NVIDIA hat die Nemotron 3-Familie offener Modelle als Teil eines vollständigen Stacks für agentische KI veröffentlicht, einschließlich Modellgewichtungen, Datensätzen und Instruments für das Reinforcement-Studying. Die Familie verfügt über drei Größen: Nano, Tremendous und Extremely und zielt auf Multi-Agent-Systeme ab, die lange Kontextbegründungen mit strenger Kontrolle über die Inferenzkosten erfordern. Nano verfügt über etwa 30 Milliarden Parameter mit etwa 3 Milliarden aktiven Parametern professional Token, Tremendous über etwa 100 Milliarden Parameter mit bis zu 10 Milliarden aktiven Parametern professional Token und Extremely über etwa 500 Milliarden Parameter mit bis zu 50 Milliarden aktiven Parametern professional Token.
Modellfamilie und Ziel-Workloads
Nemotron 3 wird als effiziente offene Modellfamilie für Agentenanwendungen vorgestellt. Die Linie besteht aus Nano-, Tremendous- und Extremely-Modellejeweils auf unterschiedliche Arbeitslastprofile abgestimmt.
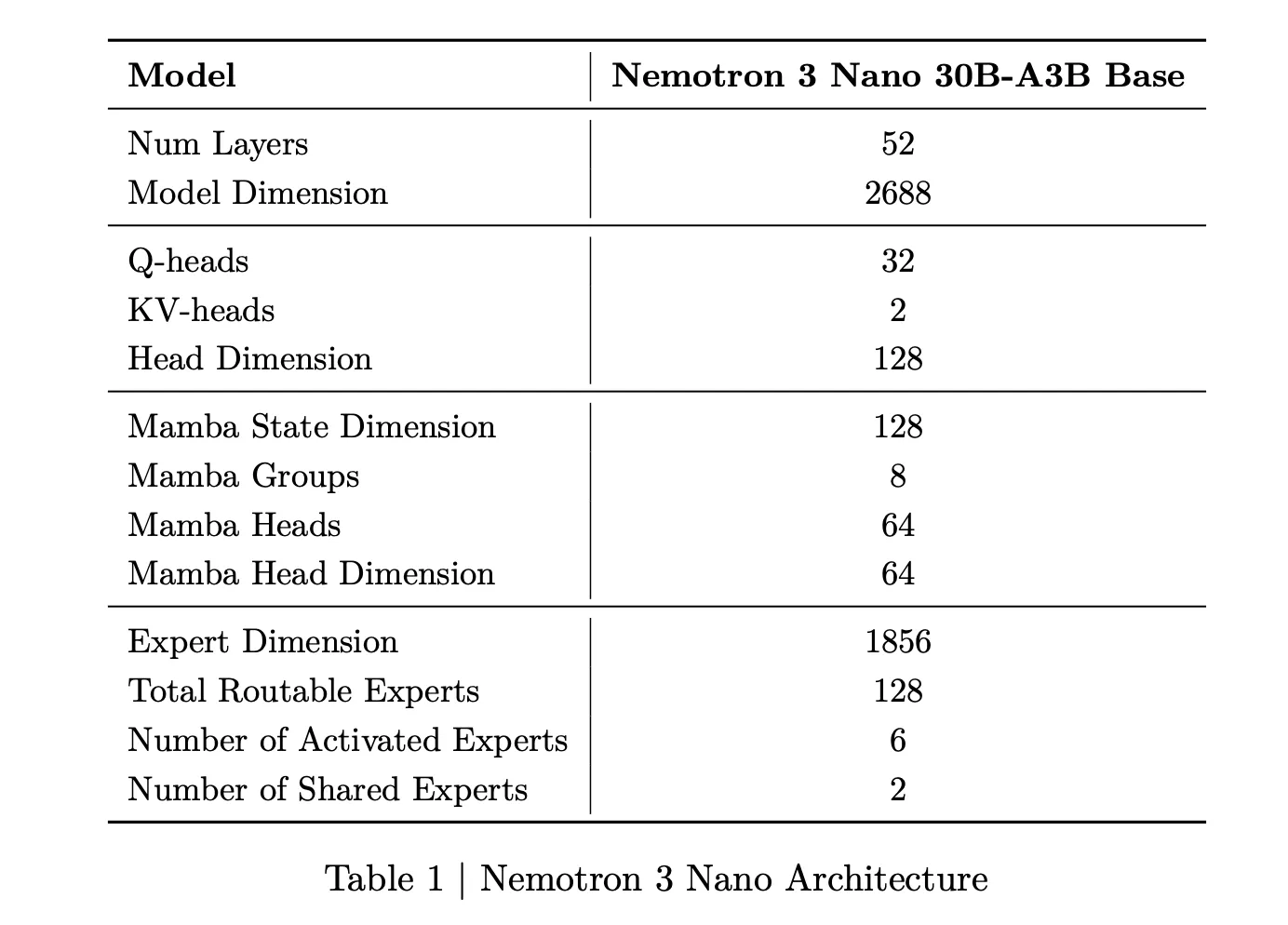
Nemotron 3 Nano ist ein Combination of Specialists-Hybrid-Mamba-Transformer-Sprachmodell mit etwa 31,6 Milliarden Parametern. Professional Vorwärtsdurchlauf sind nur etwa 3,2 Milliarden Parameter aktiv, einschließlich Einbettungen sind es 3,6 Milliarden. Diese spärliche Aktivierung ermöglicht es dem Modell, eine hohe Darstellungskapazität bei gleichzeitig niedrigem Rechenaufwand beizubehalten.
