Laut LexisNexis verlieren Banken jedes Jahr mehr als 442 Milliarden US-Greenback durch Betrug Studie zu den wahren Kosten von Betrug. Herkömmliche regelbasierte Systeme können nicht mithalten Gartner berichtet dass sie mehr als 50 % der neuen Betrugsmuster übersehen, da sich Angreifer schneller anpassen, als die Regeln aktualisiert werden können. Gleichzeitig nehmen die Falschmeldungen weiter zu. Aite-Novarica fanden heraus, dass quick 90 % der abgelehnten Transaktionen tatsächlich legitim sind, was Kunden frustriert und die Betriebskosten erhöht. Auch Betrug wird immer koordinierter. Feedzai verzeichnete innerhalb eines Jahres einen Anstieg der Aktivitäten von Betrugsringen um 109 %.
Um an der Spitze zu bleiben, benötigen Banken Modelle, die die Beziehungen zwischen Benutzern, Händlern, Geräten und Transaktionen verstehen. Aus diesem Grund entwickeln wir ein Betrugserkennungssystem der nächsten Era, das auf Graph Neural Networks und Neo4j basiert. Anstatt Transaktionen als isolierte Ereignisse zu behandeln, analysiert dieses System das gesamte Netzwerk und deckt komplexe Betrugsmuster auf, die herkömmliches ML oft übersieht.
Warum scheitert die herkömmliche Betrugserkennung?
Versuchen wir zunächst zu verstehen, warum wir auf diesen neuen Ansatz umsteigen müssen. Die meisten Betrugserkennungssysteme verwenden traditionelle Methoden ML Modelle, die die zu analysierenden Transaktionen isolieren.
Die regelbasierte Falle
Nachfolgend finden Sie ein sehr standardmäßiges, regelbasiertes Betrugserkennungssystem:
def detect_fraud(transaction):
if transaction.quantity > 1000:
return "FRAUD"
if transaction.hour in (0, 1, 2, 3):
return "FRAUD"
if transaction.location != person.home_location:
return "FRAUD"
return "LEGITIMATE"
Die Probleme hier sind ziemlich einfach:
Manchmal werden legitime Einkäufe mit hohem Wert gekennzeichnet (z. B. wenn Ihr Kunde einen Laptop bei Finest Purchase kauft).
Betrügerische Akteure passen sich schnell an – sie beschränken Einkäufe nur auf weniger als 1.000 US-Greenback
Kein Kontext – ein Geschäftsreisender, der beruflich unterwegs ist und Einkäufe tätigt, wird daher markiert
Es gibt keine neuen Erkenntnisse – das System verbessert sich nicht durch die Identifizierung neuer Betrugsmuster
Warum scheitert selbst traditionelles ML?
Zufälliger Wald und XGBoost waren besser, analysieren aber immer noch jede Transaktion einzeln. Sie merken es vielleicht nicht! Benutzer_A, Benutzer_BUnd Benutzer_C sind alle kompromittierte Konten, sie werden alle von einem betrügerischen Ring kontrolliert, sie alle scheinen innerhalb weniger Minuten denselben fragwürdigen Händler ins Visier zu nehmen.
Wichtige Erkenntnis: Betrug ist relational. Betrüger agieren nicht alleine, sie agieren als Netzwerke. Sie teilen Ressourcen. Und ihre Muster werden erst sichtbar, wenn sie über Beziehungen zwischen Entitäten hinweg beobachtet werden.
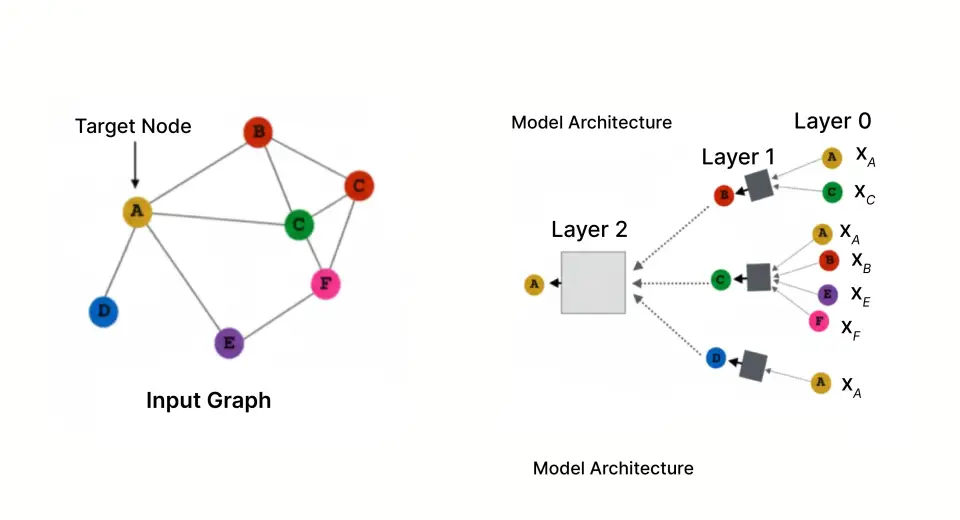
Geben Sie Graph Neural Networks ein
Graph Neural Networks wurden speziell für das Lernen aus vernetzten Daten entwickelt und analysieren die gesamte Diagrammstruktur, in der die Transaktionen eine Beziehung zwischen Benutzern und Händlern bilden und zusätzliche Knoten Geräte, IP-Adressen und mehr darstellen würden, anstatt jeweils eine Transaktion zu analysieren.
