
Retrieval-Augmented Era verändert die Artwork und Weise, wie LLMs externes Wissen nutzen. Das Drawback besteht darin, dass viele Entwickler falsch verstehen, was RAG tatsächlich tut. Sie konzentrieren sich auf das Dokument im Vektorspeicher und gehen davon aus, dass der Zauber mit dem Abrufen beginnt und endet. Aber Indizierung und Abruf sind überhaupt nicht dasselbe.
Bei der Indexierung geht es darum, wie Sie Wissen repräsentieren. Beim Abrufen geht es darum, welche Teile dieses Wissens das Modell sehen kann. Sobald Sie diese Lücke erkennen, verschiebt sich das Gesamtbild. Sie beginnen zu erkennen, wie viel Kontrolle Sie tatsächlich über die Argumentation, Geschwindigkeit und Erdung des Modells haben.
In diesem Leitfaden wird aufgeschlüsselt, was RAG-Indizierung wirklich bedeutet, und es werden praktische Wege zum Entwerfen von Indizierungsstrategien beschrieben, die Ihrem System tatsächlich dabei helfen, besser zu denken und nicht nur Textual content abzurufen.
Was ist RAG-Indexierung?
LAPPEN Die Indizierung ist die Grundlage des Abrufs. Dabei handelt es sich um den Prozess der Umwandlung von Rohwissen in numerische Daten, die dann über Ähnlichkeitsabfragen durchsucht werden können. Diese numerischen Daten werden Einbettungen genannt, und Einbettungen erfassen Bedeutung und nicht nur Textual content auf Oberflächenebene.

Betrachten Sie dies als den Aufbau einer durchsuchbaren semantischen Karte Ihrer Wissensdatenbank. Jeder Abschnitt, jede Zusammenfassung oder jede Variante einer Abfrage wird zu einem Punkt auf der Karte. Je organisierter diese Karte ist, desto besser kann Ihr Retriever relevantes Wissen identifizieren, wenn ein Benutzer eine Frage stellt.
Wenn Ihre Indizierung deaktiviert ist, beispielsweise wenn Ihre Blöcke zu groß sind, die Einbettungen Rauschen erfassen oder Ihre Darstellung der Daten nicht die Absicht des Benutzers widerspiegelt, hilft Ihnen kein LLM wirklich weiter. Die Qualität des Abrufs hängt immer davon ab, wie effektiv die Daten indiziert sind, und nicht davon, wie intestine sie sind maschinelles Lernen Modell ist.
Warum ist es wichtig?
Sie sind nicht darauf beschränkt, nur das abzurufen, was Sie indiziert haben. Die Stärke Ihres RAG-Programs liegt darin, wie effektiv Ihr Index die Bedeutung und nicht den Textual content widerspiegelt. Die Indexierung artikuliert den Rahmen, durch den Ihr Retriever das Wissen sieht.
Wenn Sie Ihre Indizierungsstrategie an Ihre Daten und Ihre Benutzerbedürfnisse anpassen, wird der Abruf präziser, die Modelle halluzinieren weniger und der Benutzer erhält genaue Vervollständigungen. Ein intestine gestalteter Index verwandelt RAG von einer Retrieval-Pipeline in eine echte semantische Argumentationsmaschine.
RAG-Indexierungsstrategien, die tatsächlich funktionieren
Angenommen, wir haben ein Dokument über die Python-Programmierung:
Doc = """ Python is a flexible programming language broadly utilized in information science, machine studying, and internet growth. It helps a number of paradigms and has a wealthy ecosystem of libraries like NumPy, pandas, and TensorFlow. """ Lassen Sie uns nun untersuchen, wann die einzelnen RAG-Indizierungsstrategien effektiv eingesetzt werden sollten und wie sie für solche Inhalte implementiert werden können, um ein leistungsstarkes Abrufsystem aufzubauen.
