
Die ESG-Berichterstattung bzw. Umwelt-, Sozial- und Governance-Berichterstattung ist oft überwältigend, weil die Daten von so vielen Orten stammen und es lange dauert, sie zusammenzuführen. Groups verbringen die meiste Zeit damit, Zahlen zu sammeln, anstatt zu interpretieren, was sie bedeuten. Agentische KI verändert diese Dynamik. Anstatt dass ein Chatbot Fragen beantwortet, erhalten Sie eine koordinierte Gruppe von KI-Helfern, die wie ein engagiertes Berichtsteam arbeiten. Sie sammeln Informationen, prüfen sie anhand relevanter Regeln und erstellen klare Zusammenfassungsentwürfe, damit sich die Mitarbeiter auf Erkenntnisse und nicht auf Papierkram konzentrieren können.
In diesem Leitfaden stellen wir Schritt für Schritt eine praktische, entwicklerorientierte Pipeline für die ESG-Berichterstattung vor, die Folgendes umfasst:
- Datenaggregation: Setzen Sie gleichzeitige Agenten ein, um Daten aus APIs und Dokumenten abzurufen und diese dann mithilfe der Vektorsuche zu indizieren (z. B. OpenAI-Einbettungen + FAISS).
- Compliance-Prüfungen: Führen Sie regulatorische Regeln (wie CSRD oder EU-Taxonomie) durch Codelogik oder SQL-Abfragen aus, um etwaige Probleme hervorzuheben.
- Intelligenter Bericht: Leiten Sie die Erstellung eines narrativen Berichts mithilfe von Retrieval-Augmented Technology (RAG) und LLM-Ketten und liefern Sie ihn als PDF.
Schritt 1: Aggregieren von ESG-Daten mit KI-Agenten
Zunächst ist es notwendig, alle relevanten Daten parallel zu erfassen. Zur Veranschaulichung: Ein Agent kann über die neueste ESG-Forschung einholen arXiv-APIein anderer kann über eine Nachrichten-API nach aktuellen regulatorischen Updates suchen und ein dritter kann die unternehmensinternen ESG-Dokumente klassifizieren.
In einem Experiment arbeiteten drei spezifische „Suchagenten“ gleichzeitig, um Anfragen an arXiv, einen internen Azure AI Search-Index und Nachrichtenquellen zu stellen. Anschließend stellte jeder Agent seine Daten der zentralen Wissensdatenbank zur Verfügung. Wir können diesen Prozess nachahmen Python durch Verwendung von Threads zusammen mit einem Vektorspeicher für die Dokumentensuche:
import requests
import concurrent.futures
from langchain.document_loaders import PyPDFLoader
from langchain.text_splitter import CharacterTextSplitter
from langchain.embeddings import OpenAIEmbeddings
from langchain.vectorstores import FAISS
from langchain.chat_models import ChatOpenAI
from langchain.chains import RetrievalQA
# ESG Information Aggregation and RAG Pipeline Instance
# 1. Exterior Search Features
# Instance: search arXiv for ESG-related papers
def search_arxiv(question, max_results=3):
"""Searches the arXiv API for papers."""
url = (
f"http://export.arxiv.org/api/question?"
f"search_query=all:{question}&max_results={max_results}"
)
res = requests.get(url)
# (Parse the XML response; right here we simply return uncooked textual content for brevity)
return res.textual content(:200) # present first 200 chars of outcome
# Instance: search information utilizing a hypothetical API (substitute with an actual information API)
def search_news(question, api_key):
"""Searches a hypothetical information API (wants substitute with an actual one)."""