Die Macht der Graphdarstellung
In unserem Framework stellen wir das Betrugsproblem mit einer Graphenstruktur dar, mit den folgenden Knoten und Kanten:
Knoten:
Benutzer (der Kunde, der die Kreditkarte besitzt)
Händler (das Unternehmen, das Zahlungen akzeptiert)
Transaktionen (Einzelkäufe)
Kanten:
Benutzer → Transaktion (wer hat den Kauf durchgeführt)
Transaktion → Händler (bei dem der Kauf stattgefunden hat)
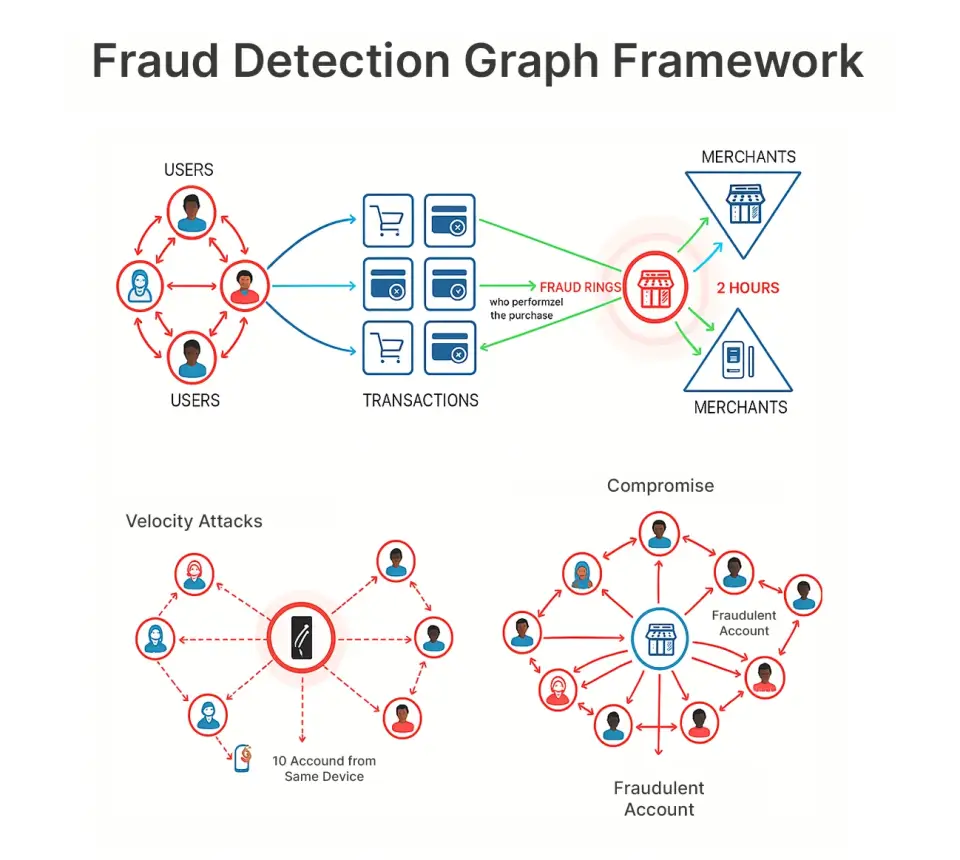
Diese Darstellung ermöglicht es uns, Muster zu beobachten wie:
Betrugsringe: 15 kompromittierte Konten, die alle auf denselben Händler abzielen, innerhalb von 2 Stunden
Kompromittierter Händler: Ein seriös aussehender Händler lockt plötzlich nur noch Betrüger an
Geschwindigkeitsangriffe: Dasselbe Gerät führt Käufe von 10 verschiedenen Konten aus
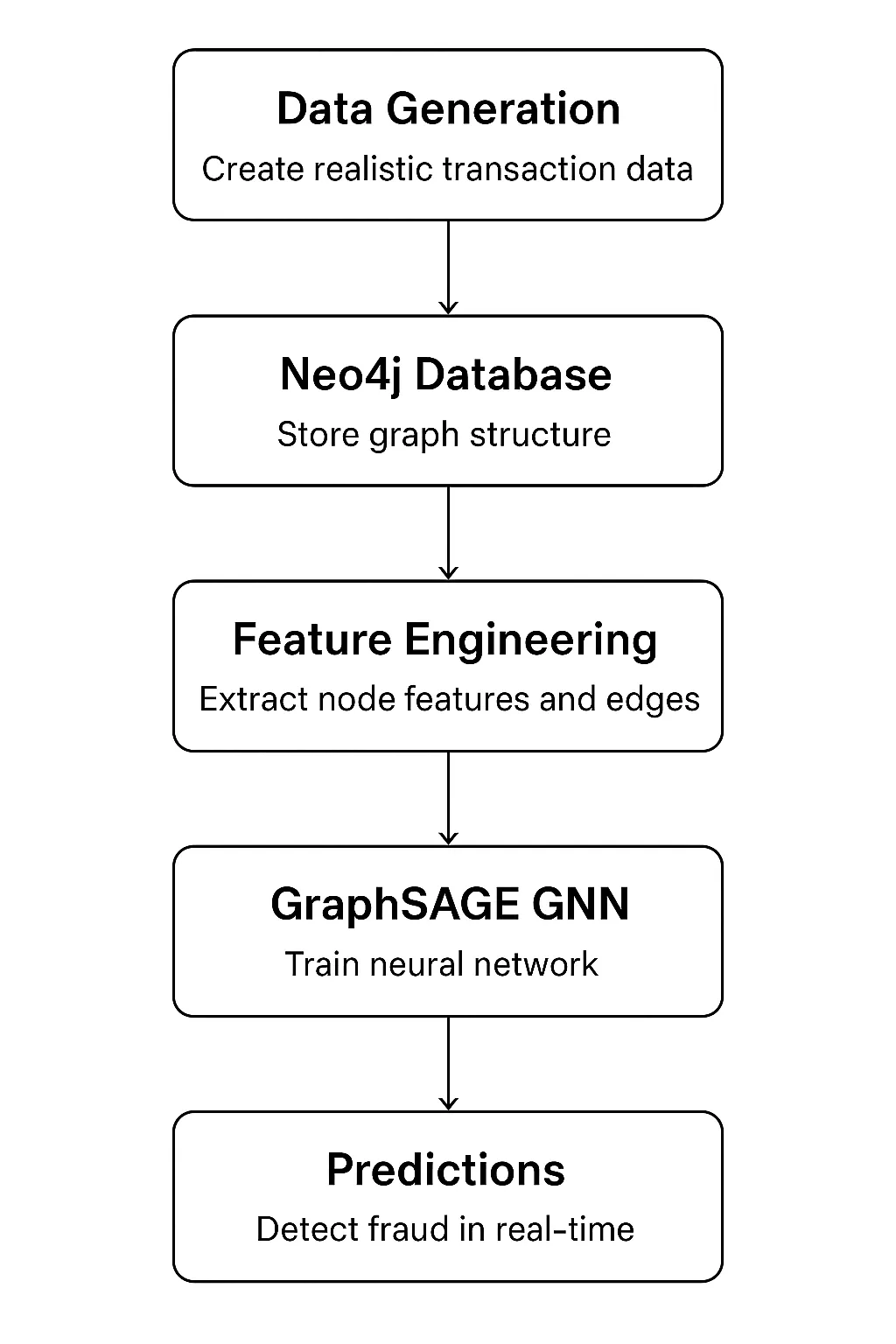
Aufbau des Programs: Architekturübersicht
Unser System besteht aus fünf Hauptkomponenten, die eine vollständige Pipeline bilden:
Technologie-Stack:
Neo4j 5.x: Es dient der Speicherung und Abfrage von Diagrammen
