
Den Textual content in einer unordentlichen PDF-Datei zu erhalten, ist eher problematisch als hilfreich. Das Downside liegt nicht in der Fähigkeit, Pixel in Textual content umzuwandeln, sondern darin, die Struktur des Dokuments beizubehalten. Tabellen, Überschriften und Bilder sollten in der richtigen Reihenfolge sein. Beim Einsatz von Mistral OCR 3 geht es nicht mehr um die Textkonvertierung, sondern um die Produktion geschäftsverwertbarer Informationen. Das neue KI-gestützte Device zur Dokumentenextraktion soll die Extraktion komplizierter Dateien verbessern.
In diesem Leitfaden wird das Mistral OCR 3-Modell erläutert. Wir werden auch die neuen Funktionen und ihre Verwendungsmethoden besprechen und abschließend mit einem Vergleich mit dem Open-Weights-DeepSeek-OCR-Modell abschließen.
Mistral OCR 3 verstehen
Mistral stellt sein neues Device vor OCR 3 als Allzweckgerät. Es befasst sich mit der großen Anzahl von Dokumenten, die in Organisationen vorhanden sind, und beschränkt sich nicht nur auf saubere OCR-Scans von Rechnungen. Mistral stellt die wichtigsten Verbesserungen vor, die einige der häufigen OCR-Fehler beheben.
- Handschrift: Das Modell erhält verbesserte Arbeit beim Drucken und Handschreiben von Textual content auf Druckern.
- Formulare: Es verarbeitet komplizierte Strukturen aus Kästchen, Beschriftungen und gemischten Textarten. Dies ist typisch für Rechnungen, Quittungen und Regierungsdokumente.
- Gescannte Dokumente: Das System wird weniger durch Scanartefakte wie Schräglauf, Verzerrung, niedrige Auflösung usw. beeinträchtigt.
- Komplexe Tabellen: Es bietet eine verbesserte Rekonstruktionstabelle. Dies umfasst eine Kombination von Zellen sowie mehrere Zeilen. Die Ausgabe erfolgt in HTML-Tags, um das ursprüngliche Format beizubehalten.
Mistral gibt an, das Modell anhand interner Benchmarks getestet zu haben, was echte Geschäftsfälle bedeutet.
Was ist neu in OCR 3?
Die endgültige Model bietet Entwicklern zwei wesentliche Änderungen: Qualität der Ausgabe und Steuerung. Diese Eigenschaften verstärken die organisierte Extraktionsleistung des Modells.
1. Neue Steuerelemente für Dokumentelemente: Das Changelog des Mistral OCR 3 verknüpft das neue Modell mit neuartigen Parametern und Ausgaben. Tableformat kann jetzt zwischen Markdown und HTML wählen. Extractheader, Extractfooter und Hyperlinks helfen auch bei der Handhabung spezieller Dokumentabschnitte. Dies ist eine der Grundlagen seines Dokumenten-KI-Programs.
2. Ein UI-Spielplatz für schnelles Testen: Mistral OCR 3 verfügt über seine OCR-API und einen „Doc AI Playground“ in Mistral AI Studio. Auf einer Spielwiese lassen sich herausfordernde Szenarien, wie z. B. fehlerhafte Scans oder Scribbles, sinnvoll testen. Bevor Sie Ihren Prozess automatisieren, können Sie Parameter wie das Tabellenformat ändern und die Ausgaben überprüfen. Erfolgreiche OCR-Projekte sollten über eine schnelle Feedbackschleife verfügen.
3. Abwärtskompatibilität: Mistral bestätigt, dass OCR 3 mit dem Relaxation seiner Vorgängerversion kompatibel ist. Dadurch können Groups ihre Systeme im Laufe der Zeit modernisieren, ohne ihre Pipeline neu schreiben zu müssen.
Modelle und Preise
Das soll OCR 3 sein mistral-ocr-2512. Die Dokumentation verweist auch auf einen mistral-ocr-latest-Alias. Die Preisgestaltung erfolgt auf Seitenbasis.
- 2 $ professional 1000 Seiten
- 3 $ professional 1000 kommentierte Seiten
Der zweite Preis wäre, wenn Sie Anmerkungen verwenden, um eine strukturierte Extraktion durchzuführen. Diese Kosten sollten von den Groups frühzeitig im Funds berücksichtigt werden.
