I TabPFN durch das ICLR 2023-Papier – TabPFN: Ein Transformator, der kleine tabellarische Klassifizierungsprobleme in einer Sekunde löst. Das Papier stellte TabPFN vor, ein Open-Supply Transformer-Modell, das speziell für tabellarische Datensätze entwickelt wurde, ein Bereich, der nicht wirklich von Deep Studying profitiert hat und in dem Entscheidungsbaummodelle mit Gradientenverstärkung immer noch dominieren.
Zu diesem Zeitpunkt unterstützte TabPFN nur bis zu 1.000 Trainingsbeispiele und 100 rein numerische Merkmale, sodass seine Verwendung in realen Umgebungen recht begrenzt warfare. Im Laufe der Zeit gab es jedoch mehrere inkrementelle Verbesserungen, darunter TabPFN-2, das 2025 durch das Papier eingeführt wurde –Genaue Vorhersagen für kleine Datenmengen mit einem tabellarischen Basismodell (TabPFN-2).

In jüngerer Zeit, TabPFN-2.5 wurde veröffentlicht und diese Model kann quick 100.000 Datenpunkte und rund 2.000 Funktionen verarbeiten, was sie für Vorhersageaufgaben in der realen Welt ziemlich praktisch macht. Ich habe einen Großteil meiner Berufsjahre damit verbracht, mit tabellarischen Datensätzen zu arbeiten, daher hat dies natürlich mein Interesse geweckt und mich dazu gebracht, tiefer zu schauen. In diesem Artikel gebe ich einen allgemeinen Überblick über TabPFN und gehe auch durch eine schnelle Implementierung mithilfe eines Kaggle-Wettbewerbs, um Ihnen den Einstieg zu erleichtern.
Was ist TabPFN?
TabPFN steht für Tabellarisches, mit Prior-Daten angepasstes Netzwerk, ein Stiftungsmodell, das basiert auf der Idee, ein Modell an a anzupassen Prior gegenüber tabellarischen Datensätzen, und nicht auf einen einzelnen Datensatz, daher der Title.
Als ich die technischen Berichte las, gab es viele interessante Particulars zu diesen Modellen. TabPFN kann beispielsweise starke tabellarische Vorhersagen mit sehr geringer Latenz liefern, oft vergleichbar mit abgestimmten Ensemble-Methoden, jedoch ohne wiederholte Trainingsschleifen.
Auch aus Workflow-Sicht gibt es keine Lernkurve, da es sich durch eine natürliche Integration in bestehende Setups einfügt scikit-learn Stilschnittstelle. Es kann fehlende Werte, Ausreißer und gemischte Characteristic-Typen mit minimaler Vorverarbeitung verarbeiten, worauf wir später in diesem Artikel bei der Implementierung eingehen werden.
Die Notwendigkeit eines Grundlagenmodells für tabellarische Daten
Bevor wir uns mit der Funktionsweise von TabPFN befassen, versuchen wir zunächst, das umfassendere Drawback zu verstehen, das damit angegangen werden soll.
Beim herkömmlichen maschinellen Lernen für tabellarische Datensätze trainieren Sie normalerweise ein neues Modell für jeden neuen Datensatz. Dies ist oft mit langen Trainingszyklen verbunden und bedeutet auch, dass ein zuvor trainiertes Modell nicht wirklich wiederverwendet werden kann.
Wenn wir uns jedoch die Grundmodelle für Textual content und Bilder ansehen, ist ihre Idee völlig anders. Anstatt von Grund auf neu zu trainieren, wird im Vorfeld ein großer Teil des Vortrainings für viele Datensätze durchgeführt und das resultierende Modell kann dann in den meisten Fällen ohne erneutes Coaching auf neue Datensätze angewendet werden.
Dies ist meiner Meinung nach die Lücke, die das Modell für tabellarische Daten zu schließen versucht, indem es die Notwendigkeit verringert, für jeden Datensatz ein neues Modell von Grund auf zu trainieren, und dies scheint ein vielversprechendes Forschungsgebiet zu sein.