PyTorch 2.x: Es wird mit verwendet PyTorch Geometrisch für die GNN-Implementierung
Python 3.9+: Gebrauchtfür die gesamte Pipeline
Pandas/NumPy: Es istzur Datenmanipulation
Umsetzung: Schritt für Schritt
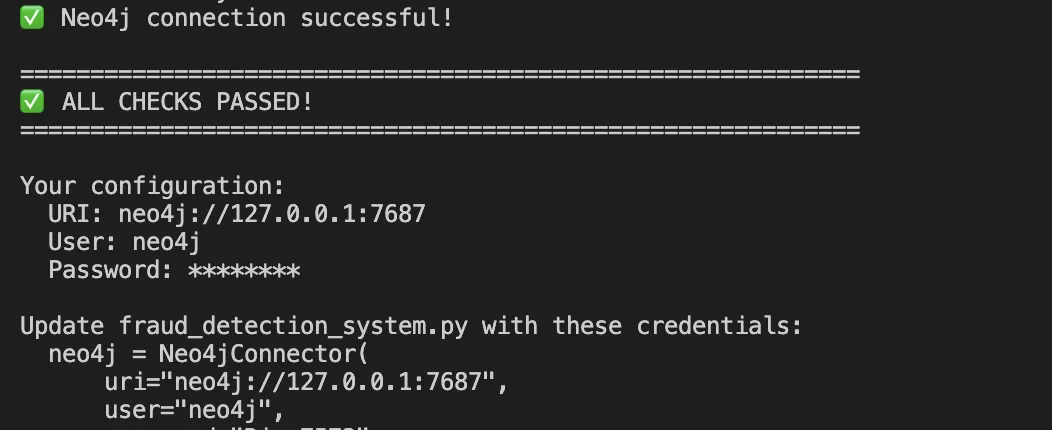
Schritt 1: Daten in Neo4j modellieren
Neo4j ist eine native Diagrammdatenbank, die Beziehungen als erstklassige Bürger speichert. So modellieren wir unsere Entitäten:
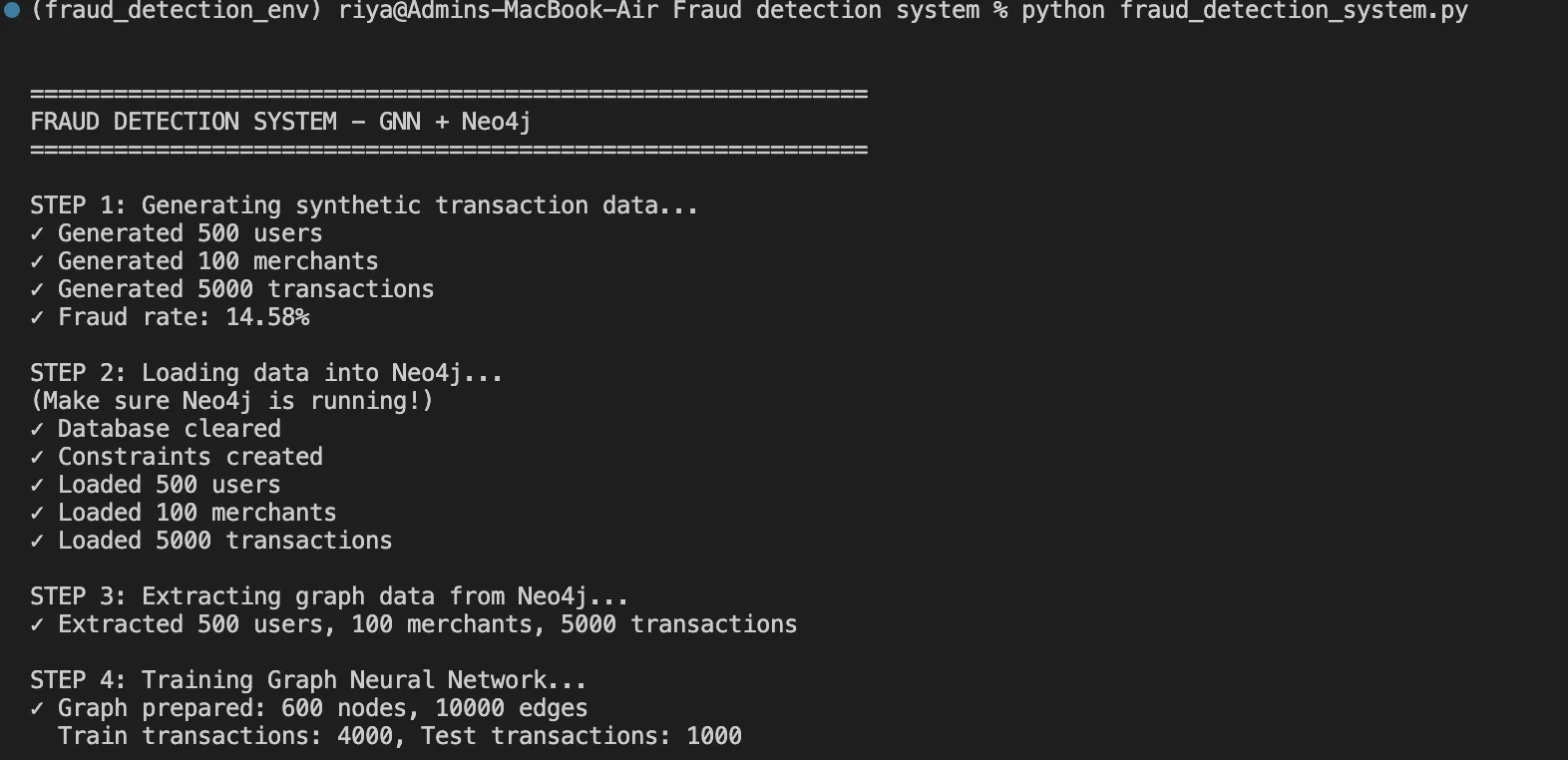
Diese Funktion hilft uns dabei, 5.000 Transaktionen mit einer Betrugsrate von 15 % zu generieren, einschließlich realistischer Muster wie Betrugsringe und zeitbasierte Anomalien.
Schritt 3: Aufbau des neuronalen GraphSAGE-Netzwerks
Wir haben uns für die GraphSAGE- oder Graph Pattern and Combination-Methode entschieden GNN-Architektur da es nicht nur intestine skaliert, sondern auch neue Knoten ohne Umschulung verarbeitet. So werden wir es umsetzen:
import torch
import torch.nn as nn
import torch.nn.useful as F
from torch_geometric.nn import SAGEConv
class FraudGNN(nn.Module):
