
In maschinelles Lernen Und Datenwissenschaftist die Bewertung eines Modells genauso wichtig wie der Aufbau. Genauigkeit ist oft die erste Metrik, die Menschen verwenden, sie kann jedoch irreführend sein, wenn die Daten unausgewogen sind. Aus diesem Grund werden häufig Metriken wie Präzision, Rückruf und F1-Rating verwendet. Dieser Artikel konzentriert sich auf den F1-Rating. Es erklärt, was der F1-Rating ist, warum er wichtig ist, wie er berechnet wird und wann er verwendet werden sollte. Der Artikel enthält auch ein praktisches Python-Beispiel mit scikit-learn und bespricht häufige Fehler, die bei der Modellbewertung vermieden werden sollten.
Was ist der F1-Rating beim maschinellen Lernen?
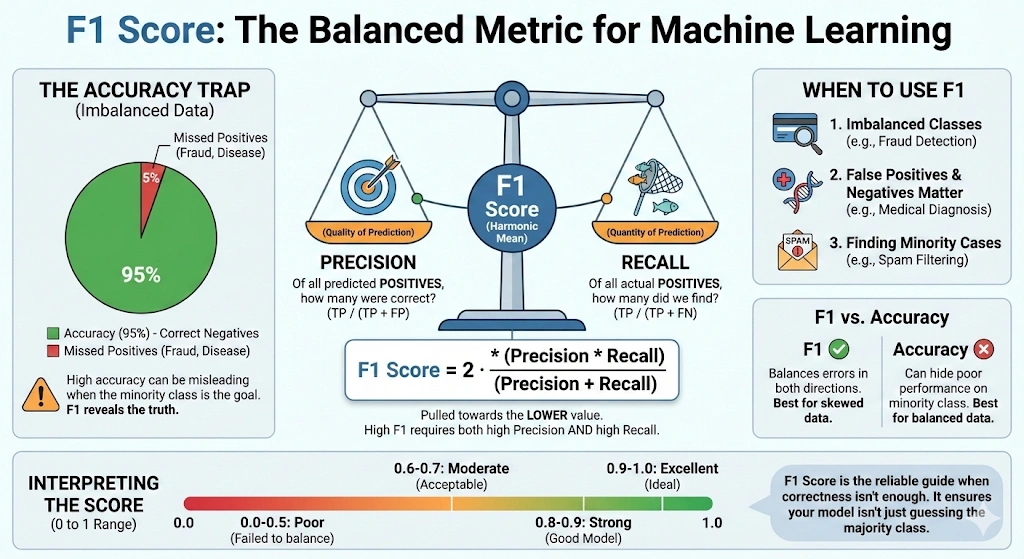
Der F1-Rating, auch Balanced F-Rating oder F-Measure genannt, ist eine Metrik zur Bewertung eines Modells durch die Kombination von Präzision und Recall in einem einzigen Wert. Es wird häufig bei Klassifizierungsproblemen verwendet, insbesondere wenn die Daten unausgeglichen sind oder wenn falsch-positive und falsch-negative Ergebnisse eine Rolle spielen.
Präzision misst, wie viele vorhergesagte constructive Fälle tatsächlich positiv sind. In einfachen Worten beantwortet es die Frage: Wie viele von allen vorhergesagten positiven Fällen sind richtig? Der Recall, auch Sensitivität genannt, misst, wie viele tatsächliche constructive Fälle das Modell korrekt identifiziert. Es beantwortet die Frage: Wie viele von allen wirklich positiven Fällen hat das Modell erkannt?
Präzision und Erinnerung oft einen Kompromiss eingehen. Die Verbesserung des einen kann das andere reduzieren. Der F1-Rating behebt dieses Drawback, indem er den harmonischen Mittelwert verwendet, der niedrigeren Werten mehr Gewicht verleiht. Daher ist der F1-Rating nur dann hoch, wenn sowohl Präzision als auch Rückruf hoch sind.
F1 = 2 ×
Präzision × Rückruf
Präzision + Rückruf
Der F1-Rating reicht von 0 bis 1 bzw. von 0 bis 100 %. Eine Punktzahl von 1 bedeutet perfekte Präzision und Erinnerung. Ein Wert von 0 bedeutet, dass entweder die Präzision oder der Rückruf null ist oder beides. Dies macht den F1-Rating zu einer zuverlässigen Metrik zur Bewertung von Klassifizierungsmodellen.
Lesen Sie auch: 8 Möglichkeiten zur Verbesserung der Genauigkeit von Modellen für maschinelles Lernen
Wann sollten Sie den F1-Rating verwenden?
