In diesem Artikel erfahren Sie, wie Temperatur- und Seed-Werte die Fehlermodi in Agentenschleifen beeinflussen und wie Sie sie für eine höhere Ausfallsicherheit optimieren können.
Zu den Themen, die wir behandeln werden, gehören:
- Wie niedrige und hohe Temperatureinstellungen unterschiedliche Fehlermuster in Agentenschleifen erzeugen können.
- Warum feste Startwerte die Robustheit in Produktionsumgebungen beeinträchtigen können.
- So nutzen Sie Temperatur- und Seed-Anpassungen, um belastbarere und kostengünstigere Agenten-Workflows aufzubauen.
Verschwenden wir keine Zeit mehr.
Warum Agenten versagen: Die Rolle von Startwerten und Temperatur in Agentenschleifen
Bild vom Herausgeber
Einführung
In der modernen KI-Landschaft ist ein Agentenschleife ist ein zyklischer, wiederholbarer und kontinuierlicher Prozess, bei dem eine Entität namens an KI-Agent arbeitet – mit einem gewissen Maß an Autonomie – auf ein Ziel hin.
In der Praxis umschließen Agentenschleifen jetzt a großes Sprachmodell (LLM) in ihnen, sodass sie, anstatt nur auf Eingabeaufforderungsinteraktionen einzelner Benutzer zu reagieren, eine Variation davon implementieren Beobachten-Vernunft-Handeln Zyklus, der vor Jahrzehnten für klassische Software program-Agenten definiert wurde.
Agenten sind natürlich nicht unfehlbar und können manchmal scheitern, in manchen Fällen aufgrund schlechter Aufforderungen oder mangelndem Zugriff auf die externen Instruments, die sie zum Erreichen eines Ziels benötigen. Allerdings können auch zwei unsichtbare Steuerungsmechanismen Einfluss auf das Scheitern haben: Temperatur Und Samenwert. Dieser Artikel analysiert beides aus der Perspektive des Fehlers in Agentenschleifen.
Lassen Sie uns im Rahmen einer sanften Diskussion, die auf aktuellen Forschungs- und Produktionsdiagnosen basiert, einen genaueren Blick darauf werfen, wie sich diese Einstellungen auf Fehler in Agentenschleifen auswirken können.
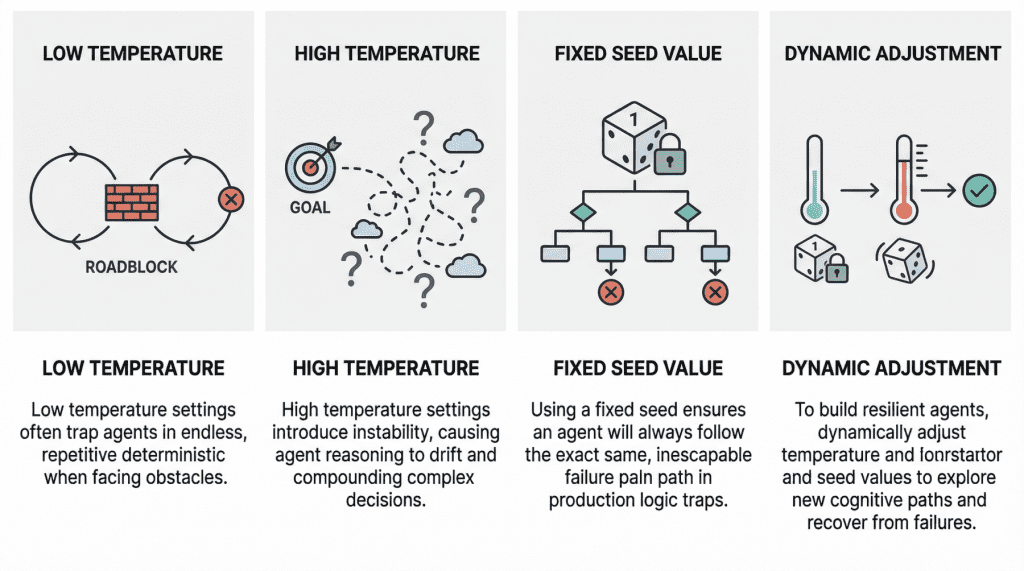
Temperatur: „Reasoning Drift“ Vs. „Deterministische Schleife“
Die Temperatur ist ein inhärenter Parameter von LLMs und steuert die Zufälligkeit ihres internen Verhaltens bei der Auswahl der Wörter oder Token, aus denen die Antwort des Modells besteht. Je höher sein Wert (näher an 1, unter der Annahme eines Bereichs zwischen 0 und 1), desto weniger deterministisch und unvorhersehbarer werden die Ausgaben des Modells und umgekehrt.
Da LLMs im Kern von Agentenschleifen sitzen, ist das Verständnis der Temperatur von entscheidender Bedeutung für das Verständnis einzigartiger, intestine dokumentierter Fehlermodi, die auftreten können, insbesondere wenn die Temperatur extrem niedrig oder hoch ist.