def __init__(self, num_features, hidden_dim=64, num_classes=2):
tremendous(FraudGNN, self).__init__()
# Three graph convolutional layers
self.conv1 = SAGEConv(num_features, hidden_dim)
self.conv2 = SAGEConv(hidden_dim, hidden_dim)
self.conv3 = SAGEConv(hidden_dim, hidden_dim)
# Classification head
self.fc = nn.Linear(hidden_dim, num_classes)
# Dropout for regularization
self.dropout = nn.Dropout(0.3)
def ahead(self, x, edge_index):
# Layer 1: Combination from 1-hop neighbors
x = self.conv1(x, edge_index)
x = F.relu(x)
x = self.dropout(x)
# Layer 2: Combination from 2-hop neighbors
x = self.conv2(x, edge_index)
x = F.relu(x)
x = self.dropout(x)
# Layer 3: Combination from 3-hop neighbors
x = self.conv3(x, edge_index)
x = F.relu(x)
x = self.dropout(x)
# Classification
x = self.fc(x)
return F.log_softmax(x, dim=1)
Layer 2 wird sich auf 2-Hop-Nachbarn erstrecken (Suche nach Benutzern, die über einen gemeinsamen Händler verbunden sind).
Schicht 3 wird 3-Hop-Nachbarn beobachten (Betrugsringe von Benutzern finden, die über mehrere Händler verbunden sind).