Praktisch mit dem Doc AI Playground
Sie können über den Doc AI Playground in Mistral AI Studio auf Mistral OCR 3 zugreifen. Dies ermöglicht eine schnelle, praxisnahe Prüfung.
- Öffnen Sie den Doc AI Playground in Mistral AI Studio. Gehen Sie rüber zu console.mistral.ai/construct/document-ai/ocr-playground
Wenn Sie sehen: „Wählen Sie einen Plan aus“, dann melden Sie sich mit Ihrer Nummer an und Sie können Folgendes sehen
- Laden Sie eine PDF- oder Bilddatei hoch. Beginnen Sie mit einem kniffligen Dokument, etwa einem gescannten Formular mit einer Tabelle.
Warum dieses Bild?
Eine saubere Rechnung mit einer Tabelle (toller erster Check für die OCR 3-Tabellenrekonstruktion)
Verwenden Sie dies, um Folgendes zu überprüfen:
- Lesereihenfolge (Kopffelder vs. Einzelposten)
- Tabellenextraktion (Zeilen/Spalten, Summen)
- Kopf-/Fußzeilenextraktion
- Wählen Sie ggf. das OCR 3-Modell aus
mistral-ocr-2512oder spätestens. - Wählen Sie ein Tabellenformat. Verwenden Sie HTML für strukturelle Genauigkeit oder Markdown, wenn Ihre Pipeline es verwendet.

- Führen Sie den Prozess aus und prüfen Sie die Ausgabe. Überprüfen Sie die Lesereihenfolge und den Tabellenaufbau.
Ausgabe:
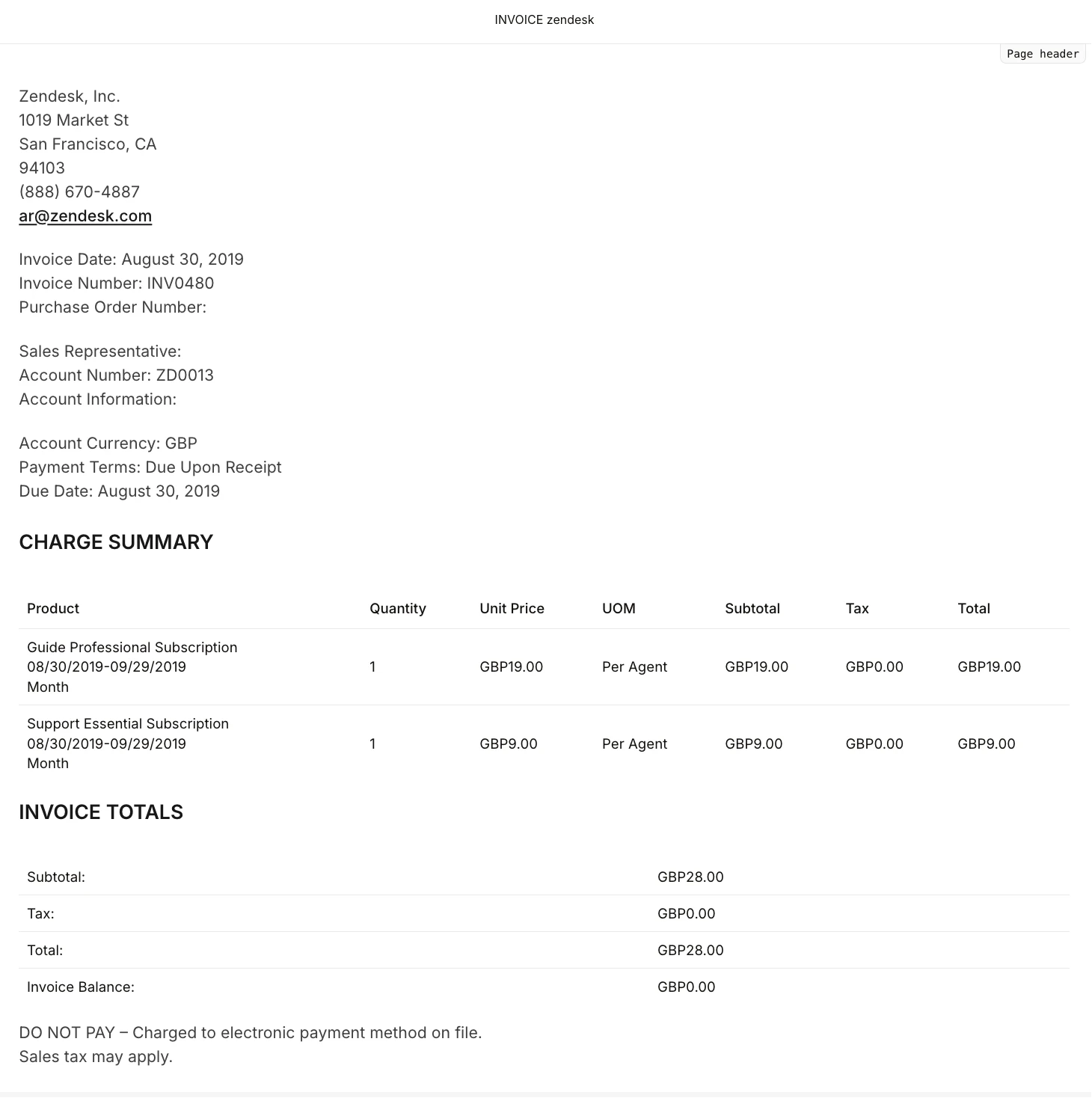
- Dieser erste OCR 3-Durchlauf ist für eine saubere digitale Rechnung im Wesentlichen fehlerfrei.
