
In unserer digitalen Welt verarbeiten Unternehmen täglich Unmengen an Daten. Daten halten die Organisation am Laufen und helfen ihr, fundiertere Entscheidungen zu treffen. Unternehmen werden mit Dokumenten überschwemmt, von Mitarbeitern, die neue Dokumente erstellen, bis hin zu Dokumenten, die aus verschiedenen Quellen wie E-Mails, Portalen, Rechnungen, Quittungen, Anträgen, Vorschlägen, Ansprüchen und mehr in das Unternehmen gelangen.
Sofern jemand diese Dokumente nicht überprüft, gibt es keine Möglichkeit herauszufinden, worum es in einem bestimmten Dokument geht oder wie es am besten verarbeitet werden kann. Es ist jedoch schwierig, jedes Dokument manuell zu bearbeiten, um zu wissen, wo und wie es gespeichert werden soll.
Lassen Sie uns die Dokumentenklassifizierung untersuchen, verstehen, warum die Dokumentenklassifizierung für ein Unternehmen von entscheidender Bedeutung ist, und untersuchen, wie Laptop Imaginative and prescient, Verarbeitung natürlicher Sprache und optische Zeichenerkennung eine Rolle bei der Dokumentenklassifizierung oder -verarbeitung spielen.
Was ist Dokumentenklassifizierung?
Manuelle Dokumentenklassifizierungsaufgaben können für viele Unternehmen einen großen Engpass darstellen, da sie zeitaufwändig, fehleranfällig und ressourcenintensiv sind. Wenn auf NLP und ML basierende automatische Klassifizierungsmodelle verwendet werden, wird der Textual content in einem Dokument automatisch identifiziert, markiert und kategorisiert.
Dokumentenklassifizierungsaufgaben basieren im Allgemeinen auf zwei Klassifizierungen: Textual content und visuell. Die Textklassifizierung basiert auf dem Style, Thema oder Typ des Inhalts. Die Verarbeitung natürlicher Sprache wird verwendet, um das Konzept, die Emotionen und den Kontext des Textes zu verstehen. Die visuelle Klassifizierung erfolgt anhand der im Dokument vorhandenen visuellen Strukturelemente mithilfe von Laptop Imaginative and prescient- und Bilderkennungssystemen.
Warum benötigen Unternehmen eine Dokumentenklassifizierung?

Jede Organisation, vom Begin-up bis zum Fortune-500-Unternehmen, hat täglich mit riesigen Dokumentenmengen zu kämpfen. Ohne Automatisierung wird die manuelle Dokumentenverarbeitung zu einem Engpass, der Arbeitsabläufe verlangsamt und Ressourcen belastet.
Deshalb ist die KI-gestützte Dokumentenklassifizierung ein Muss:
- Beschleunigt die Dokumentenverwaltung: Automatisiert das Sortieren, Indizieren und Weiterleiten und ermöglicht so den sofortigen Zugriff auf relevante Dokumente.
- Erhöht die Genauigkeit und reduziert Fehler: Minimiert menschliche Fehler, die bei sich wiederholenden Aufgaben häufig vorkommen, und gewährleistet so die Datenintegrität.
- Verbessert die betriebliche Effizienz: Befreit Mitarbeiter von alltäglichen Aufgaben und ermöglicht ihnen die Konzentration auf strategische Initiativen.
- Nahtlose Skalierung: Bewältigt wachsende Dokumentenmengen ohne proportionale Personalaufstockung.
- Unterstützt Compliance und Sicherheit: Stellt sicher, dass vertrauliche Dokumente korrekt identifiziert und gemäß den Vorschriften gehandhabt werden.
Branchen wie Gesundheitswesen, Finanzen, Versicherungen, Recht und E-Commerce nutzen bereits KI-basierte Klassifizierung, um die Schadensbearbeitung, Vertragsverwaltung, Kundenbetreuung und Bestandskategorisierung zu optimieren.
Dokumentenklassifizierung vs. Textklassifizierung: Die Nuancen verstehen
Obwohl Dokumentklassifizierung und Textklassifizierung oft synonym verwendet werden, weisen sie subtile, aber wichtige Unterschiede auf:
| Aspekt | Textklassifizierung | Dokumentenklassifizierung |
|---|---|---|
| Umfang | Konzentriert sich ausschließlich auf die Analyse und Kategorisierung von Textual content. | Analysiert sowohl Textual content als auch visuelle/Format-Elemente. |
| Dateneingabe | Rein textliche Inhalte (Sätze, Absätze). | Gesamtes Dokument inklusive Bildern, Tabellen, Formatierung. |
| Anwendungsfälle | Stimmungsanalyse, Themen-Tagging, Spam-Erkennung. | Rechnungssortierung, Identifizierung der Vertragsart, Formularbearbeitung. |
| Techniken | NLP-zentrierte Methoden wie Stimmungsanalyse, Entitätserkennung. | Kombiniert NLP mit Laptop Imaginative and prescient und OCR. |
Im Wesentlichen ist die Textklassifizierung eine Teilmenge der Dokumentenklassifizierung, die ein umfassenderes, multimodales Verständnis von Dokumenten ermöglicht.