Verwenden Sie Dropout (30 %), um eine Überanpassung an bestimmte Strukturen im Diagramm zu reduzieren
Protokoll von Softmax stellt Wahrscheinlichkeitsverteilungen für legitim vs. betrügerisch bereit
Schritt 4: Function-Engineering
Für ein stabiles Coaching normalisieren wir alle Merkmale auf den Bereich (0, 1):
def prepare_features(customers, retailers):
# Person options (4 dimensions)
user_features = ()
for person in customers:
options = (
person('age') / 100.0, # Age normalized
person('account_age_days') / 3650.0, # Account age (10 years max)
person('credit_score') / 850.0, # Credit score rating normalized
person('avg_transaction_amount') / 1000.0 # Common quantity
)
user_features.append(options)
# Service provider options (padded to match person dimensions)
merchant_features = ()
for service provider in retailers:
options = (
service provider('risk_score'), # Pre-computed threat
0.0, 0.0, 0.0 # Padding
)
merchant_features.append(options)
return torch.FloatTensor(user_features + merchant_features)
Schritt 5: Trainieren des Modells
Hier ist unsere Trainingsschleife:
def train_model(mannequin, x, edge_index, train_indices, train_labels, epochs=100):
optimizer = torch.optim.Adam(
mannequin.parameters(),
lr=0.01, # Studying fee
weight_decay=5e-4 # L2 regularization
)
for epoch in vary(epochs):
mannequin.practice()
optimizer.zero_grad()
# Ahead move
out = mannequin(x, edge_index)
# Calculate loss on coaching nodes solely
loss = F.nll_loss(out(train_indices), train_labels)
# Backward move
loss.backward()
optimizer.step()
if epoch % 10 == 0:
print(f"Epoch {epoch:3d} | Loss: {loss.merchandise():.4f}")
return mannequin
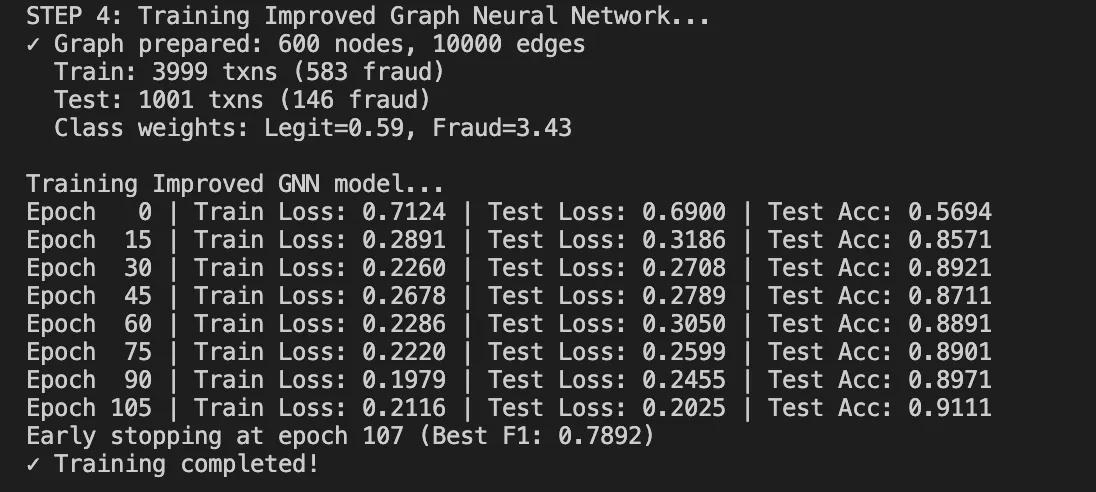
Trainingsdynamik:
Es beginnt mit einem Verlust von etwa 0,80 (zufällige Initialisierung).
Nach 100 Epochen konvergiert es auf 0,33–0,36
Für unseren Datensatz benötigt die CPU etwa 60 Sekunden
Ergebnisse: Was wir erreicht haben
Nachdem wir die komplette Pipeline ausgeführt haben, sind hier unsere Ergebnisse:
Leistungskennzahlen
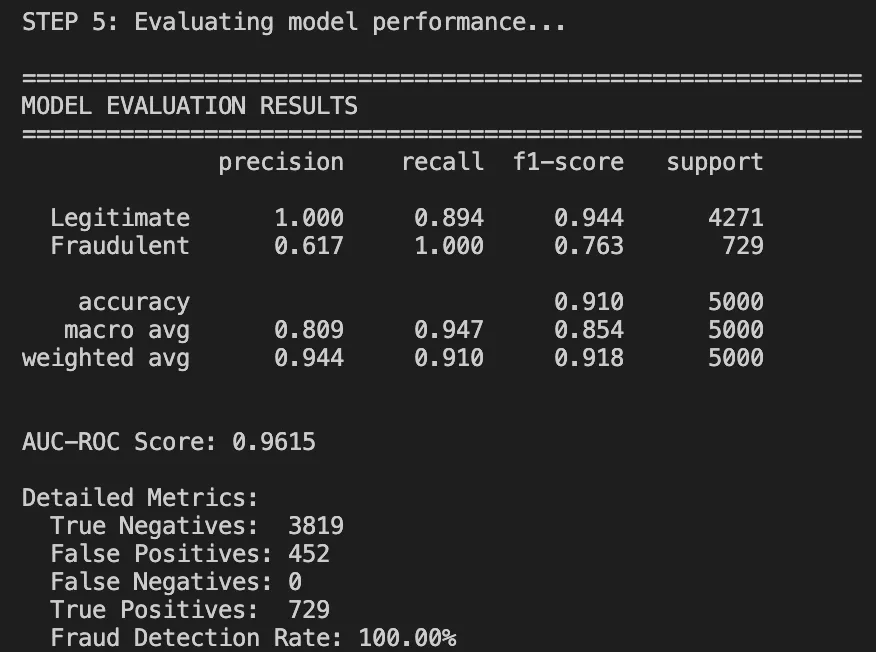
Klassifizierungsbericht:
Die Ergebnisse verstehen
Versuchen wir, die Ergebnisse aufzuschlüsseln, um sie besser zu verstehen.
Was intestine funktioniert hat:
91 % Gesamtgenauigkeit: Sie ist viel höher als die regelbasierte Genauigkeit (70 %).
