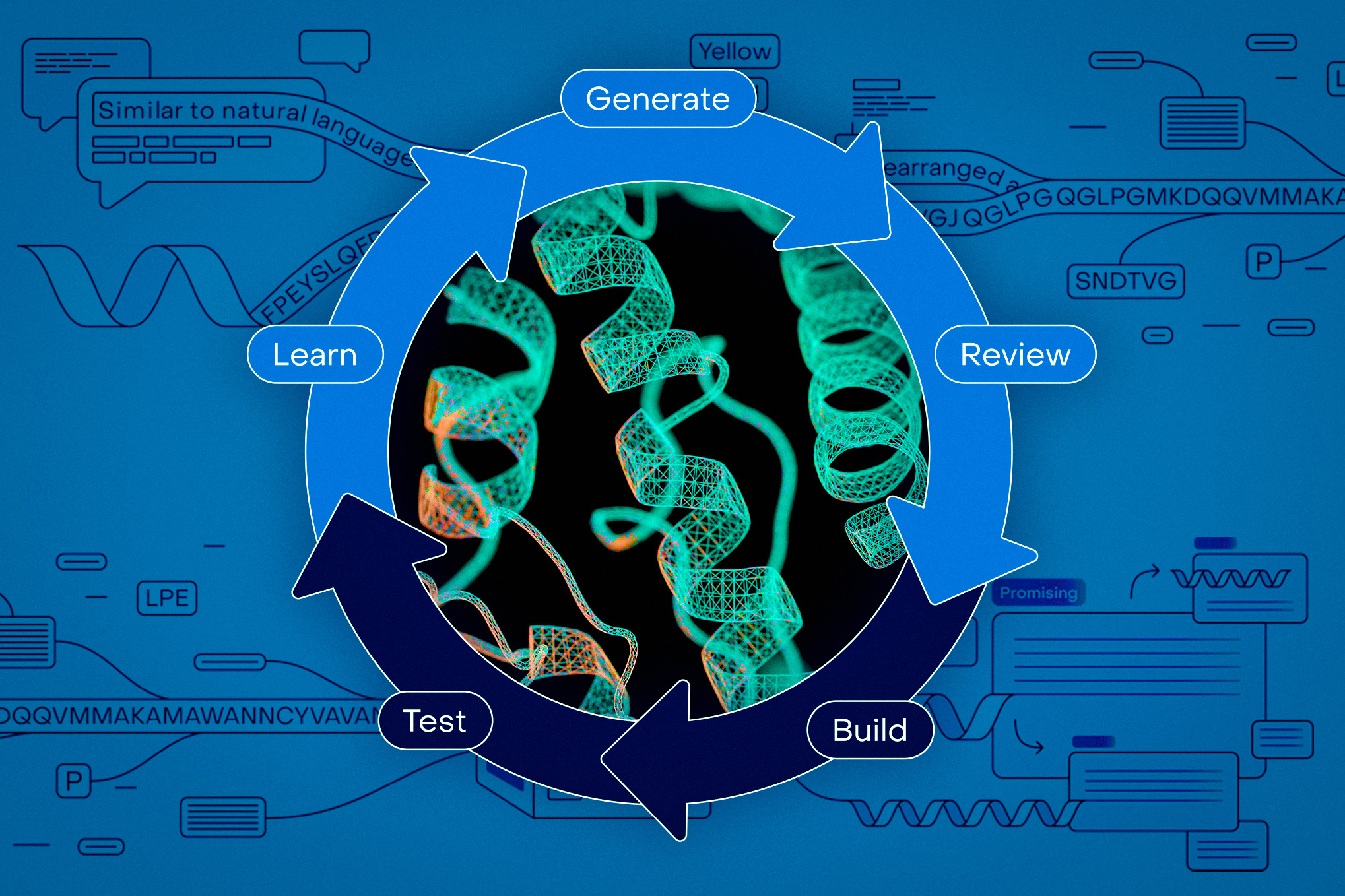
Künstliche Intelligenz beweist bereits, dass sie die Arzneimittelentwicklung beschleunigen und unser Verständnis von Krankheiten verbessern kann. Aber um KI in neuartige Behandlungen umzuwandeln, müssen wir die neuesten und leistungsstärksten Modelle in die Hände von Wissenschaftlern bringen.
Das Drawback ist, dass die meisten Wissenschaftler keine Experten für maschinelles Lernen sind. Jetzt hilft das Unternehmen OpenProtein.AI Wissenschaftlern, auf dem neuesten Stand der KI zu bleiben, mit einer No-Code-Plattform, die ihnen Zugriff auf leistungsstarke Basismodelle und eine Reihe von Instruments zum Design von Proteinen, zur Vorhersage von Proteinstruktur und -funktion sowie zum Trainieren von Modellen bietet.