- Alle Schlüsselfelder, Layoutabschnitte und die Gebührenübersichtstabelle werden korrekt erfasst, ohne Textfehler oder Halluzinationen.
- Tabellenstruktur und numerische Konsistenz bleiben erhalten, was für die Finanzautomatisierung von entscheidender Bedeutung ist.
- Es zeigt, dass OCR 3 für Standardrechnungen sofort produktionsbereit ist.
Praktisch mit der OCR-API
Possibility A: OCR eines Dokuments von einer URL
Die OCR-API unterstützt Dokument-URLs. Es gibt Textual content und strukturierte Elemente zurück.
Hier ist ein Python-Beispiel mit dem offiziellen SDK.
import os
from mistralai import Mistral, DocumentURLChunk
shopper = Mistral(api_key=os.environ("MISTRAL_API_KEY"))
resp = shopper.ocr.course of(
mannequin="mistral-ocr-2512",
doc=DocumentURLChunk(document_url="https://arxiv.org/pdf/2510.04950"),
table_format="html",
extract_header=True,
extract_footer=True,
)
print(resp.pages(0).markdown(:1000))Ausgabe:

Possibility B: Dateien hochladen und OCR per file_id
Diese Methode funktioniert für personal Dokumente, nicht für eine öffentliche URL. Die API von Mistral verfügt über eine /v1/information Endpunkt für Uploads.
Laden Sie zunächst die Datei mit hoch Python.
import os
from mistralai import Mistral
shopper = Mistral(api_key=os.environ("MISTRAL_API_KEY"))
uploaded = shopper.information.add(
file={"file_name": "doc.pdf", "content material": open("/content material/Resume-Pattern-1-Software program-Engineer.pdf", "rb")},
objective="ocr",
)
resp = shopper.ocr.course of(
mannequin="mistral-ocr-2512",
doc={"file_id": uploaded.id},
table_format="html",
)
print(resp.pages(0).markdown(:1000))Ausgabe:
Umgang mit Bildern und Tabellen
Bilder und Tabellen im Markdown werden durch Platzhalter gekennzeichnet, die von der OCR-Ausgabe von Mistral verwendet werden. Der tatsächliche extrahierte Inhalt wird in verschiedenen Arrays zurückgegeben. Dieses Format bietet Ihnen die Möglichkeit, den Markdown als primäre Dokumentansicht festzulegen. Die Bild- und Tabellenressourcen können dann am gewünschten Ort abgelegt werden.
Einfache OCR ist der erste Schritt. Strukturierte Extraktion liefert den wahren Wert. Die Funktion der Ideenanmerkungen wird in der Dokumenten-KI-Plattform von Mistral bereitgestellt. Es ermöglicht Ihnen, ein Schema zu erstellen und Dokumente mit JSON zu unstrukturieren. Auf diese Weise erhalten Sie zuverlässige Extraktionspipelines, die nicht durch eine Änderung des Rechnungslayouts durch einen Lieferanten unterbrochen werden können. Eine praktischere Lösung besteht darin, OCR 3 zu verwenden, um Textual content und Anmerkungen zu den einzelnen Feldern einzugeben, die Sie benötigen, z. B. Rechnungsnummern oder Gesamtbeträge.