1. Chunk-Indizierung
Dies ist der Ausgangspunkt für die meisten RAG-Pipelines. Sie teilen große Dokumente in kleinere, semantisch kohärente Blöcke auf und betten jeden einzelnen mithilfe eines Einbettungsmodells ein. Diese Einbettungen werden dann in einem gespeichert Vektordatenbank.
Beispielcode:
# 1. Chunk Indexing
def chunk_indexing(doc, chunk_size=100):
phrases = doc.break up()
chunks = ()
current_chunk = ()
current_len = 0
for phrase in phrases:
current_len += len(phrase) + 1 # +1 for house
current_chunk.append(phrase)
if current_len >= chunk_size:
chunks.append(" ".be part of(current_chunk))
current_chunk = ()
current_len = 0
if current_chunk:
chunks.append(" ".be part of(current_chunk))
chunk_embeddings = (embed(chunk) for chunk in chunks)
return chunks, chunk_embeddings
chunks, chunk_embeddings = chunk_indexing(doc_text, chunk_size=50)
print("Chunks:n", chunks)Finest Practices:
- Halten Sie die Blöcke immer bei etwa 200–400 Token für Kurztexte bzw. 500–800 Tokens für lange technische Inhalte.
- Achten Sie darauf, die Aufteilung in der Mitte des Satzes oder Absatzes zu vermeiden und verwenden Sie logische, semantische Bruchstellen für eine bessere Aufteilung.
- Es empfiehlt sich, überlappende Fenster (20–30 %) zu verwenden, damit der Kontext an den Grenzen nicht verloren geht.
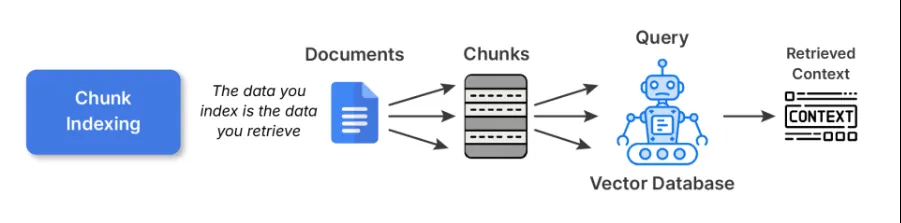
Kompromisse: Die Chunk-Indizierung ist eine einfache und universelle Indizierung. Größere Blöcke können jedoch die Abrufgenauigkeit beeinträchtigen, während kleinere Blöcke den Kontext fragmentieren und das LLM mit Teilen überfordern können, die nicht zusammenpassen.
Mehr lesen: Erstellen Sie eine RAG-Pipeline mit LlamaIndex
2. Sub-Chunk-Indizierung
Die Sub-Chunk-Indizierung dient als Verfeinerungsebene zusätzlich zur Chunk-Indizierung. Wenn Sie die normalen Chunks einbetten, teilen Sie den Chunk weiter in kleinere Unterchunks auf. Wenn Sie etwas abrufen möchten, vergleichen Sie die Unterblöcke mit der Abfrage. Sobald dieser Unterblock mit Ihrer Abfrage übereinstimmt, wird der vollständige übergeordnete Block in die Abfrage eingegeben LLM.
Warum das funktioniert:
Die Unterblöcke bieten Ihnen die Möglichkeit, gezielter, subtiler und genauer zu suchen und gleichzeitig den großen Kontext beizubehalten, den Sie für Ihre Argumentation benötigten. Sie haben beispielsweise möglicherweise einen langen Forschungsartikel und der Unterabschnitt zu einem Inhaltsteil in diesem Artikel kann die Erklärung einer Formel in einem langen Absatz sein, wodurch sowohl die Präzision als auch die Interpretierbarkeit verbessert werden.
