dieser Serie werden wir darüber sprechen tiefes Lernen.
Und wenn man über Deep Studying spricht, denken wir sofort an diese Bilder von Architekturen tiefer neuronaler Netze mit vielen Schichten, Neuronen und Parametern.
In der Praxis liegt der eigentliche Wandel, den Deep Studying mit sich bringt, woanders.
Es geht um Lernen von Datendarstellungen.
In diesem Artikel konzentrieren wir uns auf Texteinbettungenerklären Sie ihre Rolle in der maschinellen Lernlandschaft und zeigen Sie, wie sie sein können in Excel verstanden und untersucht.
1. Klassisches maschinelles Verdienen vs. Deep Studying
In diesem Teil werden wir diskutieren, warum die Einbettung eingeführt wird.
1.1 Wo passt Deep Studying?
Um Einbettungen zu verstehen, müssen wir zunächst den Stellenwert von Deep Studying klären.
Wir werden den Begriff verwenden klassisches maschinelles Lernen um Methoden zu beschreiben, die nicht auf tiefen Architekturen basieren.
Alle vorherigen Artikel befassen sich mit klassischem maschinellen Lernen, das auf zwei komplementäre Arten beschrieben werden kann.
Lernparadigmen
- Überwachtes Lernen
- Unbeaufsichtigtes Lernen
Modellfamilien
- Distanzbasierte Modelle
- Baumbasierte Modelle
- Gewichtsbasierte Modelle
In dieser Serie haben wir bereits die Lernalgorithmen hinter diesen Modellen untersucht. Insbesondere das haben wir gesehen Gefälleabstieg gilt für alle gewichtsbasierten Modelle, von der linearen Regression bis hin zu neuronalen Netzen.
Deep Studying wird oft auf neuronale Netze mit vielen Schichten reduziert.
Aber diese Erklärung ist unvollständig.
Aus Optimierungssicht führt Deep Studying keine neue Lernregel ein.
Was bedeutet es additionally?
1.2 Deep Studying als Datenrepräsentationslernen
Beim Deep Studying geht es darum wie Options erstellt werden.
Statt Options manuell zu entwerfen, Deep Studying lernt Darstellungen automatischoft durch mehrere aufeinanderfolgende Transformationen.
Dies wirft auch eine wichtige konzeptionelle Frage auf:
Wo ist die Grenze zwischen Function Engineering und Modelllernen?
Einige Beispiele machen dies deutlicher:
- Die polynomielle Regression ist immer noch ein lineares Modell, aber die Merkmale sind polynomial
- Kernel-Methoden projizieren Daten in einen hochdimensionalen Merkmalsraum
- Dichtebasierte Methoden transformieren die Daten implizit vor dem Lernen
Deep Studying setzt diese Idee fort, allerdings in großem Maßstab.
Aus dieser Perspektive gehört Deep Studying zu:
- Die Function-Engineering-Philosophiezur Darstellung
- Die gewichtsbasierte Modellfamiliezum Lernen
1.3 Bilder und Faltungs-Neuronale Netze
Bilder werden dargestellt als Pixel.
Aus technischer Sicht sind Bilddaten bereits numerisch und strukturiert: ein Zahlenraster. Allerdings ist die Info Die in diesen Pixeln enthaltenen Informationen sind nicht so strukturiert, dass klassische Modelle sie leicht ausnutzen können.
Pixel kodieren nicht explizit: Kanten, Formen, Texturen oder Objekte.
Convolutional Neural Networks (CNNs) sind darauf ausgelegt Informationen aus Pixeln erstellen. Sie wenden Filter an, um lokale Muster zu erkennen, und kombinieren sie dann schrittweise zu Darstellungen auf höherer Ebene.
Ich habe eine veröffentlicht dieser Artikel Zeigt, wie CNNs in Excel implementiert werden können, um diesen Prozess explizit zu machen.

Bei Bildern besteht die Herausforderung darin nicht um die Daten numerisch zu machen, sondern um aussagekräftige Darstellungen extrahieren aus bereits numerischen Daten.
1.4 Textdaten: ein anderes Downside
Textual content stellt eine grundlegend andere Herausforderung dar.
Im Gegensatz zu Bildern ist Textual content von Natur aus nicht numerisch.
Vor der Modellierung von Kontext oder Reihenfolge ist das erste Downside grundlegender:
Wie stellen wir Wörter numerisch dar?
Der erste Schritt besteht darin, eine numerische Darstellung für Textual content zu erstellen.
Beim Deep Studying für Textual content wird dieser Schritt von übernommen Einbettungen.