A niedrige Temperatur (nahe 0) Agent ergibt oft das sogenannte Deterministischer Schleifenfehler. Mit anderen Worten: Das Verhalten des Agenten wird zu starr. Angenommen, der Agent stößt auf seinem Weg auf eine „Störung“, beispielsweise darauf, dass eine Drittanbieter-API ständig einen Fehler zurückgibt. Aufgrund der niedrigen Temperatur und des äußerst deterministischen Verhaltens mangelt es ihm an der Artwork von kognitiver Zufälligkeit oder Erkundung, die für eine Wende erforderlich ist. Aktuelle Studien haben dieses Phänomen wissenschaftlich analysiert. Die typischerweise beobachteten praktischen Konsequenzen reichen von Agenten, die Missionen vorzeitig abschließen, bis hin zu mangelnder Koordinierung, wenn ihre ursprünglichen Pläne auf Reibung stoßen, was zu einer Schleife immer wieder derselben Versuche ohne Fortschritt führt.
Am anderen Ende des Spektrums haben wir Hochtemperatur (0,8 oder höher) Agentenschleifen. Wie bei eigenständigen LLMs eröffnen hohe Temperaturen ein viel breiteres Spektrum an Möglichkeiten bei der Abtastung jedes Components der Reaktion. In einer mehrstufigen Schleife kann sich dieses höchst wahrscheinliche Verhalten jedoch auf gefährliche Weise verschärfen und zu einem Merkmal werden, das als bekannt ist Argumentationsdrift. Im Wesentlichen läuft dieses Verhalten auf eine Instabilität bei der Entscheidungsfindung hinaus. Die Einführung von Hochtemperatur-Zufälligkeiten in komplexe Arbeitsabläufe von Agenten kann dazu führen, dass agentenbasierte Modelle ihre Orientierung verlieren – das heißt, dass sie ihre ursprünglichen Auswahlkriterien für die Entscheidungsfindung verlieren. Dazu können Symptome wie Halluzinationen (künstliche Denkketten) oder sogar das Vergessen des ursprünglichen Ziels des Benutzers gehören.
Saatgutwert: Reproduzierbarkeit
Startwerte sind die Mechanismen, die den Pseudozufallsgenerator initialisieren, der zum Erstellen der Modellausgaben verwendet wird. Einfacher ausgedrückt ist der Startwert wie die Startposition eines Würfels, der geworfen wird, um den Wortauswahlmechanismus des Modells anzustoßen, der die Antwortgenerierung steuert.
Bei dieser Einstellung besteht das Hauptproblem, das normalerweise zu Fehlern in Agentenschleifen führt, darin, dass in der Produktion ein fester Startwert verwendet wird. Ein fester Startwert ist in einer Testumgebung zum Beispiel aus Gründen der Reproduzierbarkeit in Checks und Experimenten sinnvoll, wenn man ihn jedoch in die Produktion gelangen lässt, entsteht eine erhebliche Schwachstelle. Ein Agent kann versehentlich in eine Logikfalle geraten, wenn er mit einem festen Startwert arbeitet. In einer solchen Scenario löst das System möglicherweise automatisch einen Wiederherstellungsversuch aus, aber selbst dann ist der feste Startwert quick gleichbedeutend mit der Garantie, dass der Agent immer wieder denselben, zum Scheitern verurteilten Denkweg einschlägt.
Stellen Sie sich in der Praxis einen Agenten vor, der die Aufgabe hat, eine fehlgeschlagene Bereitstellung zu debuggen, indem er Protokolle überprüft, eine Lösung vorschlägt und den Vorgang dann erneut versucht. Wenn die Schleife mit einem festen Startwert ausgeführt wird, bleiben die stochastischen Entscheidungen, die das Modell während jedes Argumentationsschritts trifft, bei jedem Auslösen einer Wiederherstellung möglicherweise effektiv in demselben Muster „eingesperrt“. Infolgedessen wählt der Agent möglicherweise trotz wiederholter Wiederholungsversuche immer wieder dieselbe fehlerhafte Interpretation der Protokolle aus, ruft dasselbe Device in derselben Reihenfolge auf oder generiert denselben ineffektiven Repair. Was auf der Systemebene wie Beharrlichkeit aussieht, ist in Wirklichkeit eine Wiederholung auf der kognitiven Ebene. Aus diesem Grund behandeln resiliente Agent-Architekturen den Seed oft als kontrollierbaren Wiederherstellungshebel: Wenn das System erkennt, dass der Agent feststeckt, kann eine Änderung des Seeds dazu beitragen, die Erforschung einer anderen Argumentationsbahn zu erzwingen, wodurch die Wahrscheinlichkeit erhöht wird, einem lokalen Fehlermodus zu entkommen, anstatt ihn auf unbestimmte Zeit zu reproduzieren.