Beispielcode:
# 2. Sub-chunk Indexing
def sub_chunk_indexing(chunk, sub_chunk_size=25):
phrases = chunk.break up()
sub_chunks = ()
current_sub_chunk = ()
current_len = 0
for phrase in phrases:
current_len += len(phrase) + 1
current_sub_chunk.append(phrase)
if current_len >= sub_chunk_size:
sub_chunks.append(" ".be part of(current_sub_chunk))
current_sub_chunk = ()
current_len = 0
if current_sub_chunk:
sub_chunks.append(" ".be part of(current_sub_chunk))
return sub_chunks
# Sub-chunks for first chunk (as instance)
sub_chunks = sub_chunk_indexing(chunks(0), sub_chunk_size=30)
sub_embeddings = (embed(sub_chunk) for sub_chunk in sub_chunks)
print("Sub-chunks:n", sub_chunks)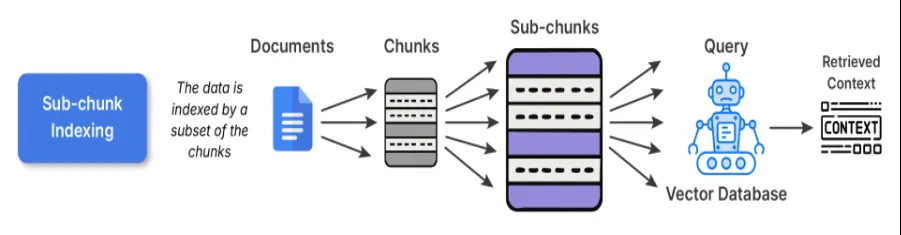
Wann zu verwenden: Dies wäre für Datensätze von Vorteil, die in jedem Absatz mehrere unterschiedliche Ideen enthalten. Wenn Sie beispielsweise Wissensdatenbanken wie Lehrbücher, Forschungsartikel usw. in Betracht ziehen, wäre dies preferrred.
Abtausch: Aufgrund der überlappenden Einbettungen sind die Kosten für die Vorverarbeitung und Speicherung etwas höher, aber die Abstimmung zwischen Abfrage und Inhalt ist wesentlich besser.
3. Abfrageindizierung
Bei der Abfrageindizierung wird der Rohtext nicht direkt eingebettet. Stattdessen erstellen wir mehrere imaginäre Fragen, die jeder Block beantworten könnte, und betten dann diesen Textual content ein. Dies geschieht teilweise, um die semantische Lücke zwischen der Artwork und Weise, wie Benutzer fragen, und der Artwork und Weise, wie Ihre Dokumente Dinge beschreiben, zu schließen.
Wenn Ihr Chunk zum Beispiel sagt:
„LangChain verfügt über Dienstprogramme für den Bau von RAG-Pipelines“
Das Modell würde Abfragen generieren wie:
- Wie baue ich eine RAG-Pipeline ein? LangChain?
- Über welche Retrieval-Instruments verfügt LangChain?
Wenn dann ein echter Benutzer eine ähnliche Frage stellt, trifft der Abruf direkt auf eine dieser indizierten Abfragen.
Beispielcode:
# 3. Question Indexing - generate artificial queries associated to the chunk
def generate_queries(chunk):
# Easy artificial queries for demonstration
queries = (
"What's Python used for?",
"Which libraries does Python help?",
"What paradigms does Python help?"
)
query_embeddings = (embed(q) for q in queries)
return queries, query_embeddings
queries, query_embeddings = generate_queries(doc_text)
print("Artificial Queries:n", queries)Finest Practices:
- Beim Schreiben von Indexabfragen würde ich die Verwendung von LLMs empfehlen, um 3–5 Abfragen professional Block zu erstellen.
- Sie können auch alle Fragen deduplizieren oder gruppieren, um den tatsächlichen Index zu verkleinern.

Wann zu verwenden:
- Q&A-Systeme oder ein Chatbot, bei dem die meisten Benutzerinteraktionen durch Fragen in natürlicher Sprache gesteuert werden.
