
Die Videobearbeitung hatte schon immer ein schmutziges Geheimnis: Das Entfernen eines Objekts aus Filmmaterial ist einfach; Es ist brutal schwierig, die Szene so aussehen zu lassen, als wäre sie nie dagewesen. Wenn man eine Individual ausschaltet, die eine Gitarre hält, bleibt ein schwebendes Instrument zurück, das der Schwerkraft trotzt. Hollywoods VFX-Groups verbringen Wochen damit, genau diese Artwork von Drawback zu beheben. Ein Forscherteam von Netflix und INSAIT der Universität Sofia „St. Kliment Ohridski“ veröffentlicht LEERE (Löschen von Videoobjekten und Interaktionen) Modell, das dies automatisch tun kann.
VOID entfernt Objekte aus Movies zusammen mit allen Interaktionen, die sie in der Szene hervorrufen – nicht nur Sekundäreffekte wie Schatten und Reflexionen, sondern auch physische Interaktionen wie herunterfallende Objekte, wenn eine Individual entfernt wird.
Welches Drawback löst VOID tatsächlich?
Standardmäßige Video-Inpainting-Modelle – wie sie heute in den meisten Bearbeitungsworkflows verwendet werden – werden darauf trainiert, den Pixelbereich auszufüllen, in dem sich ein Objekt befand. Sie sind im Wesentlichen sehr anspruchsvolle Hintergrundmaler. Was sie nicht tun, ist Vernunft Kausalität: Was soll mit dieser Requisite passieren, wenn ich einen Schauspieler entferne, der eine Requisite hält?
Bestehende Methoden zum Entfernen von Videoobjekten zeichnen sich hervorragend durch das Einmalen von Inhalten „hinter“ dem Objekt und das Korrigieren von Artefakten auf Erscheinungsebene wie Schatten und Reflexionen aus. Wenn das entfernte Objekt jedoch schwerwiegendere Wechselwirkungen aufweist, beispielsweise Kollisionen mit anderen Objekten, können aktuelle Modelle diese nicht korrigieren und liefern unplausible Ergebnisse.
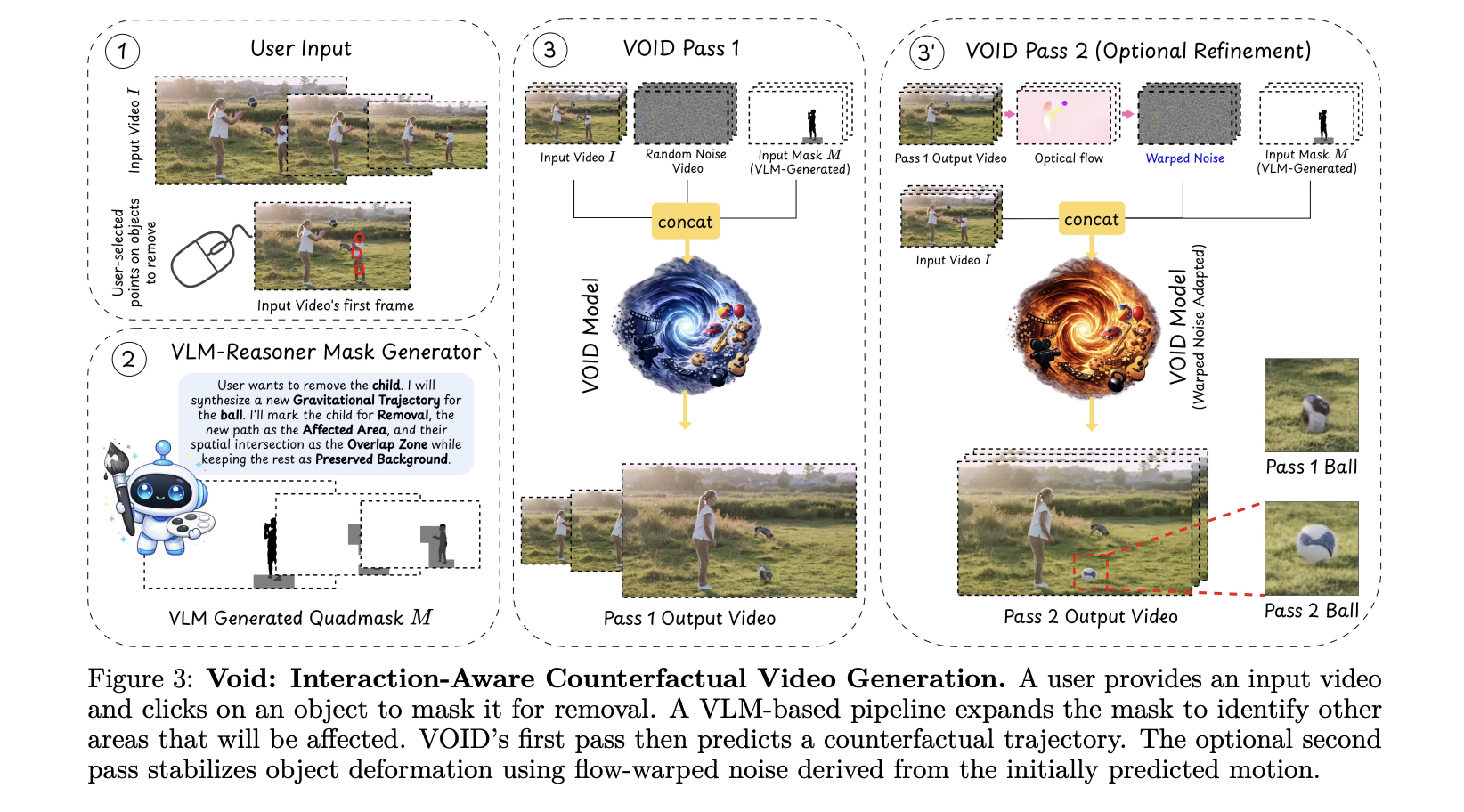
VOID basiert auf CogVideoX und ist für Video-Inpainting mit interaktionsbewusster Maskenkonditionierung optimiert. Die wichtigste Neuerung liegt darin, wie das Modell die Szene versteht – nicht nur in der Frage: „Welche Pixel soll ich füllen?“ aber „was ist physikalisch plausibel, nachdem dieses Objekt verschwunden ist?“
Das kanonische Beispiel aus der Forschungsarbeit: Wenn eine Individual, die eine Gitarre hält, entfernt wird, entfernt VOID auch den Effekt der Individual auf die Gitarre – wodurch sie auf natürliche Weise herunterfällt. Das ist nicht trivial. Das Modell muss verstehen, dass die Gitarre da battle unterstützt durch die Individual, und dass das Entfernen der Individual bedeutet, dass die Schwerkraft übernimmt.
Und im Gegensatz zu früheren Arbeiten wurde VOID im direkten Vergleich mit echten Konkurrenten bewertet. Experimente mit synthetischen und realen Daten zeigen, dass der Ansatz die konsistente Szenendynamik nach der Objektentfernung besser beibehält als frühere Methoden zur Videoobjektentfernung, einschließlich ProPainter, DiffuEraser, Runway, MiniMax-Remover, ROSE und Gen-Omnimatte.
