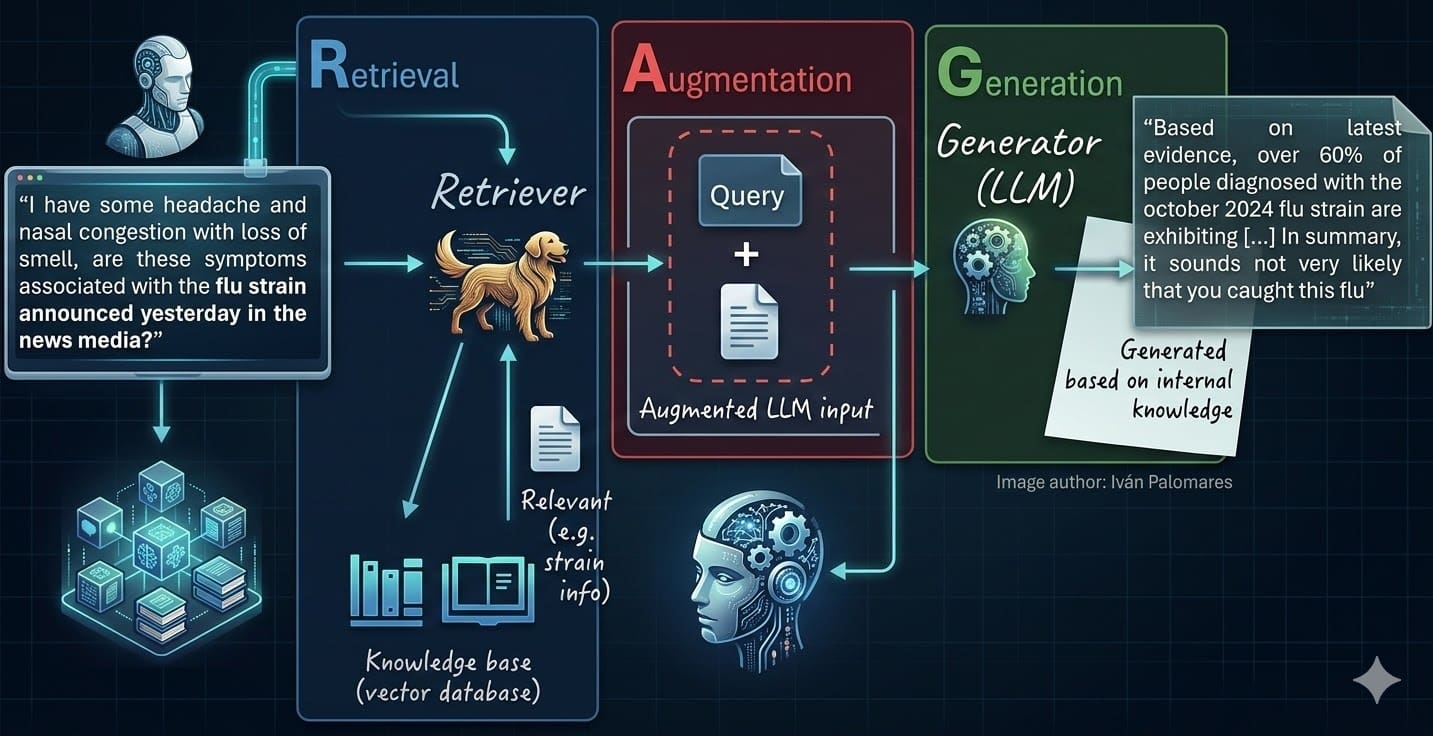
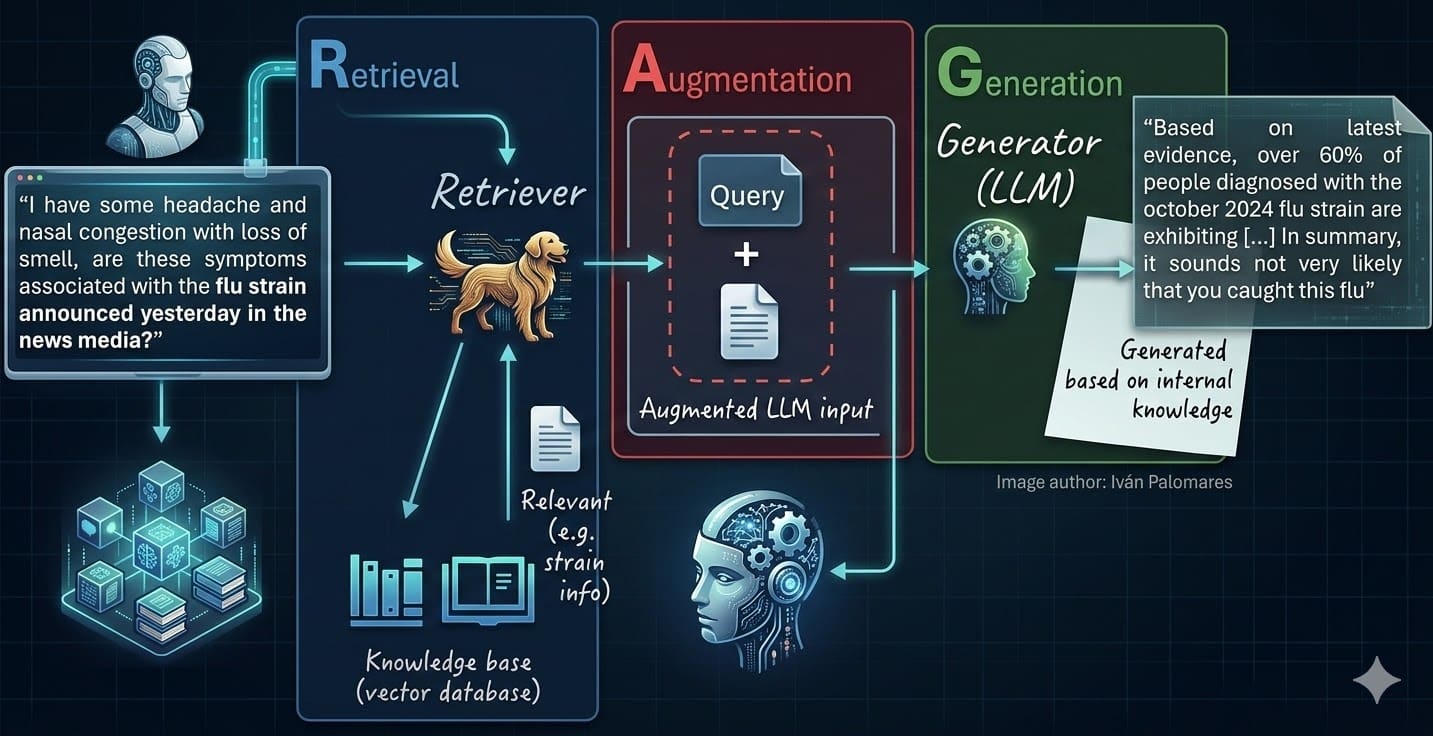
Bild vom Autor
# Einführung
Vereinfacht gesagt sind Retrieval-Augmented Technology (RAG)-Systeme die natürliche Weiterentwicklung eigenständiger großer Sprachmodelle (LLMs). RAG behebt mehrere wichtige Einschränkungen klassischer LLMs, wie z Modellhalluzinationen oder ein Mangel an aktuellem, relevantem Wissen, das erforderlich ist, um fundierte, faktenbasierte Antworten auf Benutzeranfragen zu generieren.
In einer verwandten Artikelserie RAG verstehenWir haben einen umfassenden Überblick über RAG-Systeme, ihre Eigenschaften, praktischen Überlegungen und Herausforderungen gegeben. Jetzt fassen wir einen Teil dieser Lektionen zusammen und kombinieren sie mit den neuesten Developments und Techniken, um sieben Schlüsselschritte zu beschreiben, die für die Beherrschung der Entwicklung von RAG-Systemen als wesentlich erachtet werden.
