
In der Welt der Sprach-KI wird der Unterschied zwischen einem hilfreichen Assistenten und einer unangenehmen Interaktion in Millisekunden gemessen. Während sich textbasierte Retrieval-Augmented Era (RAG)-Systeme einige Sekunden „Denkzeit“ leisten können, müssen Sprachagenten innerhalb von 200 Sekunden reagierenMS Funds, um einen natürlichen Gesprächsfluss aufrechtzuerhalten. Standardmäßige Produktionsvektordatenbankabfragen fügen normalerweise 50–300 hinzuMS der Netzwerklatenz, wodurch effektiv das gesamte Funds verbraucht wird, bevor ein LLM überhaupt mit der Generierung einer Antwort beginnt.
Das Salesforce-KI-Forschungsteam hat veröffentlicht VoiceAgentRAGeine Open-Supply-Architektur mit zwei Agenten, die diesen Abrufengpass umgehen soll, indem das Abrufen von Dokumenten von der Antwortgenerierung entkoppelt wird.
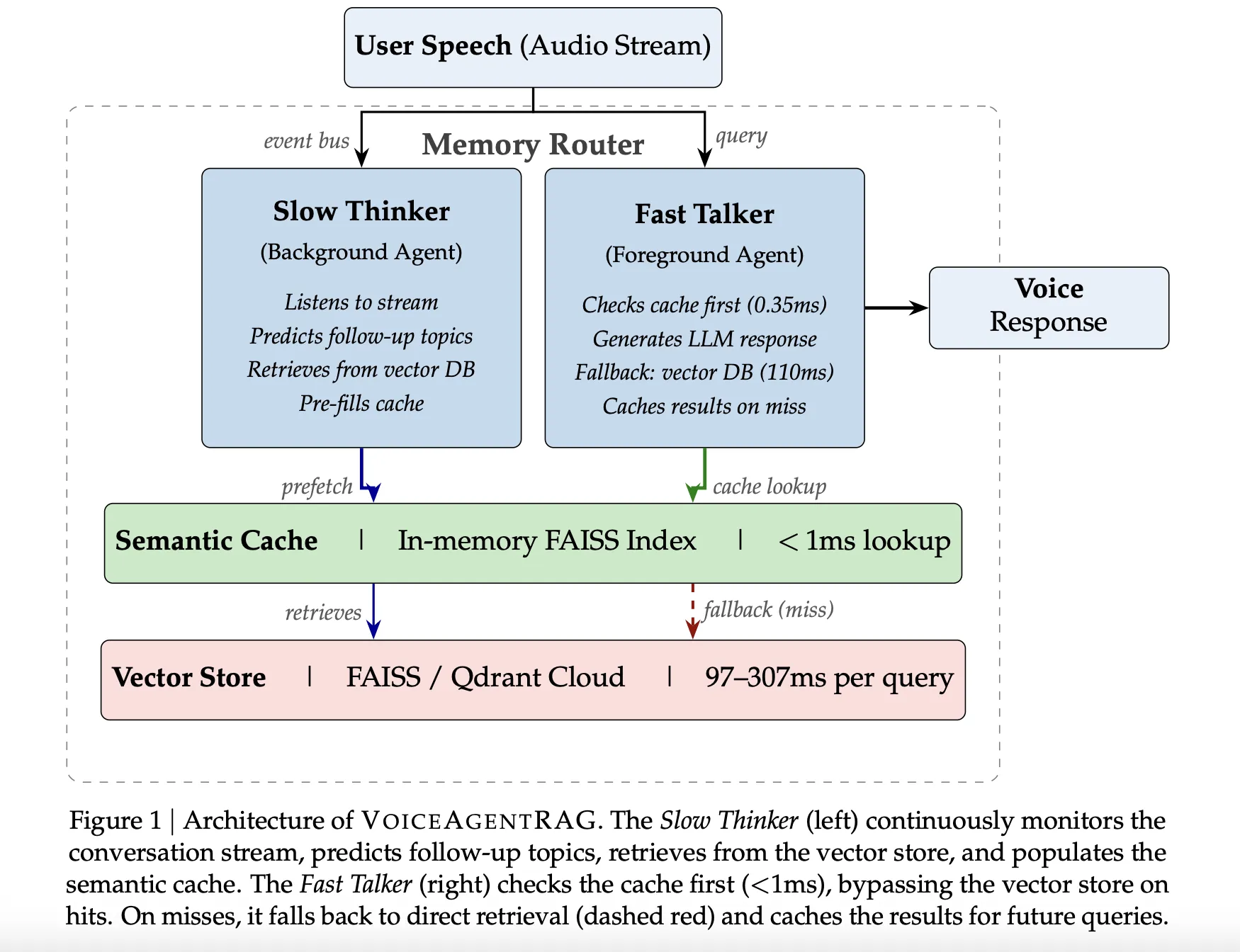
Die Twin-Agent-Architektur: Schneller Redner vs. Langsamer Denker
VoiceAgentRAG fungiert als Speicherrouter, der zwei gleichzeitige Agenten über einen asynchronen Ereignisbus orchestriert:
- Der schnelle Redner (Vordergrundagent): Dieser Agent verwaltet den kritischen Latenzpfad. Bei jeder Benutzerabfrage wird zunächst ein lokaler In-Reminiscence-Speicher überprüft Semantischer Cache. Wenn der erforderliche Kontext vorhanden ist, dauert die Suche etwa 0,35MS. Bei einem Cache-Fehler greift es auf die Distant-Vektordatenbank zurück und speichert die Ergebnisse sofort für zukünftige Runden zwischen.
