NVIDIA gab heute eine deutliche Erweiterung seines Angebots bekannt strategische Zusammenarbeit mit Mistral AI. Diese Partnerschaft fällt mit der Veröffentlichung der neuen offenen Modellfamilie Mistral 3 Frontier zusammen und markiert einen entscheidenden Second HHardwarebeschleunigung und Open-Supply-Modellarchitektur haben sich zusammengeschlossen, um Leistungsbenchmarks neu zu definieren.
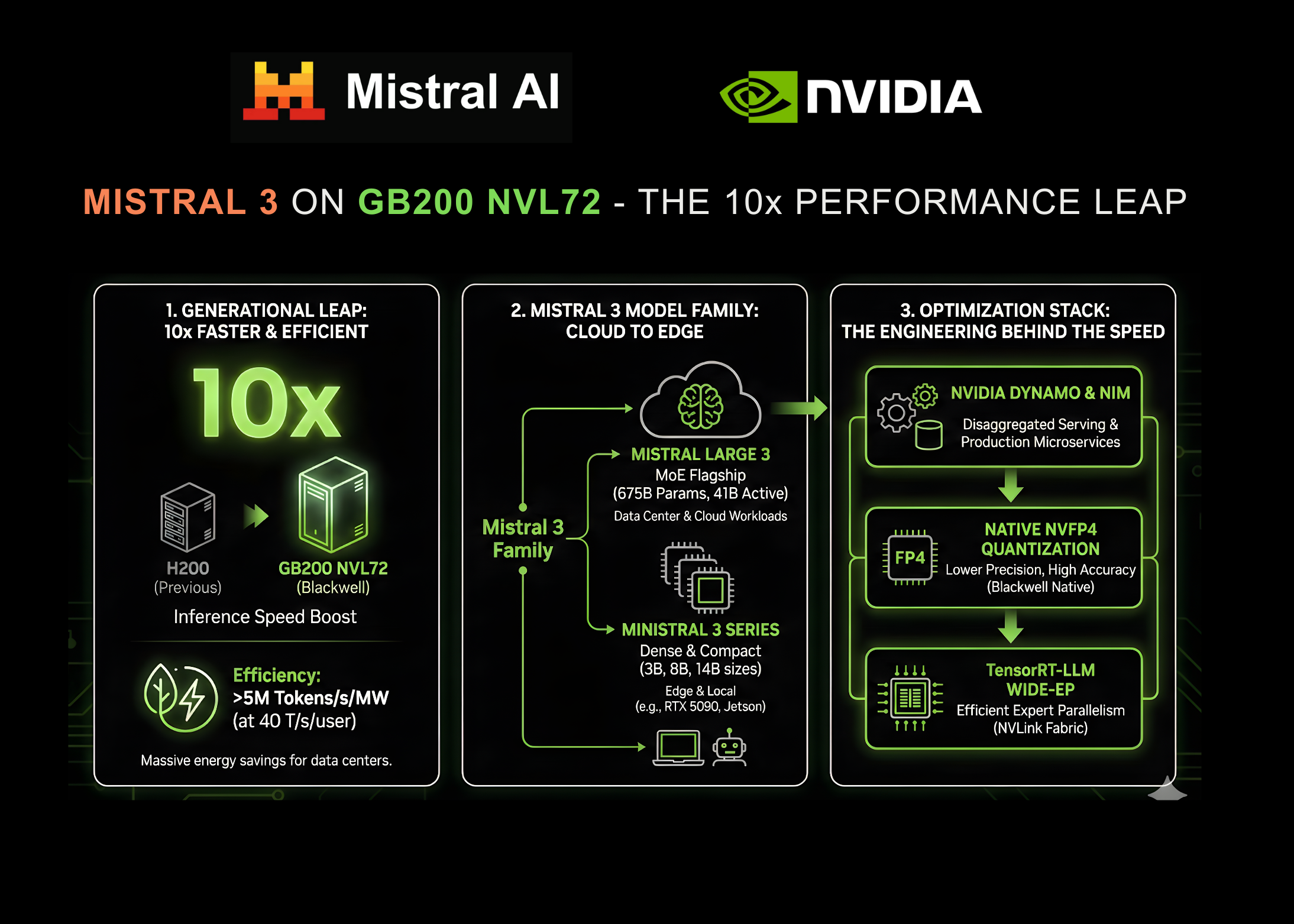
Diese Zusammenarbeit stellt einen gewaltigen Sprung in der Inferenzgeschwindigkeit dar: Die neuen Modelle erreichen jetzt diesen Wert 10x schneller auf NVIDIA GB200 NVL72-Systemen im Vergleich zu den H200-Systemen der vorherigen Era. Dieser Durchbruch eröffnet eine beispiellose Effizienz für KI auf Unternehmensniveau und verspricht, die Latenz- und Kostenengpässe zu lösen, die in der Vergangenheit den groß angelegten Einsatz von Argumentationsmodellen geplagt haben.
