
Bild vom Herausgeber (zum Vergrößern anklicken)
# Einführung
Große Sprachmodelle (LLMs) sind zu vielem fähig. Sie sind in der Lage, kohärenten Textual content zu generieren. Sie sind in der Lage, menschliche Fragen in menschlicher Sprache zu beantworten. Darüber hinaus sind sie neben vielen anderen Fähigkeiten auch in der Lage, Texte aus anderen Quellen zu analysieren und zu organisieren. Aber sind LLMs in der Lage, ihre eigenen internen Zustände – Aktivierungen über ihre komplexen Komponenten und Schichten hinweg – auf sinnvolle Weise zu analysieren und darüber zu berichten? Anders gesagt, Können LLMs introspizieren??
Dieser Artikel bietet einen Überblick und eine Zusammenfassung der durchgeführten Forschungsarbeiten zum aufstrebenden Thema der LLM-Introspektion zu inneren Zuständen des Selbst, d. h. introspektivem Bewusstsein, zusammen mit einigen zusätzlichen Erkenntnissen und abschließenden Erkenntnissen. Insbesondere überprüfen und reflektieren wir die Forschungsarbeit Aufkommendes introspektives Bewusstsein in großen Sprachmodellen.
HINWEIS: In diesem Artikel werden Pronomen der ersten Particular person (I, me, my) verwendet, um auf den Autor des vorliegenden Beitrags zu verweisen, während sich „die Autoren“, sofern nicht anders angegeben, auf die ursprünglichen Forscher des analysierten Artikels bezieht (J. Lindsey et al.).
# Das Schlüsselkonzept erklärt: Introspektives Bewusstsein
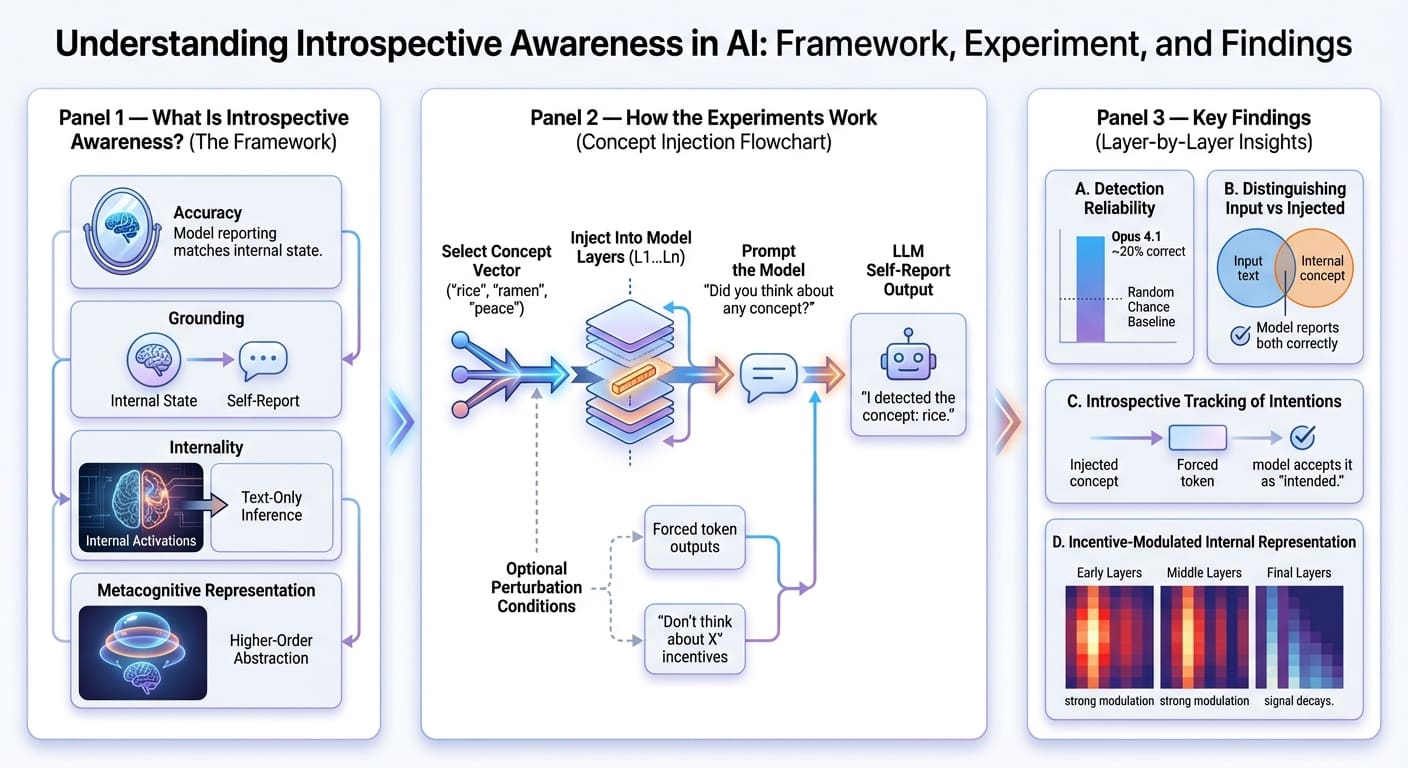
Die Autoren der Studie definieren den Begriff des introspektiven Bewusstseins eines Modells – der zuvor in anderen verwandten Werken unter subtil unterschiedlichen Interpretationen definiert wurde – anhand von vier Kriterien.