Wie funktioniert die Dokumentenklassifizierung?
Die Dokumentenklassifizierung kann mit zwei Methoden erfolgen: manuell und automatisch. Bei der manuellen Klassifizierung muss ein menschlicher Benutzer Dokumente überprüfen, Beziehungen zwischen Konzepten finden und entsprechend kategorisieren. Bei der automatischen Dokumentenklassifizierung kommen Techniken des maschinellen Lernens und des Deep Studying zum Einsatz. Lassen Sie uns die Methoden zur Dokumentenklassifizierung entschlüsseln, indem wir die verschiedenen Arten von Dokumenten verstehen, die in Geschäftsprozessen ablaufen.
Strukturierte Dokumente
Ein Dokument enthält intestine formatierte Daten mit einheitlicher Nummerierung und Schriftarten. Auch das Format des Dokuments ist einheitlich und weist keine Abweichungen auf. Die Erstellung von Klassifizierungstools für solche strukturierten Dokumente ist einfach und vorhersehbar.
Unstrukturierte Dokumente
Der Inhalt eines unstrukturierten Dokuments wird in einem unstrukturierten oder offenen Format präsentiert. Beispiele hierfür sind Briefe, Verträge und Bestellungen. Da sie inkonsistent sind, wird es schwierig, wichtige Informationen zu finden. 
Techniken zur Dokumentenklassifizierung?
Die automatische Dokumentenklassifizierung nutzt Techniken des maschinellen Lernens und der Verarbeitung natürlicher Sprache, um den Kategorisierungsprozess zu vereinfachen, zu automatisieren und zu beschleunigen. Maschinelles Lernen macht die Dokumentenklassifizierung weniger umständlich, schneller, genauer, skalierbarer und unvoreingenommener.
Die Klassifizierung von Dokumenten kann mithilfe von drei Techniken erfolgen. Sie sind
Regelbasierte Technik
Die regelbasierte Technik basiert auf sprachlichen Mustern und Regeln, die dem Modell Anweisungen geben. Die Modelle werden trainiert, um Sprachmuster, Morphologie, Syntax, Semantik usw. zu identifizieren und den Textual content zu kennzeichnen. Diese Technik kann ständig verbessert, neue Regeln hinzugefügt und improvisiert werden, um genaue Erkenntnisse zu gewinnen. Diese Technik kann jedoch zeitaufwändig, nicht skalierbar und komplex sein.
Überwachtes Lernen
Beim überwachten Lernen wird eine Reihe von Tags definiert und mehrere Texte werden manuell mit Tags versehen, damit das maschinelle Lernsystem lernen kann, genaue Vorhersagen zu treffen. Der Algorithmus wird manuell anhand einer Reihe getaggter Dokumente trainiert. Je mehr Daten Sie in das System einspeisen, desto besser ist das Ergebnis. Wenn der Textual content beispielsweise lautet: „Der Service battle erschwinglich“, sollte das Tag unter „Preise“ stehen. Sobald das Coaching des Modells abgeschlossen ist, kann es automatisch unsichtbare Dokumente vorhersagen.
Unüberwachtes Lernen
Beim unüberwachten Lernen werden ähnliche Dokumente in verschiedene Cluster gruppiert. Für dieses Lernen sind keine Vorkenntnisse erforderlich. Die Dokumente werden nach Schriftarten, Themen, Vorlagen und mehr kategorisiert. Wenn die Regeln vordefiniert, optimiert und perfektioniert sind, kann dieses Modell eine genaue Klassifizierung liefern.
Wie funktioniert die KI-basierte Dokumentenklassifizierung?
Die KI-gesteuerte Dokumentenklassifizierung folgt normalerweise den folgenden Schlüsselschritten:
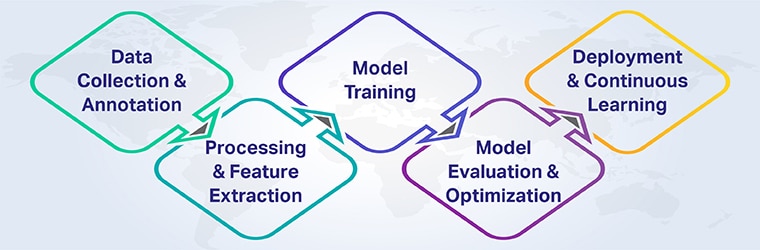
1. Datenerfassung und Annotation
Hochwertige, vielfältige Datensätze sind die Grundlage. Dokumente müssen kategorienübergreifend gesammelt und genau beschriftet (getaggt) werden, um Modelle für maschinelles Lernen effektiv zu trainieren.