Nemotron 3 Tremendous verfügt über etwa 100 Milliarden Parameter, wobei bis zu 10 Milliarden professional Token aktiv sind. Nemotron 3 Extremely skaliert dieses Design auf etwa 500 Milliarden Parameter mit bis zu 50 Milliarden aktiven Parametern professional Token. Tremendous zielt auf eine hochpräzise Argumentation für große Multiagentenanwendungen ab, während Extremely für komplexe Forschungs- und Planungsabläufe gedacht ist.
Nemotron 3 Nano ist ab sofort mit offenen Gewichten und Rezepten, auf Hugging Face und als NVIDIA NIM-Microservice verfügbar. Tremendous und Extremely sind für das erste Halbjahr 2026 geplant.
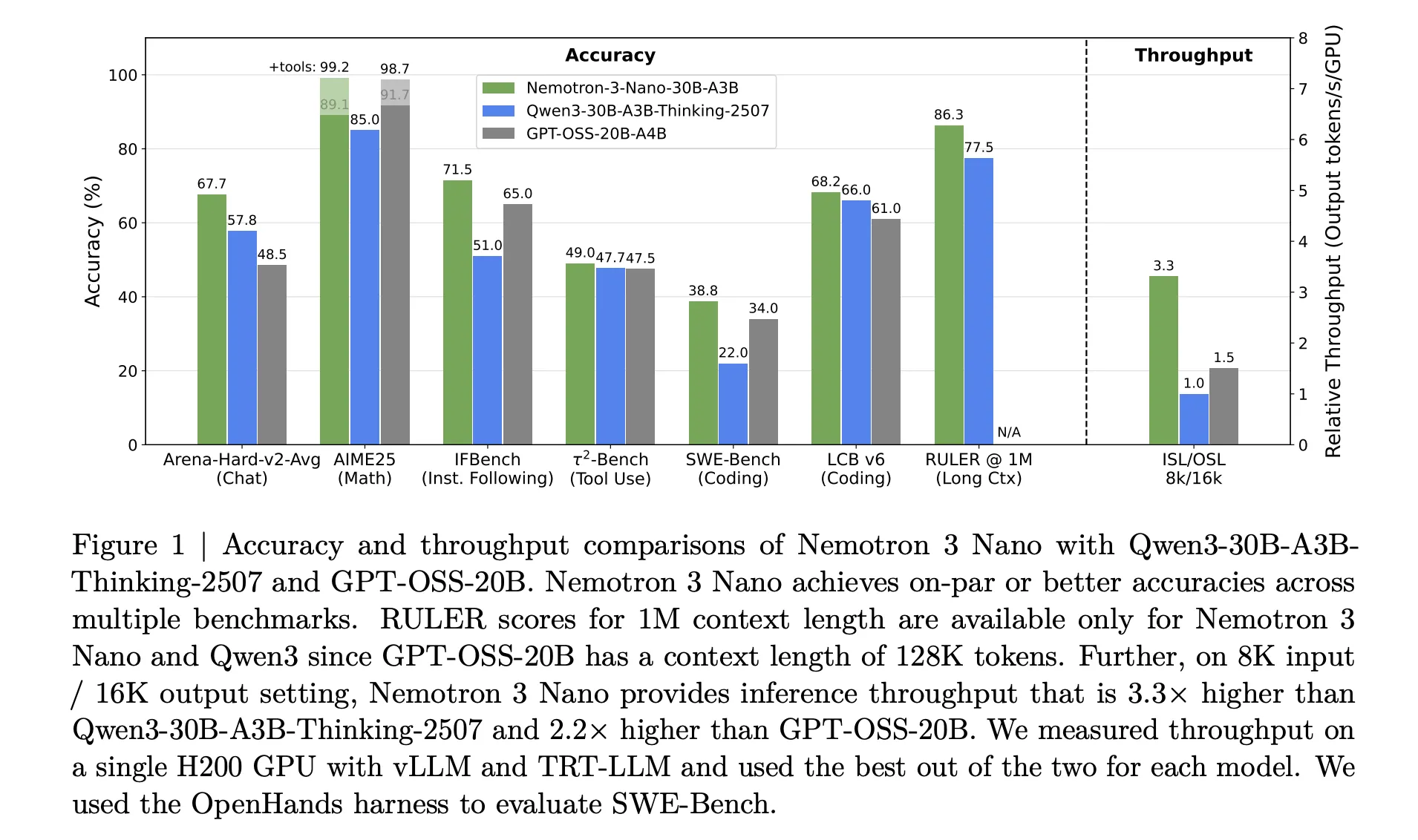
NVIDIA Nemotron 3 Nano bietet einen etwa viermal höheren Token-Durchsatz als Nemotron 2 Nano und reduziert die Nutzung von Reasoning-Token erheblich, während gleichzeitig eine native Kontextlänge von bis zu 1 Million Token unterstützt wird. Diese Kombination ist für Multiagentensysteme gedacht, die große Arbeitsbereiche wie lange Dokumente und große Codebasen bearbeiten.
Hybride Mamba Transformer MoE-Architektur
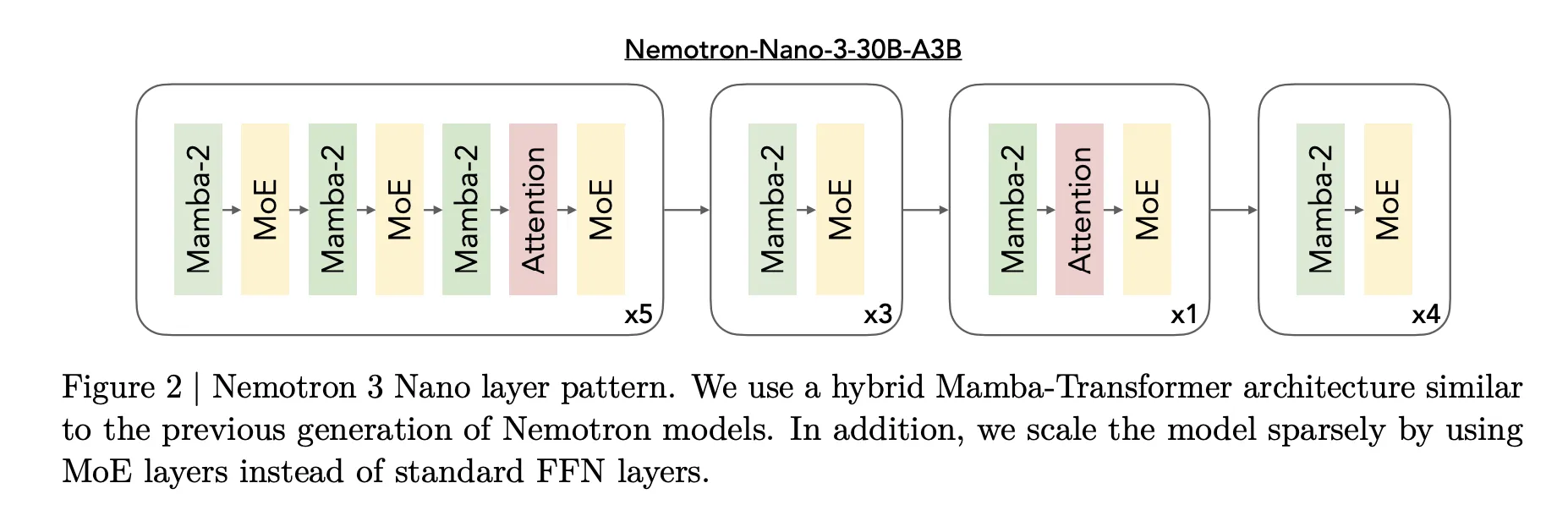