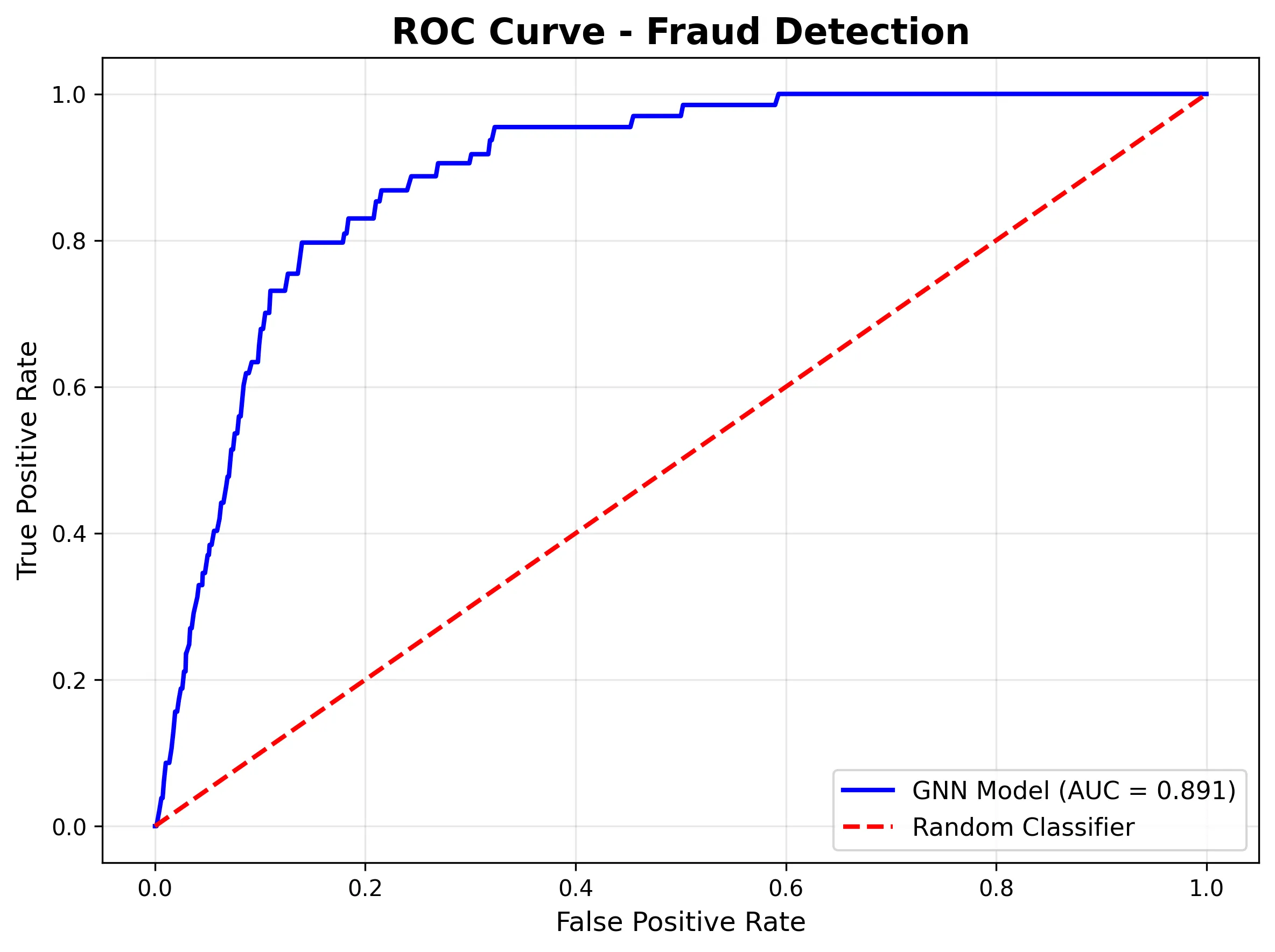
AUC-ROC von 0,96: Zeigt eine sehr gute Klassenunterscheidung.
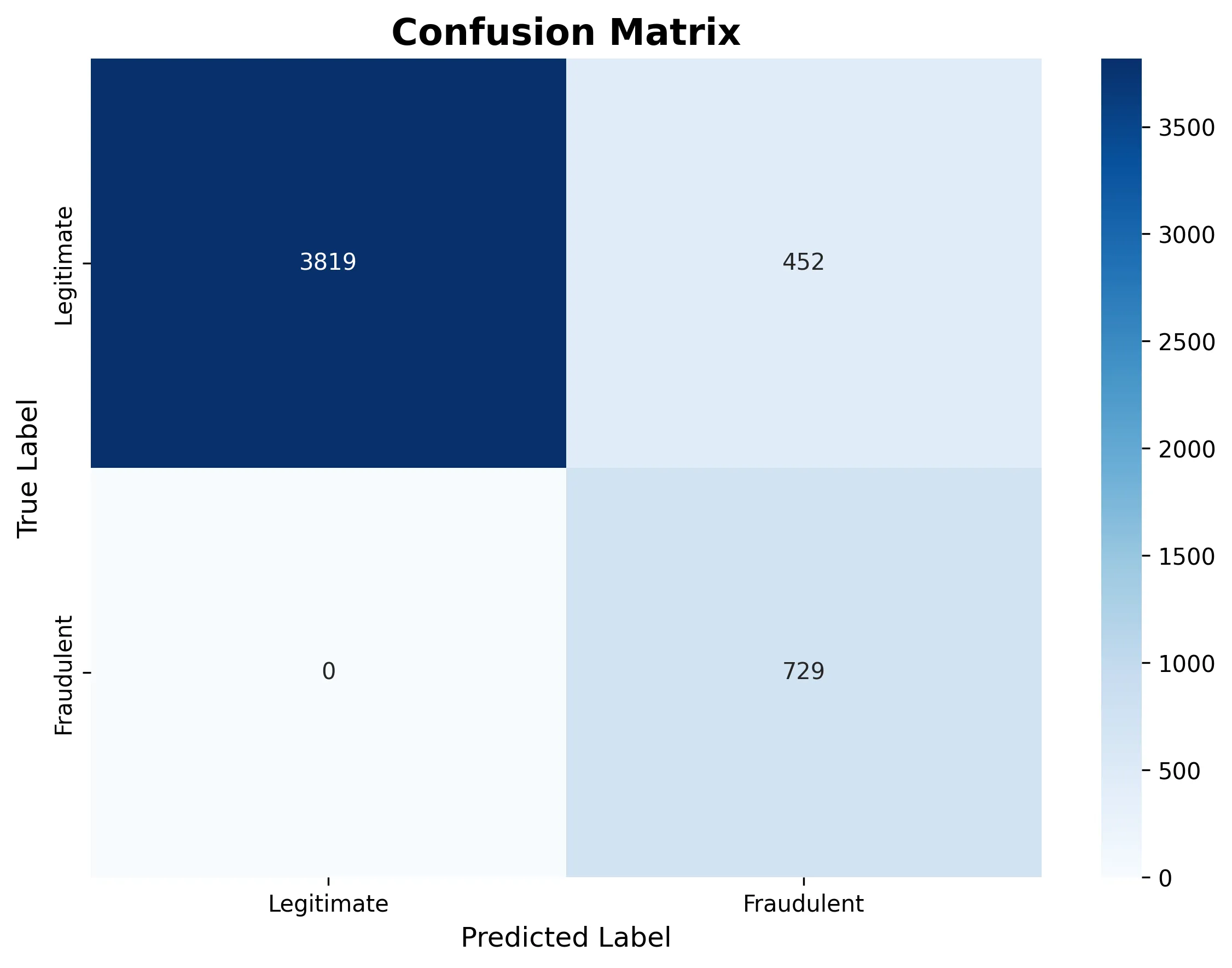
Perfekte Erinnerung an Rechtsgeschäfte: Wir blockieren keine guten Benutzer.
Was muss verbessert werden:
Die Betrügereien hatten eine Genauigkeit von Null. Das Modell ist in diesem Durchlauf einfach zu konservativ.
Dies kann passieren, weil das Modell einfach mehr Betrugsbeispiele benötigt oder der Schwellenwert angepasst werden muss.
Visualisierungen erzählen die Geschichte