Skalierung mit Batch-Inferenz
Bei der Verarbeitung großer Mengen ist eine Chargenbildung erforderlich. Das Batch-System von Mistral ermöglicht es Ihnen, eine große Anzahl von API-Anfragen in einer Datei mit der Erweiterung.jsonl zu übermitteln. Sie können dann als ein Job ausgeführt werden. Die Dokumentation weist darauf hin /v1/ocr ist einer der unterstützten Batch-Job-Endpunkte.
So wählen Sie das richtige Modell aus
Die beste Wahl hängt von Ihren Dokumenten und Einschränkungen ab. Hier ist eine saubere Möglichkeit zur Bewertung.
Was zu messen ist
- Textgenauigkeit: Verwenden Sie auf Beispielseiten Zeichen- oder Wortfehlerraten.
- Strukturqualität: Rekonstruktion der Punktetabelle und Korrektheit der Lesereihenfolge.
- Extraktionszuverlässigkeit: Messen Sie die Feldgenauigkeit für Ihre Zieldatenpunkte.
- Betriebsleistung: Verfolgen Sie Latenz, Durchsatz und Fehlermodi.
Vergleichen wir
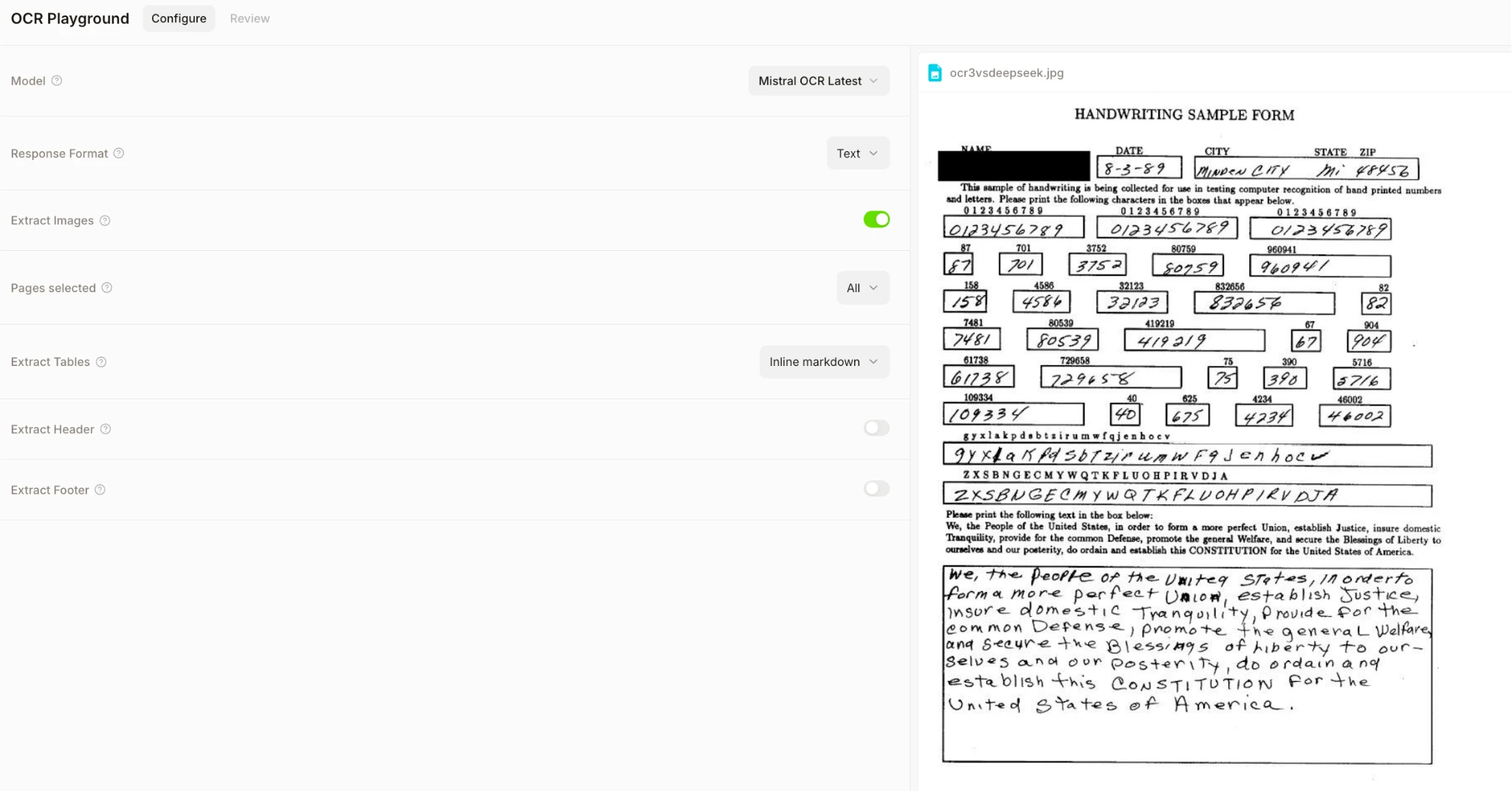
Verwenden Sie das folgende Bild als Referenz, um die beiden Modelle zu vergleichen. Wir haben dieses Bild so ausgewählt, wie es ist:
Ein hartes Stresstest-Formular mit umrahmten Feldern + gemischter Handschrift + gedrucktem Textual content (splendid für den Vergleich von OCR 3 mit DeepSeek-OCR).