- Sucherlebnis, bei dem der Benutzer wahrscheinlich nach dem Typ „Was“, „Wie“ oder „Warum“ fragt.
Abtausch: Während die synthetische Erweiterung die Zeit und den Platz für die Vorverarbeitung erhöht, sorgt sie für eine deutliche Steigerung der Abrufrelevanz für benutzerorientierte Systeme.
4. Zusammenfassende Indexierung
Mit der Zusammenfassungsindizierung können Sie Materialteile vor dem Einbetten in kleinere Zusammenfassungen umwandeln. Sie bewahren den gesamten Inhalt an einem anderen Ort auf und der Abruf erfolgt dann anhand der zusammengefassten Versionen.
Warum das von Vorteil ist:
Strukturen, dichte oder sich wiederholende Quellmaterialien (z. B. Tabellenkalkulationen, Richtliniendokumente, technische Handbücher) sind im Allgemeinen Materialien, die durch die direkte Einbettung aus der Rohtextversion Rauschen erfassen. Durch das Zusammenfassen werden die weniger relevanten Oberflächendetails abstrahiert und es ist semantisch bedeutsamer für Einbettungen.
Zum Beispiel:
Im Originaltext heißt es: „Die Temperaturwerte von 2020 bis 2025 lagen zwischen 22 und 42 Grad Celsius, wobei Anomalien El Niño zugeschrieben wurden.“
Die Zusammenfassung wäre: Jährliche Temperaturtrends (2020–2025) mit El Niño-bedingten Anomalien.
Die zusammenfassende Darstellung sorgt für den Fokus auf das Konzept.
Beispielcode:
# 4. Abstract Indexing
def summarize(textual content):
# Easy abstract for demonstration (substitute with an precise summarizer for actual use)
if "Python" in textual content:
return "Python: versatile language, utilized in information science and internet growth with many libraries."
return textual content
abstract = summarize(doc_text)
summary_embedding = embed(abstract)
print("Abstract:", abstract)

Wann sollte man es verwenden:
- Mit strukturierten Daten (Tabellen, CSVs, Logdateien)
- Technische oder ausführliche Inhalte, bei denen Einbettungen mit Rohtexteinbettungen schlechter abschneiden.
Abtausch: Wenn Zusammenfassungen zu abstrakt werden, besteht die Gefahr, dass sie an Nuancen und sachlicher Genauigkeit verlieren. Für wichtige Fachgebiete, insbesondere Recht, Finanzen usw., verlinken Sie zur Begründung auf den Originaltext.
5. Hierarchische Indizierung
Durch die hierarchische Indizierung werden Informationen auf verschiedenen Ebenen, Dokumenten, Abschnitten, Absätzen und Unterabsätzen organisiert. Sie rufen schrittweise ab, beginnend mit einer breiten Einleitung, um dann auf einen spezifischen Kontext einzugrenzen. Die oberste Ebene für die Komponente ruft Abschnitte relevanter Dokumente ab und die nächste Ebene ruft Absätze oder Unterabsätze zu einem bestimmten Kontext innerhalb dieser abgerufenen Abschnitte der letzten Dokumente ab.
Was bedeutet das?
Der hierarchische Abruf reduziert Störungen im System und ist nützlich, wenn Sie die Kontextgröße steuern müssen. Dies ist besonders nützlich, wenn Sie mit einem großen Dokumentenbestand arbeiten und nicht alles auf einmal abrufen können. Es verbessert auch die Interpretierbarkeit für spätere Analysen, da Sie wissen, welches Dokument mit welchem Abschnitt zur endgültigen Antwort beigetragen hat.