- Der Langsame Denker (Hintergrundagent): Dieser Agent wird als Hintergrundaufgabe ausgeführt und überwacht kontinuierlich den Gesprächsstrom. Es nutzt ein Schiebefenster des letzten sechs Gesprächsrunden vorhersagen 3–5 wahrscheinliche Folgethemen. Anschließend ruft es relevante Dokumentblöcke aus dem Distant-Vektorspeicher in den lokalen Cache ab, bevor der Benutzer überhaupt seine nächste Frage stellt.
Um die Suchgenauigkeit zu optimieren, wird der Sluggish Thinker angewiesen, zu generieren Beschreibungen im Dokumentstil statt Fragen. Dadurch wird sichergestellt, dass die resultierenden Einbettungen besser mit der tatsächlichen Prosa in der Wissensdatenbank übereinstimmen.
Das technische Rückgrat: Semantisches Caching
Die Effizienz des Methods hängt von einem speziellen semantischen Cache ab, der mit einem In-Reminiscence implementiert wird FAISS IndexFlat IP (inneres Produkt).
- Indizierung zur Einbettung von Dokumenten: Im Gegensatz zu passiven Caches, die nach Abfragebedeutung indizieren, indiziert VoiceAgentRAG Einträge selbst Einbettungen von Dokumenten. Dadurch kann der Cache eine ordnungsgemäße semantische Suche über seinen Inhalt durchführen und so die Relevanz sicherstellen, selbst wenn die Formulierung des Benutzers von den Vorhersagen des Methods abweicht.
- Schwellenwertmanagement: Da die Kosinus-Ähnlichkeit zwischen Abfrage und Dokument systematisch geringer ist als die Ähnlichkeit zwischen Abfrage und Abfrage, verwendet das System einen Standardschwellenwert von um Präzision und Erinnerung in Einklang zu bringen.
- Wartung: Der Cache erkennt Beinahe-Duplikate mithilfe von a 0,95 Kosinus-Ähnlichkeitsschwelle und beschäftigt a Am wenigsten kürzlich genutzt (LRU) Räumungspolitik mit a 300 Sekunden Time-To-Dwell (TTL).
- Prioritätsabruf: Bei einem Quick-Talker-Cache-Fehlschlag, a
PriorityRetrievalDas Ereignis veranlasst den Sluggish Thinker, einen sofortigen Abruf mit einem durchzuführen erweitertes High-Ok (2x die Standardeinstellung) um den Cache um den neuen Themenbereich schnell zu füllen.
Benchmarks und Leistung
Das Forschungsteam bewertete das System anhand von Qdrant Cloud als Distant-Vektordatenbank für 200 Abfragen und 10 Konversationsszenarien.
| Metrisch | Leistung |
| Gesamt-Cache-Trefferrate | 75 % (79 % bei warmen Kurven) |
| Beschleunigung des Abrufs | 316x |
| Gesamte Zeitersparnis beim Abrufen | 16,5 Sekunden über 200 Umdrehungen |
Die Architektur ist in thematisch kohärenten oder thematisch nachhaltigen Szenarien am effektivsten. Zum Beispiel, ‚Funktionsvergleich‘ (S8) erreicht a 95 % Trefferquote. Umgekehrt sank die Leistung in volatileren Szenarien; Das Szenario mit der niedrigsten Leistung struggle „Bestandskunden-Improve“ (S9) bei a 45 % Trefferquotewährend „Gemischtes Schnellfeuer“ (S10) 55 % beibehielt.