Ein Generationssprung: 10x schneller auf Blackwell
Da sich die Nachfrage der Unternehmen von einfachen Chatbots hin zu Agenten mit hoher Argumentation und langem Kontext verlagert, ist die Inferenzeffizienz zum kritischen Engpass geworden. Der Zusammenarbeit zwischen NVIDIA und Mistral AI geht dieses Downside direkt an, indem es die Mistral 3-Familie speziell für die NVIDIA Blackwell-Architektur optimiert.
Wo Produktions-KI-Systeme sowohl ein starkes Benutzererlebnis (UX) als auch eine kosteneffiziente Skalierung bieten müssen, bietet der NVIDIA GB200 NVL72 eine bis zu zehnmal höhere Leistung als der H200 der vorherigen Era. Dabei handelt es sich nicht nur um einen reinen Geschwindigkeitsgewinn; Dies führt zu einer deutlich höheren Energieeffizienz. Das System übertrifft 5.000.000 Token professional Sekunde professional Megawatt (MW).) bei Benutzerinteraktivitätsraten von 40 Token professional Sekunde.
Dies gilt für Rechenzentren, die mit Strombeschränkungen zu kämpfen haben Effizienzgewinn ist genauso wichtig wie die Leistungssteigerung selbst. Dieser Generationssprung gewährleistet niedrigere Kosten professional Token und behält gleichzeitig den hohen Durchsatz bei, der für Echtzeitanwendungen erforderlich ist.
Eine neue Mistral 3-Familie
Der Motor für diese Leistung ist die neu veröffentlichte Mistral 3-Familie. Diese Modellsuite bietet branchenführende Genauigkeit, Effizienz und Anpassungsmöglichkeiten und deckt das Spektrum von massiven Rechenzentrums-Workloads bis hin zur Inferenz von Edge-Geräten ab.
Mistral Massive 3: Das Flaggschiff-MoE
An der Spitze der Hierarchie sitzt Mistral Massive 3, ein hochmodernes, spärliches multimodales und mehrsprachiges Combination-of-Consultants (MoE)-Modell.
- Gesamtparameter: 675 Milliarden
- Aktive Parameter: 41 Milliarden
- Kontextfenster: 256.000 Token
Ausgebildet NVIDIA Hopper-GPUs, Mistral Massive 3 ist für die Bewältigung komplexer Argumentationsaufgaben konzipiert und bietet Parität mit geschlossenen Modellen der Spitzenklasse, während die Flexibilität offener Gewichte erhalten bleibt.
Ministral 3: Dichte Kraft am Rande
Ergänzt wird das große Modell durch das Ministerial 3 Serieeine Reihe kleiner, kompakter Hochleistungsmodelle, die auf Geschwindigkeit und Vielseitigkeit ausgelegt sind.
- Größen: 3B-, 8B- und 14B-Parameter.
- Varianten: Foundation, Anleitung und Begründung für jede Größe (insgesamt neun Modelle).
- Kontextfenster: Insgesamt 256.000 Token.
Der Ministerial 3 Die Serie übertrifft den GPQA Diamond Accuracy Benchmark, indem sie 100 Token weniger verwendet und gleichzeitig eine höhere Genauigkeit liefert:

Bedeutende Technik hinter der Geschwindigkeit: Ein umfassender Optimierungsstapel
Der Leistungsanspruch „10x“ basiert auf einer umfassenden Reihe von Optimierungen, die von Mistral- und NVIDIA-Ingenieuren gemeinsam entwickelt wurden. Die Groups verfolgten einen „extremen Co-Design“-Ansatz, bei dem Hardwarefunktionen mit Anpassungen der Modellarchitektur kombiniert wurden.
