
Die automatische Spracherkennung (ASR) hat einen langen Weg zurückgelegt. Obwohl es schon vor langer Zeit erfunden wurde, wurde es kaum jemals von jemandem verwendet. Allerdings haben sich Zeit und Technologie inzwischen erheblich verändert. Die Audiotranskription hat sich erheblich weiterentwickelt.
Technologien wie KI (Künstliche Intelligenz) haben den Prozess der Audio-zu-Textual content-Übersetzung vorangetrieben und liefern schnelle und genaue Ergebnisse. Infolgedessen haben auch die Anwendungen in der realen Welt zugenommen, wobei einige beliebte Apps wie Tik Tok, Spotify und Zoom den Prozess in ihre mobilen Apps integrieren.
Lassen Sie uns additionally ASR erkunden und herausfinden, warum es eine der beliebtesten Technologien im Jahr 2022 ist.
Was ist Speech-to-Textual content?
Speech-to-Textual content (STT), auch automatische Spracherkennung (ASR) genannt, wandelt gesprochene Audiodaten in geschriebenen Textual content um. Moderne Systeme sind Softwaredienste, die Audiosignale analysieren und Wörter mit Zeitstempeln und Konfidenzwerten ausgeben.
Für Groups, die Contact Middle, Gesundheitswesen und Sprach-UX aufbauen, ist STT das Tor zu durchsuchbaren, analysierbaren Gesprächen, unterstützenden Untertiteln und nachgelagerter KI wie Zusammenfassung oder Qualitätssicherung.
Gebräuchliche Bezeichnungen für Sprache und Textual content
Diese fortschrittliche Spracherkennungstechnologie ist auch beliebt und wird mit folgenden Namen bezeichnet:
- Automatische Spracherkennung (ASR)
- Spracherkennung
- Laptop-Spracherkennung
- Audiotranskription
- Bildschirmlesung
Anwendungen der Speech-to-Textual content-Technologie
Kontaktzentren
Echtzeit-Transkripte unterstützen die Reside-Agentenunterstützung; Batch-Transkripte unterstützen die Qualitätssicherung, Compliance-Audits und durchsuchbare Anrufarchive.
Beispiel: Verwenden Sie Streaming-ASR, um während eines Abrechnungsstreits Echtzeit-Eingabeaufforderungen anzuzeigen, und führen Sie dann nach dem Anruf eine Batch-Transkription aus, um die Qualitätssicherung zu bewerten und die Zusammenfassung automatisch zu generieren.
Gesundheitspflege
Ärzte diktieren Notizen und erhalten Besuchszusammenfassungen; Transkripte unterstützen die Kodierung (CPT/ICD) und die klinische Dokumentation – immer mit PHI-Schutzmaßnahmen.
Beispiel: Ein Anbieter zeichnet eine Konsultation auf, führt ASR aus, um die SOAP-Notiz zu erstellen, und hebt automatisch Arzneimittelnamen und Vitalwerte für die Überprüfung durch den Kodierer hervor, wobei die PHI-Schwärzung angewendet wird.
Medien & Bildung
Generieren Sie Bildunterschriften/Untertitel für Vorträge, Webinare und Sendungen; Fügen Sie eine leichte menschliche Bearbeitung hinzu, wenn Sie nahezu perfekte Genauigkeit benötigen.
Beispiel: Eine Universität transkribiert Vorlesungsvideos im Stapel, dann korrigiert ein Rezensent Namen und Fachsprache, bevor er barrierefreie Untertitel veröffentlicht.
Sprachprodukte und IVR
Wake-Phrase- und Befehlserkennung ermöglichen Freisprech-UX in Apps, Kiosken, Fahrzeugen und Good-Geräten; IVR verwendet Transkripte zur Weiterleitung und Auflösung.
Beispiel: Ein Financial institution-IVR erkennt „Meine Karte einfrieren“, bestätigt Particulars und löst den Workflow aus – keine Tastaturnavigation erforderlich.
Betrieb und Wissen
Besprechungen und Feldgespräche werden zu durchsuchbarem Textual content mit Zeitstempeln, Rednern und Aktionselementen für Teaching und Analysen.
Beispiel: Verkaufsgespräche werden transkribiert, thematisch markiert (Preise, Einwände) und zusammengefasst; Supervisor filtern nach „Verlängerungsrisiko“, um Folgemaßnahmen zu planen.
Warum sollten Sie Sprache in Textual content umwandeln?
- Machen Sie Gespräche auffindbar. Verwandeln Sie stundenlange Audioaufnahmen in durchsuchbaren Textual content für Audits, Schulungen und Kundeneinblicke.
