
Sie müssen mit der endlosen Wartezeit eines KI-Modells konfrontiert gewesen sein, das sich die Zeit nimmt, Ihre Frage zu beantworten. Um diesem Warten ein Ende zu setzen, ist das neue Mercury 2-Argumentationsmodell von Inception Labs jetzt stay. Es funktioniert etwas anders als andere. Es nutzt die Diffusion, um qualitativ hochwertige Antworten nahezu augenblicklich bereitzustellen. In diesem Artikel werden wir die einzigartigen Qualitäten des Mercury 2-Argumentationsmodells erleben und mit seinen Stärken experimentieren.
Eine neue Denkweise: Diffusion vs. Autoregression
Die autoregressive Dekodierung ist ein Prozess, der am häufigsten verwendet wird große Sprachmodelle derzeit genutzte Instruments wie die von Google und OpenAI erstellten. Sie produzieren jeweils ein Wort oder einen Textbaustein. Dies funktioniert wie eine Schreibmaschine, wobei das nachfolgende Wort an das vorherige Wort gebunden wird.
Obwohl es funktioniert, gibt es auch einen Engpass. Schwierige Fragen erfordern Gedankenketten, die das Modell nacheinander durchgehen muss. Dabei handelt es sich um einen seriellen Prozess, der die Geschwindigkeit einschränkt und hohe Kosten verursacht. Es ist besonders nützlich für tiefgreifende Denkprozesse.
Das Argumentationsmodell von Mercury 2 verhält sich anders. Es gehört zu den ersten kommerzielle Diffusionssprachmodelle. Anstatt einem Token-für-Token-Ansatz zu folgen, beginnt es mit einer groben Model der vollständigen Antwort. Anschließend wird es durch einen Verfeinerungsprozess besser. Betrachten Sie es eher als Editor denn als Schreibmaschine. Es prüft und korrigiert gleichzeitig die gesamte Antwort und ist so in der Lage, Fehler frühzeitig im Prozess zu korrigieren. Die Geschwindigkeit dieser Methode liegt in dieser Parallelität.
Dies ist kein neues Konzept in der KI. Diffusionsmodelle haben sich bereits in der Bild- und Videoerstellung bewährt. Diese Technologie wird jetzt von Inception Labs, einem Begin-up von Akademikern aus Stanford, UCLA und Cornell, genutzt und zeigt eine bemerkenswert gute Leistung.
Geschwindigkeit und Kosten: Der Vorteil von Mercury 2
Die Geschwindigkeit des Mercury 2-Argumentationsmodells ist seine herausragendste Eigenschaft. In Benchmarks beträgt der Durchsatz etwa 1.000 Token. Perspektivisch laufen andere beliebte Modelle wie Claude 4.5 Haiku und GPT-5 mini mit etwa 89 bzw. 71 Token professional Sekunde. Dadurch erhöht sich die Geschwindigkeit von Mercury 2 um mehr als das Zehnfache. Dies ist nicht nur eine Zahl in einem Diagramm, sondern stellt einen Unterschied in der realen Welt dar. Bei komplizierteren Aufgaben kann es bei anderen Modellen mehrere Sekunden dauern, bis eine Frage beantwortet ist. Mittlerweile kann Mercury 2 eine Frage in weniger als zwei Sekunden beantworten.

Diese Geschwindigkeit gibt es nicht um jeden Preis. Tatsächlich ist Mercury 2 viel günstiger als seine Konkurrenten. Der Preis beträgt 0,25 professional Million Enter-Tokens und der Enter-Preis 0,75 professional Million Output-Tokens. Die Erstellung einer Antwort kostet etwa 2,5-mal so viel wie GPT-5 mini und mehr als 6,5-mal so viel wie Claude Haiku 4.5. Diese Geschwindigkeit, gepaart mit niedrigen Kosten, ermöglicht neue Anwendungsfälle, insbesondere solche Anwendungen, die auf Echtzeitinteraktionen und komplizierten Schleifen von KI-Agenten basieren.
Qualität und Leistung
Geschwindigkeit kann nur genutzt werden, wenn die Antworten stimmen. In dieser Hinsicht steht das Argumentationsmodell von Mercury 2 für sich allein. Von den Qualitätsstandards her entspricht es allen anderen gängigen Modellen. Beim AIME 2025-Mathe-Benchmark erreichte es einen Wert von 91,1. Auch bei der GPQA-Bewertung der Naturwissenschaften auf Graduiertenebene und der anschließenden Lehrtätigkeit im IFBench schnitt es intestine ab. Diese Ergebnisse zeigen, dass die Fehlerkorrektur des Diffusionsprozesses die Qualität nicht auf Kosten der Geschwindigkeit beeinträchtigt.