Das Kerndesign von Nemotron 3 ist eine Hybrid-Mamba-Transformer-Architektur von Combination of Specialists. Die Modelle mischen Mamba-Sequenzblöcke, Aufmerksamkeitsblöcke und spärliche Expertenblöcke in einem einzigen Stapel.
Für Nemotron 3 Nano beschreibt das Forschungsteam ein Muster, das Mamba-2-Blöcke, Aufmerksamkeitsblöcke und MoE-Blöcke verschachtelt. Commonplace-Feedforward-Schichten früherer Nemotron-Generationen werden durch MoE-Schichten ersetzt. Ein erlernter Router wählt eine kleine Teilmenge von Experten professional Token aus, zum Beispiel 6 von 128 routbaren Experten für Nano, wodurch die Anzahl der aktiven Parameter nahe bei 3,2 Milliarden bleibt, während das vollständige Modell 31,6 Milliarden Parameter enthält.
Mamba 2 übernimmt die Langstrecken-Sequenzmodellierung mit Aktualisierungen des Zustandsraumstils, Aufmerksamkeitsebenen bieten direkte Token-zu-Token-Interaktionen für struktursensible Aufgaben und MoE bietet Parameterskalierung ohne proportionale Rechenskalierung. Der wichtige Punkt ist, dass es sich bei den meisten Schichten entweder um schnelle Sequenzen oder spärliche Expertenberechnungen handelt und die volle Aufmerksamkeit nur dort eingesetzt wird, wo es für die Argumentation am wichtigsten ist.