Wir werden dies zum Vergleich verwenden:
- Handschriftgenauigkeit (Kursivschrift + Ziffern)
- Field-/Feldausrichtung (Zahlen in kleinen Quadraten)
- Robustheit gegenüber dichten Layouts und kleinem Textual content
Mistral OCR 3
Ausgabe:
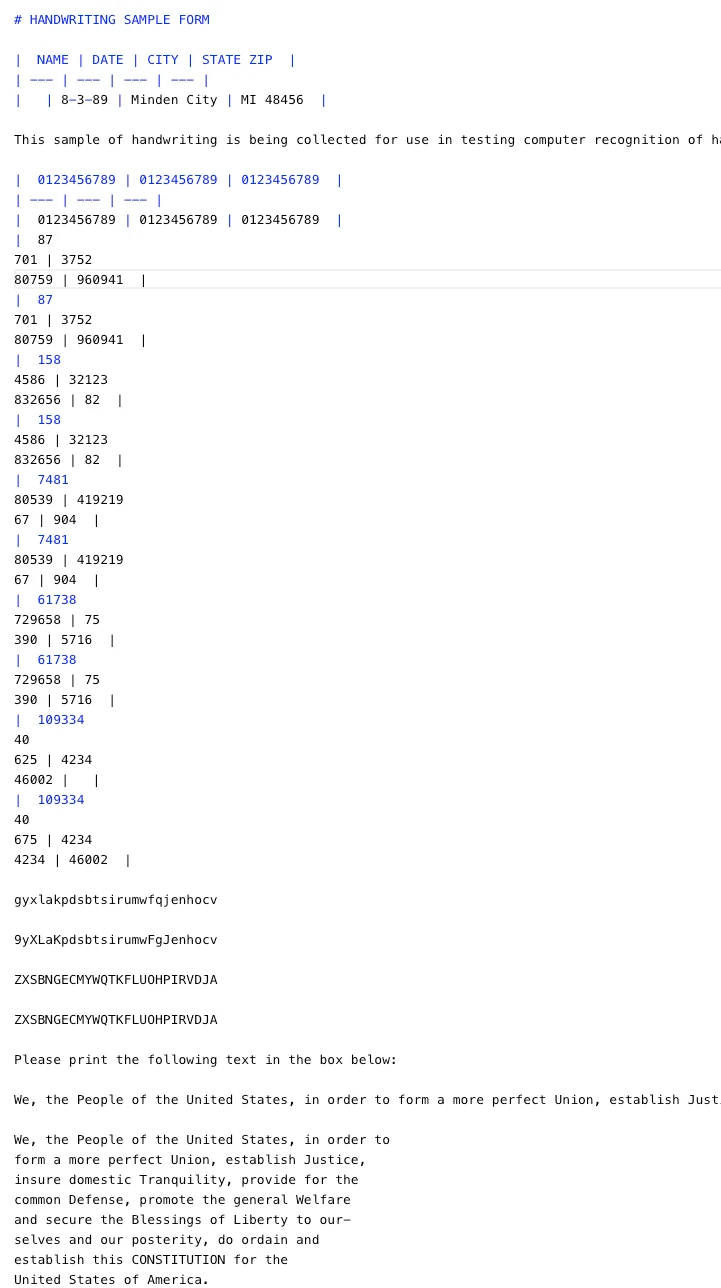
Dieses Ergebnis ist angesichts der Schwierigkeit der Eingabe beeindruckend.