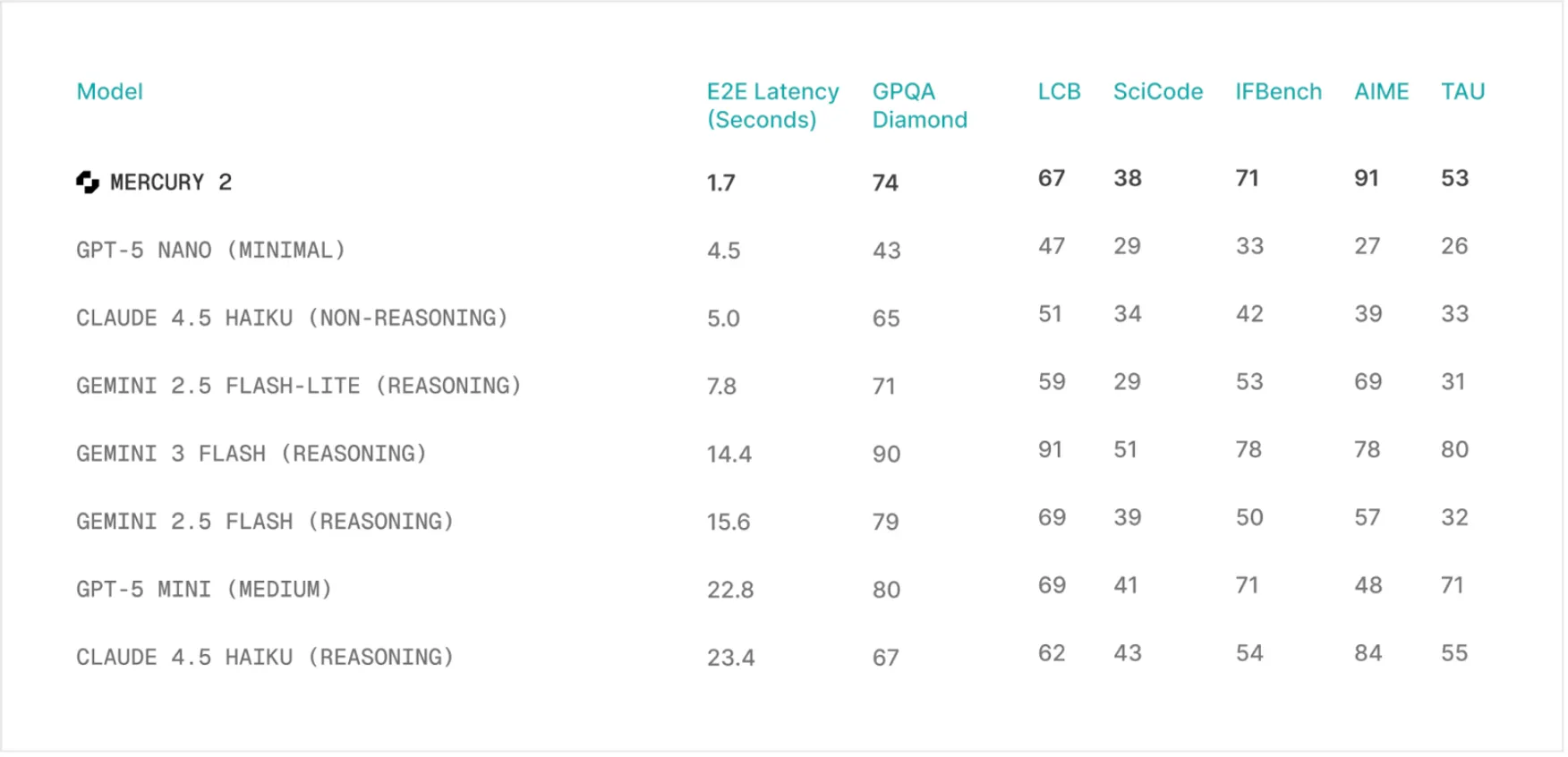
Das Modell fördert außerdem ein Kontextfenster mit einer Größe von 128 KB, die Verwendung von Instruments und die JSON-Ausgabe. Es ist daher ein praktisches Werkzeug für die Entwickler. Die Funktionen sind entscheidend für die Erstellung fortschrittlicher Anwendungen, die eine Argumentation mit hohem Durchsatz erfordern. Aufgrund seiner Fähigkeit, umfangreiche Informationen zu verarbeiten und mit anderen Anwendungen zu kommunizieren, eignet es sich hervorragend für Anwendungen wie Echtzeit-Sprachassistenten, Suchtools und Codeunterstützung
Praktisch mit dem Mercury 2 Reasoning Mannequin
Sehen ist Glauben. Quecksilber 2 lässt sich am besten durch Experimente verstehen. Sie können entweder mit dem Modell interagieren oder den API-Zugriff abonnieren, um Ihre eigenen Anwendungen zu erstellen.
