
Der neueste Satz von Open-Supply-Modelle von DeepSeek sind hier.
Während die Branche die Dominanz von „geschlossen„Iterationen wie GPT-5.5, die Ankunft von DeepSeek-V4 hat die Dominanz zugunsten der Open-Supply-KI abgehakt. Durch die Kombination einer MoE-Architektur mit 1,6 Billionen Parametern und einem riesigen Kontextfenster mit 1 Million Token hat DeepSeek-V4 Excessive-Reasoning-Intelligenz effektiv zur Ware gemacht.
Dieser Wandel verändert die Artwork und Weise, wie wir über Kosten und Fähigkeiten von KI denken. Lassen Sie uns die neuesten Varianten der DeepSeek-Familie entschlüsseln.
Was ist DeepSeek-V4?
DeepSeek-V4 ist die neueste Model der DeepSeek-Modellfamilie, die speziell für die Verarbeitung von Daten mit langem Kontext entwickelt wurde. Es kann bis zu 1 Million Token effizient verarbeiten und eignet sich daher perfect für Aufgaben wie erweiterte Argumentation, Codegenerierung und Dokumentzusammenfassung. Es nutzt revolutionary Hybridmechanismen wie Manifold-Constrained Hyper-Connections (mHC) und ermöglicht so die effiziente Verarbeitung von über einer Million Token. Dies macht es zur ersten Wahl für Branchen und Entwickler, die KI in großem Maßstab in ihre Arbeitsabläufe integrieren möchten.
Hauptmerkmale von DeepSeek-V4
Hier sind die bemerkenswerten Funktionen des neuesten Modells von DeepSeek:
- Open-Supply (Apache 2.0): Im Gegensatz zu „geschlossenen“ Modellen von OpenAI oder Google ist DeepSeek-V4 vollständig Open Supply. Dies bedeutet, dass die Gewichte und der Code für jedermann zum Herunterladen, Ändern und Ausführen auf seiner eigenen {Hardware} verfügbar sind.
- Huge Kosteneinsparungen: Die API kostet ungefähr einen Bruchteil der Preise der Konkurrenz 1/5 die Kosten von GPT-5.5.
- Zwei Modellvarianten:
- DeepSeek-V4-Professional: Eine sehr leistungsstarke Model mit 1,6 Billionen Parameterkonzipiert für Excessive-Finish-Rechenaufgaben.
- DeepSeek-V4-Flash: Eine effizientere und kostengünstigere Model, die die meisten Vorteile der Professional-Model zu einem reduzierten Preis bietet.
| Modell | Gesamtparameter | Aktive Parameter | Vorab trainierte Token | Kontextlänge | Open Supply | API-Dienst | WEB/APP-Modus |
|---|---|---|---|---|---|---|---|
| deepseek-v4-pro | 1,6T | 49B | 33T | 1M | ✔️ | ✔️ | Experte |
| deepseek-v4-flash | 284B | 13B | 32T | 1M | ✔️ | ✔️ | Sofort |
- Unübertroffene Agentenfähigkeit: Speziell optimiert, um als „autonomer Agent“ zu fungieren. Es beantwortet nicht nur Fragen; Es kann durch Ihr gesamtes Projekt navigieren, Instruments verwenden und mehrstufige Aufgaben wie ein digitaler Mitarbeiter erledigen.
- Weltklasse-Argumentation: In Mathematik- und Wettbewerbs-Codierungs-Benchmarks erreicht oder übertrifft es die leistungsstärksten privaten Modelle der Welt und beweist damit, dass Open Supply auf „Frontier“-Niveau mithalten kann.
- Bereit für Client-{Hardware}: Dank extremer Effizienz ist die V4-Flash Die Model kann auf Excessive-Finish-Client-GPUs (wie einem Twin-RTX-5090-Setup) ausgeführt werden und bringt Leistung der „GPT-Klasse“ auf Ihren lokalen Schreibtisch.