Diese sieben Schritte beziehen sich auf verschiedene Phasen oder Komponenten einer RAG-Umgebung, wie in den numerischen Beschriftungen ((1) bis (7)) im Diagramm unten dargestellt, das eine klassische RAG-Architektur veranschaulicht:
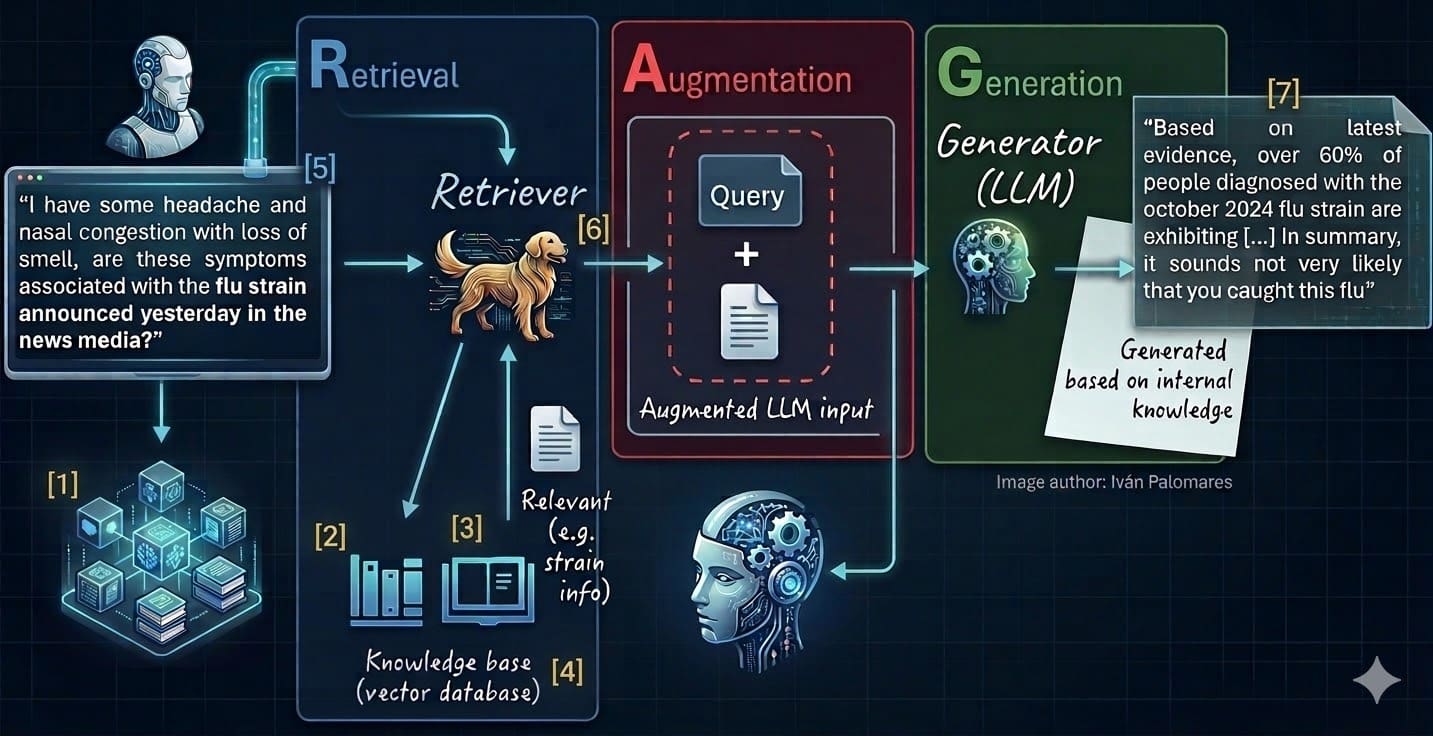
7 Schritte zur Beherrschung von RAG-Systemen (siehe nummerierte Etiketten 1–7 und Liste unten)
- Datenquellen auswählen und bereinigen
- Chunking und Splitting
- Einbettung/Vektorisierung
- Füllen Sie Vektordatenbanken
- Abfragevektorisierung
- Relevanten Kontext abrufen
- Generieren Sie eine fundierte Antwort
# 1. Datenquellen auswählen und bereinigen
Das „Rubbish in, Rubbish out“-Prinzip kommt bei RAG voll zur Geltung. Sein Wert ist direkt proportional zur Relevanz, Qualität und Sauberkeit der Quelltextdaten, die er abrufen kann. Um hochwertige Wissensdatenbanken sicherzustellen, identifizieren Sie hochwertige Datensilos und überprüfen Sie Ihre Datenbanken regelmäßig. Führen Sie vor der Aufnahme von Rohdaten einen effektiven Reinigungsprozess durch robuste Pipelines durch, die wichtige Schritte wie das Entfernen persönlich identifizierbarer Informationen (PII), das Entfernen von Duplikaten und das Beheben anderer störender Elemente durchführen. Dabei handelt es sich um einen kontinuierlichen Engineering-Prozess, der jedes Mal angewendet wird, wenn neue Daten aufgenommen werden.