- Mistral OCR 3 erkennt die Dokumentstruktur, Kopfzeilen und die meisten handschriftlichen Ziffern und Texte korrekt und wandelt eine dichte Handschriftform in einen verwendbaren Markdown um.
- In den Tabellen treten einige Duplikate und kleinere Ausrichtungsprobleme auf, was bei Rastern mit schwerer Handschrift zu erwarten ist.
- Insgesamt weist es eine starke Handschrifterkennung und Layouterkennung auf und eignet sich daher für die Digitalisierung von Formularen in der Praxis mit leichter Nachbearbeitung
Deepseek OCR
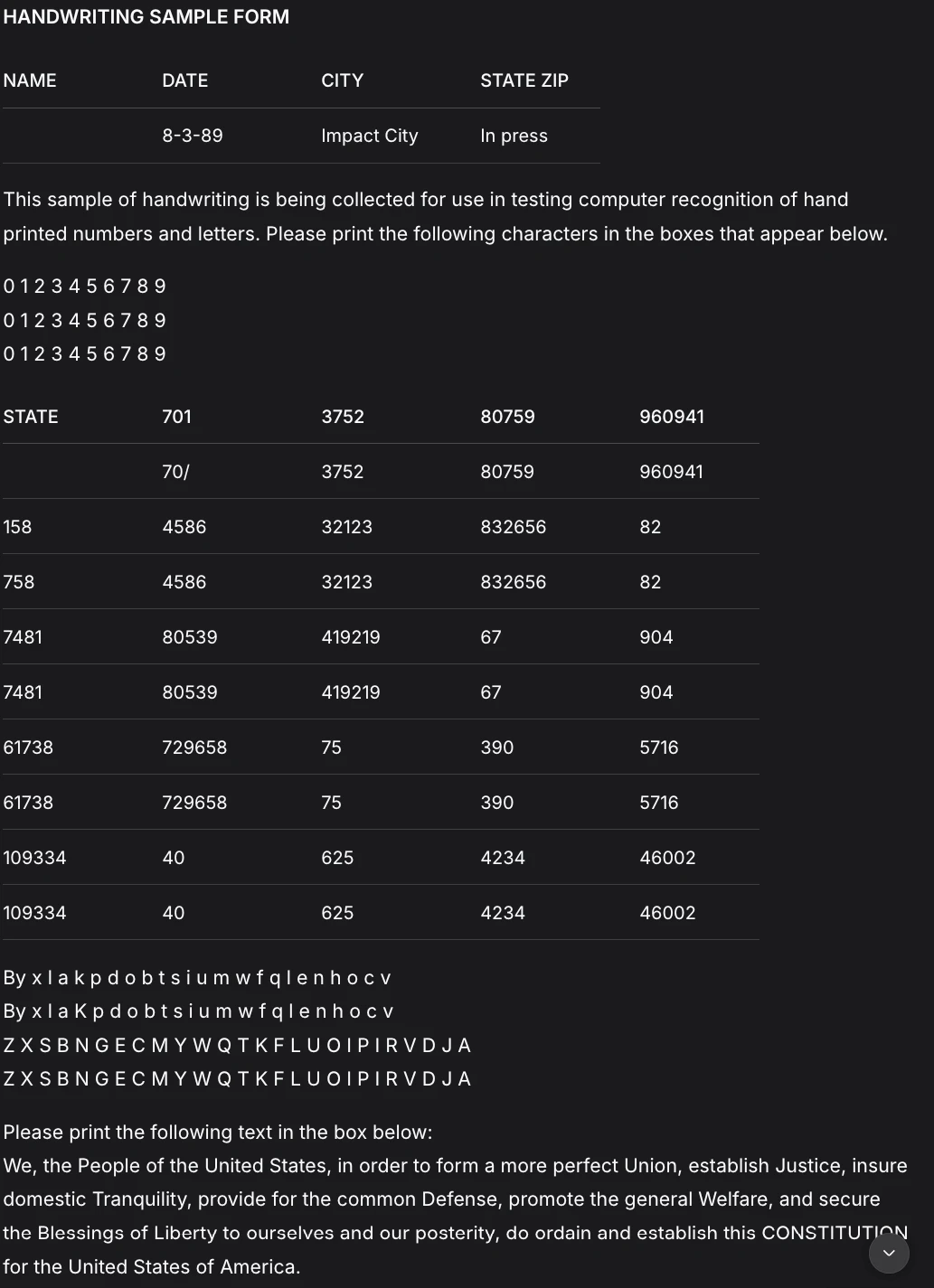
Das Ergebnis wurde verschönert, was es einfacher macht, es durchzugehen als die vorherige Antwort. Hier sind einige andere Dinge, die mir an Folgendem aufgefallen sind:
- DeepSeek OCR zeigt eine solide Handschrifterkennung, hat aber größere Probleme mit semantischer Genauigkeit und Layouttreue.