Wenn die Präzision allein kein klares Bild der Leistung des Modells liefern kann, wird der F1-Rating verwendet. Dies geschieht meist bei einseitigen Daten. Ein Modell kann in solchen Situationen nur dann sehr genau sein, wenn es Vorhersagen für den Großteil der Klasse trifft. Dennoch kann es völlig versagen, Minderheitengruppen zu identifizieren. Der F1-Rating ist bei der Lösung dieses Issues nützlich, da er auf Präzision und Erinnerung achtet.
Der F1-Rating ist nützlich, wenn sowohl falsch-positive als auch falsch-negative Ergebnisse wichtig sind. Es stellt einen Wert bereit, anhand dessen ein Modell diese beiden Fehlerkategorien ausgleicht. Um einen hohen F1-Rating für ein Modell zu erzielen, muss es hinsichtlich Präzision und Erinnerung intestine abschneiden. Dies macht es bei den meisten Aufgaben in der realen Welt zuverlässiger als Präzision.
Praxisnahe Anwendungsfälle des F1-Scores
Der F1-Rating wird normalerweise in den folgenden Situationen verwendet:
- Unausgewogene Klassifizierungsprobleme wie Spam-Filterung, Betrugserkennung und medizinische Diagnose.
- Die Informationsabruf- und Suchsysteme, in denen die nützlichen Ergebnisse mit einer minimalen Anzahl falscher Zufälle gefunden werden sollen.
- Modell- oder Schwellenwertabstimmung, wenn sowohl Präzision als auch Rückruf wichtig sind.
Wenn eine Fehlerart wesentlich teurer ist als die andere, sollte diese Fehlerart nicht unabhängig auf den F1-Rating angewendet werden. Der Rückruf könnte von größerer Bedeutung sein, wenn es noch schlimmer ist, einen positiven Fall zu verpassen. Wenn Fehlalarme schlimmer sind, kann die Genauigkeit der wichtigste Punkt sein. Wenn Genauigkeit und Erinnerungsfähigkeit gleichermaßen wichtig sind, ist der F1-Rating am besten geeignet.
So berechnen Sie den F1-Rating Schritt für Schritt
Der F1-Rating kann berechnet werden, sobald Präzision und Erinnerung bekannt sind. Diese Metriken werden aus der Verwirrungsmatrix in einem binären Klassifizierungsproblem abgeleitet.
Präzision misst, wie viele vorhergesagte constructive Fälle tatsächlich positiv sind. Es ist definiert als:
Präzision =
TP
TP + FP
Der Rückruf wird verwendet, um die Anzahl der tatsächlich abgerufenen positiven Ergebnisse zu bestimmen. Es ist definiert als:
Abrufen =
TP
TP + FN
Hier steht TP für richtig constructive Ergebnisse, FP für falsch constructive Ergebnisse und FN für falsch damaging Ergebnisse.
F1-Ergebnisformel mit Präzision und Rückruf
Nachdem Präzision (P) und Rückruf (R) bekannt sind, kann der F1-Rating als harmonisches Mittel der beiden bestimmt werden:
F1 =
2 × P × R
P + R
Das harmonische Mittel gibt kleineren Werten mehr Gewicht. Infolgedessen wird der F1-Rating in Richtung der niedrigeren Werte für Präzision oder Erinnerung verschoben. Wenn die Präzision beispielsweise 0,90 und die Erinnerung 0,10 beträgt, beträgt der F1-Rating etwa 0,18. Wenn sowohl Präzision als auch Rückruf 0,50 betragen, beträgt der F1-Rating ebenfalls 0,50.
Dadurch wird sichergestellt, dass ein hoher F1-Rating nur dann erreicht wird, wenn sowohl Präzision als auch Rückruf hoch sind.
F1-Rating-Formel unter Verwendung der Verwirrungsmatrix
Man kann dieselbe Formel auch mit Begriffen der Verwirrungsmatrix formulieren:
F1 =
2 TP
2 TP + FP + FN
Betrachten wir ein Beispiel: Wenn das Modell durch eine Präzision von 0,75 und einen Rückruf von 0,60 gekennzeichnet ist, beträgt der F1-Rating:
F1 =
2 × 0,75 × 0,60
0,75 + 0,60
=
0,90
/
1,35
≈
0,67
Bei Klassifizierungsproblemen mit mehreren Klassen wird der F1-Rating für jede Klasse separat berechnet und dann gemittelt. Bei der Makromittelung werden alle Klassen gleich behandelt, während bei der gewichteten Mittelung die Klassenhäufigkeit berücksichtigt wird. In stark unausgeglichenen Datensätzen ist gewichtetes F1 normalerweise die bessere Gesamtmetrik. Überprüfen Sie beim Vergleich der Modellleistung immer die Mittelungsmethode.