Das von Tristan Bepler PhD ’20 und dem ehemaligen MIT-Assoziierten Professor Tim Lu PhD ’07 gegründete Unternehmen stattet Forscher in Pharma- und Biotech-Unternehmen jeder Größe bereits mit seinen Werkzeugen aus, darunter intern entwickelte Grundlagenmodelle für Protein-Engineering. OpenProtein.AI stellt seine Plattform auch Wissenschaftlern im akademischen Bereich kostenlos zur Verfügung.
„Es ist gerade eine wirklich aufregende Zeit, denn diese Modelle können nicht nur das Protein-Engineering effizienter machen – was die Entwicklungszyklen für Therapeutika und industrielle Anwendungen verkürzt – sie können auch unsere Fähigkeit verbessern, neue Proteine mit spezifischen Eigenschaften zu entwerfen“, sagt Bepler. „Wir denken auch darüber nach, diese Ansätze auf Nicht-Protein-Modalitäten anzuwenden. Das große Ganze ist, dass wir eine Sprache zur Beschreibung biologischer Systeme schaffen.“
Mit KI die Biologie voranbringen
Bepler kam 2014 im Rahmen des PhD-Programms für Pc- und Systembiologie ans MIT und studierte bei Bonnie Berger, Simons-Professorin für Angewandte Mathematik am MIT. Dort wurde ihm klar, wie wenig wir über die Moleküle wissen, aus denen die Bausteine der Biologie bestehen.
„Wir hatten Biomoleküle und Proteine nicht intestine genug charakterisiert, um gute Vorhersagemodelle darüber zu erstellen, was beispielsweise ein ganzer Genomkreislauf tun wird oder wie sich ein Proteininteraktionsnetzwerk verhalten wird“, erinnert sich Bepler. „Es hat mein Interesse geweckt, Proteine auf einer feineren Ebene zu verstehen.“
Bepler begann mit der Erforschung von Möglichkeiten zur Vorhersage der Aminosäureketten, aus denen Proteine bestehen, indem er Evolutionsdaten analysierte. Dies geschah, bevor Google AlphaFold veröffentlichte, ein leistungsstarkes Vorhersagemodell für die Proteinstruktur. Die Arbeit führte zu einem der ersten generativen KI-Modelle zum Verständnis und Design von Proteinen – das, was das Workforce ein Protein-Sprachmodell nennt.
„Ich warfare wirklich begeistert vom klassischen Gerüst von Proteinen und den Beziehungen zwischen ihrer Sequenz, Struktur und Funktion. Wir verstehen diese Zusammenhänge nicht intestine“, sagt Bepler. „Wie könnten wir additionally diese Basismodelle nutzen, um die ‚Struktur‘-Komponente zu überspringen und direkt von der Sequenz zur Funktion überzugehen?“
Nach seiner Promotion im Jahr 2020 trat Bepler als Postdoc in Lus Labor in der Abteilung für Biotechnik des MIT ein.
„Das warfare ungefähr zu der Zeit, als die Idee, KI und Biologie zu integrieren, aufkam“, erinnert sich Lu. „Tristan hat uns geholfen, bessere Rechenmodelle für das biologische Design zu entwickeln. Wir haben auch erkannt, dass es eine Diskrepanz zwischen den modernsten verfügbaren Werkzeugen und den Biologen gibt, die diese Dinge gerne nutzen würden, aber nicht wissen, wie man programmiert. OpenProtein entstand aus der Idee, den Zugang zu diesen Werkzeugen zu erweitern.“
Bepler hatte im Rahmen seiner Doktorarbeit an der Spitze der KI gearbeitet. Er wusste, dass die Technologie Wissenschaftlern helfen könnte, ihre Arbeit zu beschleunigen.
„Wir begannen mit der Idee, eine Allzweckplattform für die maschinelle Lern-in-the-Loop-Proteintechnik zu entwickeln“, sagt Bepler. „Wir wollten etwas entwickeln, das benutzerfreundlich ist, weil Ideen für maschinelles Lernen irgendwie esoterisch sind. Sie erfordern Implementierung, GPUs, Feinabstimmung und den Entwurf von Sequenzbibliotheken. Besonders zu dieser Zeit gab es für Biologen viel zu lernen.“
Im Gegensatz dazu verfügt die Plattform von OpenProtein über eine intuitive Weboberfläche, über die Biologen Daten hochladen und Protein-Engineering-Arbeiten mit maschinellem Lernen durchführen können. Es bietet eine Reihe von Open-Supply-Modellen, darunter PoET, das Flaggschiff-Proteinsprachenmodell von OpenProtein.
