Da Deep-Studying-Modelle immer größer werden und die Datensätze immer größer werden, stehen Praktiker vor einem immer häufiger auftretenden Engpass: der GPU-Speicherbandbreite. Während modernste {Hardware} FP8-Präzision bietet, um Coaching und Inferenz zu beschleunigen, arbeiten die meisten Datenwissenschaftler und ML-Ingenieure mit älteren GPUs, denen diese Fähigkeit fehlt.
Diese Lücke im Ökosystem hat mich zum Aufbau motiviert Federeine Open-Supply-Bibliothek, die einen softwarebasierten Ansatz nutzt, um FP8-ähnliche Leistungsverbesserungen auf allgemein verfügbarer {Hardware} zu erzielen. Ich habe dieses Software entwickelt, um effizientes Deep Studying für die breitere ML-Neighborhood zugänglicher zu machen, und ich freue mich über Beiträge
Notation und Abkürzungen
- FPX: X-Bit-Gleitkommazahl
- UX: X-Bit-Ganzzahl ohne Vorzeichen
- GPU: Grafikprozessoreinheit
- SRAM: Statischer RAM (On-Chip-GPU-Cache)
- HBM: Speicher mit hoher Bandbreite (GPU VRAM)
- GEMV: Allgemeine Matrix-Vektor-Multiplikation
Motivation
Die FP8-Verarbeitung hat sich in der Deep-Studying-Neighborhood als effektiv erwiesen (1); Es wird jedoch nur von bestimmten neueren {Hardware}-Architekturen (Ada und Blackwell) unterstützt, was den Nutzen für Praktiker und Forscher bei der Nutzung einschränkt. Ich selbst habe ein `Nvidia RTX 3050 6 GB Laptop computer-GPU`, was leider keine FP8-Operationen auf Hardwareebene unterstützt.
Inspiriert von softwarebasierten Lösungen wie (softwarebeschleunigtes Rendering auf Computern, die keine native Hardwarebeschleunigung für Spiele unterstützen) schlägt der Artikel eine interessante Lösung vor, die die Leistungsfähigkeit von FP8-Datentypen nutzen kann
Verpacken von FP8 und FP16 in FP32-Behälter
Inspiriert von bitweisen Operationen und Packtechniken stellt der Artikel einen Algorithmus vor, der zwei FP16s oder vier FP8s in einen einzigen FP32 packt. Dadurch kann der Speicher verdoppelt oder vervierfacht werden, was von einem geringeren Speicherbedarf bei nur geringen Einbußen bei der Präzision profitiert.
Man könnte argumentieren, dass wir redundante Berechnungen durchführen: „Packen -> Laden -> Entpacken -> Berechnen.“ Erwägen Sie jedoch Deep-Studying-Operationen; In den meisten Fällen sind diese Vorgänge speichergebunden und nicht rechengebunden. Dies ist derselbe Engpass, den Algorithmen wie FlashAttention beheben. FlashAttention nutzt jedoch Kacheln, um Daten im schnellen SRAM zu halten, während Feather Daten komprimiert, um den Speicherverkehr zu reduzieren.
