
Wenn Sie Open-Supply-LLMs verfolgen, wissen Sie bereits, dass sich der Bereich schnell entwickelt. Alle paar Monate erscheint ein neues Modell, das bessere Argumentation, bessere Codierung und geringere Rechenkosten verspricht. Mistral struggle eines der wenigen Unternehmen, das diese Ansprüche konsequent erfüllt, und mit Mistral 3 haben sie die Dinge noch weiter vorangetrieben. Diese neue Model ist nicht nur ein weiteres Replace. Mistral 3 stellt eine vollständige Suite kompakter, effizienter Open-Supply-Modelle (3B, 8B, 14B) zusammen mit Mistral Massive 3 vor, einem Sparse MoE Modell, das 41B aktive Parameter in eine 675B-Parameter-Architektur packt. In diesem Handbuch erläutern wir, was in Mistral 3 eigentlich neu ist, warum es wichtig ist, wie man es mit Ollama installiert und ausführt und wie es sich bei realen Denk- und Codierungsaufgaben verhält.
Überblick über Mistral 3: Was ist neu und wichtig?
Mistral 3 wurde am 2. Dezember 2025 gestartet und markiert einen großen Fortschritt für Open-Supply-KI. Anstatt immer größeren Modellen nachzujagen, konzentrierte sich Mistral auf Effizienz, Argumentationsqualität und Benutzerfreundlichkeit in der Praxis. Die Produktpalette umfasst jetzt drei kompakte, dichte Modelle (3B, 8B, 14B) und Mistral Massive 3, ein spärliches MoE-Modell mit 41B aktiven Parametern innerhalb einer 675B-Parameter-Architektur.
Die gesamte Suite wird unter Apache 2.0 veröffentlicht, wodurch sie vollständig für kommerzielle Projekte nutzbar ist – einer der größten Gründe, warum die Entwickler-Neighborhood begeistert ist.
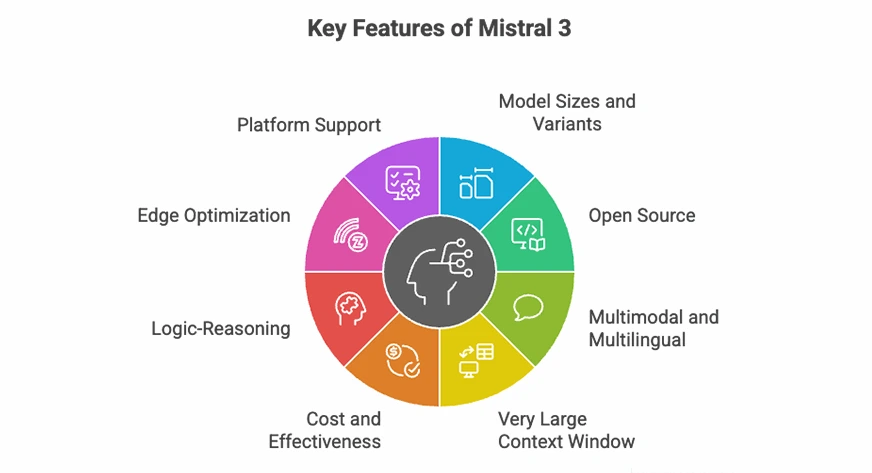
Hauptmerkmale von Mistral 3
- Mehrere Modellgrößen: Verfügbar in den Varianten „Foundation“ (3B), „Instruieren“ (8B) und „Begründung“ (14B), sodass Sie genau das auswählen können, was zu Ihrem Arbeitsaufwand passt (Chat, Instruments, Langform-Begründung usw.).
- Offen und flexibel: Die Apache 2.0-Lizenz macht Mistral 3 heute zu einer der zugänglichsten und geschäftsfreundlichsten Modellfamilien.
- Multimodal: Alle Modelle unterstützen Textual content- und Bildeingaben mit einem integrierten Imaginative and prescient-Encoder, sodass sie für das Verständnis von Dokumenten, Diagrammen und visuellen Aufgaben geeignet sind.
- Langkontextfähigkeit: Mistral Massive 3 kann bis zu 256.000 Token verarbeiten, was bedeutet, dass vollständige Bücher, lange Rechtsverträge und riesige Codebasen auf einmal verarbeitet werden können.
- Besseres Preis-Leistungs-Verhältnis: Mistral behauptet, dass seine neuen Befehlsvarianten mit konkurrierenden offenen Modellen übereinstimmen oder diese übertreffen und gleichzeitig weniger unnötige Token erzeugen, was die Inferenzkosten senkt.