2. Vorverarbeitung und Merkmalsextraktion
Mithilfe der optischen Zeichenerkennung (OCR) wird Textual content aus gescannten oder bildbasierten Dokumenten extrahiert. NLP-Techniken bereinigen, tokenisieren und wandeln den Textual content dann in sinnvolle Funktionen um. Gleichzeitig analysiert Laptop Imaginative and prescient Dokumentlayouts und visuelle Hinweise.
3. Modellschulung
Überwachte Lernalgorithmen (z. B. Transformer, CNNs) werden auf gekennzeichneten Daten trainiert, um Muster zu erkennen. Modelle lernen, Dokumentmerkmale Kategorien zuzuordnen.
4. Modellbewertung und -optimierung
Modelle werden rigoros anhand unsichtbarer Daten getestet, um Genauigkeit, Präzision und Erinnerung zu messen. Hyperparameter werden optimiert, um die Leistung zu verbessern.
5. Bereitstellung und kontinuierliches Lernen
Nach der Bereitstellung klassifizieren Modelle eingehende Dokumente in Echtzeit und verbessern sich im Laufe der Zeit durch Feedbackschleifen und zusätzliche Trainingsdaten.
Anwendungsfälle aus der Praxis
Die Dokumentenklassifizierung wird zur Lösung verschiedener Geschäftsprobleme eingesetzt. Obwohl es sich bei den meisten Anwendungsfällen nicht um Klassifizierungsaufgaben handelt, wird der Algorithmus zur Lösung mehrerer realer Probleme eingesetzt.
-
Spam-Erkennung
Die Dokumentenklassifizierung, insbesondere die Textklassifizierung, dient der Erkennung unerwünschten Spams. Das Modell ist darauf trainiert, Spam-Phrasen und deren Häufigkeit zu erkennen, um festzustellen, ob es sich bei der Nachricht um Spam handelt. Der Gmail-Spam-Detektor von Google verwendet beispielsweise die Technik der Verarbeitung natürlicher Sprache, um häufig vorkommende Wörter in Junk-Nachrichten zu erkennen und die E-Mails im richtigen Ordner abzulegen.
-
Stimmungsanalyse
Die Stimmungsanalyse durch Social Listening hilft Unternehmen, ihre Kunden, ihre Meinungen und Bewertungen zu verstehen. Durch die Klassifizierung von Bewertungen, Rückmeldungen und Beschwerden und deren Kategorisierung nach ihrer emotionalen Natur helfen die NLP-basierten Modelle bei der Stimmungsanalyse. Das Modell ist darauf trainiert, Wörter zu extrahieren, die optimistic oder unfavourable Konnotationen bezeichnen oder haben.
-
Ticket oder Prioritätsklassifizierung
Die Kundendienstabteilung eines jeden Unternehmens stößt auf viele Serviceanfragen und Tickets. Ein automatisiertes Dokumentenklassifizierungstool kann dabei helfen, die enorme Menge an Tickets zu bewältigen. Mithilfe von NLP können Prioritätstickets an die richtige Abteilung weitergeleitet werden. Dadurch wird die Geschwindigkeit der Lösung, Verarbeitung und Wartung erheblich verbessert.
-
Objekterkennung
Die automatisierte Dokumentenklassifizierung wird auch verwendet, um große Mengen visueller Daten in Dokumenten zu verarbeiten, indem sie nach Kategorien klassifiziert werden. Die Objekterkennung wird typischerweise im E-Commerce oder in Produktionseinheiten zur Klassifizierung von Produkten eingesetzt.
Erste Schritte mit der Dokumentenklassifizierung auf Foundation von KI
Dokumente enthalten Daten, die für das Funktionieren des Unternehmens von entscheidender Bedeutung sind. Die Dokumente enthalten wertvolle Erkenntnisse, die den Betrieb, die Dienstleistungen und die Wachstumsziele einer Organisation fördern.
Allerdings ist die Klassifizierung von Dokumenten eine mühsame, aber notwendige Aufgabe. Da die Dokumentenklassifizierung eine Herausforderung darstellt, insbesondere wenn das Volumen relativ groß ist, ist ein automatisiertes Dokumentenklassifizierungssystem erforderlich.
Ein KI-basiertes Dokumentenklassifizierungsmodell, das durch maschinelle Lernalgorithmen trainiert wird, ist effizient, kostengünstig, fehlerfrei und genau. Der Prozess kann jedoch erst dann in Gang kommen, wenn das von Ihnen erstellte Modell auf Qualität und genau getaggte Datensätze trainiert wird.
Shaip bringt zu Ihnen vorgetaggte Datensätze die bei der Entwicklung genauer Klassifizierungsmodelle helfen. Nehmen Sie Kontakt mit uns auf und legen Sie gleich mit Ihrem Dokumentenklassifizierungstool los.