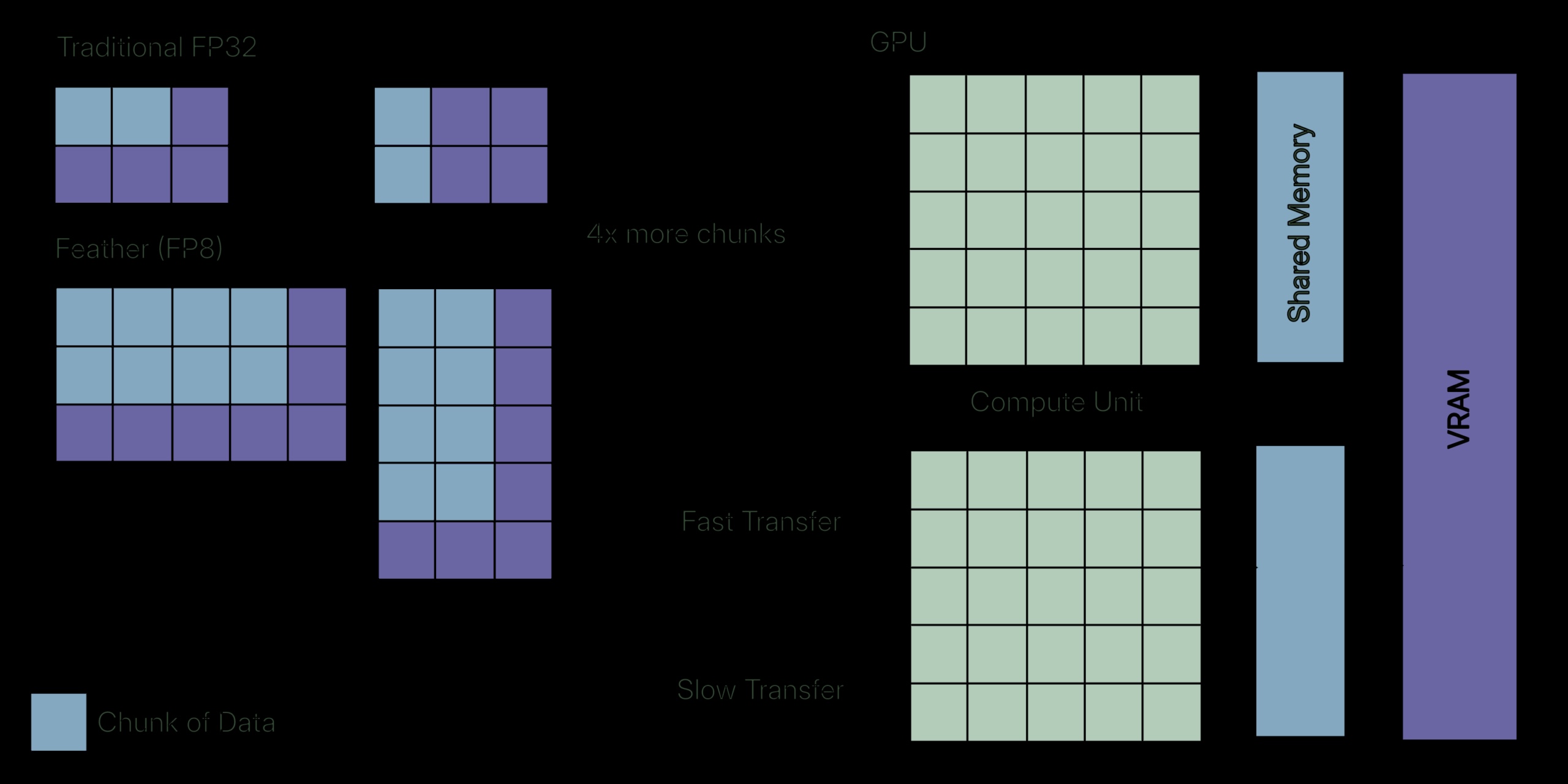
GPU-Speicherhierarchie

Schauen Sie sich dieses Diagramm an. SRAM ist der am schnellsten zugängliche GPU-Speicherbereich und verfügt über die höchste Bandbreite (ohne das Register selbst), ist jedoch auf nur 20 MB begrenzt. HBM kann als der VRAM der GPU selbst angesehen werden, der ungefähr hat 1/7 die Bandbreite von SRAM.
Die GPU-Kerne sind schnell genug, um die Berechnung sofort abzuschließen, aber sie verbringen die meiste Zeit im Leerlauf und warten darauf, dass das Laden und Zurückschreiben der Daten abgeschlossen ist. Das meine ich mit speichergebunden: Der Engpass liegt hier nicht in der Mathematik, sondern in der Datenübertragung zwischen der Speicherhierarchie in der GPU.
Typen mit geringerer Präzision und Bandbreite
Meistens sind die Werte während der Berechnung aufgrund der Normalisierung auf Bereiche um Null beschränkt. Ingenieure entwickelten Typen mit geringerer Präzision wie FP8 und FP16, die eine höhere Bandbreite ermöglichen. Man könnte verwirrt sein, wie eine Verringerung der Präzision eine höhere Bandbreite ermöglicht. Wenn wir genauer hinschauen, laden wir effektiv zwei Werte anstelle von einem für den FP16-Typ und vier Werte anstelle von einem für den FP8-Typ. Wir tauschen Präzision gegen höhere Bandbreite ein, um speichergebundene Vorgänge zu bewältigen.
Unterstützung auf Hardwareebene
Genau wie AVX-512-Befehle, die nur auf einer begrenzten Anzahl von Hardwareplattformen unterstützt werden, sind auch FP8- und FP16-Befehle und -Register durch die {Hardware} begrenzt und nur auf den neueren verfügbar. Wenn Sie eine GPU der RTX-30- oder RTX-20-Serie von Nvidia verwenden, können Sie diesen FP8-Typ mit geringerer Präzision nicht nutzen. Das ist genau das Downside Feder Versuche zu lösen.
Verpackungsmethode
Mit bitweisen Operatoren kann man den FP16-Typ leicht in einen FP32 packen. Der Algorithmus wird unten beschrieben.
Verpackung FP16
- Wandeln Sie den Eingabe-FP32 in einen FP16 um; Dieser Schritt kann mit Numpys problemlos durchgeführt werden astyp Funktion.
