementieren.
- Der Coach erstellt 10 Läufer, die gleichzeitig ausgeführt werden.
- Jeder Läufer ruft die
rolloutMethode, sammelt Spuren und sendet Belohnungen zurück, um die Richtlinie zu aktualisieren.
Debuggen des Agenten mit coach.dev()
Bevor mit dem vollständigen RL-Coaching begonnen wird, wird empfohlen, die gesamte Rohrleitung trocken laufen zu lassen, um Verbindungen und Leiterbahnen zu überprüfen.
coach = agl.Coach(
n_workers=1,
initial_resources={
"main_llm": agl.LLM(
endpoint=os.environ("OPENAI_API_BASE"),
mannequin="gpt-4.1-nano",
sampling_parameters={"temperature": 0.7},
)
},
)
# Load a small subset for dry-run
import pandas as pd
dev_data = pd.read_parquet("knowledge/test_dev_500.parquet").to_dict("information")(:10)
# Run dry-run mode
coach.dev(agent, dev_dataset=dev_data)Dies bestätigt den gesamten LangGraph-Kontrollfluss, die Datenbankverbindungen und die Logik der Belohnung, bevor Sie mit dem Coaching für lange GPU-Stunden fortfahren.
Ausführen des vollständigen Beispiels
Um die Umgebung einzurichten, installieren Sie Abhängigkeiten (z. B. mit pip set up -r necessities.txt) und führen Sie das vollständige Trainingsskript aus:
# Step 1: Set up dependencies
pip set up "agentlightning(verl)" langchain pandas gdown
# Step 2: Obtain Spider dataset
cd examples/spider
gdown --fuzzy https://drive.google.com/file/d/1oi9J1jZP9TyM35L85CL3qeGWl2jqlnL6/view
unzip -q spider-data.zip -d knowledge && rm spider-data.zip
# Step 3: Launch coaching
python train_sql_agent.py qwen # Qwen-2.5-Coder-1.5B
# or
python train_sql_agent.py llama # LLaMA 3.2 1BWenn Sie Modelle verwenden, die auf Hugging Face gehostet werden, exportieren Sie unbedingt Ihr Token:
export HF_TOKEN="your_huggingface_token" Debuggen ohne VERL
Wenn Sie die Agentenlogik ohne Reinforcement Studying validieren möchten, können Sie den integrierten Debug-Helfer verwenden:
export OPENAI_API_BASE="https://api.openai.com/v1"
export OPENAI_API_KEY="your_api_key_here"
cd examples/spider
python sql_agent.pyDadurch können Sie das ausführen SQL-Agent mit Ihrem aktuellen LLM-Endpunkt, um zu bestätigen, dass die Abfrage ausgeführt wurde und der Kontrollfluss wie erwartet funktioniert hat.
Bewertungsergebnisse
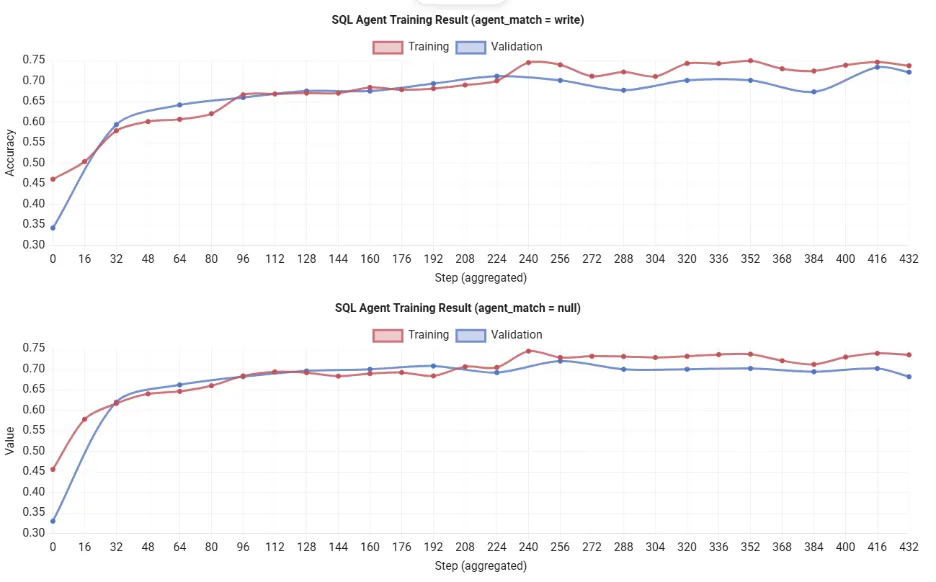
Notiz: Python ausführen train_sql_agent.py qwen auf einer einzelnen 80-GB-GPU ist normalerweise nach etwa 12 Stunden fertig. Sie werden feststellen, dass der Nutzen der Schulung stetig steigt, was darauf hindeutet, dass der Agent seinen SQL-Generierungsprozess im Laufe der Zeit verbessert. Aufgrund der Ressourcenbeschränkungen habe ich daher die in der offiziellen Dokumentation gezeigten Ergebnisse verwendet.