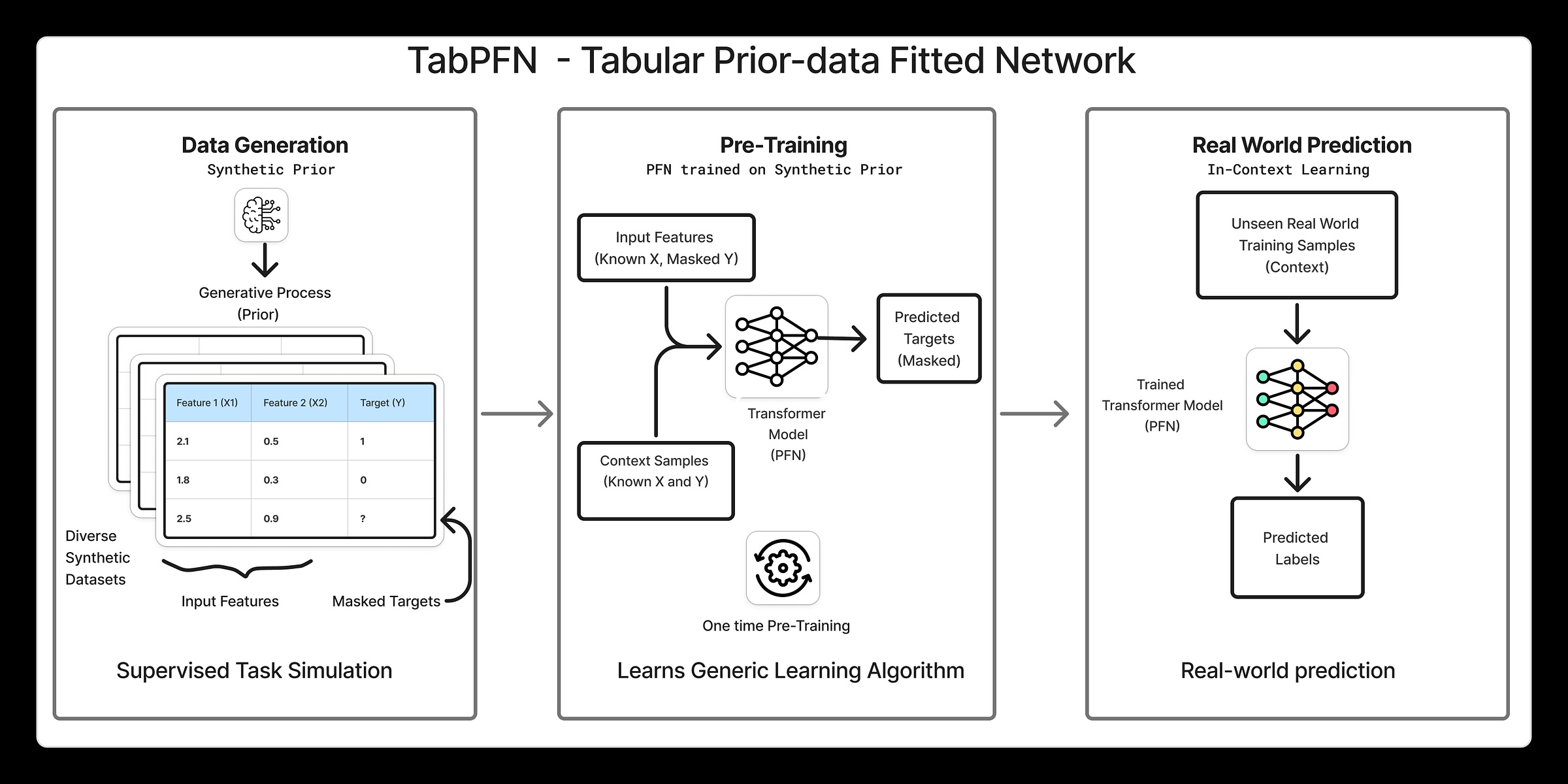
TabPFN-Schulungs- und Inferenz-Pipeline auf hohem Niveau

TabPFN nutzt Lernen im Kontext um ein neuronales Netzwerk an einen Prior über tabellarische Datensätze anzupassen. Dies bedeutet, dass das Modell nicht nur eine Aufgabe nach der anderen lernt, sondern lernt, wie tabellarische Probleme im Allgemeinen aussehen, und dieses Wissen dann nutzt, um in einem einzigen Vorwärtsdurchlauf Vorhersagen für neue Datensätze zu treffen. Hier ist ein Auszug aus TabPFN’s Natur Papier:
TabPFN nutzt In-Context-Studying (ICL), denselben Mechanismus, der zur erstaunlichen Leistung großer Sprachmodelle geführt hat, um einen leistungsstarken tabellarischen Vorhersagealgorithmus zu generieren, der vollständig erlernt ist. Obwohl ICL erstmals in großen Sprachmodellen beobachtet wurde, haben neuere Arbeiten gezeigt, dass Transformatoren einfache Algorithmen wie die logistische Regression durch ICL erlernen können.