- Schlüsselfelder wie „Stadt“ und „Bundesland PLZ“ werden falsch interpretiert und die Tabellenstruktur ist aufgrund falscher Überschriften und doppelter Zeilen weniger originalgetreu.
- Die Erkennung auf Zeichenebene ist intestine, aber Abstände, Gruppierungen und Feldbedeutungen verschlechtern sich bei dichter Handschrift.
Ergebnis:
Mistral OCR 3 übertrifft DeepSeek OCR bei dieser handschriftlastigen Kind deutlich. Die Struktur des Dokuments, die Feldsemantik und die Tabellenausrichtung bleiben weitaus genauer erhalten, selbst bei dichten handschriftlichen Rastern. DeepSeek OCR liest Zeichen einigermaßen intestine, bricht jedoch bei Format, Kopfzeilen und Feldbedeutung, was zu einem höheren Bereinigungsaufwand führt. Wenn es um die Digitalisierung und Automatisierung von Formularen in der Praxis geht, ist Mistral OCR 3 der klare Gewinner.
Welches sollten Sie wählen?
Wählen Sie Mistral OCR 3, wenn Sie ein vollständiges OCR-Produkt benötigen, das eine Benutzeroberfläche und eine klare OCR-API umfasst. Es ist optimum, wenn die SaaS-Kosten und die Bewertung der Tabellenrekonstruktion zuverlässig und vorhersehbar sind.
Wählen Sie DeepSeek-OCR, wenn es vor Ort oder selbst gehostet gehostet werden soll. Es gibt den Groups, die bereit sind, die Abläufe zu kontrollieren, die Flexibilität und Kontrolle des Inferenzprozesses. Es ist möglich, dass viele Groups auf beides zurückgreifen: Mistral als primäre Pipeline und DeepSeek als Backup sensibler Dokumente.
Abschluss
Die Struktur und der Workflow werden aufgrund der Änderungen in Mistral OCR 3 zu einem wichtigen Downside. Die Tabellensteuerelemente, JSON-Extraktionsanmerkungen und ein Playground verfügen über Funktionen wie die Benutzeroberfläche und können die Entwicklungszeit verkürzen. Es handelt sich um eine der leistungsstarken Produktisierungen von Doc Intelligence. DeepSeek-OCR bietet eine andere Möglichkeit. Es betrachtet OCR als ein Komprimierungsproblem, das LLM betrifft, und bietet Benutzern Freiheit bei der Infrastruktur. Diese beiden Modelle demonstrieren die zukünftige Trennung der OCR-Technologie.
Häufig gestellte Fragen
A. Seine Hauptstärke liegt darin, dass es sich auf die Aufrechterhaltung der Dokumentstruktur, einschließlich komplizierter Tabellen und Lesesequenzen, sowie die Umwandlung gescannter Dokumente in nützliche Informationen konzentriert.
A. Es verfügt über die Möglichkeit, Tabellen im HTML-Format zu generieren, was den zusätzlichen Vorteil hat, dass komplexe Daten wie zusammengeführte Zellen und mehrzeilige Überschriften beibehalten werden, was eine größere Datenintegrität gewährleistet.
A. Ja, Doc AI Playground im AI Studio von Mistral bietet Ihnen die Möglichkeit, Dokumente hochzuladen und mit den OCR-Funktionen zu experimentieren.
Harsh Mishra ist ein KI/ML-Ingenieur, der mehr Zeit damit verbringt, mit großen Sprachmodellen zu sprechen als mit echten Menschen. Leidenschaftlich für GenAI, NLP und die intelligentere Entwicklung von Maschinen (damit sie ihn noch nicht ersetzen). Wenn er nicht gerade Modelle optimiert, optimiert er wahrscheinlich seinen Kaffeekonsum. 🚀☕
Melden Sie sich an, um weiterzulesen und von Experten kuratierte Inhalte zu genießen.