- Verbesserte Argumentation: Das auf Argumentation abgestimmte 14B-Modell erreicht 85 % im AIME-Benchmark – eine der höchsten Punktzahlen für ein Modell dieser Größe.
- Edge-ready: Die Modelle 3B und 8B können mithilfe der Quantisierung lokal auf Laptops und Client-GPUs ausgeführt werden, und das Modell 14B passt problemlos auf Hochleistungs-Desktops.
Mistral 3 mit Ollama einrichten
Einer der Vorteile von Mistral 3 ist die Möglichkeit, auf einem lokalen Laptop ausgeführt zu werden. Ollama kann kostenlos verwendet werden und fungiert als Befehlszeilenschnittstelle zum Ausführen großer Sprachmodelle unter Linux, macOS und Home windows. Es verarbeitet Modell-Downloads und bietet automatisch GPU-Unterstützung.
Schritt 1: Ollama installieren
Führen Sie das offizielle Skript aus, um die Ollama-Binärdateien und -Dienste zu installieren, und überprüfen Sie dann die Verwendung ollama --version
curl -fsSL https://ollama.com/set up.sh | sh - macOS-Benutzer: Laden Sie die Ollama-DMG von ollama.com herunter und ziehen Sie sie in „Anwendungen“. Ollama installiert alle erforderlichen Abhängigkeiten (einschließlich Rosetta für ARM-basierte Macs).
- Home windows-Benutzer: Laden Sie die neueste Model herunter
.exeaus dem Ollama GitHub-Repository. Öffnen Sie nach der Set up PowerShell und führen Sie es ausollama serve. Der Daemon wird automatisch gestartet
Schritt 2: Starten Sie Ollama
Starten Sie den Ollama-Dienst (normalerweise automatisch):
ollama serve Sie können jetzt auf die lokale API zugreifen unter: http://localhost:11434
Schritt 3: Ziehen Sie ein Mistral 3-Modell
So laden Sie das quantisierte 8B-Instruct-Modell herunter:
ollama pull Mistral :8b-instruct-q4_0 Schritt 4: Führen Sie das Modell interaktiv aus
ollama run Mistral :8b-instruct-q4_0 Dies öffnet eine interaktive REPL. Geben Sie eine beliebige Eingabeaufforderung ein, zum Beispiel:
> Clarify quantum entanglement in easy phrases. Das Modell reagiert sofort und Sie können weiterhin mit ihm interagieren.
Schritt 5: Verwenden Sie die Ollama-API
Ollama stellt außerdem eine REST-API bereit. Hier ist eine Beispiel-cURL-Anfrage zur Codegenerierung:
curl http://localhost:11434/api/generate -d '{
"mannequin": "Mistral :8b-instruct-q4_0",
"immediate": "Write a Python operate to kind a listing.",
"stream": false
}'Lesen Sie auch: Wie führe ich LLM-Modelle lokal mit Ollama aus?
Mistral 3-Fähigkeiten
Mistral 3 ist eine universelle Modellsuite, die den Einsatz zum Chatten, Beantworten von Fragen, Argumentieren, Generieren und Analysieren von Code sowie zum Verarbeiten visueller Eingaben ermöglicht. Es verfügt über einen Imaginative and prescient-Encoder, der beschreibende Antworten auf bestimmte Bilder liefern kann. Um die Fähigkeiten der Mistral 3-Modelle zu demonstrieren, haben wir sie bei drei Sätzen logischer Argumentations- und Codierungsprobleme eingesetzt:
- Argumentationsfähigkeit mit einem Logikrätsel
- Codedokumentation und -verständnis
- Programmierkenntnisse mit einer Multiprocessing-Implementierung
Um dies zu erreichen, haben wir Ollama verwendet, um die Mistral 3-Modelle abzufragen und zu beobachten, wie intestine sie funktionieren. Es folgt eine kurze Diskussion der Aufgaben, Leistungsergebnisse und Benchmarks.
Aufgabe 1: Denkfähigkeit mit einem Logikrätsel
Immediate:
Vier Freunde: A, B, C und D werden verdächtigt, einen einzigen Schlüssel versteckt zu haben. Jeder macht eine Aussage:
A: „B hat den Schlüssel.“
B: „C hat den Schlüssel nicht.“
C: „D hat den Schlüssel.“
D: „Ich habe den Schlüssel nicht.“
Ihnen wird gesagt, dass genau eine dieser vier Aussagen wahr ist. Wer versteckt den Schlüssel?