Sie können es durchlesen dieser Artikel um einen Überblick über Datenbereinigungstechniken zu erhalten.
# 2. Dokumente aufteilen und aufteilen
Viele Instanzen von Textdaten oder Dokumenten, wie Literaturromane oder Doktorarbeiten, sind zu groß, um als einzelne Dateninstanz oder -einheit eingebettet zu werden. Chunking besteht darin, lange Texte in kleinere Teile aufzuteilen, die ihre semantische Bedeutung und die kontextuelle Integrität bewahren. Es erfordert einen sorgfältigen Ansatz: nicht zu viele Blöcke (was möglicherweise zu Kontextverlust führt), aber auch nicht zu wenige – übergroße Blöcke wirken sich später auf die semantische Suche aus!
Es gibt verschiedene Chunking-Ansätze: von solchen, die auf der Zeichenanzahl basieren, bis hin zu solchen, die auf logischen Grenzen wie Absätzen oder Abschnitten basieren. LamaIndex Und LangChainmit ihren zugehörigen Python-Bibliotheken, können bei dieser Aufgabe sicherlich helfen, indem sie fortgeschrittenere Aufteilungsmechanismen implementieren.
Beim Chunking können auch Überlappungen zwischen Teilen des Dokuments berücksichtigt werden, um die Konsistenz im Abrufprozess zu gewährleisten. Zur Veranschaulichung: So könnte eine solche Unterteilung bei einem kleinen Textual content in Spielzeuggröße aussehen:
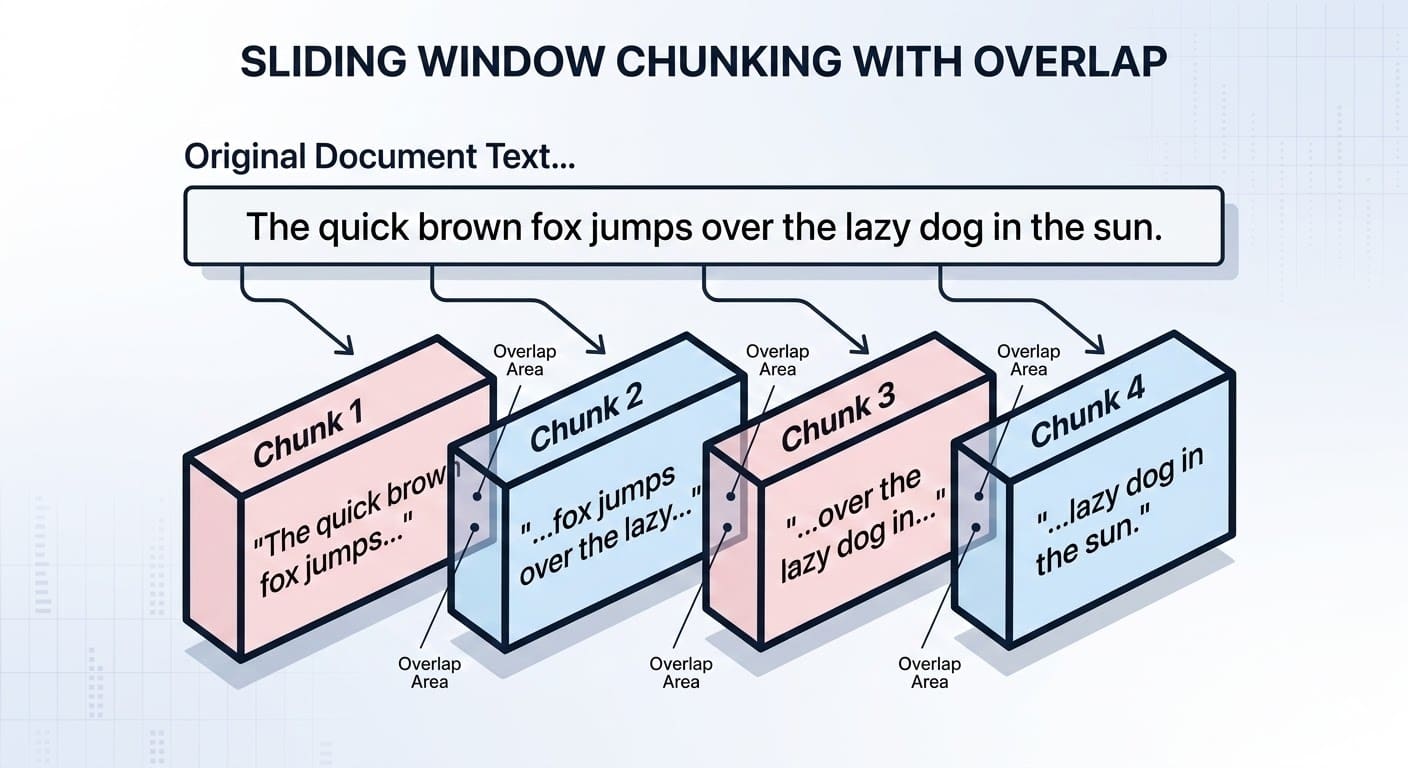
Chunking von Dokumenten in RAG-Systemen mit Überlappung | Bild vom Autor
In diese Folge In der RAG-Reihe erfahren Sie auch, welche zusätzliche Rolle Dokument-Chunking-Prozesse bei der Verwaltung der Kontextgröße von RAG-Eingaben spielen.
# 3. Einbetten und Vektorisieren von Dokumenten
Sobald die Dokumente in Blöcke aufgeteilt sind, besteht der nächste Schritt vor ihrer sicheren Speicherung in der Wissensdatenbank darin, sie in die „Sprache der Maschinen“ zu übersetzen: Zahlen. Dies geschieht typischerweise durch die Konvertierung jedes Textes in eine Vektoreinbettung – eine dichte, hochdimensionale numerische Darstellung, die semantische Eigenschaften des Textes erfasst. In den letzten Jahren wurden für diese Aufgabe spezielle LLMs entwickelt: Sie werden Einbettungsmodelle genannt und umfassen bekannte Open-Supply-Optionen wie Umarmende Gesichter all-MiniLM-L6-v2.