Eine hervorragende Möglichkeit, mit dem Modell zu experimentieren und die einzigartigen Fähigkeiten zu testen, besteht darin, mit seiner Einstellung reasoning_effort zu experimentieren. Ein einfaches, reales Drawback.
Der Autowaschtest
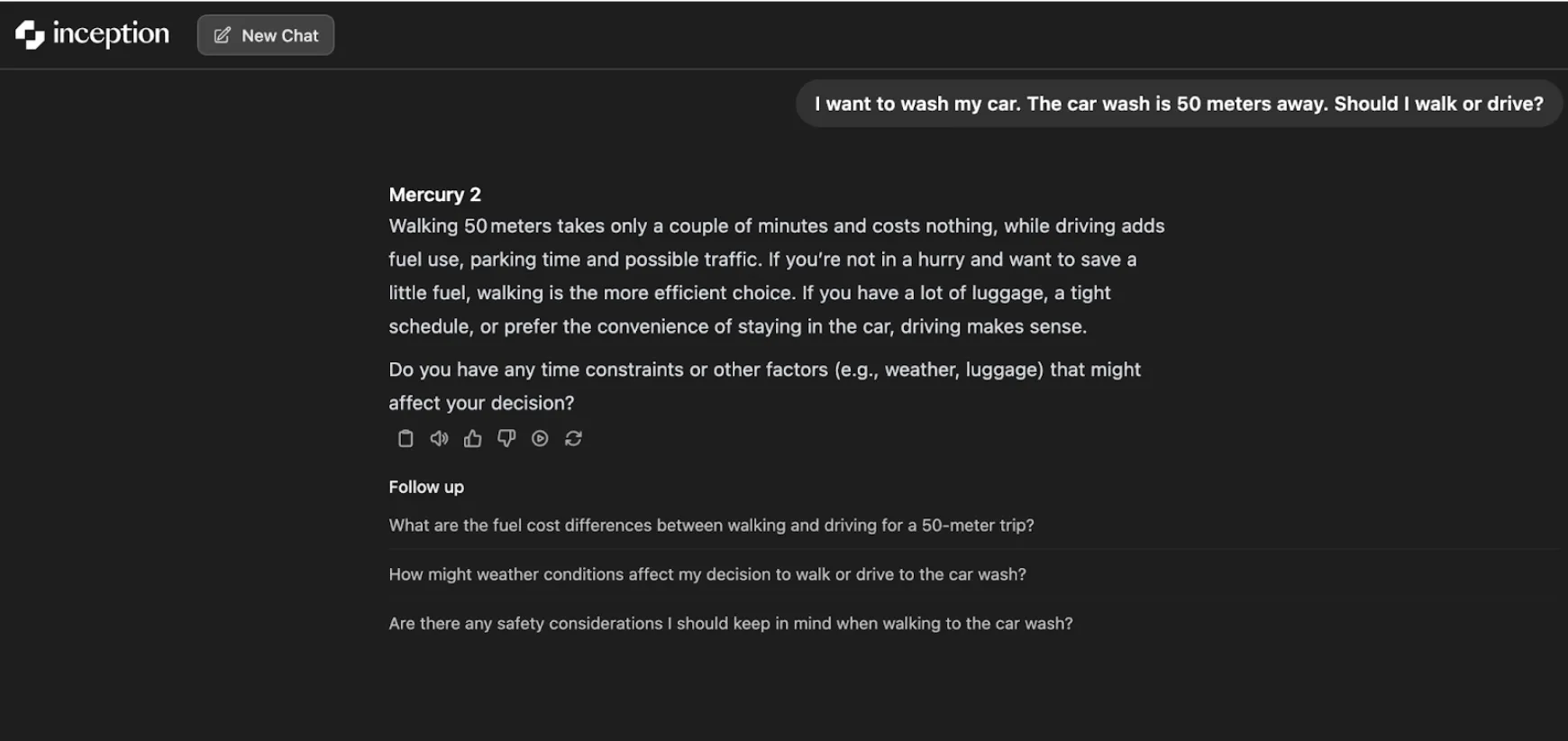
Stellen Sie dem Modell die folgende Frage:
„Ich möchte mein Auto waschen. Die Waschanlage ist 50 Meter entfernt. Soll ich zu Fuß gehen oder fahren?“
Das Modell mit geringem Denkaufwand liefert eine sinnvolle und einfache Antwort: Es ist günstiger und in wenigen Minuten zu Fuß erledigt. Zu Recht wird das Gehen als die effizienteste Choice für kurze Distanzen anerkannt.