Antwort von Mistral 8B:

Danach dauert es ein paar Sekunden, alle möglichen Szenarien auszuwerten und zu analysieren. Bevor er zum Schluss kommt und in etwa 50 Sekunden eine richtige Antwort als C gibt.

Meine Meinung:
Das Modell löste das Rätsel richtig und folgte einem schrittweisen Argumentationsansatz. Es untersuchte jedes mögliche Szenario und kam dann zu dem Schluss, dass C den Schlüssel in der Hand hält. Allerdings struggle die Latenz spürbar: Das 8B-Modell brauchte etwa 40–50 Sekunden, um zu reagieren. Diese Verzögerung ist wahrscheinlich auf lokale Hardwarebeschränkungen zurückzuführen und kein inhärentes Modellproblem.
Aufgabe 2: Codedokumentation und -verständnis
Immediate:
Geben Sie mir die vollständige Dokumentation des Codes aus der Codedatei. Denken Sie daran, dass die Dokumentation Folgendes enthalten sollte:
1) Doc-Strings
2) Kommentare
3) Detaillierte Dokumentation der Funktionen
Antwort von Mistral 3:
Meine Meinung:
Die Dokumentationsausgabe struggle verwendbar, stimmte jedoch nicht vollständig mit den Anweisungen überein. Schlüsselelemente wie Dokumentzeichenfolgen, Inline-Kommentare und detaillierte Erklärungen auf Funktionsebene waren entweder unvollständig oder fehlten ganz. Obwohl das Modell die Aufgabe verstand, gelang es ihm nicht, die Dokumentation in einem gründlichen, für Entwickler geeigneten Format zu strukturieren.
Aufgabe 3: Programmierkenntnisse mit einer Multiprocessing-Implementierung
Immediate:
Implementieren Sie ein Python-Programm, das das Multiprocessing-Modul verwendet, um die Quadratsumme der ersten N natürlichen Zahlen parallel zu berechnen.
Teilen Sie den Zahlenbereich in kleinere Teile auf, lassen Sie jeden Prozess die Teilquadratsumme für seinen Teil berechnen und kombinieren Sie schließlich die Teilergebnisse, um die Gesamtsumme zu erhalten.
Vergleichen Sie dann die Leistung der Multiprozessor-Implementierung mit einer Einzelprozessversion.
Antwort von Mistral 3:
import multiprocessing
import time
import math
def sum_of_squares_single(n):
"""Compute the sum of squares of the primary N pure numbers in a single course of."""
return sum(i ** 2 for i in vary(1, n + 1))
def sum_of_squares_parallel(n, num_processes=None):
"""Compute the sum of squares in parallel utilizing multiprocessing."""
if num_processes is None:
num_processes = multiprocessing.cpu_count()
chunk_size = n // num_processes
chunks = ((i * chunk_size + 1, (i + 1) * chunk_size) for i in vary(num_processes))
def compute_chunk(begin, finish):
return sum(i ** 2 for i in vary(begin, finish + 1))
with multiprocessing.Pool(processes=num_processes) as pool:
partial_sums = pool.map(lambda args: compute_chunk(*args), chunks)
return sum(partial_sums)
def compare_performance(n):
"""Evaluate single-process and parallel efficiency."""
print(f"Computing sum of squares for the primary {n} pure numbers...")
# Single-process
start_time = time.time()
single_result = sum_of_squares_single(n)
single_time = time.time() - start_time
print(f"Single-process time: {single_time:.6f} seconds")
print(f"Single-process consequence: {single_result}")
# Parallel
start_time = time.time()
parallel_result = sum_of_squares_parallel(n)
parallel_time = time.time() - start_time
print(f"Parallel time: {parallel_time:.6f} seconds")
print(f"Parallel consequence: {parallel_result}")
print(f"nSpeedup: {single_time / parallel_time:.2f}x")
if __name__ == "__main__":
N = 10**6 # Instance: Compute for first 1,000,000 numbers
compare_performance(N)Antwort vom Terminal

Meine Meinung:
Die Codegenerierung struggle stark. Das Modell ergab eine modulare, saubere und funktionale Multiprozessorlösung. Die Chunking-Logik, der Prozesspool, die Teilsummenberechnung und ein klarer Leistungsvergleich wurden korrekt implementiert. Allerdings fehlten dem Code, ähnlich wie bei Aufgabe 2, die richtigen Kommentare und Dokumentzeichenfolgen. Während die Logik korrekt und vollständig ausführbar struggle, beeinträchtigte das Fehlen erläuternder Anmerkungen die allgemeine Klarheit und Entwicklerfreundlichkeit.