TensorRT-LLM Huge Skilled Parallelism (Huge-EP)
Um die enorme Größe des GB200 NVL72 voll auszuschöpfen, NVIDIA nutzte Huge Skilled Parallelism innerhalb von TensorRT-LLM. Diese Technologie bietet optimierte MoE GroupGEMM-Kernel, Expertenverteilung und Lastausgleich.
Entscheidend ist, dass Huge-EP die kohärente Speicherdomäne und NVLink-Cloth des NVL72 nutzt. Es ist äußerst widerstandsfähig gegenüber architektonischen Variationen in großen MoEs. Zum Beispiel, Mistral Massive 3 nutzt etwa 128 Experten professional Schicht, etwa halb so viele wie vergleichbare Modelle wie DeepSeek-R1. Trotz dieses Unterschieds ermöglicht Huge-EP dem Modell, die Vorteile der NVLink-Cloth in Bezug auf hohe Bandbreite, geringe Latenz und Nichtblockierung zu nutzen und sicherzustellen, dass die enorme Größe des Modells nicht zu Kommunikationsengpässen führt.
Native NVFP4-Quantisierung
Einer der bedeutendsten technischen Fortschritte in dieser Model ist die Unterstützung von NVFP4, einem in der Blackwell-Architektur nativen Quantisierungsformat.
Für Mistral Massive 3 können Entwickler mithilfe der Open-Supply-Bibliothek llm-compressor einen rechenoptimierten NVFP4-Checkpoint bereitstellen, der offline quantisiert wird.
Dieser Ansatz reduziert die Rechen- und Speicherkosten bei strikter Wahrung der Genauigkeit. Es nutzt die präziseren FP8-Skalierungsfaktoren und die feinkörnigere Blockskalierung von NVFP4, um Quantisierungsfehler zu kontrollieren. Das Rezept zielt speziell auf die MoE-Gewichte ab und behält gleichzeitig die ursprüngliche Präzision anderer Komponenten bei, sodass das Modell nahtlos und mit minimalem Genauigkeitsverlust auf dem GB200 NVL72 bereitgestellt werden kann.
Disaggregierte Bereitstellung mit NVIDIA Dynamo
Mistral Massive 3 nutzt NVIDIA Dynamoein verteiltes Inferenz-Framework mit geringer Latenz, um die Vorfüll- und Dekodierungsphasen der Inferenz zu disaggregieren.
In herkömmlichen Setups konkurrieren die Vorfüllphase (Verarbeitung der Eingabeaufforderung) und die Dekodierungsphase (Erzeugung der Ausgabe) um Ressourcen. Durch die Ratenanpassung und Disaggregation dieser Phasen steigert Dynamo die Leistung für Workloads mit langem Kontext, wie z. B. 8K-Eingabe-/1K-Ausgabekonfigurationen, erheblich. Dies gewährleistet einen hohen Durchsatz, selbst wenn das riesige 256-KByte-Kontextfenster des Modells genutzt wird.
Von der Cloud zum Edge: Leistung von Ministral 3
Die Optimierungsbemühungen gehen über die riesigen Rechenzentren hinaus. Angesichts des wachsenden Bedarfs an lokaler KI ist die Ministral 3-Serie für den Edge-Einsatz konzipiert und bietet Flexibilität für eine Vielzahl von Anforderungen.
RTX- und Jetson-Beschleunigung
Die dichten Ministral-Modelle sind für Plattformen wie den NVIDIA GeForce RTX AI PC und die NVIDIA Jetson-Robotikmodule optimiert.
- RTX 5090: Die Ministral-3B-Varianten können rasante Inferenzgeschwindigkeiten von erreichen 385 Token professional Sekunde auf der NVIDIA RTX 5090 GPU. Dies bringt KI-Leistung der Workstation-Klasse auf lokale PCs und ermöglicht so eine schnelle Iteration und einen besseren Datenschutz.
- Jetson Thor: Für Robotik und Edge-KI können Entwickler den vLLM-Container auf NVIDIA Jetson Thor verwenden. Das Ministral-3-3B-Instruct-Modell erreicht 52 Token professional Sekunde für einzelne Parallelität und kann auf bis zu skaliert werden 273 Token professional Sekunde mit einer Parallelität von 8.