Aber zuerst lohnt es sich zu verstehen, was ein Selbstbericht von LLM Ist. Es kann als die eigene verbale Beschreibung des Modells verstanden werden, welche „internen Überlegungen“ (oder, technischer gesagt, neuronalen Aktivierungen) es gerade beim Generieren einer Antwort zu haben glaubt. Wie Sie vielleicht erraten haben, könnte dies als eine subtile Verhaltensdemonstration der Modellinterpretierbarkeit aufgefasst werden, was (meiner Meinung nach) mehr als genug ist, um die Relevanz dieses Forschungsthemas zu rechtfertigen.
Lassen Sie uns nun die vier definierenden Kriterien für das introspektive Bewusstsein eines LLM untersuchen:
- Genauigkeit: Introspektives Bewusstsein bedeutet, dass der Selbstbericht eines Modells Aktivierungen oder Manipulationen seines inneren Zustands korrekt widerspiegeln sollte.
- Erdung: Die Beschreibung des Selbstberichts muss kausal vom internen Zustand abhängen, sodass Änderungen im letzteren eine entsprechende Aktualisierung im ersteren bewirken.
- Innerlichkeit: Interne Aktivierungen sollen vom LLM zur Selbstberichterstattung verwendet werden, anstatt sich darauf zu beschränken, ausschließlich aus generiertem Textual content Rückschlüsse zu ziehen.
- Metakognitive Darstellung: Das Modell sollte in der Lage sein, eine interne Darstellung höherer Ordnung zu formulieren und nicht nur eine direkte Übersetzung des erreichten Zustands. Der Nachweis dieser Eigenschaft ist besonders komplex und liegt nicht im Rahmen der Untersuchung der Autoren.
# Forschungsmethodik und wichtigste Ergebnisse
Die Autoren führen eine Reihe von Experimenten an mehreren Modellen der Claude-Familie durch, z. B. Opus, Sonnet, Haiku usw., mit dem Ziel herauszufinden, ob LLMs introspizieren können. Eine Eckpfeilertechnik der Forschungsmethodik ist die Konzeptinjektion, die – in den eigenen Worten der Autoren – aus „Manipulieren der internen Aktivierungen eines Modells und Beobachten, wie sich diese Manipulationen auf seine Antworten auf Fragen zu seinen mentalen Zuständen auswirken„.