Lesen Sie auch: Die 12 besten Open-Supply-LLMs für 2025 und ihre Einsatzmöglichkeiten
Benchmarking und Beobachtungen
Die Gesamtleistung von Mistral 3 ist überlegen. Die wichtigsten Benchmarks und Erkenntnisse aus der Laufzeit des Modells sind:
Open-Supply-Führer
Mistral Massive veröffentlichte als Open-Supply-Modell unabhängig von seiner Denkfähigkeit seine höchste Platzierung auf LMArena (Platz 2 in der Kategorie „Offene Modelle“, Platz 6 insgesamt). Es erzielt bei zwei beliebten Benchmarks, MMMLU für Allgemeinwissen und MMMLU für Argumentation, gleiche oder bessere Platzierungen und übertrifft damit mehrere führende geschlossene Modelle.
Benchmarks für Mathematik und logisches Denken
Zusätzlich zu den mathematischen Benchmarks schnitt Mistral 14B bei AIME25 (0,85 vs. 0,737) und GPQA Diamond (0,712 vs. 0,663) besser ab als Qwen-14B. Während AIME25 die mathematischen Fähigkeiten misst (MATH-Datensatz), messen die anderen Benchmarks Denkaufgaben. MATH-Benchmark-Ergebnisse: Mistral 14B erreichte etwa 90,4 % im Vergleich zu 85,4 % für das 12B-Modell von Google.
Code-Benchmarks
Beim HumanEval-Benchmark erzielte das spezialisierte Codestral-Modell (das wir für effektiv befunden haben) in unserem Check eine Punktzahl von 86,6 %. Wir haben auch festgestellt, dass Mistral für die meisten Testprobleme genaue Lösungen generierte, aufgrund seines ausgewogenen Designs jedoch in einigen Herausforderungs-Bestenlisten leicht hinter den größten Codierungsmodellen rangiert.
Effizienz (Geschwindigkeit und Token)
Mistral 3 hat eine effiziente Laufzeit. Ein aktueller Bericht zeigte, dass sein 8B-Modell auf modernen GPUs eine Inferenz von etwa 50–60 Tokens/Sekunde erreicht. Die kompakten Modelle verbrauchen auch weniger Speicher: Beispielsweise benötigt das 3B-Modell ein paar GB auf der Festplatte, das 8B etwa 5 GB und das 14B etwa 9 GB (nicht quantisiert).
{Hardware}-Spezifikationen
Wir haben überprüft, dass eine 16-GB-GPU ausreichend Leistung für Mistral 3B bietet. Das 8B-Modell benötigt im Allgemeinen etwa 32 GB RAM und 8 GB GPU-Speicher; Es kann jedoch mit 4-Bit-Quantisierung auf einer 6–8-GB-GPU ausgeführt werden. Viele Instanzen des 14B-Modells erfordern typischerweise eine High-Tier- oder Flaggschiff-Grafikkarte (z. B. 24 GB VRAM) und/oder mehrere GPUs. Nur CPU-Versionen kleiner Modelle können mit quantisierter Inferenz ausgeführt werden, obwohl GPUs nach wie vor die schnellste Choice sind.
Abschluss
Mistral 3 zeichnet sich als schnelles, leistungsfähiges und zugängliches Open-Supply-Modell aus, das bei Argumentations-, Codierungs- und realen Aufgaben eine gute Leistung erbringt. Die kleinen Varianten lassen sich problemlos lokal ausführen, und die größeren Modelle bieten wettbewerbsfähige Genauigkeit bei geringeren Kosten. Egal, ob Sie Entwickler, Forscher oder KI-Fanatic sind, probieren Sie Mistral 3 selbst aus und sehen Sie, wie es in Ihren Workflow passt.
Hallo! Ich bin Vipin, ein leidenschaftlicher Fanatic für Datenwissenschaft und maschinelles Lernen mit fundierten Kenntnissen in Datenanalyse, Algorithmen für maschinelles Lernen und Programmierung. Ich verfüge über praktische Erfahrung in der Modellerstellung, der Verwaltung unübersichtlicher Daten und der Lösung realer Probleme. Mein Ziel ist es, datengesteuerte Erkenntnisse anzuwenden, um praktische Lösungen zu schaffen, die zu Ergebnissen führen. Ich bin bestrebt, meine Fähigkeiten in einer kollaborativen Umgebung einzubringen und gleichzeitig weiterhin in den Bereichen Information Science, maschinelles Lernen und NLP zu lernen und mich weiterzuentwickeln.
Melden Sie sich an, um weiterzulesen und von Experten kuratierte Inhalte zu genießen.