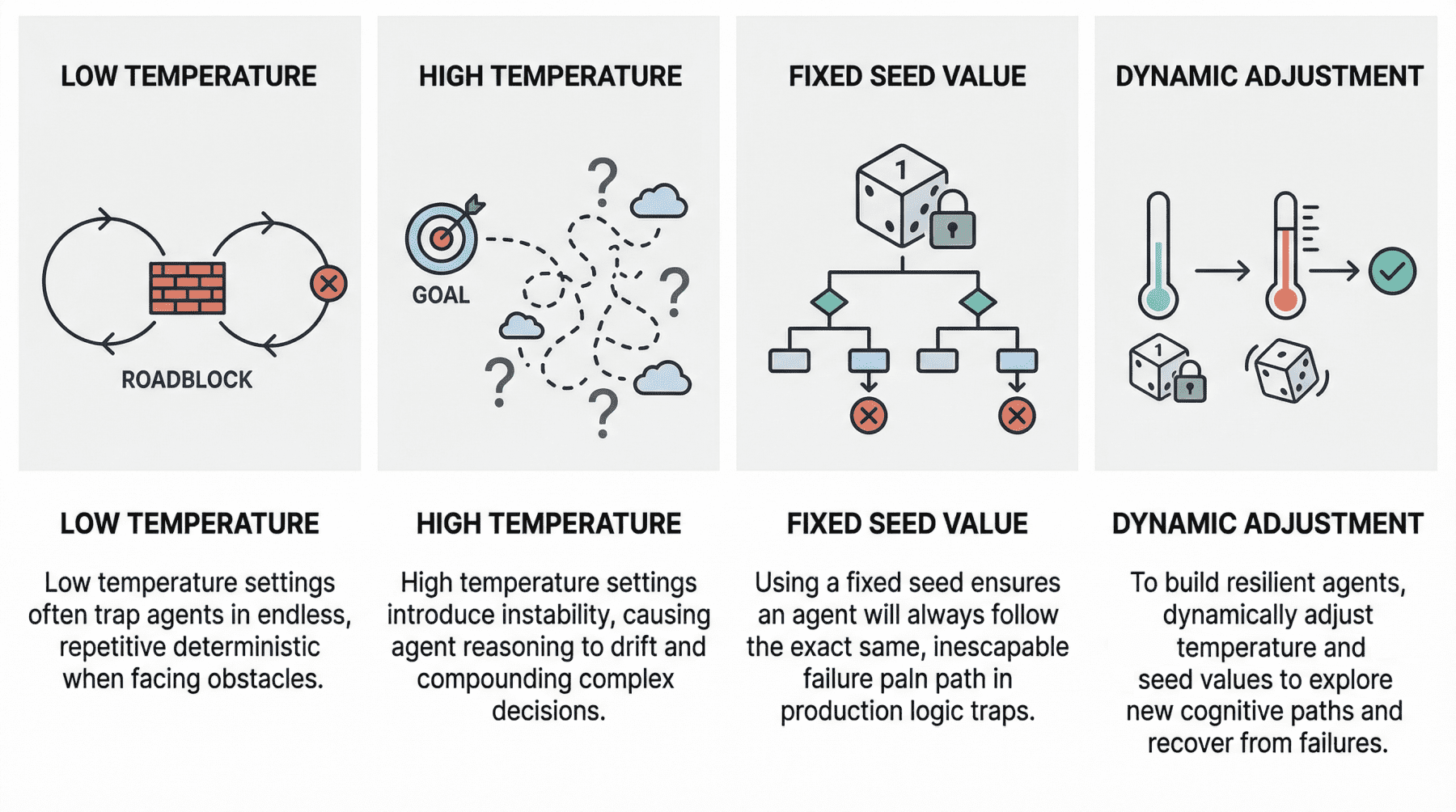
Eine Zusammenfassung der Rolle von Startwerten und Temperatur in Agentenschleifen
Bild vom Herausgeber
Greatest Practices für belastbare und kosteneffiziente Schleifen
Nachdem man die Auswirkungen von Temperatur und Seed-Wert auf Agentenschleifen kennengelernt hat, fragt man sich vielleicht, wie man diese Schleifen widerstandsfähiger gegen Ausfälle machen kann, indem man diese beiden Parameter sorgfältig einstellt.
Grundsätzlich erfordert der Ausbruch aus Fehlern in Agentenschleifen oft die Änderung des Startwerts oder der Temperatur als Teil der Wiederholungsversuche, um einen anderen kognitiven Weg zu finden. Resiliente Agenten implementieren in der Regel Ansätze, die diese Parameter in Grenzfällen dynamisch anpassen, beispielsweise durch vorübergehendes Erhöhen der Temperatur oder Randomisieren des Seeds, wenn eine Analyse des Zustands des Agenten darauf hindeutet, dass er feststeckt. Die schlechte Nachricht ist, dass das Testen bei Verwendung kommerzieller APIs sehr teuer werden kann, weshalb Open-Weight-Modelle, lokale Modelle und lokale Modellläufer wie z Ollama werden in diesen Szenarien kritisch.
Durch die Implementierung einer flexiblen Agentenschleife mit anpassbaren Einstellungen ist es möglich, viele Schleifen zu simulieren und Stresstests über verschiedene Temperatur- und Saatgutkombinationen hinweg durchzuführen. Wenn dies mit kostenlosen Instruments durchgeführt wird, ist dies ein praktischer Weg, um die Grundursachen für Argumentationsfehler vor der Bereitstellung zu ermitteln.