Beispielcode:
# 5. Hierarchical Indexing
# Set up doc into ranges: doc -> chunks -> sub-chunks
hierarchical_index = {
"doc": doc_text,
"chunks": chunks,
"sub_chunks": {chunk: sub_chunk_indexing(chunk) for chunk in chunks}
}
print("Hierarchical index instance:")
print(hierarchical_index)Finest Practices:
Verwenden Sie mehrere Einbettungsebenen oder eine Kombination aus Einbettung und Stichwortsuche. Rufen Sie beispielsweise Dokumente zunächst nur mit BM25 ab und rufen Sie dann präziser die relevanten Blöcke oder Komponenten mit Einbettung ab.
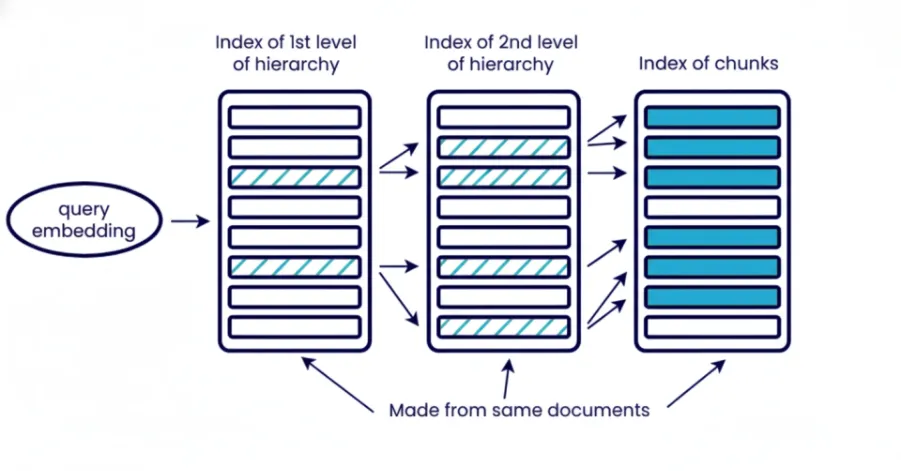
Wann sollte man es verwenden:
- RAG im Unternehmensmaßstab mit Tausenden von Dokumenten.
- Abrufen aus langen Quellen wie Büchern, juristischen Archiven oder technischen PDFs.
Abtausch: Erhöhte Komplexität aufgrund mehrerer gewünschter Abrufebenen. Erfordert außerdem zusätzlichen Speicher und Vorverarbeitung für Metadaten/Zusammenfassungen. Erhöht die Abfragelatenz aufgrund des mehrstufigen Abrufs und ist nicht intestine für große unstrukturierte Daten geeignet.
6. Hybride Indizierung (multimodal)
Wissen liegt nicht nur im Textual content. In seiner hybriden Indexierungsform führt RAG zwei Dinge aus, um mit mehreren Datenformen oder Modalitäten arbeiten zu können. Der Retriever verwendet Einbettungen, die er von verschiedenen Encodern generiert, die auf jede der möglichen Modalitäten spezialisiert oder abgestimmt sind. Und der ruft Ergebnisse aus jeder der relevanten Einbettungen ab und kombiniert sie, um mithilfe von Bewertungsstrategien oder Late-Fusion-Ansätzen eine Antwort zu generieren.
Hier ist ein Beispiel für seine Verwendung:
- Verwenden CLIP oder BLIP für Bilder und Textbeschriftungen.
- Verwenden Sie CodeBERT- oder StarCoder-Einbettungen, um Code zu verarbeiten.