# NOTE: This can be a placeholder URL and won't work and not using a actual information API
url = f"https://newsapi.instance.com/search?q={question}&apiKey={api_key}"
attempt:
# Simulate a request; this may seemingly fail with a 404/SSL error
res = requests.get(url, timeout=5)
articles = res.json().get("articles", ())
return (article("title") for article in articles(:3))
besides requests.exceptions.RequestException as e:
return (f"Error fetching information (API Placeholder): {e}")
# 2. Inner Doc Indexing Operate (for RAG)
def build_vector_index(pdf_paths):
"""Masses, splits, and embeds PDF paperwork right into a FAISS vector retailer."""
splitter = CharacterTextSplitter(chunk_size=800, chunk_overlap=100)
all_docs = ()
# NOTE: PyPDFLoader requires the information 'annual_report.pdf' and 'energy_audit.pdf' to exist
for path in pdf_paths:
attempt:
loader = PyPDFLoader(path)
pages = loader.load()
docs = splitter.split_documents(pages)
all_docs.lengthen(docs)
besides Exception as e:
print(f"Warning: Couldn't load PDF {path}. Skipping. Error: {e}")
if not all_docs:
# Return a easy object or increase an error if no paperwork have been loaded
print("Error: No paperwork have been efficiently loaded to construct the index.")
return None
embeddings = OpenAIEmbeddings()
vector_index = FAISS.from_documents(all_docs, embeddings)
return vector_index
# --- Essential Execution ---
# Paths to inner ESG PDFs (should exist in the identical listing or have full path)
pdf_files = ("annual_report.pdf", "energy_audit.pdf")
# Run exterior searches and doc indexing in parallel
print("Beginning parallel information fetching and index constructing...")
with concurrent.futures.ThreadPoolExecutor() as executor:
# Exterior Searches
future_arxiv = executor.submit(search_arxiv, "internet zero 2030")
# NOTE: Change 'YOUR_NEWS_API_KEY' with a sound key for an actual information API
future_news = executor.submit(
search_news,
"EU CSRD regulation",
"YOUR_NEWS_API_KEY"
)
# Construct vector index (will print warnings if PDFs do not exist)
future_index = executor.submit(build_vector_index, pdf_files)
# Accumulate outcomes
arxiv_data = future_arxiv.outcome()
news_data = future_news.outcome()
vector_index = future_index.outcome()
print("n--- Aggregated Outcomes ---")
print("ArXiv fetched information snippet:", arxiv_data)
print("High information titles:", news_data)
if vector_index:
print("nFAISS Vector Index efficiently constructed.")
# Instance continuation: Initialize the RAG chain
# llm = ChatOpenAI(model_name="gpt-3.5-turbo", temperature=0)
# qa_chain = RetrievalQA.from_chain_type(
# llm=llm,
# retriever=vector_index.as_retriever()
# )
# print("RAG setup full. Prepared to question inner paperwork.")
else:
print("RAG setup skipped as a consequence of failed vector index creation.")Ausgabe:


Hier haben wir einen Thread-Pool verwendet, um verschiedene Quellen gleichzeitig aufzurufen. Ein Thread ruft arXiv-Papiere ab, ein anderer ruft eine Nachrichten-API auf und ein anderer erstellt einen Vektorspeicher interner Dokumente. Der Vektorindex nutzt in FAISS gespeicherte OpenAI-Einbettungen und ermöglicht so eine Suche in natürlicher Sprache in den Dokumenten.
Abfrage der aggregierten Daten
Mit den gesammelten Daten können Agenten diese in natürlicher Sprache abfragen. Zum Beispiel können wir verwenden LangChain’s RAG-Pipeline, um Fragen zu den indizierten Dokumenten zu stellen:
# Create a retriever from the FAISS index
retriever = vector_index.as_retriever(
search_type="similarity",
search_kwargs={"okay": 4}
)
# Initialize an LLM (e.g., GPT-4) and a RetrievalQA chain
llm = ChatOpenAI(temperature=0, mannequin="gpt-4")
qa_chain = RetrievalQA(llm=llm, retriever=retriever)
# Ask a pure language query about ESG information
reply = qa_chain.run("What have been the Scope 2 emissions for 2023?")