- Automatisieren Sie die manuelle Transkription. Reduzieren Sie Durchlaufzeiten und Kosten im Vergleich zu Arbeitsabläufen, die ausschließlich von Menschen durchgeführt werden, und sorgen Sie gleichzeitig dafür, dass die Qualität perfekt sein muss.
- Unterstützen Sie die nachgelagerte KI. Transkript-Feed-Zusammenfassung, Absichts-/Themenextraktion, Compliance-Flags und Teaching.
- Verbessern Sie die Zugänglichkeit. Untertitel und Transkripte helfen Benutzern mit Hörverlust und verbessern die Benutzererfahrung in lauten Umgebungen.
- Unterstützen Sie Entscheidungen in Echtzeit. Streaming ASR ermöglicht Beratung auf Abruf, Echtzeitformulare und Reside-Überwachung.
Vorteile der Speech-to-Textual content-Technologie
Geschwindigkeits- und Modusflexibilität
Beim Streaming werden Teiltöne im Subsekundenbereich für den Reside-Einsatz bereitgestellt. Batch-Aufarbeitung von Rückständen mit umfassenderer Nachbearbeitung.
Beispiel: Transkripte zur Agentenunterstützung streamen; Spätere Batch-Neutranskribierung für Archive in Qualitätssicherungsqualität.
Qualitätsmerkmale eingebaut
Erhalten Sie Tagebucheinträge, Zeichensetzung/Groß-/Kleinschreibung, Zeitstempel und Phrasenhinweise/benutzerdefiniertes Vokabular für den Umgang mit Fachjargon.
Beispiel: Beschriften Sie Arzt-/Patientenrunden und erhöhen Sie die Medikamentennamen, damit sie korrekt transkribiert werden.
Bereitstellungsauswahl
Nutzen Sie Cloud-APIs für Skalierung/Updates oder lokale/Edge-Container für Datenresidenz und geringe Latenz.
Beispiel: Ein Krankenhaus betreibt ASR in seinem Rechenzentrum, um PHI vor Ort zu halten.
Individualisierung und Mehrsprachigkeit
Schließen Sie Genauigkeitslücken mit Phrasenlisten und Domänenanpassungen; Unterstützt mehrere Sprachen und Code-Switching.
Beispiel: Eine Fintech-App fördert Markennamen und Ticker auf Englisch/Hinglisch und optimiert sie dann für Nischenbegriffe.
Verstehen der Funktionsweise der automatischen Spracherkennung
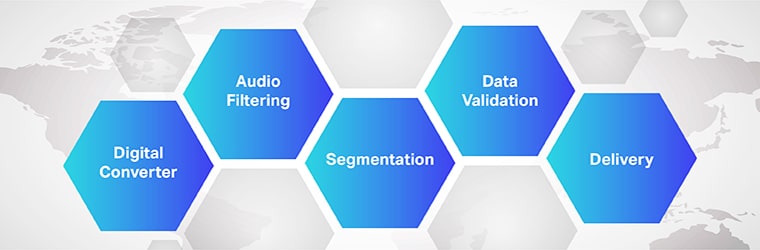
Die Funktionsweise einer Audio-zu-Textual content-Übersetzungssoftware ist komplex und erfordert die Implementierung mehrerer Schritte. Wie wir wissen, handelt es sich bei Speech-to-Textual content um eine exklusive Software program zur Konvertierung von Audiodateien in ein bearbeitbares Textformat. Dies geschieht durch die Nutzung der Spracherkennung.
Verfahren
- Zunächst wendet ein Computerprogramm mithilfe eines Analog-Digital-Wandlers linguistische Algorithmen auf die bereitgestellten Daten an, um Vibrationen von akustischen Signalen zu unterscheiden.
- Anschließend werden die relevanten Geräusche durch Messung der Schallwellen gefiltert.
- Darüber hinaus werden die Laute in Hundertstel- oder Tausendstelsekunden verteilt/segmentiert und mit Phonemen (einer messbaren Lauteinheit zur Unterscheidung eines Wortes von einem anderen) abgeglichen.
- Die Phoneme werden außerdem einem mathematischen Modell unterzogen, um die vorhandenen Daten mit bekannten Wörtern, Sätzen und Phrasen zu vergleichen.
- Die Ausgabe erfolgt in einer Textual content- oder computerbasierten Audiodatei.
(Lesen Sie auch: Ein umfassender Überblick über die automatische Spracherkennung)
Was sind die Verwendungsmöglichkeiten von Sprache zu Textual content?