Je mehr Argumentationsaufwand Sie jedoch investieren, desto realistischer und pragmatischer erweist sich das Modell. Es berücksichtigt die Artwork der Autowaschanlage. Im Falle einer Autowäsche ist das einzig Vernünftige, selbst zu fahren. Handelt es sich um eine Selbstbedienungsstation, kann bei guten Bedingungen auch der Fußmarsch eine Lösung sein. Der überlegene Argumentationskontext führt zu einer fundierteren und kontextualisierten Empfehlung: Bei den meisten Autowaschanlagen ist das Autofahren die einfachste Choice.
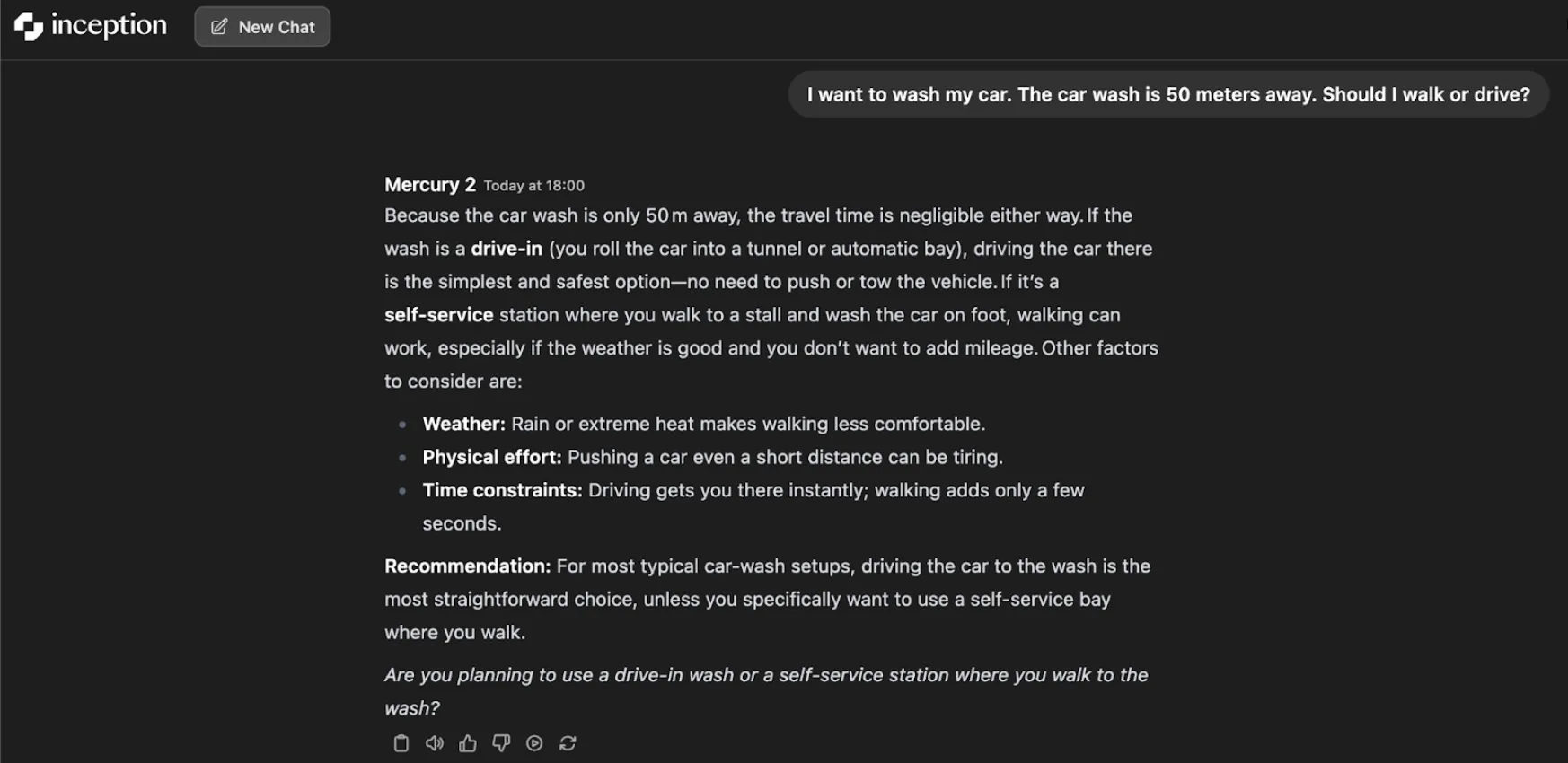
Es handelt sich lediglich um einen einfachen Take a look at, der zeigt, wie der iterative Prozess der Verfeinerung des Modells zu einem besseren Verständnis führen kann, vorausgesetzt, dass mehr Zeit zum Nachdenken zur Verfügung steht.