- Werfen Sie sie in die U16 und dann in die U32; Dadurch werden die oberen 16 Bits auf Nullen und die unteren 16 Bits auf den tatsächlichen FP16 gesetzt.
- Verschieben Sie einen von ihnen bitweise um 16 LSHIFT Operator und kombinieren Sie beide bitweise ODER Operator.
FP16 auspacken
- Extrahieren Sie die unteren 16 Bits bitweise UND Operator und Maske 0xFFFF.
- Extrahieren Sie die oberen 16 Bits mit RSHIFT Operation um 16 und dann bitweise ausführen UND Operation mit der Maske 0xFFFF.
- Übertragen Sie beide U16-Werte auf FP16 und bei Bedarf auf FP32.
Verpackung FP8
FP8 hat zwei weit verbreitete Formate – E5M2 und E4M3. Man kann nicht denselben Algorithmus verwenden, der zum Packen von zwei FP16 in FP32 verwendet wird, da die CPU FP8-Typen nicht nativ unterstützt, dies jedoch für FP16 (halbe Genauigkeit) tut. Das ist der Grund dafür np.float8 existiert nicht.

Die Umwandlung eines FP16 in FP8-E5M2 ist, wie in der Abbildung zu sehen ist, unkompliziert, da beide die gleiche Anzahl an Exponentenbits haben und sich nur in ihrem Bruch unterscheiden.
FP8-E5M2 Verpackung
- Wandeln Sie den Eingabe-FP32 in einen FP16 um; Dieser Schritt kann mit Numpys problemlos durchgeführt werden astyp Funktion, oder erhalten Sie die Eingabe selbst als FP16.
- Besetzung für U16, LSHIFT additionally um 8 RSHIFT um 8, um die oberen 8 Bits zu isolieren
- Tun Sie dies für alle vier FP32 oder FP16.
- Jetzt mit dem LSHIFT Operator, verschieben Sie sie um 0, 8, 16 und 24 Einheiten und kombinieren Sie sie bitweise ODER Operator.
Auch hier sollte das Auspacken unkompliziert sein; es ist das genaue Gegenteil von Packen.
Das Packen eines FP8-E4M3 ist aufgrund der Nichtübereinstimmung der Exponentenbits nicht so einfach und unkompliziert wie das Packen eines FP16 oder FP8-E5M2.

Anstatt es von Grund auf zu implementieren, verwendet die Bibliothek die ml_dtypes Bibliothek, die bereits die Casting-Mathematik durchführt.
Der ml_dtypes Die Bibliothek bietet Unterstützung für häufig verwendete FP8-Requirements wie E5M2- und E4M3-Casting für NumPy-Arrays. Mit der gleichen astype-Funktion können wir das Casting genauso durchführen, wie wir es für FP16-Typen getan haben. Der Algorithmus ist genau identisch mit der Artwork und Weise, wie wir FP16 packen, daher überspringe ich ihn hier.
Triton GPU-Kernel
Nach dem Packen benötigen wir einen Algorithmus (Kernel), um diesen gepackten Datentyp zu nutzen und die Berechnung durchzuführen. Die Übergabe des gepackten Datentyps an einen für FP32 oder FP64 implementierten Kernel führt zu einer undefinierten Berechnung, da wir den übergebenen FP32 oder FP64 bereits beschädigt haben. Das Schreiben eines Kernels, der den gepackten Datentyp als Eingabe in CUDA verwendet, ist keine einfache Aufgabe und fehleranfällig. Genau hier ist es Triton glänzt; Es handelt sich um eine domänenspezifische Sprachbibliothek, die eine benutzerdefinierte Zwischendarstellung für GPU-Kernel nutzt. Laienhaft ausgedrückt ermöglicht es einem, GPU-Kernel in Python selbst zu schreiben, ohne CUDA-Kernel in C schreiben zu müssen.
Triton-Kernel machen genau das, was zuvor erwähnt wurde; Der Algorithmus ist wie folgt:
- Laden Sie das gepackte Array in den Speicher
- Entpacken Sie den Speicher und übertragen Sie ihn für Akkumulationsaufgaben auf FP32
- Führen Sie die Berechnung durch
Der Leser sollte beachten, dass bei der Berechnung Upcasting verwendet wird, um Überläufe zu verhindern. Aus rechnerischer Sicht ergibt sich daher kein Vorteil. Aus Sicht der Bandbreite laden wir den Speicher jedoch zwei- oder viermal, ohne die Bandbreite zu beeinträchtigen.