Wann und wo Agent Lightning eingesetzt werden sollte
Nehmen wir in praktischen Situationen an, Sie haben einen LLM-basierten Agenten, der eine wichtige Rolle in einer Anwendung spielt (Chatbot für den Kundensupport, automatisierter Codierungsassistent usw.) und Sie beabsichtigen, ihn zu verfeinern. Agent Lightning ist ein guter Kandidat. Es wurde bereits gezeigt, dass das Framework bei anderen Aufgaben funktioniert, beispielsweise bei der Generierung von SQL-Abfragen. In solchen und anderen ähnlichen Situationen hat Agent Lightning einen bereits vorhandenen Agenten genommen und ihn durch RL oder Immediate-Optimierung weiter optimiert, was zu genaueren Antworten führte.
- Wenn Sie möchten, dass ein KI-Agent durch Versuch und Irrtum lernt, sollten Sie Agent Lightning verwenden. Es ist für mehrstufige logische Situationen mit klaren Signalen konzipiert, die über Erfolg oder Misserfolg entscheiden.
- Beispielsweise kann Agent Lightning einen Bot, der Datenbankabfragen generiert, verbessern, indem er das beobachtete Suggestions aus der Ausführung zum Lernen nutzt. Das Lernmodell ist auch für Chatbots, virtuelle Assistenten, Spielagenten und Allzweckagenten nützlich, die Instruments oder APIs nutzen.
- Das Agent Lightning-Framework ist agentenunabhängig. Es läuft je nach Bedarf auf einem Commonplace-PC oder Server, sodass Sie Modelle bei Bedarf auf Ihrem eigenen Laptop computer oder in der Cloud trainieren können.
Abschluss
Microsoft Agent Lightning ist ein beeindruckender neuer Mechanismus zur Verbesserung der Intelligenz von KI-Agenten. Anstatt einen Agenten als festes Objekt oder Codestück zu betrachten, ermöglicht Agent Lightning eine Trainingsschleife, damit Ihr Agent aus Erfahrungen lernen kann. Durch die Entkopplung von Coaching und Ausführung kann jeder Agenten-Workflow ohne Codeänderungen optimiert werden.
Dies bedeutet, dass Sie den Arbeitsablauf eines Agenten ganz einfach verbessern können, unabhängig davon, ob es sich um einen benutzerdefinierten Agenten, einen LangChain-Bot, CrewAI, LangGraph, AutoGen oder einen spezifischeren Agent handelt OpenAI SDK-Agentindem der Reinforcement-Studying-Mechanismus mit Agent Lightning umgeschaltet wird. In der Praxis ermöglichen Sie Ihren Agenten, ihre eigenen Daten intelligenter zu nutzen.
Häufig gestellte Fragen
A: Es handelt sich um ein Open-Supply-Framework von Microsoft, das KI-Agenten mithilfe von Reinforcement Studying trainiert, ohne ihre Kernlogik oder Arbeitsabläufe zu ändern.
A. Es ermöglicht Agenten, aus echtem Aufgaben-Suggestions zu lernen, indem sie Verstärkungslernen nutzen und Eingabeaufforderungen oder Modellgewichtungen kontinuierlich verfeinern, um eine bessere Leistung zu erzielen.
A. Ja, es lässt sich mit minimalen Codeänderungen problemlos in LangChain, AutoGen, CrewAI, LangGraph und benutzerdefinierte Python-Agenten integrieren.
Hallo! Ich bin Vipin, ein leidenschaftlicher Fanatic für Datenwissenschaft und maschinelles Lernen mit fundierten Kenntnissen in Datenanalyse, Algorithmen für maschinelles Lernen und Programmierung. Ich verfüge über praktische Erfahrung in der Modellerstellung, der Verwaltung unübersichtlicher Daten und der Lösung realer Probleme. Mein Ziel ist es, datengesteuerte Erkenntnisse anzuwenden, um praktische Lösungen zu schaffen, die zu Ergebnissen führen. Ich bin bestrebt, meine Fähigkeiten in einer kollaborativen Umgebung einzubringen und gleichzeitig weiterhin in den Bereichen Knowledge Science, maschinelles Lernen und NLP zu lernen und mich weiterzuentwickeln.
Melden Sie sich an, um weiterzulesen und von Experten kuratierte Inhalte zu genießen.