Durch Einbettungen werden diskrete Symbole (Wörter) in Vektoren umgewandelt, mit denen Modelle arbeiten können. Sobald Einbettungen vorhanden sind, können wir Folgendes modellieren: Kontext, Reihenfolge und Beziehungen zwischen Wörtern.
In diesem Artikel konzentrieren wir uns auf diesen ersten und wesentlichen Schritt:
wie Einbettungen numerische Darstellungen für Textual content erstellenund wie dieser Prozess in Excel untersucht werden kann.
2. Zwei Möglichkeiten, Texteinbettungen zu lernen
In diesem Artikel verwenden wir die IMDB-Datensatz zu Filmkritiken um beide Ansätze zu veranschaulichen. Der Datensatz wird unter der Apache-Lizenz 2.0 vertrieben.
Es gibt zwei Hauptmethoden, um Einbettungen für Textual content zu lernen, und wir werden beide mit diesem Datensatz durchführen:
- überwacht: Wir erstellen Einbettungen, um die Stimmung vorherzusagen
- unbeaufsichtigt oder selbstüberwacht: Wir werden den Word2vec-Algorithmus verwenden
In beiden Fällen ist das Ziel dasselbe:
um Wörter in numerische Vektoren umzuwandeln, die von Modellen des maschinellen Lernens verwendet werden können.
Bevor wir diese beiden Ansätze vergleichen, müssen wir zunächst klären, was Einbettungen sind und in welcher Beziehung sie zum klassischen maschinellen Lernen stehen.

2.1 Einbettungen und klassisches maschinelles Lernen
Beim klassischen maschinellen Lernen werden kategoriale Daten normalerweise wie folgt verarbeitet:
- Etikettenkodierungdas feste Ganzzahlen zuweist, aber eine künstliche Ordnung einführt
- One-Sizzling-Kodierungwodurch die Ordnung entfernt wird, aber hochdimensionale, dünn besetzte Vektoren erzeugt werden
Wie sie eingesetzt werden können, hängt von der Artwork der Modelle ab.
Distanzbasierte Modelle One-Sizzling-Codierung kann nicht effektiv verwendet werden, da am Ende alle Kategorien gleich weit voneinander entfernt sind. Die Etikettenkodierung könnte nur funktionieren, wenn wir den Kategorien aussagekräftige numerische Werte zuordnen können, was in klassischen Modellen im Allgemeinen nicht der Fall ist.
Gewichtsbasierte Modelle kann One-Sizzling-Codierung verwenden, da das Modell eine Gewichtung für jede Kategorie lernt. Im Gegensatz dazu sind bei der Etikettenkodierung die numerischen Werte fest und können nicht angepasst werden, um sinnvolle Beziehungen darzustellen.
Baumbasierte Modelle Behandeln Sie alle Variablen als kategoriale Aufteilungen und nicht als numerische Größen, was die Etikettenkodierung in der Praxis akzeptabel macht. Allerdings erfordern die meisten Implementierungen, einschließlich scikit-learn, immer noch numerische Eingaben. Daher müssen Kategorien in Zahlen umgewandelt werden, entweder durch Label-Kodierung oder One-Sizzling-Kodierung. Wenn die numerischen Werte eine semantische Bedeutung hätten, wäre dies wiederum von Vorteil.
Insgesamt verdeutlicht dies eine Einschränkung klassischer Ansätze:
Kategoriewerte sind fest und werden nicht gelernt.
Einbettungen erweitern diese Idee um Erlernen der Darstellung selbst.
Jedes Wort ist mit einem trainierbaren Vektor verknüpft, wodurch die Darstellung von Kategorien zu einem Lernproblem und nicht zu einem Vorverarbeitungsschritt wird.
2.2 Überwachte Einbettungen
Beim überwachten Lernen werden Einbettungen im Rahmen einer Vorhersageaufgabe gelernt.
Der IMDB-Datensatz enthält beispielsweise Beschriftungen zur In-Sentiment-Analyse. So können wir eine sehr einfache Architektur erstellen:
In unserem Fall können wir eine sehr einfache Architektur verwenden: Jedes Wort wird einem zugeordnet eindimensionale Einbettung
Dies ist möglich, da das Ziel eine binäre Stimmungsklassifizierung ist.