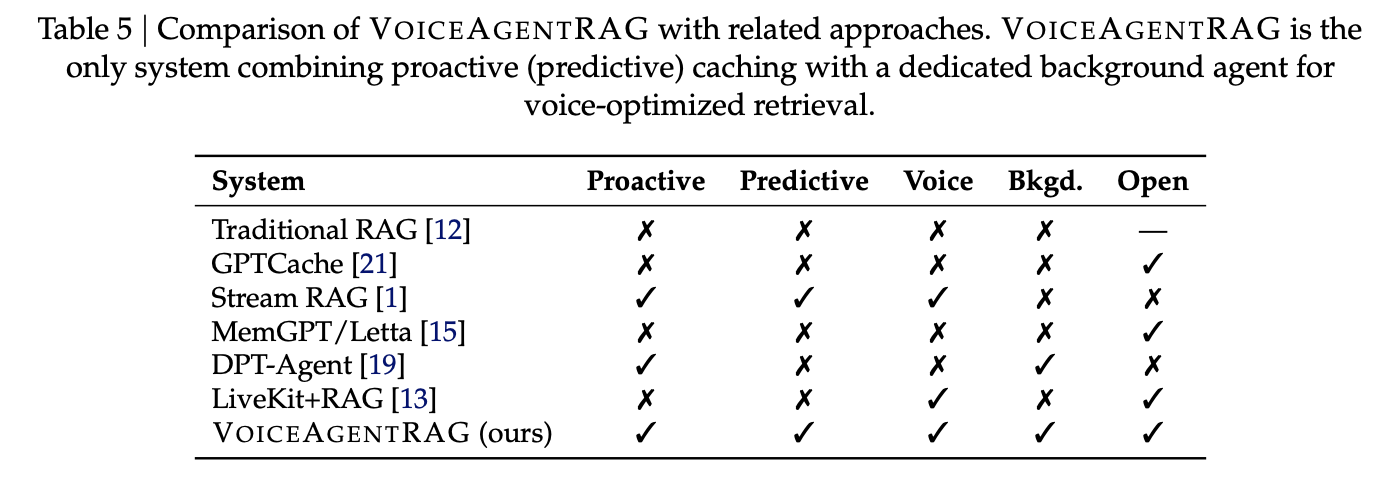
Integration und Help
Das VoiceAgentRAG-Repository ist auf umfassende Kompatibilität mit dem gesamten KI-Stack ausgelegt:
- LLM-Anbieter: Unterstützt OpenAI, Anthropisch, Zwillinge/Vertex-KIUnd Ollama. Das Standardbewertungsmodell des Papiers struggle GPT-4o-mini.
- Einbettungen: Die Forschung genutzt OpenAI text-embedding-3-small (1536 Dimensionen), aber das Repository bietet Unterstützung für beide OpenAI Und Ollama Einbettungen.
- STT/TTS: Unterstützt Flüstern (lokal oder OpenAI) für Speech-to-Textual content und Edge-TTS oder OpenAI für Textual content-to-Speech.
- Vector Shops: Integrierte Unterstützung für FAISS Und Qdrant.
Wichtige Erkenntnisse
- Twin-Agent-Architektur: Das System löst den RAG-Latenzengpass, indem es einen „Quick Talker“ im Vordergrund für Cache-Suchen unter einer Millisekunde und einen „Sluggish Thinker“ im Hintergrund für vorausschauendes Vorabholen verwendet.
- Deutliche Beschleunigung: Es wird eine 316-fache Abrufgeschwindigkeit erreicht bei Cache-Treffern, was entscheidend ist, um innerhalb des natürlichen Sprachantwortbudgets von 200 ms zu bleiben.
- Hohe Cache-Effizienz: Über verschiedene Szenarien hinweg behält das System eine Gesamt-Cache-Trefferquote von 75 % bei und erreicht bei thematisch zusammenhängenden Gesprächen wie Funktionsvergleichen einen Spitzenwert von 95 %.
- Dokumentindiziertes Caching: Um die Genauigkeit unabhängig von der Benutzerformulierung sicherzustellen, indiziert der semantische Cache Einträge nach Dokumenteinbettungen und nicht nach der Einbettung der vorhergesagten Abfrage.
- Vorausschauendes Vorabrufen: Der Hintergrundagent verwendet ein Schiebefenster der letzten sechs Gesprächsrunden, um wahrscheinliche Folgethemen vorherzusagen und den Cache während natürlicher Pausen zwischen den Gesprächsrunden zu füllen.
Schauen Sie sich das an Papier Und Repo hier. Sie können uns auch gerne weiter folgen Twitter und vergessen Sie nicht, bei uns mitzumachen 120.000+ ML SubReddit und Abonnieren Unser Publication. Warten! Bist du im Telegram? Jetzt können Sie uns auch per Telegram kontaktieren.