Es gibt mehrere Einsatzmöglichkeiten von automatischer Spracherkennungssoftware, z
- Inhaltssuche: Die meisten von uns sind vom Eintippen von Buchstaben auf dem Helpful dazu übergegangen, einen Knopf zu drücken, damit die Software program unsere Stimme erkennt und die gewünschten Ergebnisse liefert.
- Kundendienst: Chatbots und KI-Assistenten, die den Kunden durch die wenigen ersten Schritte des Prozesses führen können, sind mittlerweile weit verbreitet.
- Untertitel in Echtzeit: Mit dem zunehmenden weltweiten Zugang zu Inhalten ist die Untertitelung in Echtzeit zu einem prominenten und bedeutenden Markt geworden, der ASR für seinen Einsatz vorantreibt.
- Elektronische Dokumentation: Mehrere Verwaltungsabteilungen haben begonnen, ASR zur Erfüllung von Dokumentationszwecken einzusetzen, um eine höhere Geschwindigkeit und Effizienz zu erreichen.
Was sind die größten Herausforderungen bei der Spracherkennung?
Akzente und Dialekte. Das gleiche Wort kann in den verschiedenen Regionen sehr unterschiedlich klingen, was Modelle, die auf „Normal“-Sprache trainiert sind, verwirrt. Die Lösung ist einfach: Sammeln und testen Sie mit akzentreichen Audiodaten und fügen Sie Phrasen-/Aussprachehinweise für Marken-, Orts- und Personennamen hinzu.
Kontext und Homophone. Um das richtige Wort („to/too/two“) auszuwählen, sind Kontext- und Fachkenntnisse erforderlich. Verwenden Sie stärkere Sprachmodelle, passen Sie sie an Ihren eigenen Domänentext an und validieren Sie kritische Einheiten wie Medikamentennamen oder SKUs.
Rauschen und schlechte Audiokanäle. Verkehr, Übersprechen, Anrufcodecs und Fernfeldmikrofone verdecken wichtige Geräusche. Entrauschen und normalisieren Sie Audio, verwenden Sie Sprachaktivitätserkennung, simulieren Sie echte Geräusche/Codecs im Coaching und bevorzugen Sie bessere Mikrofone, wo Sie können.
Code-Switching und mehrsprachige Sprache. Menschen verwechseln häufig Sprachen oder wechseln mitten im Satz, wodurch einsprachige Modelle zerstört werden. Wählen Sie mehrsprachige oder Code-Swap-fähige Modelle, werten Sie Audiodaten in verschiedenen Sprachen aus und verwalten Sie gebietsschemaspezifische Phrasenlisten.
Mehrere Sprecher und Überschneidungen. Wenn sich Stimmen überschneiden, verschwimmen die Transkripte, wer was gesagt hat. Aktivieren Sie die Lautsprecherdialogisierung, um Abbiegungen zu kennzeichnen, und verwenden Sie Trennung/Beamforming, wenn Audio mit mehreren Mikrofonen verfügbar ist.
Videohinweise in Aufnahmen. Bei Movies sorgen Lippenbewegungen und Textual content auf dem Bildschirm für Bedeutung, die allein durch den Ton verloren gehen kann. Wenn es auf Qualität ankommt, verwenden Sie audiovisuelle Modelle und kombinieren Sie ASR mit OCR, um Folientitel, Namen und Begriffe zu erfassen.
Anmerkungs- und Beschriftungsqualität. Inkonsistente Transkripte, falsche Sprecherkennzeichnungen oder eine schlampige Zeichensetzung beeinträchtigen sowohl das Coaching als auch die Bewertung. Legen Sie einen klaren Styleguide fest, überprüfen Sie regelmäßig Beispiele und behalten Sie einen kleinen Goldsatz bei, um die Annotatorkonsistenz zu messen.
Datenschutz und Compliance. Anrufe und klinische Aufzeichnungen können PII/PHI enthalten, daher müssen Speicherung und Zugriff streng kontrolliert werden. Schwärzen oder anonymisieren Sie Ausgaben, schränken Sie den Zugriff ein und wählen Sie Cloud- statt lokale/Edge-Bereitstellungen, um Ihre Richtlinien zu erfüllen.
So wählen Sie den besten Speech-to-Textual content-Anbieter aus
Wählen Sie einen Anbieter aus, indem Sie Ihre Audioqualität (Akzente, Geräte, Geräusche) testen und die Genauigkeit gegen Datenschutz, Latenz und Kosten abwägen. Fangen Sie klein an, messen Sie und skalieren Sie dann.