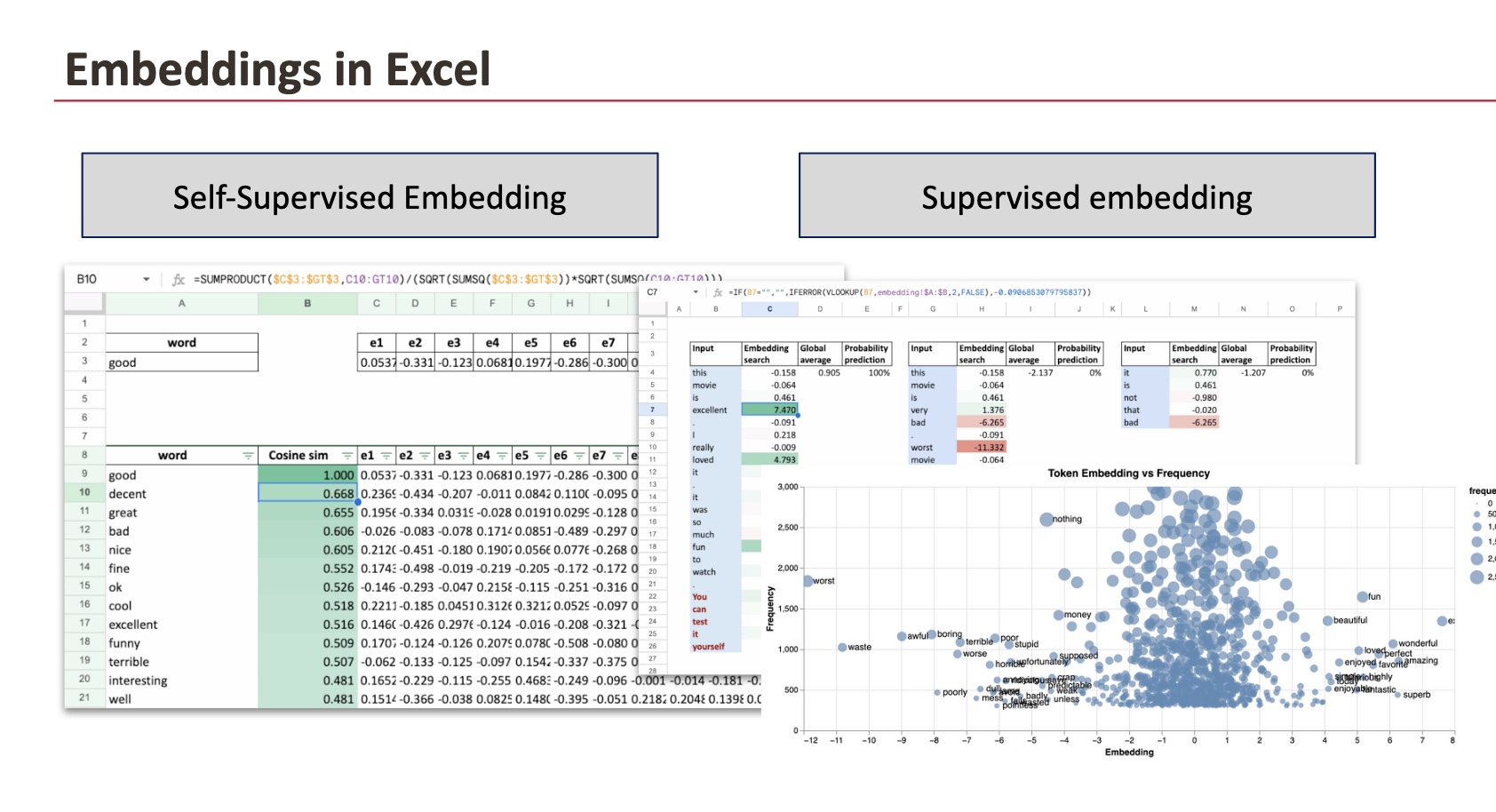
Sobald die Schulung abgeschlossen ist, können wir es tun Exportieren Sie die Einbettungen und erkunden Sie sie in Excel.
Wenn man die Einbettungen auf der x-Achse und die Worthäufigkeit auf der y-Achse aufträgt, zeigt sich ein klares Muster:
- Optimistic Werte werden mit Wörtern wie verbunden exzellent oder wunderbar,
- Detrimental Werte werden mit Wörtern wie verbunden am schlimmsten oder Abfall
Abhängig von der Initialisierung kann das Vorzeichen umgekehrt werden, da die logistische Regressionsschicht auch über Parameter verfügt, die die endgültige Vorhersage beeinflussen.

Schließlich rekonstruieren wir in Excel die vollständige Pipeline, die der Architektur entspricht, die wir frühzeitig definiert haben.
Eingabespalte
Der Eingabetext (eine Rezension) wird in Wörter zerschnitten und jede Zeile entspricht einem Wort.