Die Pipeline kann in drei Hauptschritte unterteilt werden:
1. Generieren synthetischer Datensätze
TabPFN behandelt einen gesamten Datensatz als einen einzelnen Datenpunkt (oder ein Token), der in das Netzwerk eingespeist wird. Dies bedeutet, dass während des Trainings eine sehr große Anzahl von Datensätzen verwendet werden muss. Aus diesem Grund beginnt das Coaching von TabPFN mit synthetische tabellarische Datensätze. Warum synthetisch? Im Gegensatz zu Textual content oder Bildern stehen nicht viele große und vielfältige tabellarische Datensätze aus der realen Welt zur Verfügung, weshalb synthetische Daten ein wichtiger Bestandteil des Setups sind. Um es ins rechte Licht zu rücken: TabPFN 2 wurde anhand von 130 Millionen Datensätzen trainiert.
Der Prozess der Generierung synthetischer Datensätze ist an sich schon interessant. TabPFN verwendet eine hochparametrische Methode strukturelles Kausalmodell um tabellarische Datensätze mit unterschiedlichen Strukturen, Merkmalsbeziehungen, Rauschpegeln und Zielfunktionen zu erstellen. Durch Stichproben aus diesem Modell kann ein großer und vielfältiger Satz von Datensätzen generiert werden, die jeweils als Trainingssignal für das Netzwerk dienen. Dies ermutigt das Modell, allgemeine Muster über viele Arten von Tabellenproblemen hinweg zu lernen, anstatt eine Überanpassung an einen einzelnen Datensatz vorzunehmen.
2. Ausbildung
Die folgende Abbildung stammt aus dem NaturpapierDas oben erwähnte Beispiel zeigt deutlich den Trainings- und Inferenzprozess.

Während des Trainings wird ein synthetischer Tabellendatensatz abgetastet und in X-Zug aufgeteilt.Y-Zug, X-CheckUnd Y-Check. Der Y-Check Die Werte werden zurückgehalten und die restlichen Teile werden an das neuronale Netzwerk übergeben, das für jeden eine Wahrscheinlichkeitsverteilung ausgibt Y-Check Datenpunkt, wie in der linken Abbildung dargestellt.
Das hat durchgehalten Y-Check Die Werte werden dann unter diesen vorhergesagten Verteilungen ausgewertet. A Kreuzentropie Anschließend wird der Verlust berechnet und das Netzwerk aktualisiert Minimieren Sie diesen Verlust. Damit ist ein Backpropagation-Schritt für einen einzelnen Datensatz abgeschlossen und dieser Vorgang wird dann für Millionen synthetischer Datensätze wiederholt.
3. Schlussfolgerung
Zum Testzeitpunkt wird das trainierte TabPFN-Modell auf einen realen Datensatz angewendet. Dies entspricht der Abbildung rechts, in der das Modell zur Schlussfolgerung verwendet wird. Wie Sie sehen, bleibt die Benutzeroberfläche dieselbe wie beim Coaching. Sie sorgen dafür X-Zug, Y-ZugUnd X-Checkund das Modell gibt Vorhersagen für aus Y-Check durch einen einzigen Vorwärtspass.
Am wichtigsten ist, dass zum Testzeitpunkt keine erneute Schulung erfolgt und TabPFN die effektivste Leistung erbringt Zero-Shot-Inferenzwodurch sofort Vorhersagen erstellt werden, ohne dass die Gewichte aktualisiert werden müssen.
Architektur

Lassen Sie uns auch auf die Kernarchitektur des Modells eingehen, wie im erwähnt Papier. Auf hoher Ebene passt TabPFN die Transformatorarchitektur an, um sie besser an Tabellendaten anzupassen. Anstatt eine Tabelle in eine lange Sequenz zu reduzieren, behandelt das Modell jeden Wert in der Tabelle als eigene Einheit. Es verwendet einen zweistufigen Aufmerksamkeitsmechanismus, bei dem es zunächst lernt, wie Options innerhalb einer einzelnen Zeile miteinander in Beziehung stehen, und dann lernt, wie sich dasselbe Characteristic über verschiedene Zeilen hinweg verhält.