Erfahren Sie mehr über Einbettungen und ihre Vorteile gegenüber klassischen Textdarstellungsansätzen in dieser Artikel.
# 4. Befüllen der Vektordatenbank
Im Gegensatz zu herkömmlichen relationalen Datenbanken sind Vektordatenbanken so konzipiert, dass sie den Suchprozess durch hochdimensionale Arrays (Einbettungen) effektiv ermöglichen, die Textdokumente darstellen – eine kritische Section von RAG-Systemen zum Abrufen relevanter Dokumente für die Anfrage des Benutzers. Beide Open-Supply-Vektorshops mögen FAISS oder Freemium-Alternativen wie Tannenzapfen existieren und können hervorragende Lösungen bieten und so die Lücke zwischen menschenlesbarem Textual content und mathematisch ähnlichen Vektordarstellungen schließen.
Dieser Codeauszug wird verwendet, um Textual content zu teilen (siehe Punkt 2 zuvor) und eine lokale, freie Vektordatenbank mithilfe von LangChain und zu füllen Chroma – vorausgesetzt, wir müssen ein langes Dokument in einer Datei mit dem Namen speichern knowledge_base.txt:
from langchain_community.document_loaders import TextLoader
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_community.embeddings import HuggingFaceEmbeddings
from langchain_community.vectorstores import Chroma
# Load and chunk the information
docs = TextLoader("knowledge_base.txt").load()
chunks = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=50).split_documents(docs)
# Create textual content embeddings utilizing a free open-source mannequin and retailer in ChromaDB
embedding_model = HuggingFaceEmbeddings(model_name="all-MiniLM-L6-v2")
vector_db = Chroma.from_documents(paperwork=chunks, embedding=embedding_model, persist_directory="./db")
print(f"Efficiently saved {len(chunks)} embedded chunks.")Lesen Sie mehr über Vektordatenbanken Hier.
