

10 Python-Einzeiler zur Berechnung der Bedeutung von Modellmerkmalen
Bild vom Herausgeber
Modelle des maschinellen Lernens verstehen ist ein wesentlicher Aspekt beim Aufbau vertrauenswürdiger KI-Systeme. Die Verständlichkeit solcher Modelle beruht auf zwei grundlegenden Eigenschaften: Erklärbarkeit Und Interpretierbarkeit. Ersteres bezieht sich darauf, wie intestine wir das „Innere“ eines Modells beschreiben können (d. h. wie es funktioniert und intern aussieht), während sich Letzteres darauf bezieht, wie leicht Menschen die erfassten Beziehungen zwischen Eingabemerkmalen und vorhergesagten Ausgaben verstehen können. Wie wir sehen können, ist der Unterschied zwischen ihnen subtil, aber es gibt eine starke Brücke, die beide verbindet: Characteristic-Wichtigkeit.
In diesem Artikel werden 10 einfache, aber effektive Python-Einzeiler vorgestellt, mit denen Sie die Wichtigkeit von Modellmerkmalen aus verschiedenen Perspektiven berechnen können. So können Sie nicht nur verstehen, wie sich Ihr Modell für maschinelles Lernen verhält, sondern auch, warum es die Vorhersage(n) getroffen hat.
1. Integrierte Funktionsbedeutung in entscheidungsbaumbasierten Modellen
Baumbasierte Modelle wie Random Forests und XGBoost Mit Ensembles können Sie mithilfe eines Attributs wie dem folgenden ganz einfach eine Liste der Gewichtungen von Merkmalsbedeutung erhalten:
|
Wichtigkeiten = Modell.feature_importances_ |
Beachten Sie, dass mannequin sollte a priori ein trainiertes Modell enthalten. Das Ergebnis ist ein Array, das die Wichtigkeit von Options enthält. Wenn Sie jedoch eine selbsterklärendere Model wünschen, erweitert dieser Code den vorherigen Einzeiler, indem er die Characteristic-Namen für einen Datensatz wie Iris in einer Zeile einfügt.
|
drucken(„Characteristic-Wichtigkeiten:“, Liste(Reißverschluss(Iris.Characteristic-Namen, Modell.feature_importances_))) |
2. Koeffizienten in linearen Modellen
Einfachere lineare Modelle wie die lineare Regression und die logistische Regression legen Merkmalsgewichte auch über erlernte Koeffizienten offen. Dies ist eine Möglichkeit, die erste davon direkt und sauber zu erhalten (entfernen Sie den Positionsindex, um alle Gewichte zu erhalten):
|
Wichtigkeiten = Bauchmuskeln(Modell.coef_(0)) |
3. Sortieren von Options nach Wichtigkeit
Ähnlich wie die erweiterte Model von Nummer 1 oben kann dieser nützliche Einzeiler verwendet werden, um Options nach ihren Wichtigkeitswerten in absteigender Reihenfolge zu ordnen: ein hervorragender Einblick, welche Options am stärksten oder einflussreichsten zu Modellvorhersagen beitragen.
|
sortierte_features = sortiert(Reißverschluss(Merkmale, Wichtigkeiten), Schlüssel=Lambda X: X(1), umkehren=WAHR) |
4. Bedeutung der modellunabhängigen Permutation
Permutationswichtigkeit ist ein zusätzlicher Ansatz zur Messung der Wichtigkeit eines Merkmals – nämlich durch Mischen seiner Werte und Analysieren, wie eine Metrik, die zur Messung der Leistung des Modells verwendet wird (z. B. Genauigkeit oder Fehler), abnimmt. Dementsprechend ist dieser modellunabhängige Einzeiler von scikit-lernen wird verwendet, um Leistungseinbußen zu messen, die durch zufälliges Mischen der Werte einer Funktion entstehen.
|
aus sklearn.Inspektion Import permutation_importance Ergebnis = permutation_importance(Modell, X, j).Wichtigkeiten_Mittelwert |
5. Mittlerer Genauigkeitsverlust bei Kreuzvalidierungspermutationen
Dies ist ein effizienter Einzeiler zum Testen von Permutationen im Kontext von Kreuzvalidierungsprozessen – um zu analysieren, wie sich das Mischen der einzelnen Options auf die Modellleistung auswirkt Ok Falten.
|
Import Numpy als np aus sklearn.model_selection Import cross_val_score Wichtigkeiten = ((cross_val_score(Modell, X.zuordnen(**{F: np.zufällig.Permutation(X(F))}), j).bedeuten()) für F In X.Spalten) |
6. Visualisierungen der Permutationsbedeutung mit Eli5
Eli5 – eine Kurzform von „Erklären, als wäre ich 5 (Jahre alt)“ – ist im Kontext des maschinellen Lernens von Python eine Bibliothek für kristallklare Erklärbarkeit. Es bietet eine leicht visuell interaktive HTML-Ansicht der Characteristic-Wichtigkeiten, wodurch es besonders praktisch für Notebooks ist und sich sowohl für trainierte lineare als auch für Baummodelle eignet.