Beispielcode:
# 6. Hybrid Indexing (instance with textual content + picture)
# Instance textual content and dummy picture embedding (substitute embed_image with precise mannequin)
def embed_image(image_data):
# Dummy instance: picture information represented as size of string (substitute with CLIP/BLIP encoder)
return (len(image_data) / 1000)
text_embedding = embed(doc_text)
image_embedding = embed_image("image_bytes_or_path_here")
print("Textual content embedding dimension:", len(text_embedding))
print("Picture embedding dimension:", len(image_embedding))
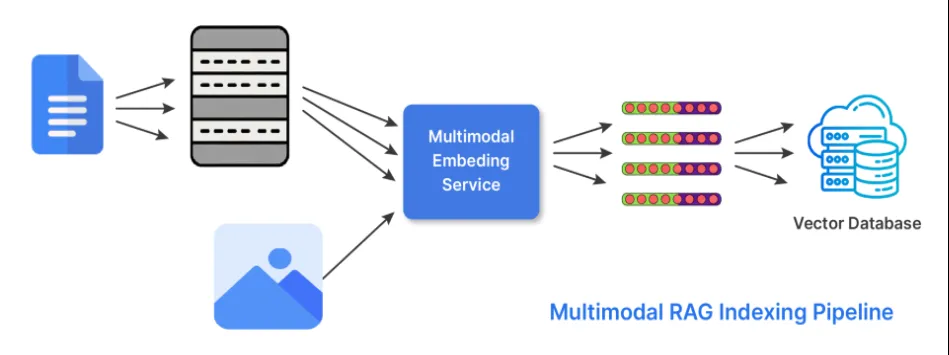
Wann sollte die Hybridindizierung verwendet werden:
- Bei der Arbeit mit technischen Handbüchern oder Dokumentationen, die Bilder oder Diagramme enthalten.
- Multimodale Dokumentation oder Supportartikel.
- Produktkataloge oder E-Commerce.
Abtausch: Es handelt sich um ein komplizierteres Logik- und Speichermodell für den Abruf, aber um ein viel umfassenderes Kontextverständnis in der Antwort und eine höhere Flexibilität in der Domäne.
Abschluss
Erfolgreiche RAG-Systeme hängen von geeigneten Indexierungsstrategien für die Artwork der Daten und die zu beantwortenden Fragen ab. Die Indizierung leitet an, was der Retriever findet und worauf das Sprachmodell aufbaut, und macht sie so zu einer wichtigen Grundlage über die Recherche hinaus. Die Artwork der Indizierung, die Sie verwenden würden, kann Chunk-, Sub-Chunk-, Abfrage-, zusammenfassende, hierarchische oder hybride Indizierung sein. Die Indizierung sollte der in Ihren Daten vorhandenen Struktur folgen, was die Relevanz erhöht und Rauschen beseitigt. Intestine konzipierte Indexierungsprozesse werden niedriger sein Halluzinationen und ein genaues, vertrauenswürdiges System bereitzustellen.
Häufig gestellte Fragen
A. Durch die Indizierung wird Wissen in Einbettungen codiert, während beim Abrufen ausgewählt wird, welche codierten Teile das Modell sieht, um eine Anfrage zu beantworten.
A. Sie bestimmen, wie genau das System Abfragen zuordnen kann und wie viel Kontext das Modell für die Argumentation erhält.
A. Verwenden Sie es, wenn Ihre Wissensdatenbank Textual content, Bilder, Code oder andere Modalitäten vermischt und Sie den Retriever benötigen, um alle davon zu verarbeiten.
Ich bin Knowledge Science Trainee bei Analytics Vidhya und arbeite leidenschaftlich an der Entwicklung fortschrittlicher KI-Lösungen wie generative KI-Anwendungen, große Sprachmodelle und hochmoderne KI-Instruments, die die Grenzen der Technologie verschieben. Zu meinen Aufgaben gehört es auch, ansprechende Bildungsinhalte für die YouTube-Kanäle von Analytics Vidhya zu erstellen, umfassende Kurse zu entwickeln, die das gesamte Spektrum von maschinellem Lernen bis hin zu generativer KI abdecken, und technische Blogs zu verfassen, die grundlegende Konzepte mit den neuesten Innovationen in der KI verbinden. Dadurch möchte ich zum Aufbau intelligenter Systeme beitragen und Wissen teilen, das die KI-Neighborhood inspiriert und stärkt.
Melden Sie sich an, um weiterzulesen und von Experten kuratierte Inhalte zu genießen.