Definieren Sie zunächst die Bedürfnisse
- Anwendungsfälle: Streaming, Batch oder beides
- Sprachen/Akzente (inkl. Code-Umschaltung)
- Audiokanäle: Telefon (8 kHz), App/Desktop, Fernfeld
- Datenschutz/Aufenthalt: PII/PHI, Area, Aufbewahrung, Prüfung
- Einschränkungen: Latenzziel, SLA, Price range, Cloud vs. On-Prem/Edge
Bewerten Sie Ihr Audio
- Genauigkeit: WER + Entitätsgenauigkeit (Jargon, Namen, Codes)
- Multi-Sprecher: Diarisierungsqualität (Wer hat wann gesprochen)
- Formatierung: Satzzeichen, Groß-/Kleinschreibung, Zahlen/Datumsangaben
- Streaming: TTFT/TTF-Latenz + Stabilität
- Funktionen: Phrasenlisten, benutzerdefinierte Modelle, Schwärzung, Zeitstempel
Fragen Sie im RFP nach
- Rohergebnisse auf unserem Testsatz anzeigen (nach Akzent/Geräusch)
- Stellen Sie eine Streaming-Latenz von p50/p95 für unsere Clips bereit
- Diarisierungsgenauigkeit für 2–3 Lautsprecher mit Überlappung
- Datenverarbeitung: Verarbeitung in der Area, Aufbewahrung, Zugriffsprotokolle
- Pfad von Phrasenlisten → benutzerdefiniertes Modell (Daten, Zeit, Kosten)
Achten Sie auf rote Fahnen
- Tolle Demo, schwache Ergebnisse bei Ihrem Audio
- „Wir werden es mit Feinabstimmung beheben“, aber kein Plan/keine Daten
- Versteckte Gebühren für die Aufzeichnung/Redaktion/Speicherung
(Lesen Sie auch: Den Erfassungsprozess von Audiodaten für die automatische Spracherkennung verstehen)
Die Zukunft der Speech-to-Textual content-Technologie
Größere mehrsprachige „Grundlagen“-Modelle. Erwarten Sie einzelne Modelle, die dank umfangreichem Vortraining und leichter Feinabstimmung mehr als 100 Sprachen mit besserer Genauigkeit bei geringen Ressourcen abdecken.
Sprache + Übersetzung in einem Stapel. Einheitliche Modelle bewältigen ASR, Sprache-zu-Textual content-Übersetzung und sogar Sprache-zu-Sprache – wodurch Latenzzeiten reduziert und Code zusammengeklebt werden.
Standardmäßig intelligentere Formatierung und Diarisierung. Automatische Interpunktion, Groß-/Kleinschreibung, Zahlen und zuverlässige „Wer hat wann gesprochen“-Kennzeichnung werden zunehmend sowohl für Batch als auch für Streaming integriert.
Audiovisuelle Erkennung für schwierige Umgebungen. Lippenhinweise und Bildschirmtext (OCR) steigern die Transkripte bei lautem Ton – ein bereits schnelllebiges Forschungsgebiet und frühe Produktprototypen.
Datenschutzorientierte Schulung und On-System/Edge. Föderiertes Lernen und Container-Bereitstellungen sorgen dafür, dass Daten lokal bleiben und gleichzeitig die Modelle verbessert werden – wichtig für regulierte Sektoren.
Regulierungsbewusste KI. Die Zeitpläne des EU-KI-Gesetzes bedeuten mehr Transparenz, Risikokontrollen und Dokumentation, die in STT-Produkte und -Beschaffung integriert sind.
Umfangreichere Auswertung über WER hinaus. Die Groups werden sich auf Entitätsgenauigkeit, Diarisierungsqualität, Latenz (TTFT/TTF) und Equity über Akzente/Geräte hinweg standardisieren, nicht nur auf Schlagzeilen-WER.
Wie Shaip Ihnen dabei hilft, dorthin zu gelangen
Auch wenn sich diese Traits durchsetzen, hängt der Erfolg immer noch davon ab Ihre Daten. Shaip bietet akzentreiche mehrsprachige Datensätze, PHI-sichere De-Identifizierung und Gold-Testsätze (WER, Entität, Diarisierung, Latenz), um Anbieter truthful zu vergleichen und Modelle zu optimieren – so können Sie die Zukunft von STT mit Zuversicht annehmen. Sprechen Sie mit den ASR-Datenexperten von Shaip um einen schnellen Piloten zu planen.