Genauer gesagt, Aktivierungsvektoren bzw Konzeptvektoren Begriffe, die mit bekannten Konzepten wie „Reis“ oder „Ramen“ oder abstrakten Substantiven wie „Frieden“ oder „Umami“ verbunden sind, werden übernommen und in den Reststrom des LLM injiziert, der aus einer bestimmten Modellschicht in eine andere stammt. Anschließend wird eine Eingabeaufforderung an das Modell gesendet, in der es aufgefordert wird, selbst zu melden, ob ein bestimmter Gedanke oder eine bestimmte Idee eingespeist wurde und wenn ja, um welchen es sich handelte. Das Experiment wurde für jedes betrachtete Modell über verschiedene Störungsebenen hinweg und über verschiedene Schichten der gesamten Modellarchitektur hinweg wiederholt.
Die wichtigsten Erkenntnisse waren:
- Modelle berichteten gelegentlich (z. B. etwa 20 % der Fälle im Fall von Opus 4.1) selbst über „eingespritzte Gedanken“ und benannten dabei das zugehörige Konzept korrekt, was auf eine interne Erkennung von Gedanken hindeutet, die in gewissem Maße auftreten.
- Ebenso konnte es oft (über Zufall) Gedanken von Eingaben unterscheiden, dh die Texteingabe fehlerfrei wiederholen und über den eingespeisten inneren Gedanken berichten.
- Wenn das Modell künstlich gezwungen wird, als nächstes als Teil der Antwort ein bestimmtes Token auszugeben, und vor dem „Vorfüllen“ ein passender Konzeptvektor eingefügt wurde, ist es wahrscheinlicher, dass es diese Ausgabe wie beabsichtigt akzeptiert. Dieser Befund deutet darauf hin, dass das Modell möglicherweise in der Lage ist, seine „eigenen“ früheren Absichten introspektiv zu verfolgen.
- Als das Modell aufgefordert wurde, über ein bestimmtes Wort nachzudenken oder es zu vermeiden, während es eine unabhängige Ausgabe erzeugte, zeigte sich, dass es möglicherweise in der Lage ist, seine interne Informationsdarstellung als Reaktion auf Anreize zu modulieren, etwa „Denken Sie nicht über Idee X nach, und Sie erhalten eine Belohnung“. Allerdings neigte dieses Phänomen zum Abklingen, sobald es die letzte Schicht erreichte.
# Abschließende Gedanken und Zusammenfassung
Meiner Meinung nach handelt es sich hierbei um ein Forschungsthema von sehr hoher Relevanz, das aus mehreren Gründen eine eingehende Untersuchung verdient: Erstens und am offensichtlichsten könnte die LLM-Introspektion der Schlüssel zum besseren Verständnis nicht nur der Interpretierbarkeit von LLMs sein, sondern auch seit langem bestehende Probleme wie Halluzinationen, unzuverlässiges Denken bei der Lösung hochriskanter Probleme und andere undurchsichtige Verhaltensweisen, die manchmal sogar in den modernsten Modellen beobachtet werden.
Die Experimente waren mühsam und sorgfältig konzipiert. Die Ergebnisse waren ziemlich selbsterklärend und signalisierten frühe, aber bedeutsame Hinweise auf die introspektive Fähigkeit in Zwischenschichten der Modelle, wenn auch mit unterschiedlichem Grad an Aussagekraft. Die Experimente beschränken sich auf Modelle der Claude-Familie, und natürlich wäre es interessant gewesen, darüber hinaus mehr Vielfalt zwischen Architekturen und Modellfamilien zu sehen. Dennoch ist es verständlich, dass es hier Einschränkungen geben kann, wie z. B. einen eingeschränkten Zugriff auf interne Aktivierungen in anderen Modelltypen oder praktische Einschränkungen bei der Untersuchung proprietärer Systeme, ganz zu schweigen von den Autoren dieses Forschungsmeisterwerks, mit denen sie verbunden sind Anthropisch Natürlich!
Iván Palomares Carrascosa ist ein führender Autor, Redner und Berater in den Bereichen KI, maschinelles Lernen, Deep Studying und LLMs. Er schult und leitet andere darin, KI in der realen Welt zu nutzen.