Für Nemotron 3 Tremendous und Extremely fügt NVIDIA LatentMoE hinzu. Token werden in einen niedrigerdimensionalen latenten Raum projiziert, Experten arbeiten in diesem latenten Raum und dann werden die Ergebnisse zurückprojiziert. Dieses Design ermöglicht ein Vielfaches mehr Experten bei ähnlichen Kommunikations- und Rechenkosten, was eine stärkere Spezialisierung über Aufgaben und Sprachen hinweg unterstützt.
Tremendous und Extremely beinhalten auch die Multi-Token-Vorhersage. Mehrere Ausgabeköpfe teilen sich einen gemeinsamen Stamm und prognostizieren mehrere zukünftige Token in einem einzigen Durchgang. Dies verbessert während des Trainings die Optimierung und ermöglicht bei der Inferenz eine spekulative Dekodierung wie eine Ausführung mit weniger vollständigen Vorwärtsdurchgängen.
Trainingsdaten, Präzisionsformat und Kontextfenster
Nemotron 3 ist auf umfangreiche Textual content- und Codedaten trainiert. Das Forschungsteam berichtet von einem Vortraining für etwa 25 Billionen Token, mit mehr als 3 Billionen neuen einzigartigen Token im Laufe der Nemotron 2-Era. Nemotron 3 Nano verwendet Nemotron Widespread Crawl v2 Punkt 1, Nemotron CC Code und Nemotron Pretraining Code v2 sowie spezielle Datensätze für wissenschaftliche und argumentative Inhalte.