Triton-Kernel-Implementierung (Pseudocode)
@triton.jit
def gemv_fp8_kernel(packed_matrix_ptr, packed_vector_ptr, out_ptr):
# Get present row to course of
row_id = get_program_id()
# Initialize accumulator for dot product
accumulator = 0
# Iterate over row in blocks
for every block in row:
# Load packed FP32 values (every comprises 4 FP8s)
packed_matrix = load(packed_matrix_ptr)
packed_vector = load(packed_vector_ptr)
# Unpack the FP32 into 4 FP8 values
m_a, m_b, m_c, m_d = unpack_fp8(packed_matrix)
v_a, v_b, v_c, v_d = unpack_fp8(packed_vector)
# Upcast to FP32 and compute partial dot merchandise
accumulator += (m_a * v_a) + (m_b * v_b) + (m_c * v_c) + (m_d * v_d)
# Retailer last outcome
retailer(out_ptr, accumulator)Ergebnisse
{Hardware}: NVIDIA GeForce RTX 3050 6 GB VRAM
CUDA-Model: 13.0
Python-Model: 3.13.9
GEMV-Benchmark (M = 16384, N = 16384) (MxN-Matrix)
| Durchführung | Zeit (Mikrosekunden) | Beschleunigung |
| Pytorch (FP32) | 5.635 | (Grundlinie) |
| Feder (FP8-E4M3) | 2.703 | 2,13x |
| Feder (FP8-E5M2) | 1.679 | 3,3x |
Die theoretisch erreichbare Leistungssteigerung liegt bei 4x; 3.3x ist im Vergleich sehr intestine, wobei der verbleibende Overhead hauptsächlich auf Pack-/Entpackvorgänge und Kernel-Startkosten zurückzuführen ist.
E5M2 ist aufgrund des einfacheren Auspackens schneller als E4M3, E4M3 bietet jedoch eine bessere Präzision. Allerdings ist das Entpacken deutlich komplexer (Feather nutzt einen separaten GPU-Kernel zum Entpacken des E4M3-Codecs).
Flash-Aufmerksamkeits-Benchmark (Sequenzlänge = 8192, Einbettungsdimension = 512)
| Durchführung | Zeit (Mikrosekunden) | Beschleunigung |
| Pytorch (FP32) | 33.290 | (Grundlinie) |
| Feder (FP8-E5M2) | 9.887 | ~3,3x |
Genauigkeit und Präzision
Exams mit Zufallsmatrizen (Ganzzahlverteilungen im Bereich (-3, 3) und Standardnormalverteilungen) zeigen, dass sowohl E4M3 als auch E5M2 numerische Ergebnisse innerhalb praktischer Toleranzen für Deep-Studying-Operationen halten. Die Akkumulationsfehler bleiben für typische Workload-Größen beherrschbar; Benutzer, die eine strenge numerische Präzision benötigen, sollten jedoch ihren spezifischen Anwendungsfall validieren.
Wann sollten Sie Feather verwenden?
Die Anwendungsfälle für Feather sind nicht begrenzt. Man kann Feather überall dort einsetzen, wo das Ein- und Auspacken von FP8 von Vorteil ist, wie z
- Große Matrix-Vektor-Produkte, bei denen das Be- und Entladen die Engpässe darstellt.
- Aufmerksamkeitsähnliche speichergebundene Kernel.
- Rückschluss oder Feinabstimmung auf native RTX 30- oder 20-Serien.
- Stapelverarbeitung, bei der sich der Verpackungsaufwand amortisiert
Wann sollten Sie Feather nicht verwenden?
- Sie verfügen über GPUs der RTX 40-Serie oder H100 (natives FP8 ist schneller).
- Arbeitslasten sind rechengebunden und nicht bandbreiten- oder speichergebunden.
- Sie brauchen garantierte Präzision.
Einschränkungen der Feder
Feather befindet sich derzeit im Anfangsstadium der Prototypenentwicklung und weist mehrere Bereiche mit Verbesserungsbedarf auf.
- Begrenzte Unterstützung für den Betrieb; momentan, Feder unterstützt nur das Skalarprodukt, die GEMV-Unterroutine und FlashAttention.
- Genauigkeitsvalidierung für komplette ML-Workloads; momentan, Federn Die Genauigkeit wird nur für Vorgänge validiert, nicht für Finish-to-Finish-ML-Workloads.
- Die Integration ist derzeit begrenzt; Feder ist eine eigenständige Implementierung. Durch die Integration mit PyTorch und die Unterstützung von Autograd wäre es besser für die Produktion geeignet.
Das Projekt ist Open Supply; Neighborhood-Beiträge sind willkommen! Sie können den Code ausprobieren, indem Sie einfach den Anweisungen auf folgen GitHub.
Bildlizenz: Alle Bilder wurden vom Autor erstellt. Adaptionsquellen werden in den jeweiligen Bildunterschriften deutlich erwähnt.