Die Architektur: CogVideoX unter der Haube
VOID ist aufgebaut CogVideoX-Enjoyable-V1.5-5b-InP – ein Modell von Alibaba PAI – und für Video-Inpainting mit Interaktionserkennung optimiert Quadmask Konditionierung. CogVideoX ist ein auf 3D-Transformatoren basierendes Videogenerierungsmodell. Stellen Sie es sich wie eine Videoversion von Steady Diffusion vor – einem Diffusionsmodell, das über zeitliche Bildsequenzen und nicht über einzelne Bilder arbeitet. Das spezifische Basismodell (CogVideoX-Enjoyable-V1.5-5b-InP) wird von Alibaba PAI auf Hugging Face veröffentlicht. Dabei handelt es sich um den Checkpoint-Ingenieur, den er separat herunterladen muss, bevor er VOID ausführen kann.
Die fein abgestimmten Architekturspezifikationen: ein CogVideoX 3D Transformer mit 5B-Parametern, der Video, Quadmask und eine Textaufforderung aufnimmt, die die Szene nach dem Entfernen als Eingabe beschreibt, mit einer Standardauflösung von 384×672 arbeitet, maximal 197 Frames verarbeitet, den DDIM-Scheduler verwendet und in BF16 mit FP8-Quantisierung für Speichereffizienz läuft.
Der Quadmask ist wohl der interessanteste technische Beitrag hier. Anstelle einer binären Maske (dieses Pixel entfernen/dieses Pixel behalten) ist die Quadmaske eine 4-Werte-Maske, die das zu entfernende primäre Objekt, überlappende Regionen, betroffene Regionen (fallende Objekte, verschobene Elemente) und den beizubehaltenden Hintergrund codiert.
In der Praxis erhält jedes Pixel in der Maske einen von vier Werten: 0 (Primärobjekt wird entfernt), 63 (Überschneidung zwischen primären und betroffenen Regionen), 127 (von der Interaktion betroffene Area – Dinge, die sich infolge der Entfernung bewegen oder verändern) und 255 (Hintergrund, unverändert lassen). Dadurch erhält das Modell eine strukturierte semantische Karte von was in der Szene passiertnicht nur wo sich das Objekt befindet.
Inferenzpipeline mit zwei Durchgängen
VOID verwendet zwei Transformatorprüfpunkte, die nacheinander trainiert werden. Sie können die Inferenz nur mit Durchgang 1 ausführen oder beide Durchgänge verketten, um eine höhere zeitliche Konsistenz zu erzielen.
Durchgang 1 (void_pass1.safetensors) ist das Foundation-Inpainting-Modell und reicht für die meisten Movies aus. Durchgang 2 dient einem bestimmten Zweck: der Korrektur eines bekannten Fehlermodus. Wenn das Modell Objektmorphing erkennt – ein bekannter Fehlermodus kleinerer Videodiffusionsmodelle – führt ein optionaler zweiter Durchgang die Inferenz unter Verwendung von flussverzerrtem Rauschen aus dem ersten Durchgang erneut aus und stabilisiert so die Objektform entlang der neu synthetisierten Trajektorien.