Berechnen des F1-Scores in Python mit scikit-learn
Ein Beispiel für eine binäre Klassifizierung ist wie folgt. Präzision, Rückruf und F1-Rating werden mit Hilfe von scikit-learn berechnet. Dies hilft dabei zu demonstrieren, wie praktisch diese Metriken sind.
Bringen Sie zunächst die notwendigen Funktionen ein.
from sklearn.metrics import precision_score, recall_score, f1_score, classification_report Definieren Sie nun die wahren Bezeichnungen und Modellvorhersagen für zehn Stichproben.
# True labels
y_true = (1, 1, 1, 1, 1, 0, 0, 0, 0, 0) # 1 = constructive, 0 = damaging
# Predicted labels
y_pred = (1, 0, 1, 1, 0, 0, 0, 1, 0, 0) Berechnen Sie als Nächstes Präzision, Rückruf und den F1-Rating für die constructive Klasse.
precision = precision_score(y_true, y_pred, pos_label=1)
recall = recall_score(y_true, y_pred, pos_label=1)
f1 = f1_score(y_true, y_pred, pos_label=1)
print("Precision:", precision)
print("Recall:", recall)
print("F1 rating:", f1) Sie können auch einen vollständigen Klassifizierungsbericht erstellen.
print ("nClassification Report:n", classification_report(y_true, y_pred)) Das Ausführen dieses Codes erzeugt eine Ausgabe wie die folgende:
Precision: 0.75 Recall: 0.6 F1 rating: 0.6666666666666666
Klassifizierungsbericht:
Classification Report:
precision recall f1-score assist
0 0.67 0.80 0.73 5
1 0.75 0.60 0.67 5
accuracy 0.70 10
macro avg 0.71 0.70 0.70 10
weighted avg 0.71 0.70 0.70 10
Grundlegendes zur Ausgabe von Klassifizierungsberichten in scikit-learn
Lassen Sie uns diese Ergebnisse interpretieren.
In der positiven Kategorie (Label 1) beträgt die Genauigkeit 0,75. Dies impliziert, dass drei Viertel der Proben, die als positiv angenommen wurden, positiv waren. Der Recall beträgt 0,60, was bedeutet, dass das Modell 60 % aller wirklich positiven Proben korrekt identifiziert hat. Addiert man diese beiden Werte, ergibt sich ein Wert von etwa F1 von 0,67.
Bei der negativen Kategorie (Label 0) ist der Recall mit 0,80 größer. Dies zeigt, dass das Modell Negativismus effektiver erkennen kann als Positivismus. Seine Genauigkeit beträgt insgesamt 70 %, was kein Maß für die Wirksamkeit des Modells in jeder einzelnen Klassifizierung ist.
Dies kann im Klassifizierungsbericht einfacher eingesehen werden. Es präsentiert Präzision, Rückruf und F1 nach Klasse, Makro und gewichteten Durchschnittswerten. In diesem ausgewogenen Fall sind die Makro- und gewichteten F1-Werte vergleichbar. Gewichtete F1-Ergebnisse in unausgeglicheneren Datensätzen legen mehr Wert auf die dominante Klasse.
Dies wird anhand eines praktischen Beispiels zur Berechnung und Interpretation des F1-Scores demonstriert. Der F1-Rating der Validierungs-/Testdaten in realen Projekten würde verwendet, um das Gleichgewicht zwischen falsch-positiven und falsch-negativen Ergebnissen zu bestimmen, wie es bei Ihrem Modell der Fall wäre.
Greatest Practices und häufige Fallstricke bei der Verwendung von F1 Rating
Wählen Sie F1 basierend auf Ihrem Ziel:
- F1 wird verwendet, wenn Erinnerung und Präzision gleichermaßen wichtig sind.
- Es besteht keine Notwendigkeit, F1 zu verwenden, wenn eine Fehlerart teurer ist.
- Verwenden Sie bei Bedarf gewichtete F-Scores.
Verlassen Sie sich nicht allein auf die Formel 1:
- F1 ist eine kombinierte Metrik.
- Es verbirgt das Gleichgewicht zwischen Präzision und Erinnerung.
- Überprüfen Sie Präzision und Rückruf immer separat.