Der Artikelzusammenfassungstest
Hier ist mein vorheriger Artikel über LLM-Bewertungsmetriken, der ziemlich umfangreich zu lesen ist. Versuchen wir, es abschnittsweise zusammenzufassen, und schauen wir, wie viel Zeit es in Anspruch nehmen wird.
Immediate:
https://www.analyticsvidhya.com/weblog/2025/03/llm-evaluation-metrics/
Hier ist ein Artikel mit 5.000 bis 10.000 Wörtern. Fassen Sie das gesamte Stück in einem überzeugenderen Ton zusammen, verbessern Sie die Klarheit, entfernen Sie Redundanzen, verstärken Sie die Einleitung und den Schluss und sorgen Sie für eine durchgehend einheitliche Terminologie.
Als wir diese Eingabeaufforderung in Mercury 2 ausführten, wurde der Artikel sofort extrahiert und die Ergebnisse in weniger als 3 Sekunden angezeigt.
Video:
Als ich aus Neugier die gleiche Eingabeaufforderung auf ChatGPT versuchte, dauerte es quick 25 Sekunden. Diesmal dauerte es nur, darüber nachzudenken, was und wie zu tun ist, und weitere 10 Sekunden, um die Antwort zu generieren.

Fazit: Ein Blick in die Zukunft der KI
Das Argumentationsmodell Mercury 2 ist nicht nur ein weiterer Akteur auf dem überfüllten KI-Markt. Es ist die mögliche Veränderung im Herangehen künstliche Intelligenz in seiner Konstruktion und Kommunikation. Es befasst sich mit dem grundlegenden Drawback der Latenz und öffnet somit die Tür zu einer neuen Era wirklich reaktionsfähiger Anwendungen. Die Zeiten, in denen eine KI denken musste, werden bald vorbei sein. Mit Modellen wie Mercury 2 kann man sagen, dass die Zukunft der KI schnell, günstig und überraschend leistungsstark sein wird.
Häufig gestellte Fragen
Das Mercury 2 Reasoning-Modell ist ein neues großes Sprachmodell von Inception Labs, das einen diffusionsbasierten Ansatz verwendet, um Textual content mit hoher Geschwindigkeit zu generieren.
Anstatt Textual content Wort für Wort zu generieren, erstellt Mercury 2 einen Entwurf der vollständigen Antwort und verfeinert ihn parallel, was ihn viel schneller macht.
Mercury 2 kann Textual content mit etwa 1.000 Token professional Sekunde generieren, was etwa zehnmal schneller ist als vergleichbare Modelle.
Ja, bei Qualitätsbenchmarks schneidet der Mercury 2 in Bereichen wie Mathematik, Naturwissenschaften und Unterrichtsverfolgung mit anderen Spitzenmodellen konkurrenzfähig ab.
Sie können direkt mit dem Modell chatten oder sich über die Inception Labs-Web site für einen frühen API-Zugriff anmelden.
Harsh Mishra ist ein KI/ML-Ingenieur, der mehr Zeit damit verbringt, mit großen Sprachmodellen zu sprechen als mit echten Menschen. Leidenschaftlich für GenAI, NLP und die intelligentere Entwicklung von Maschinen (damit sie ihn noch nicht ersetzen). Wenn er nicht gerade Modelle optimiert, optimiert er wahrscheinlich seinen Kaffeekonsum. 🚀☕
Melden Sie sich an, um weiterzulesen und von Experten kuratierte Inhalte zu genießen.