PoET, kurz für Protein Evolutionary Transformer, wurde auf Proteingruppen trainiert, um Sätze verwandter Proteine zu generieren. Bepler und seine Mitarbeiter zeigten, dass es die evolutionären Einschränkungen von Proteinen verallgemeinern und neue Informationen über Proteinsequenzen ohne Umschulung einbeziehen konnte, was es anderen Forschern ermöglichte, experimentelle Daten hinzuzufügen, um das Modell zu verbessern.
„Forscher können ihre eigenen Daten verwenden, um Modelle zu trainieren und Proteinsequenzen zu optimieren, und dann können sie unsere anderen Instruments verwenden, um diese Proteine zu analysieren“, sagt Bepler. „Die Leute erstellen Bibliotheken von Proteinsequenzen in silico (auf Computern) und lassen sie dann durch Vorhersagemodelle laufen, um Validierung und strukturelle Prädiktoren zu erhalten. Es handelt sich im Grunde genommen um ein No-Code-Frontend, aber wir haben auch APIs für Leute, die mit Code darauf zugreifen möchten.“
Die Modelle helfen Forschern, Proteine schneller zu entwerfen und dann zu entscheiden, welche für weitere Labortests vielversprechend genug sind. Forscher können auch Proteine von Interesse eingeben und die Modelle können neue mit ähnlichen Eigenschaften generieren.
Seit seiner Gründung hat das Workforce von OpenProtein seiner Plattform kontinuierlich Instruments für Forscher hinzugefügt, unabhängig von der Größe ihres Labors oder ihren Ressourcen.
„Wir haben uns sehr bemüht, die Plattform zu einem offenen Werkzeugkasten zu machen“, sagt Bepler. „Es verfügt über spezifische Arbeitsabläufe, ist aber nicht spezifisch an eine Proteinfunktion oder Proteinklasse gebunden. Eines der großartigen Dinge an diesen Modellen ist, dass sie Proteine sehr intestine im Großen und Ganzen verstehen können. Sie lernen den gesamten Bereich möglicher Proteine kennen.“
Ermöglichung der nächsten Technology von Therapien
Das große Pharmaunternehmen Boehringer Ingelheim begann Anfang 2025 mit der Nutzung der Plattform von OpenProtein. Kürzlich gaben die Unternehmen eine erweiterte Zusammenarbeit bekannt, bei der die Plattform und Modelle von OpenProtein in die Arbeit von Boehringer Ingelheim bei der Entwicklung von Proteinen zur Behandlung von Krankheiten wie Krebs sowie Autoimmun- oder Entzündungserkrankungen eingebettet werden.
Letztes Jahr veröffentlichte OpenProtein außerdem eine neue Model seines Protein-Sprachmodells PoET-2, das viel größere Modelle übertrifft und dabei nur einen kleinen Teil der Rechenressourcen und experimentellen Daten verbraucht.
„Wir wollen wirklich die Frage lösen, wie wir Proteine beschreiben“, sagt Bepler. „Was ist die sinnvolle, domänenspezifische Sprache der Proteinbeschränkungen, die wir verwenden, wenn wir sie generieren? Wie können wir weitere evolutionäre Einschränkungen einführen? Wie können wir eine enzymatische Reaktion, die ein Protein ausführt, so beschreiben, dass ein Modell Sequenzen generieren kann, um diese Reaktion durchzuführen?“
Vorwärts gehen, Die Gründer hoffen, Modelle zu entwickeln, die die sich verändernde, vernetzte Natur der Proteinfunktion berücksichtigen.
„Der Bereich, der mich begeistert, ist, über Proteinbindungsereignisse hinauszugehen und diese Modelle zur Vorhersage und Gestaltung dynamischer Merkmale zu verwenden, bei denen das Protein zwei, drei oder vier biologische Mechanismen gleichzeitig aktivieren oder seine Funktion nach der Bindung ändern muss“, sagt Lu, der derzeit in einer beratenden Funktion für das Unternehmen tätig ist.
Während der Fortschritt in der KI voranschreitet, sieht OpenProtein seine Mission weiterhin darin, Wissenschaftlern die besten Werkzeuge zur Verfügung zu stellen, um neue Behandlungen schneller zu entwickeln.
„Da die Arbeit immer komplexer wird und Ansätze Dinge wie Proteinlogik und dynamische Therapien einbeziehen, werden die vorhandenen experimentellen Instruments zu Einschränkungen“, sagt Lu. „Es ist wirklich wichtig, offene Ökosysteme rund um KI und Biologie zu schaffen. Es besteht die Gefahr, dass KI-Ressourcen so konzentriert werden, dass der durchschnittliche Forscher sie nicht nutzen kann. Offener Zugang ist für den Fortschritt im wissenschaftlichen Bereich äußerst wichtig.“