print("RAG reply:", reply)Das LAPPEN Mit diesem Ansatz kann der Agent relevante Dokumentsegmente abrufen (über eine Ähnlichkeitssuche) und dann eine Antwort generieren. In einer Demonstration konvertierte ein Agent einfache englische Abfragen in SQL, um numerische Daten (z. B. „Scope-2-Emissionen im Jahr 2024“) aus der Emissionsdatenbank abzurufen. Bei Bedarf können wir auf ähnliche Weise einen SQL-Abfrageschritt einbetten, beispielsweise mit SQLite in Python:
import sqlite3
# Instance: retailer some emissions information in SQLite
conn = sqlite3.join(':reminiscence:')
cursor = conn.cursor()
cursor.execute("CREATE TABLE emissions (12 months INTEGER, scope2 REAL)")
cursor.execute("INSERT INTO emissions VALUES (2023, 1725.4)")
conn.commit()
# Easy SQL question for numeric information
cursor.execute("SELECT scope2 FROM emissions WHERE 12 months=2023")
scope2_emissions = cursor.fetchone()(0)
print("Scope 2 emissions 2023 (from DB):", scope2_emissions) In der Praxis könnten Sie einen LangChain-SQL-Agenten integrieren, um natürliche Sprache zu konvertieren SQL automatisch. Unabhängig von der Quelle fließen alle diese Datenpunkte – von PDFs, APIs und Datenbanken – in eine einheitliche Wissensdatenbank für die Berichtspipeline ein.
Schritt 2: Automatisierte Compliance-Prüfungen
Nachdem die Rohkennzahlen erfasst wurden, folgt als nächstes der Compliance-Assurance-Prozess. Die Mischung aus Code-Logik und LLM-Unterstützung kann dabei helfen. Beispielsweise können wir die Regeln der Domäne abbilden (z. B. die Kriterien der EU-Taxonomie) und dann Prüfungen durchführen:
# Instance ESG metrics extracted from information aggregation
metrics = {
"scope1_tCO2": 980,
"scope2_tCO2": 1725.4,
"renewable_percent": 25, # p.c of power from renewables
"water_usage_liters": 50000,
"reported_water_liters": 48000
}
# Easy rule-based compliance checks
def run_compliance_checks(metrics):
"""
Runs fundamental checks in opposition to predefined ESG compliance guidelines.
"""
points = ()
# Instance rule 1: EU Taxonomy requires >= 30% renewable power
if metrics("renewable_percent") < 30:
points.append("Renewables under EU taxonomy threshold (30%).")
# Instance rule 2: Consistency examine (tolerance of 1000 liters)
if abs(metrics("water_usage_liters") - metrics("reported_water_liters")) > 1000:
points.append("Water utilization mismatch between operations information and monetary report.")
return points
# Execute the checks
compliance_issues = run_compliance_checks(metrics)
print("Compliance points discovered:", compliance_issues)Diese einfache Funktion identifiziert alle Regeln, gegen die verstoßen wurde. Im wirklichen Leben würden Sie Regeln vielleicht aus einer Wissensdatenbank oder Konfiguration beziehen. Compliance-Prüfungen werden in agentenbasierten Systemen häufig in Rollen unterteilt. Die Kriterien-/Zuordnungsagenten verknüpfen die extrahierten Daten mit den spezifischen Offenlegungsfeldern oder den Kriterien der Taxonomie, während die Berechnungsagenten die numerischen Prüfungen oder Konvertierungen durchführen. Um ein Beispiel zu nennen: Einer der Agenten könnte prüfen, ob eine bestimmte Aktivität den von der Taxonomie festgelegten „Do No Vital Hurt“-Kriterien entspricht, oder könnte mithilfe von Textual content-to-SQL-Abfragen die Gesamtemissionen ableiten.
Textual content-to-SQL-Beispiel (non-compulsory)
LangChain bietet SQL-Instruments zur Automatisierung dieses Schritts. Sie können beispielsweise einen SQL-Agenten erstellen, der Ihr Datenbankschema untersucht und Abfragen generiert. Hier ist eine Skizze mit der SQLDatabase von LangChain:
from langchain.brokers import create_sql_agent
from langchain.sql_database import SQLDatabase
# Arrange a SQLite DB (similar as above)
db = SQLDatabase.from_uri("sqlite:///:reminiscence:", include_tables=("emissions"))
# Create an agent that may reply questions utilizing the DB
sql_agent = create_sql_agent(llm=llm, db=db, verbose=False)
query_result = sql_agent.run("What's the whole Scope 2 emissions for 2023?")
print("SQL Agent outcome:", query_result)Dieser Agent untersucht die Emissionstabelle und erstellt eine Abfrage zur Berechnung der Antwort. Er überprüft sie, bevor er ein Ergebnis zurückgibt. (Stellen Sie in der Praxis sicher, dass Ihre Datenbankberechtigungen gesperrt sind, da die Ausführung von modellgeneriertem SQL Risiken birgt.)