Gehen Sie vorsichtig mit Klassenungleichgewichten um:
- F1 schneidet im Vergleich zur Genauigkeit intestine ab, wenn es mit unausgeglichenen Daten konfrontiert wird.
- Mittelungsmethoden wirken sich auf das Endergebnis aus.
- Makro F1 behandelt alle Klassen gleich.
- Gewichtetes F1 begünstigt häufige Unterrichtsstunden.
- Wählen Sie die Methode, die Ihren Zielen entspricht.
Achten Sie auf null oder fehlende Vorhersagen:
- F1 kann Null sein, wenn eine Klasse nie vorhergesagt wird.
- Dies kann auf ein Modell- oder Datenproblem hinweisen.
- Überprüfen Sie immer die Verwirrungsmatrix.
Verwenden Sie F1 mit Bedacht für die Modellauswahl:
- F1 eignet sich intestine zum Vergleichen von Modellen.
- Kleine Unterschiede sind möglicherweise nicht aussagekräftig.
- Kombinieren Sie F1 mit Domänenwissen und anderen Metriken.
Abschluss
Der F1-Rating ist ein starker Indikator dafür Bewertung von Klassifizierungsmodellen. Es kombiniert Präzision und Rückruf in einem einzigen Wert und ist besonders nützlich, wenn beide Arten von Fehlern von Bedeutung sind. Es ist besonders effektiv bei Problemen mit unausgeglichenen Daten.
Im Gegensatz zur Genauigkeit hebt der F1-Rating Schwächen hervor, die die Genauigkeit verbergen kann. In diesem Artikel wurde anhand von Python-Beispielen erläutert, was der F1-Rating ist, wie er berechnet wird und wie er zu interpretieren ist.
Der F1-Rating sollte wie jede Bewertungsmetrik mit Vorsicht verwendet werden. Es funktioniert am besten, wenn Präzision und Erinnerung gleichermaßen wichtig sind. Wählen Sie Bewertungsmetriken immer basierend auf Ihren Projektzielen. Wenn der F1-Rating im richtigen Kontext verwendet wird, hilft er dabei, ausgewogenere und zuverlässigere Modelle zu erstellen.
Häufig gestellte Fragen
A. Ein F1-Rating von 0,5 weist auf eine mäßige Leistung hin. Dies bedeutet, dass das Modell Präzision und Erinnerung schlecht ausbalanciert und oft nur als Basislinie akzeptabel ist, insbesondere bei unausgeglichenen Datensätzen oder Modellen im Frühstadium.
A. Ein gutes F1-Ergebnis hängt vom Drawback ab. Im Allgemeinen gelten Werte über 0,7 als anständig, über 0,8 als stark und über 0,9 als ausgezeichnet, insbesondere bei Klassifizierungsaufgaben mit Klassenungleichgewicht.
A. Nein. Niedrigere F1-Werte deuten auf eine schlechtere Leistung hin. Da F1 Präzision und Erinnerung kombiniert, bedeutet ein höherer Wert immer, dass das Modell insgesamt weniger falsch-positive und falsch-negative Ergebnisse erzeugt.
A. Der F1-Rating wird verwendet, wenn ein Klassenungleichgewicht besteht oder wenn sowohl falsch-positive als auch falsch-negative Ergebnisse von Bedeutung sind. Es stellt eine einzige Metrik bereit, die im Gegensatz zur Genauigkeit, die irreführend sein kann, Präzision und Erinnerung in Einklang bringt.
A. Eine Genauigkeit von 80 % kann je nach Kontext intestine oder schlecht sein. In ausgeglichenen Datensätzen magazine dies akzeptabel sein, aber bei unausgeglichenen Problemen kann eine hohe Genauigkeit eine schlechte Leistung bei Minderheitsklassen verbergen.
A. Verwenden Sie Genauigkeit für ausgewogene Datensätze, bei denen alle Fehler gleichermaßen wichtig sind. Verwenden Sie den F1-Rating, wenn es um Klassenungleichgewichte geht oder wenn Präzision und Erinnerung wichtiger sind als allgemeine Korrektheit.
Hallo, ich bin Janvi, ein leidenschaftlicher Knowledge-Science-Fanatic, der derzeit bei Analytics Vidhya arbeitet. Meine Reise in die Welt der Daten begann mit einer tiefen Neugier, wie wir aus komplexen Datensätzen aussagekräftige Erkenntnisse gewinnen können.
Melden Sie sich an, um weiterzulesen und von Experten kuratierte Inhalte zu genießen.