Diese Artwork der Aufmerksamkeitsstrukturierung ist von entscheidender Bedeutung, da sie der tatsächlichen Organisation tabellarischer Daten entspricht. Dies bedeutet auch, dass sich das Modell nicht um die Reihenfolge der Zeilen oder Spalten kümmert, was bedeutet, dass es Tabellen verarbeiten kann, die größer sind als diejenigen, auf denen es trainiert wurde.
Durchführung
Lassen Sie uns nun eine Implementierung von durchgehen TabPFN-2.5 und vergleiche es mit einer Vanille XGBoost Klassifikator, um einen vertrauten Bezugspunkt bereitzustellen. Die Modellgewichte können unter heruntergeladen werden Umarmendes Gesichtverwenden Kaggle-Notizbücher ist einfacher, da die Modell ist dort leicht verfügbar und die GPU-Unterstützung ist für schnellere Schlussfolgerungen sofort einsatzbereit. In jedem Fall müssen Sie die Modellbedingungen akzeptieren, bevor Sie es verwenden können. Nach dem Hinzufügen des TabPFN Modell Um es in die Kaggle-Pocket book-Umgebung zu importieren, führen Sie die folgende Zelle aus, um es zu importieren.
# importing the mannequin
import os
os.environ("TABPFN_MODEL_CACHE_DIR") = "/kaggle/enter/tabpfn-2-5/pytorch/default/2"Den vollständigen Code finden Sie im beiliegenden Kaggle-Notizbuch Hier.
Set up
Sie können auf TabPFN auf zwei Arten zugreifen, entweder als Python-Paket und führen Sie es lokal oder als aus API-Shopper So führen Sie das Modell in der Cloud aus:
# Python package deal
pip set up tabpfn
# As an API shopper
pip set up tabpfn-clientDatensatz: Kaggle Playground-Wettbewerbsdatensatz
Um ein besseres Gefühl dafür zu bekommen, wie TabPFN in einer realen Umgebung funktioniert, habe ich es bei einem Kaggle Playground-Wettbewerb getestet, der vor einigen Monaten zu Ende ging. Die Aufgabe, Binäre Vorhersage mit einem Niederschlagsdatensatz (MIT-Lizenz) erfordert die Vorhersage der Niederschlagswahrscheinlichkeit für jeden id im Testsatz. Die Auswertung erfolgt mit ROC–AUCwodurch dies intestine für wahrscheinlichkeitsbasierte Modelle wie TabPFN geeignet ist. Die Trainingsdaten sehen so aus:
Trainieren eines TabPFN-Klassifizierers
Das Coaching des TabPFN-Klassifikators ist unkompliziert und folgt einem vertrauten Prinzip scikit-lernen Stilschnittstelle. Zwar gibt es keine aufgabenspezifische Schulung im herkömmlichen Sinne, dennoch ist es wichtig, sie zu ermöglichen GPU-Unterstützungandernfalls kann die Schlussfolgerung deutlich langsamer sein. Der folgende Codeausschnitt führt durch die Vorbereitung der Daten, das Coaching eines TabPFN-Klassifikators und die Bewertung seiner Leistung mithilfe des ROC-AUC-Scores.
# Importing needed libraries
from tabpfn import TabPFNClassifier
import pandas as pd, numpy as np
from sklearn.model_selection import train_test_split
# Choose characteristic columns
FEATURES = (c for c in prepare.columns if c not in ("rainfall",'id'))
X = prepare(FEATURES).copy()
y = prepare("rainfall").copy()
# Cut up knowledge into prepare and validation units
train_index, valid_index = train_test_split(
prepare.index,
test_size=0.2,
random_state=42
)
x_train = X.loc(train_index).copy()
y_train = y.loc(train_index).copy()
x_valid = X.loc(valid_index).copy()
y_valid = y.loc(valid_index).copy()
# Initialize and prepare TabPFN
model_pfn = TabPFNClassifier(system=("cuda:0", "cuda:1"))
model_pfn.match(x_train, y_train)
# Predict class possibilities
probs_pfn = model_pfn.predict_proba(x_valid)
# # Use likelihood of the optimistic class
pos_probs = probs_pfn(:, 1)
# # Consider utilizing ROC AUC
print(f"ROC AUC: {roc_auc_score(y_valid, pos_probs):.4f}")
-------------------------------------------------
ROC AUC: 0.8722Als nächstes trainieren wir einen grundlegenden XGBoost-Klassifikator.