Einbettungssuche
Mithilfe einer Nachschlagefunktion wird der jedem Wort zugeordnete Einbettungswert aus der während des Trainings erlernten Einbettungstabelle abgerufen.
Globaler Durchschnitt
Die globale durchschnittliche Einbettung wird berechnet, indem die Einbettungen aller bisher gesehenen Wörter gemittelt werden. Dies entspricht einer sehr einfachen Satzdarstellung: dem Mittelwert von Wortvektoren.
Wahrscheinlichkeitsvorhersage
Die gemittelte Einbettung wird dann durch eine Logistikfunktion geleitet, um eine Stimmungswahrscheinlichkeit zu erzeugen.

Was wir beobachten
- Worte mit stark optimistic Einbettungen (Zum Beispiel exzellent, Liebe, Spaß) treiben den Durchschnitt nach oben.
- Worte mit stark adverse Einbettungen (Zum Beispiel am schlimmsten, schrecklich, Abfall) ziehen den Durchschnitt nach unten.
- Neutrale oder schwach gewichtete Wörter haben kaum Einfluss.
Wenn mehr Wörter hinzugefügt werden, stabilisiert sich die globale durchschnittliche Einbettung und die Stimmungsvorhersage wird sicherer.
2.3 Word2Vec: Einbettungen aus Kookkurrenz
In Word2Vec, Ähnlichkeit bedeutet nicht, dass zwei Wörter die gleiche Bedeutung haben.
Es bedeutet, dass sie tauchen in ähnlichen Zusammenhängen auf.
Word2Vec lernt Worteinbettungen durch Ansehen welche Wörter häufig gleichzeitig vorkommen innerhalb eines festen Fensters im Textual content. Zwei Wörter gelten als ähnlich, wenn sie häufig vorkommen um die gleichen benachbarten Wörter herumauch wenn ihre Bedeutungen entgegengesetzt sind.
Wie in der Excel-Tabelle unten gezeigt, berechnen wir die Kosinusähnlichkeit für das Wort Intestine und rufen Sie die ähnlichsten Wörter ab.

Aus Sicht des Modells sind die umgebenden Wörter nahezu identisch. Das Einzige, was sich ändert, ist das Adjektiv selbst.
Dadurch lernt Word2Vec das „intestine“ und „schlecht“ spielen in der Sprache eine ähnliche Rolleauch wenn ihre Bedeutung entgegengesetzt ist.
Additionally erfasst Word2Vec Verteilungsähnlichkeitnicht semantische Polarität.
Eine nützliche Möglichkeit, darüber nachzudenken, ist:
Wörter sind nahe beieinander, wenn sie an denselben Stellen verwendet werden.
2.4 Wie Einbettungen verwendet werden
In modernen Systemen wie z RAG (Retrieval-Augmented Technology)Einbettungen werden häufig verwendet, um Dokumente oder Passagen zur Beantwortung von Fragen abzurufen.
Dieser Ansatz weist jedoch Einschränkungen auf.
Die am häufigsten verwendeten Einbettungen werden in a trainiert selbstüberwacht basierend auf Koexistenz oder kontextbezogenen Vorhersagezielen. Dadurch erfassen sie allgemeine Sprachähnlichkeiten und keine aufgabenspezifische Bedeutung.
Das bedeutet:
- Einbettungen können jedoch Textual content abrufen, der sprachlich ähnlich ist nicht related
- Semantische Nähe ist keine Garantie Richtigkeit der Antwort
Andere Einbettungsstrategien können verwendet werden, einschließlich aufgabenangepasster oder überwachter Einbettungen, aber sie bleiben im Kern oft selbstüberwacht.
Daher ist es wichtig zu verstehen, wie Einbettungen erstellt werden, was sie kodieren und was nicht, bevor sie in nachgelagerten Systemen wie RAG verwendet werden.
Abschluss
Einbettungen sind erlernte numerische Darstellungen von Wörtern, die Ähnlichkeit messbar machen.
Unabhängig davon, ob sie durch Aufsicht oder durch gemeinsames Vorkommen erlernt wurden, bilden Einbettungen Wörter basierend auf ihrer Verwendung in Daten Vektoren zu. Durch den Export nach Excel können wir diese Darstellungen direkt prüfen, Ähnlichkeiten berechnen und verstehen, was sie erfassen und was nicht.
Dies macht Einbettungen weniger mysteriös und verdeutlicht ihre Rolle als Grundlage für komplexere Systeme wie Retrieval oder RAG.