Es lohnt sich, den Unterschied zu verstehen: Move 2 ist nicht nur für längere Clips gedacht – es ist speziell ein Formstabilitätsfix. Wenn das Diffusionsmodell Objekte erzeugt, die sich über Frames hinweg allmählich verziehen oder verformen (ein intestine dokumentiertes Artefakt bei der Videodiffusion), verwendet Move 2 den optischen Fluss, um die Latentdaten aus Move 1 zu verzerren und sie als Initialisierung in einen zweiten Diffusionsdurchlauf einzuspeisen, wodurch die Type der synthetisierten Objekte von Body zu Body verankert wird.
Wie die Trainingsdaten generiert wurden
Hier wird es erst richtig interessant. Um einem Modell das Verständnis physikalischer Wechselwirkungen beizubringen, sind gepaarte Movies erforderlich – dieselbe Szene, mit und ohne Objekt, wobei die Physik in beiden korrekt abläuft. Es gibt keine realen gepaarten Daten in diesem Maßstab. Additionally baute das Staff es synthetisch auf.
Beim Coaching wurden gepaarte kontrafaktische Movies verwendet, die aus zwei Quellen generiert wurden: HUMOTO – Mensch-Objekt-Interaktionen, gerendert in Blender mit Physiksimulation – und Kubric – reine Objektinteraktionen mithilfe von Google Scanned Objects.
HUMOTO nutzt Movement-Seize-Daten von Mensch-Objekt-Interaktionen. Der Schlüsselmechanismus ist eine Blender-Neusimulation: Die Szene wird mit einem Menschen und Objekten aufgebaut, einmal mit dem anwesenden Menschen gerendert, dann wird der Mensch aus der Simulation entfernt und die Physik wird von diesem Punkt an erneut ausgeführt. Das Ergebnis ist ein physikalisch korrektes kontrafaktisches Ergebnis: Objekte, die gehalten oder gestützt wurden, fallen jetzt genau so, wie sie sollten. Kubric, entwickelt von Google Analysis, wendet dieselbe Idee auf Objekt-Objekt-Kollisionen an. Zusammen erzeugen sie einen Datensatz gepaarter Movies, bei denen die Physik nachweislich korrekt ist und nicht von einem menschlichen Annotator angenähert wird.
Wichtige Erkenntnisse
- VOID geht über das Füllen von Pixeln hinaus. Im Gegensatz zu bestehenden Video-Inpainting-Instruments, die nur visuelle Artefakte wie Schatten und Reflexionen korrigieren, versteht VOID die physikalische Kausalität – wenn Sie eine Individual entfernen, die ein Objekt hält, fällt das Objekt auf natürliche Weise in das Ausgabevideo.
- Die Quadmask ist die Kerninnovation. Anstelle einer einfachen binären Entfernungs-/Beibehaltungsmaske verwendet VOID eine 4-Werte-Quadmaske (Werte 0, 63, 127, 255), die nicht nur kodiert, was entfernt werden soll, sondern auch, welche umgebenden Bereiche der Szene es sein werden körperlich betroffen – Geben Sie dem Diffusionsmodell ein strukturiertes Szenenverständnis, mit dem es arbeiten kann.
- Zwei-Durchlauf-Inferenz löst einen echten Fehlermodus. Move 1 verarbeitet die meisten Movies; Durchlauf 2 dient speziell dazu, Objektmorphing-Artefakte zu beheben – eine bekannte Schwäche von Videodiffusionsmodellen –, indem optisch flussverzerrte Latentdaten aus Durchlauf 1 als Initialisierung für einen zweiten Diffusionslauf verwendet werden.
- Synthetische gepaarte Daten ermöglichten das Coaching. Da gepaarte kontrafaktische Videodaten aus der realen Welt nicht in großem Maßstab vorhanden sind, hat das Forschungsteam sie mithilfe der Blender-Physik-Resimulation (HUMOTO) und des Kubric-Frameworks von Google erstellt und so grundgetreue Vorher-/Nachher-Videopaare generiert, bei denen die Physik nachweislich korrekt ist.
Schauen Sie sich das an Papier, Modellgewicht Und Repo. Sie können uns auch gerne weiter folgen Twitter und vergessen Sie nicht, bei uns mitzumachen 120.000+ ML SubReddit und Abonnieren Unser Publication. Warten! Bist du im Telegram? Jetzt können Sie uns auch per Telegram kontaktieren.

Michal Sutter ist ein Information-Science-Experte mit einem Grasp of Science in Information Science von der Universität Padua. Mit einer soliden Grundlage in statistischer Analyse, maschinellem Lernen und Datentechnik ist Michal hervorragend darin, komplexe Datensätze in umsetzbare Erkenntnisse umzuwandeln.