Trainieren eines XGBoost-Klassifikators
from xgboost import XGBClassifier
# Initialize XGBoost classifier
model_xgb = XGBClassifier(
goal="binary:logistic",
tree_method="hist",
system="cuda",
enable_categorical=True,
random_state=42,
n_jobs=1
)
# Prepare the mannequin
model_xgb.match(x_train, y_train)
# Predict class possibilities
probs_xgb = model_xgb.predict_proba(x_valid)
# Use likelihood of the optimistic class
pos_probs_xgb = probs_xgb(:, 1)
# Consider utilizing ROC AUC
print(f"ROC AUC: {roc_auc_score(y_valid, pos_probs_xgb):.4f}")
------------------------------------------------------------
ROC AUC: 0.8515Wie Sie sehen können, schneidet TabPFN im Auslieferungszustand recht intestine ab. Während XGBoost sicherlich noch weiter optimiert werden kann, möchte ich hier einen Vergleich anstellen grundlegende Vanilla-Implementierungen statt optimierter Modelle. Damit landete ich auf Platz 22 der öffentlichen Bestenliste. Unten sind die drei besten Ergebnisse als Referenz aufgeführt.

Wie sieht es mit der Erklärbarkeit von Modellen aus?
Transformatormodelle sind nicht von Natur aus interpretierbar. Um die Vorhersagen zu verstehen, werden daher häufig Submit-hoc-Interpretierbarkeitstechniken wie SHAP (SHapley Additive Explanations) verwendet, um einzelne Vorhersagen und Merkmalsbeiträge zu analysieren. TabPFN bietet eine dedizierte Erweiterung der Interpretierbarkeit Das lässt sich in SHAP integrieren und erleichtert so die Überprüfung und Begründung der Vorhersagen des Modells. Um darauf zuzugreifen, müssen Sie zuerst die Erweiterung installieren:
# Set up the interpretability extension:
pip set up "tabpfn-extensions(interpretability)"
from tabpfn_extensions import interpretability
# Calculate SHAP values
shap_values = interpretability.shap.get_shap_values(
estimator=model_pfn,
test_x=x_test(:50),
attribute_names=FEATURES,
algorithm="permutation",
)
# Create visualization
fig = interpretability.shap.plot_shap(shap_values)
Das Diagramm auf der linken Seite zeigt die durchschnittliche SHAP-Merkmalsbedeutung über den gesamten Datensatz hinweg und bietet einen globalen Überblick darüber, welche Merkmale für das Modell am wichtigsten sind. Die Handlung auf der rechten Seite ist a SHAP-Zusammenfassungsdiagramm (Bienenschwarm).das eine detailliertere Ansicht bietet, indem SHAP-Werte für jedes Characteristic über einzelne Vorhersagen hinweg angezeigt werden.
Aus den obigen Diagrammen geht hervor, dass Wolkendecke, Sonnenschein, LuftfeuchtigkeitUnd Taupunkt haben insgesamt den größten Einfluss auf die Vorhersagen des Modells, während Merkmale wie Windrichtung, Druck und temperaturbezogene Variablen eine vergleichsweise geringere Rolle spielen.
Es ist wichtig zu beachten, dass SHAP die erlernten Beziehungen des Modells erklärt, nicht die physikalische Kausalität.
Abschluss
TabPFN bietet viel mehr als das, was ich in diesem Artikel behandelt habe. Was mir persönlich gefallen hat, ist sowohl die Grundidee als auch der einfache Einstieg. Es gibt viele Aspekte, die ich hier nicht angesprochen habe, wie z. B. die Verwendung von TabPFN bei Zeitreihenprognosen, die Erkennung von Anomalien, die Generierung synthetischer Tabellendaten und das Extrahieren von Einbettungen aus TabPFN-Modellen.
Ein weiterer Bereich, der mich besonders interessiert, ist die Feinabstimmung, bei der diese Modelle an Daten aus einem bestimmten Bereich angepasst werden können. Dennoch sollte dieser Artikel eine kurze Einführung sein, die auf meinen ersten praktischen Erfahrungen basiert. Ich habe vor, diese zusätzlichen Funktionen in zukünftigen Beiträgen ausführlicher zu untersuchen. Vorerst der Beamte Dokumentation ist ein guter Ort, um tiefer einzutauchen.
Hinweis: Alle Bilder wurden, sofern nicht anders angegeben, vom Autor erstellt.