Breite Framework-Unterstützung
NVIDIA hat mit der Open-Supply-Group zusammengearbeitet, um sicherzustellen, dass diese Modelle überall einsetzbar sind.
- Llama.cpp & Ollama: NVIDIA hat mit diesen beliebten Frameworks zusammengearbeitet, um eine schnellere Iteration und geringere Latenz für die lokale Entwicklung zu gewährleisten.
- SGLang: NVIDIA hat mit SGLang zusammengearbeitet, um eine Implementierung von Mistral Massive 3 zu erstellen, die sowohl Disaggregation als auch spekulative Decodierung unterstützt.
- vLLM: NVIDIA arbeitete mit vLLM zusammen, um die Unterstützung für Kernel-Integrationen zu erweitern, einschließlich spekulativer Dekodierung (EAGLE), Blackwell-Unterstützung und erweiterter Parallelität.
Produktionsbereit mit NVIDIA NIM
Um die Einführung in Unternehmen zu optimieren, werden die neuen Modelle über verfügbar sein NVIDIA NIM-Mikrodienste.
Mistral Massive 3 und Ministral-14B-Instruct sind derzeit über den NVIDIA API-Katalog und die Vorschau-API verfügbar. Bald können Unternehmensentwickler herunterladbare NVIDIA NIM-Microservices nutzen. Dies stellt eine containerisierte, produktionsbereite Lösung bereit, die es Unternehmen ermöglicht, die Mistral 3-Familie mit minimalem Setup auf jeder GPU-beschleunigten Infrastruktur bereitzustellen.
Diese Verfügbarkeit stellt sicher, dass der spezifische „10-fache“ Leistungsvorteil des GB200 NVL72 in Produktionsumgebungen ohne komplexe kundenspezifische Entwicklungen realisiert werden kann, wodurch der Zugang zu erstklassiger Intelligenz demokratisiert wird.
Fazit: Ein neuer Normal für Open Intelligence
Die Veröffentlichung der NVIDIA-beschleunigten offenen Modellfamilie Mistral 3 stellt einen großen Sprung für KI in der Open-Supply-Group dar. Indem Mistral und NVIDIA Leistung auf Spitzenniveau unter einer Open-Supply-Lizenz anbieten und diese mit einem robusten {Hardware}-Optimierungs-Stack unterstützen, treffen sie Entwickler dort, wo sie sind.
Von der gewaltigen Größe der GB200 NVL72 mit Huge-EP und NVFP4Mit der kantenfreundlichen Dichte von Ministral auf einer RTX 5090 bietet diese Partnerschaft einen skalierbaren, effizienten Weg für künstliche Intelligenz. Da bevorstehende Optimierungen wie die spekulative Dekodierung mit Multitoken-Vorhersage (MTP) und EAGLE-3 die Leistung voraussichtlich noch weiter steigern werden, ist die Mistral 3-Familie auf dem besten Weg, ein grundlegendes Component der nächsten Era von KI-Anwendungen zu werden.
Zum Testen verfügbar!
Wenn Sie ein Entwickler sind, der diese Leistungssteigerungen vergleichen möchte, können Sie dies tun Laden Sie die Mistral 3-Modelle herunter direkt von Hugging Face oder testen Sie die einsatzfreien gehosteten Versionen auf construct.nvidia.com/mistralai um die Latenz und den Durchsatz für Ihren spezifischen Anwendungsfall zu bewerten.
Schauen Sie sich die Modelle an Umarmendes Gesicht. Einzelheiten finden Sie unter Unternehmensblog Und Technik-/Entwickler-Weblog.
Vielen Dank an das NVIDIA AI-Crew für die Vordenkerrolle/Ressourcen für diesen Artikel. Das NVIDIA AI-Crew hat diesen Inhalt/Artikel unterstützt.

Jean-marc ist ein erfolgreicher KI-Geschäftsführer. Er leitet und beschleunigt das Wachstum von KI-basierten Lösungen und gründete 2006 ein Laptop-Imaginative and prescient-Unternehmen. Er ist ein anerkannter Redner auf KI-Konferenzen und hat einen MBA von Stanford.