Tremendous und Extremely werden hauptsächlich in NVFP4 trainiert, einem 4-Bit-Gleitkommaformat, das für NVIDIA-Beschleuniger optimiert ist. Matrixmultiplikationsoperationen werden in NVFP4 ausgeführt, während Akkumulationen eine höhere Präzision erfordern. Dies reduziert den Speicherdruck und verbessert den Durchsatz, während die Genauigkeit nahe an Standardformaten bleibt.
Alle Nemotron 3-Modelle unterstützen Kontextfenster mit bis zu 1 Million Token. Die Architektur und die Schulungspipeline sind auf Lengthy-Horizon-Argumentation über diese Länge abgestimmt, was für Umgebungen mit mehreren Agenten, die große Spuren und einen gemeinsamen Arbeitsspeicher zwischen Agenten übertragen, von wesentlicher Bedeutung ist.
Wichtige Erkenntnisse
- Nemotron 3 ist eine dreistufige offene Modellfamilie für agentische KI: Nemotron 3 ist in den Varianten Nano, Tremendous und Extremely erhältlich. Nano verfügt über etwa 30 Milliarden Parameter mit etwa 3 Milliarden aktiven Parametern professional Token, Tremendous über etwa 100 Milliarden Parameter mit bis zu 10 Milliarden aktiven Parametern professional Token und Extremely über etwa 500 Milliarden Parameter mit bis zu 50 Milliarden aktiven Parametern professional Token. Die Familie zielt auf Multi-Agent-Anwendungen ab, die effizientes Lengthy-Context-Argumentation erfordern.
- Hybrid Mamba Transformer MoE mit 1 Million Token-Kontext: Nemotron 3-Modelle verwenden eine hybride Mamba 2 plus Transformer-Architektur mit einer spärlichen Expertenmischung und unterstützen ein 1-Millionen-Token-Kontextfenster. Dieses Design ermöglicht eine lange Kontextverarbeitung mit hohem Durchsatz, wobei professional Token nur eine kleine Untergruppe von Experten aktiv ist und die Aufmerksamkeit dort eingesetzt wird, wo sie für die Argumentation am nützlichsten ist.
- Latente MoE- und Multi-Token-Vorhersage in Tremendous und Extremely: Die Tremendous- und Extremely-Varianten fügen latentes MoE hinzu, bei dem Expertenberechnungen in einem reduzierten latenten Raum stattfinden, was die Kommunikationskosten senkt und mehr Experten ermöglicht, sowie Multi-Token-Vorhersageköpfe, die mehrere zukünftige Token professional Vorwärtsdurchlauf generieren. Diese Änderungen verbessern die Qualität und ermöglichen eine Beschleunigung des spekulativen Stils für lange Textual content- und Gedankenketten-Workloads.
- Umfangreiche Trainingsdaten und NVFP4-Präzision für Effizienz: Nemotron 3 ist auf etwa 25 Billionen Token vorab trainiert, mit mehr als 3 Billionen neuen Tokens im Vergleich zur vorherigen Era, und Tremendous und Extremely werden hauptsächlich in NVFP4 trainiert, einem 4-Bit-Gleitkommaformat für NVIDIA-GPUs. Diese Kombination verbessert den Durchsatz und reduziert die Speichernutzung, während die Genauigkeit nahe an der Standardgenauigkeit bleibt.
Schauen Sie sich das an Papier, Technischer Weblog Und Modellgewichte auf HF. Schauen Sie sich gerne bei uns um GitHub-Seite für Tutorials, Codes und Notebooks. Sie können uns auch gerne weiter folgen Twitter und vergessen Sie nicht, bei uns mitzumachen 100.000+ ML SubReddit und Abonnieren Unser Publication.
Der Beitrag NVIDIA AI veröffentlicht Nemotron 3: einen Hybrid-Mamba-Transformer-MoE-Stack für Lengthy-Context-Agent-KI erschien zuerst auf MarkTechPost.