Die folgende Verwirrungsmatrix zeigt, wie das Modell in diesem bestimmten Lauf alle Transaktionen als legitim klassifizierte:
Die ROC-Kurve zeigt eine starke Unterscheidungsfähigkeit (AUC = 0,961), was bedeutet, dass das Modell Betrugsmuster lernt, selbst wenn der Schwellenwert angepasst werden muss:
Analyse von Betrugsmustern
Die von uns durchgeführte Analyse konnte eindeutige Tendencies aufzeigen:
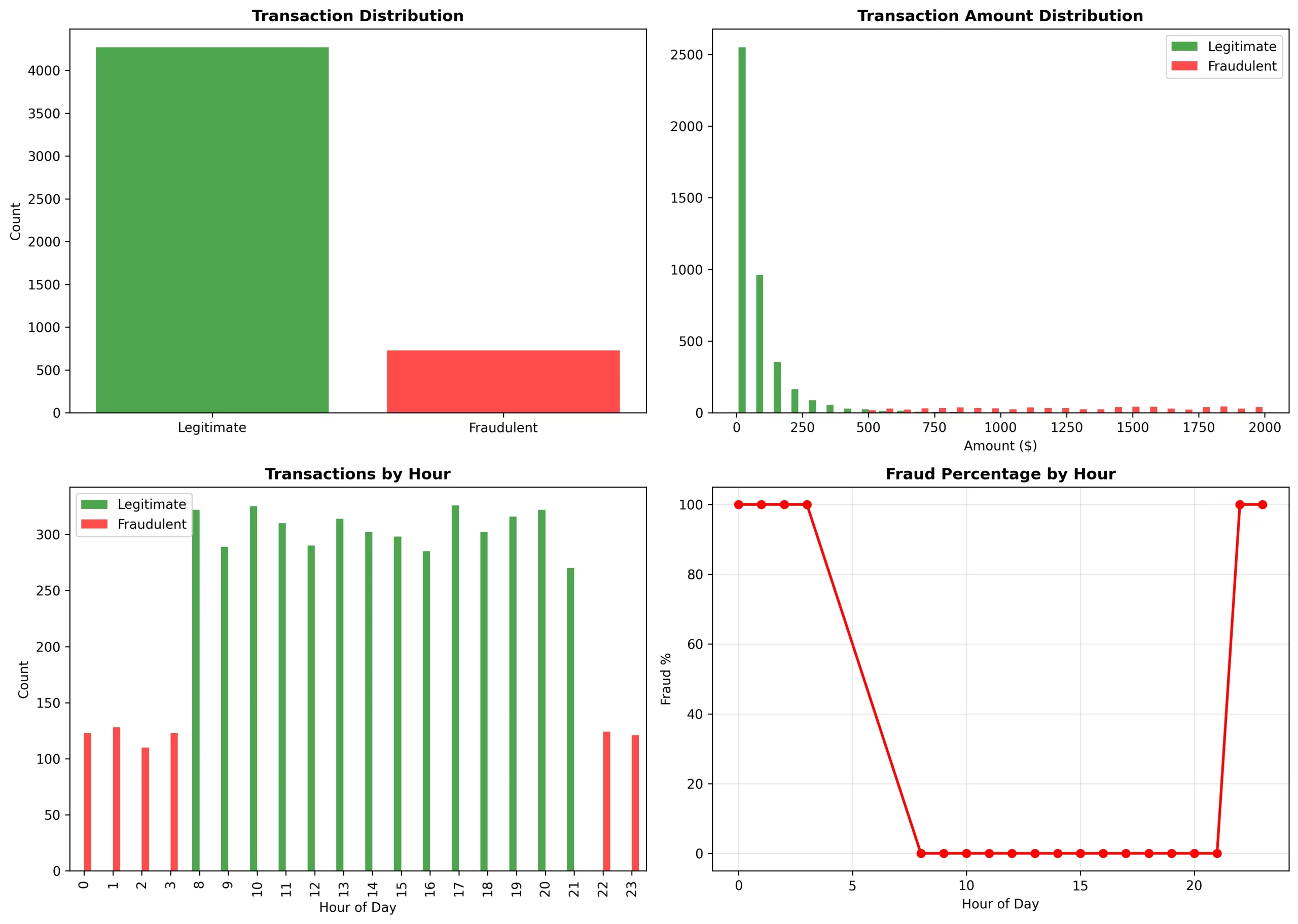
Zeitliche Tendencies:
Von 0 bis 3 und von 22 bis 23 Uhr: Es gab eine Betrugsrate von 100 % (es handelte sich um klassische Angriffe zu ungeraden Stunden).