Schritt 3: Generatives Good Reporting mit RAG-Agenten
Nach der Validierung besteht die letzte Section darin, den narrativen Bericht zu verfassen. Hier nimmt ein Syntheseagent die bereinigten Daten und schreibt für Menschen lesbare Offenlegungen. Hierfür können wir LLM-Ketten verwenden, oft mit LAPPEN um bestimmte Zahlen und Zitate aufzunehmen. Beispielsweise könnten wir das Modell mit den Schlüsselmetriken auffordern und es eine Zusammenfassung erstellen lassen:
from langchain.prompts import PromptTemplate
from langchain.chains import LLMChain
# Put together a immediate template to generate an govt abstract
prompt_template = """
Write a concise govt abstract of the ESG report utilizing the info under.
Embody key figures and context:
{summary_data}
"""
template = PromptTemplate(
input_variables=("summary_data"),
template=prompt_template
)
# Instance information to incorporate within the abstract
findings = f"""
- Scope 1 CO2 emissions: {metrics('scope1_tCO2')} tCO2e
- Scope 2 CO2 emissions: {metrics('scope2_tCO2')} tCO2e
- Renewable power share: {metrics('renewable_percent')}%
"""
chain = LLMChain(llm=ChatOpenAI(temperature=0.2), immediate=template)
summary_text = chain.run({"summary_data": findings})
print("Generated abstract:n", summary_text)Ausgabe:
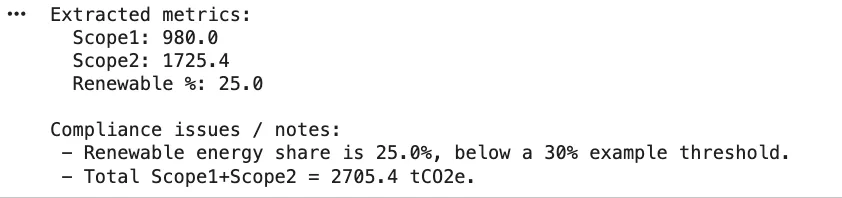
=== ANSWER ===
Within the **Sustainability Annual Report 2024**, the reported emissions are as follows:- **Scope 1 Emissions**: 980 tCO2e
- **Scope 2 Emissions**: 1,725.4 tCO2eThe entire emissions quantity to **2,705.4 tCO2e**.
A notable compliance hole is recognized within the **Power Audit Abstract - 2024**, the place the renewable power share is reported at **28%**, which is under the regulatory goal of **30%**. This means a necessity for enchancment in renewable power utilization to fulfill compliance requirements.
Moreover, the report highlights a advice so as to add **500 kW** of rooftop photo voltaic to reinforce renewable power capability.
Alternativ können Sie eine verkettete RetrievalQA oder einen Agenten erstellen, der die indizierten Dokumente und Daten abruft und dann den LLM aufruft, um jeden Abschnitt zu schreiben. Wenn Sie beispielsweise LangChains RetrievalQA wie oben verwenden, könnten Sie den Agenten bitten, „die Emissionen von Scope 1 und 2 zusammenzufassen und etwaige Compliance-Lücken hervorzuheben“. Der Schlüssel liegt darin, dass jede Antwort Quellen oder Methoden zitieren kann, was eine Beweisspur ermöglicht.