|
Import eli5 eli5.show_weights(Modell, Characteristic-Namen=Merkmale) |
7. Globale SHAP-Funktionsbedeutung
Gestalten ist eine beliebte und leistungsstarke Bibliothek, mit der Sie tiefer in die Erklärung der Bedeutung von Modellmerkmalen einsteigen können. Es kann verwendet werden, um mittlere absolute SHAP-Werte (Characteristic-Significance-Indikatoren in SHAP) für jedes Characteristic zu berechnen – alles im Rahmen eines modellunabhängigen, theoretisch fundierten Messansatzes.
|
Import Numpy als np Import Gestalt shap_values = Gestalt.TreeExplainer(Modell).shap_values(X) Wichtigkeiten = np.Bauchmuskeln(shap_values).bedeuten(0) |
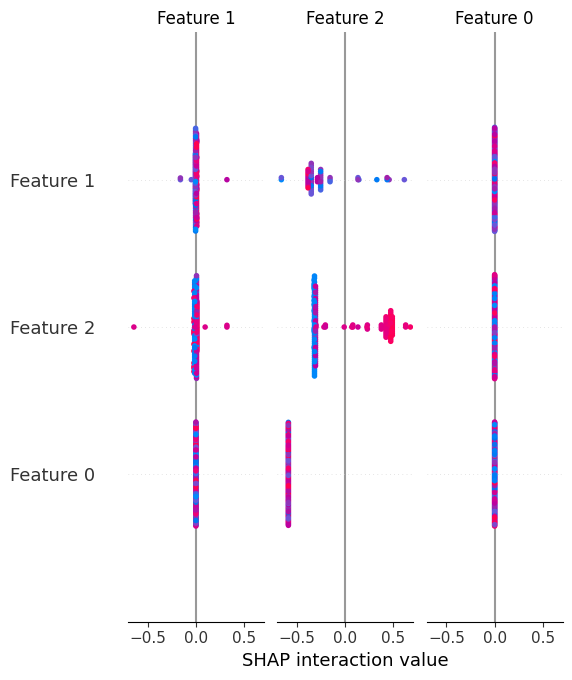
8. Zusammenfassendes Diagramm der SHAP-Werte
Im Gegensatz zu globalen SHAP-Characteristic-Bedeutungen liefert das Übersichtsdiagramm nicht nur die globale Bedeutung von Options in einem Modell, sondern auch deren Richtungen und hilft so visuell zu verstehen, wie Characteristic-Werte Vorhersagen nach oben oder unten verschieben.
|
Gestalt.summary_plot(shap_values, X) |
Schauen wir uns ein visuelles Beispiel des erzielten Ergebnisses an:
9. Single-Prediction-Erklärungen mit SHAP
Ein besonders attraktiver Aspekt von SHAP besteht darin, dass es nicht nur dabei hilft, das Gesamtverhalten des Modells und die Bedeutung von Merkmalen zu erklären, sondern auch, wie Merkmale speziell eine einzelne Vorhersage beeinflussen. Mit anderen Worten: Wir können eine einzelne Vorhersage offenlegen oder zerlegen und erklären, wie und warum das Modell diese spezifische Ausgabe erbracht hat.
|
Gestalt.force_plot(Gestalt.TreeExplainer(Modell).erwarteter_Wert, shap_values(0), X.iloc(0)) |
10. Modellunabhängige Funktionsbedeutung mit LIME
KALK ist eine different Bibliothek zu SHAP, die lokale Ersatzerklärungen generiert. Anstatt die eine oder andere zu verwenden, ergänzen sich diese beiden Bibliotheken intestine und tragen dazu bei, die Bedeutung von Merkmalen für einzelne Vorhersagen besser einzuschätzen. In diesem Beispiel wird dies für ein zuvor trainiertes logistisches Regressionsmodell durchgeführt.
|
aus Kalk.Lime_Tabular Import LimeTabularExplainer exp = LimeTabularExplainer(X.Werte, Characteristic-Namen=Merkmale).erklären_instanz(X.iloc(0), Modell.predict_proba) |
Zusammenfassung
In diesem Artikel wurden 10 effektive Python-Einzeiler vorgestellt, die dabei helfen, Modelle für maschinelles Lernen besser zu verstehen, zu erklären und zu interpretieren, wobei der Schwerpunkt auf der Bedeutung von Funktionen liegt. Mithilfe dieser Instruments ist es keine mysteriöse Blackbox mehr, die Funktionsweise Ihres Modells von innen zu verstehen.