# 5. Vektorisieren von Abfragen
In natürlicher Sprache ausgedrückte Benutzeraufforderungen werden nicht direkt mit gespeicherten Dokumentvektoren abgeglichen: Sie müssen ebenfalls übersetzt werden, wobei der gleiche Einbettungsmechanismus oder das gleiche Modell verwendet wird (siehe Schritt 3). Mit anderen Worten: Es wird ein einzelner Abfragevektor erstellt und mit den in der Wissensdatenbank gespeicherten Vektoren verglichen, um auf der Grundlage von Ähnlichkeitsmetriken die relevantesten oder ähnlichsten Dokumente abzurufen.
Einige fortgeschrittene Ansätze zur Vektorisierung und Optimierung von Abfragen werden in erläutert diesen Teil des RAG verstehen Serie.
# 6. Relevanten Kontext abrufen
Sobald Ihre Abfrage vektorisiert ist, führt der Retriever des RAG-Methods eine ähnlichkeitsbasierte Suche durch, um die am besten passenden Vektoren (Dokumentblöcke) zu finden. Während traditionelle Prime-Okay-Ansätze oft funktionieren, können fortschrittliche Methoden wie Fusion Retrieval und Reranking verwendet werden, um die Verarbeitung und Integration der abgerufenen Ergebnisse als Teil der endgültigen, angereicherten Eingabeaufforderung für das LLM zu optimieren.
Kasse diesen verwandten Artikel Weitere Informationen zu diesen fortschrittlichen Mechanismen finden Sie hier. Ebenfalls, Verwalten von Kontextfenstern ist ein weiterer wichtiger Prozess, der angewendet werden muss, wenn die LLM-Fähigkeiten zur Verarbeitung sehr großer Eingaben begrenzt sind.
# 7. Fundierte Antworten generieren
Schließlich betritt der LLM die Szene, nimmt die Anfrage des erweiterten Benutzers mit dem abgerufenen Kontext entgegen und wird angewiesen, die Frage des Benutzers mithilfe dieses Kontexts zu beantworten. In einer richtig gestalteten RAG-Architektur führt die Befolgung der vorherigen sechs Schritte normalerweise zu genaueren, vertretbaren Antworten, die sogar Zitate auf unsere eigenen Daten umfassen können, die zum Aufbau der Wissensbasis verwendet wurden.
An diesem Punkt ist die Bewertung der Qualität der Reaktion von entscheidender Bedeutung, um zu messen, wie sich das gesamte RAG-System verhält und um zu signalisieren, wann das Modell dies benötigen könnte Feinabstimmung. Bewertungsrahmen zu diesem Zweck wurden gegründet.
# Abschluss
RAG-Systeme oder -Architekturen sind zu einem quick unverzichtbaren Bestandteil von LLM-basierten Anwendungen geworden, und kommerzielle, groß angelegte Anwendungen vermissen sie heutzutage kaum noch. RAG macht LLM-Anwendungen zuverlässiger und wissensintensiver und hilft diesen Modellen dabei, fundierte Antworten auf der Grundlage von Beweisen zu generieren, die manchmal auf privaten Daten in Organisationen basieren.
Dieser Artikel fasst sieben wichtige Schritte zur Beherrschung des Prozesses der Konstruktion von RAG-Systemen zusammen. Sobald Sie über diese grundlegenden Kenntnisse und Fähigkeiten verfügen, sind Sie in einer guten Place, erweiterte LLM-Anwendungen zu entwickeln, die Leistung, Genauigkeit und Transparenz auf Unternehmensniveau ermöglichen – etwas, das mit bekannten, im Web verwendeten Modellen nicht möglich ist.
Iván Palomares Carrascosa ist ein führender Autor, Redner und Berater in den Bereichen KI, maschinelles Lernen, Deep Studying und LLMs. Er schult und leitet andere darin, KI in der realen Welt zu nutzen.