Schritt 4: Erstellen des Abschlussberichts
Nach dem Entwurf wäre es möglich, die Abschnitte zu kombinieren und zu formatieren, da dies auf sehr einfache Weise mithilfe von erfolgt fpdf. Zum Verfassen der Zusammenfassung wird PDF verwendet.
from fpdf import FPDF
pdf = FPDF()
pdf.add_page()
pdf.set_font("Arial", dimension=14)
pdf.multi_cell(0, 10, summary_text)
pdf.output("esg_report_summary.pdf")
print("PDF report generated.")Ausgabe:

In einer vollständigen Pipeline könnte man viele Abschnitte (wie Kulturen, Emissionen, Energie, Wasser usw.) erstellen und diese zusammenfügen. Agenten könnten sogar bei der Bearbeitung durch den Menschen behilflich sein: Die Antwortentwürfe werden in einer Chat-Benutzeroberfläche angezeigt, damit Fachexperten sie bewerten und verbessern können. Nach der Genehmigung kann ein Syntheseagent die endgültige PDF- oder Textvorlage zusammen mit erforderlichen Tabellen und Abbildungen erstellen.
Letztendlich reduziert dieser Agenten-Workflow den Zeitaufwand für die manuelle Berichterstattung von Wochen auf Stunden: Agenten füllen die Fragebogenelemente stapelweise aus den Daten aus, markieren etwaige Probleme, lassen sie von Menschen überprüfen und erstellen dann einen vollständigen Bericht. Zur Verdeutlichung enthält jede Antwort Inline-Referenzen und Berechnungsschritte. Das Ergebnis ist ein prüfungsbereiter ESG-Bericht, der durch Code und KI und nicht durch menschliche Hand erstellt wurde.
Abschluss
Ein Finish-to-Finish-ESG-Workflow kann viel reibungsloser ablaufen, wenn mehrere davon vorhanden sind KI-Agenten die Final teilen. Sie rufen gleichzeitig Informationen aus Forschungsquellen, Newsfeeds und internen Dateien ab, prüfen die Daten anhand relevanter Regeln und helfen durch kontextbezogene Generierung bei der Gestaltung des Abschlussberichts. Die Codebeispiele zeigen, wie jeder Teil sauber und modular bleibt, sodass es einfach ist, echte APIs einzubinden, den Regelsatz zu erweitern oder die Logik anzupassen, wenn sich Vorschriften ändern. Der wahre Gewinn ist die Zeit: Groups verbringen weniger Energie damit, Daten nachzujagen und mehr darauf zu konzentrieren, zu verstehen, was sie bedeuten. Mit dieser Pipeline verfügen Sie über eine klare Blaupause für den Aufbau Ihres eigenen agentengesteuerten ESG-Berichtssystems.
Häufig gestellte Fragen
A. Es teilt die Arbeitslast auf autonome Agenten auf, die parallel Daten abrufen, die Einhaltung prüfen und Abschnitte entwerfen. Der größte Teil der Routinearbeit entfällt und die Menschen müssen die Arbeit überprüfen und verfeinern, anstatt alles von Hand zusammenzusetzen.
A. Nicht wirklich. Ein typisches Setup verwendet Python, LangChain, Vektorsuchtools wie FAISS und eine LLM-API. Bei Bedarf können Sie später mit Workflow-Orchestratoren oder Cloud-Funktionen skalieren.
A. Ja. Compliance-Regeln befinden sich im Code oder in der Konfiguration, sodass Sie Regelmodule aktualisieren oder hinzufügen können, ohne den Relaxation der Pipeline zu beeinträchtigen. Agenten wenden bei Prüfungen automatisch die neueste Logik an.
Information Science Trainee bei Analytics Vidhya
Derzeit arbeite ich als Information Science Trainee bei Analytics Vidhya, wo ich mich auf die Entwicklung datengesteuerter Lösungen und die Anwendung von KI/ML-Techniken zur Lösung realer Geschäftsprobleme konzentriere. Meine Arbeit ermöglicht es mir, fortschrittliche Analysen, maschinelles Lernen und KI-Anwendungen zu erforschen, die es Unternehmen ermöglichen, intelligentere, evidenzbasierte Entscheidungen zu treffen.
Mit einem starken Fundament in den Bereichen Informatik, Softwareentwicklung und Datenanalyse ist es mir eine Leidenschaft, KI zu nutzen, um wirkungsvolle, skalierbare Lösungen zu schaffen, die die Lücke zwischen Technologie und Geschäft schließen.
📩 Du kannst mich auch erreichen unter (electronic mail protected)
Melden Sie sich an, um weiterzulesen und von Experten kuratierte Inhalte zu genießen.