Von 8 bis 21 Uhr: Es gab eine Betrugsrate von 0 % (es waren normale Geschäftszeiten)
Betragsverteilung:
Legitim: Der Schwerpunkt lag auf dem Bereich von 0 bis 250 US-Greenback (Log-Normalverteilung).
Betrügerisch: Es deckte den Bereich von 500 bis 2.000 US-Greenback ab (Angriffe mit hohem Wert)
Netzwerktrends:
Der Betrugsring aus 50 Konten hatte 10 Händler gemeinsam
Der Betrug battle nicht gleichmäßig verteilt, sondern konzentrierte sich auf bestimmte Händlergruppen
Wann sollte dieser Ansatz verwendet werden?
Dieser Ansatz ist superb für:
Betrug weist sichtbare Netzwerkmuster auf (z. B. Ringe, koordinierte Angriffe)
Sie verfügen über Beziehungsdaten (Benutzer-Händler-Geräte-Verbindungen)
Aufgrund des Transaktionsvolumens lohnt es sich, in die Infrastruktur zu investieren (Millionen Transaktionen).
Echtzeiterkennung mit einer Latenz von 50–100 ms ist in Ordnung
Dieser Ansatz eignet sich nicht für Szenarios wie:
Völlig unabhängige Transaktionen ohne Netzwerkeffekte
Sehr kleine Datensätze (< 10.000 Transaktionen)
Erfordert eine Latenz von weniger als 10 ms
Begrenzte ML-Infrastruktur
Abschluss
Graph Neural Networks verändern das Spiel bei der Betrugserkennung. Anstatt die Transaktionen als isolierte Ereignisse zu behandeln, können Unternehmen sie nun als Netzwerk modellieren und auf diese Weise komplexere Betrugspläne erkennen, die den herkömmlichen Methoden entgehen ML.
Der Fortschritt unserer Arbeit beweist, dass diese Denkweise nicht nur in der Theorie interessant, sondern auch in der Praxis nützlich ist. Die GNN-basierte Betrugserkennung mit Zahlen von 91 % Genauigkeit, 0,961 AUC und der Fähigkeit, Betrugsringe und koordinierte Angriffe zu erkennen, bietet einen echten Mehrwert für das Unternehmen.
Der gesamte Code ist verfügbar unter GitHubSie können es additionally gerne an Ihre spezifischen Probleme und Anwendungsfälle bei der Betrugserkennung anpassen.
Häufig gestellte Fragen
Q1. Warum Graph Neural Networks (GNN) zur Betrugserkennung verwenden?
A. GNNs erfassen Beziehungen zwischen Benutzern, Händlern und Geräten und decken Betrugsringe und vernetzte Verhaltensweisen auf, die herkömmliche ML- oder regelbasierte Systeme übersehen, indem sie Transaktionen unabhängig analysieren.
Q2. Wie verbessert Neo4j dieses Betrugserkennungssystem?
A. Neo4j speichert und fragt Diagrammbeziehungen nativ ab und erleichtert so die Modellierung und Durchquerung von Benutzer-Händler-Transaktionsverbindungen, die für die Erkennung von Betrugsmustern in Echtzeit unerlässlich sind.
Q3. Welche Ergebnisse hat das GNN-basierte Modell erzielt?
A. Das Modell erreichte eine Genauigkeit von 91 % und eine AUC von 0,961 und identifizierte erfolgreich koordinierte Betrugsringe, während gleichzeitig die Anzahl der Fehlalarme gering gehalten wurde.
Knowledge Science Trainee bei Analytics Vidhya Derzeit arbeite ich als Knowledge Science Trainee bei Analytics Vidhya, wo ich mich auf die Entwicklung datengesteuerter Lösungen und die Anwendung von KI/ML-Techniken zur Lösung realer Geschäftsprobleme konzentriere. Meine Arbeit ermöglicht es mir, fortschrittliche Analysen, maschinelles Lernen und KI-Anwendungen zu erforschen, die es Unternehmen ermöglichen, intelligentere, evidenzbasierte Entscheidungen zu treffen. Mit einem starken Fundament in den Bereichen Informatik, Softwareentwicklung und Datenanalyse ist es mir eine Leidenschaft, KI zu nutzen, um wirkungsvolle, skalierbare Lösungen zu schaffen, die die Lücke zwischen Technologie und Geschäft schließen. 📩 Du kannst mich auch erreichen unter (electronic mail protected)
Melden Sie sich an, um weiterzulesen und von Experten kuratierte Inhalte zu genießen.