DeepSeek-V4: Technische Durchbrüche
DeepSeek-V4 gelingt nicht nur durch rohe Gewalt. Es werden drei spezifische Architekturinnovationen vorgestellt, die das Downside des langen Kontexts lösen:
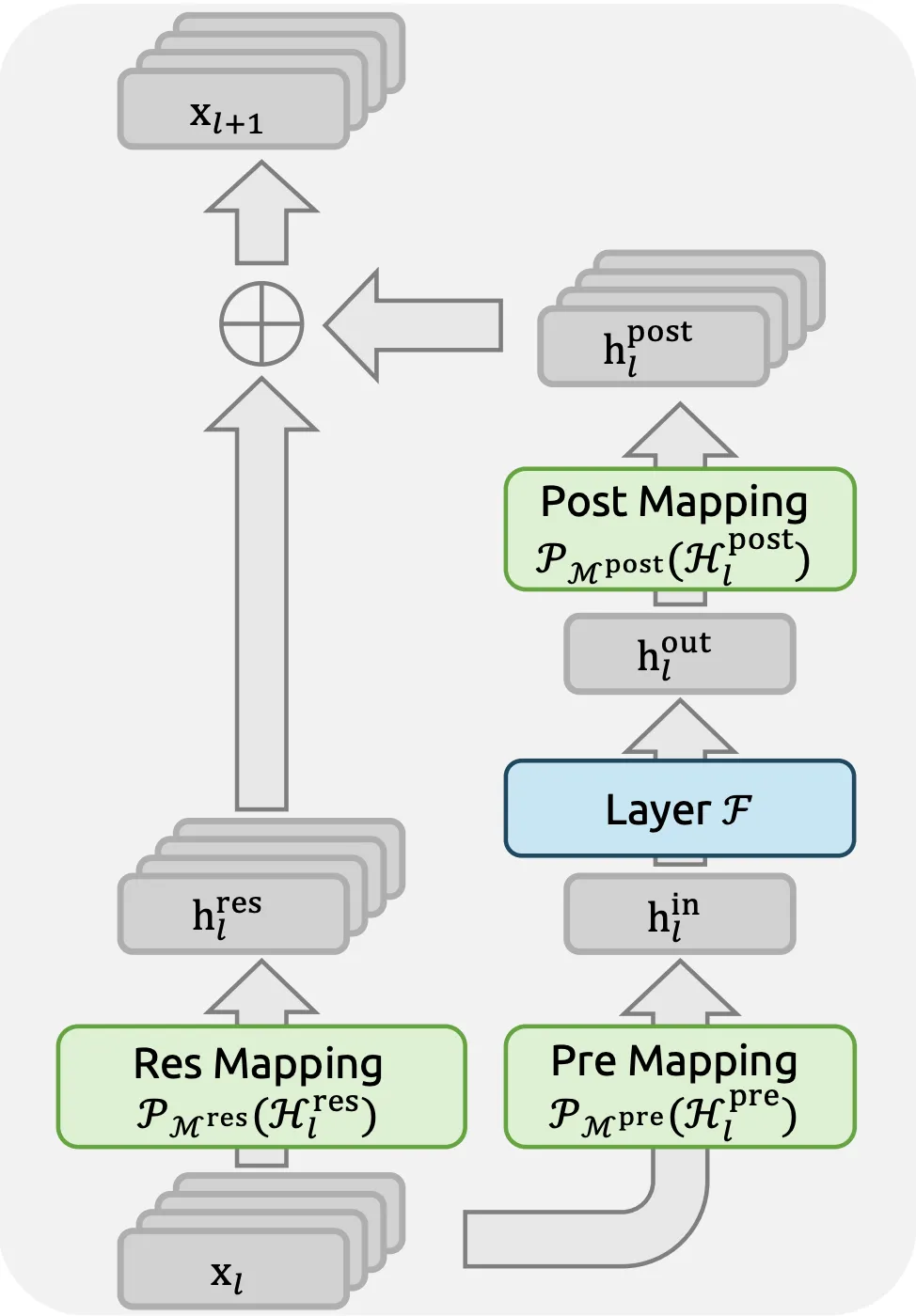
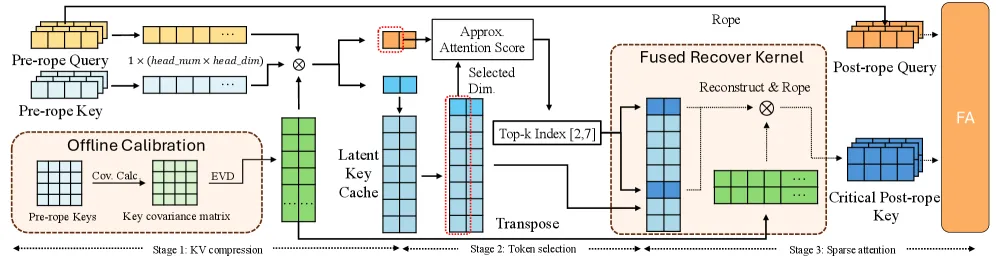
- Hybride Aufmerksamkeit (CSA + HCA): Durch Kombinieren Komprimierte spärliche Aufmerksamkeit mit Stark komprimierte Aufmerksamkeitreduziert das Modell den VRAM-Overhead um 70 % im Vergleich zum Customary-FlashAttention-2, sodass 1 Mio. Kontextlängen auf Unternehmenshardware der Verbraucherklasse ausgeführt werden können.
- Der Myon-Optimierer: Eine revolutionäre Optimierungstechnik zweiter Ordnung, die es dem Modell ermöglicht, während des Trainings schneller „Konvergenz“ zu erreichen und so sicherzustellen, dass die 1,6T-Parameter tatsächlich effizient genutzt werden und nicht auf dem Konfigurationsblatt verbleiben.
Hier erfahren Sie, wie diese Optimierungen dazu beitragen, die Transformer-Architektur von DeepSeek-V4 im Vergleich zu einer Customary-Transformer-Architektur zu verbessern.
| Besonderheit | Standardtransformator | DeepSeek-V4 (2026) |
| Aufmerksamkeitsskalierung | Quadratisch (An2)) | Sublinear/Hybrid |
| KV-Cache-Größe | 100 % (Basislinie) | 12 % des Ausgangswertes |
| Optimierung | Erste Ordnung (AdamW) | Zweite Ordnung (Myon) |
| Vorhersage | Einzel-Token | Multi-Token (4-stufig) |
Diese Architektur macht DeepSeek-V4 im Wesentlichen zu einer „Reasoning Engine“ und nicht nur zu einem Textgenerator.
Diese Effizienz verbesserte nicht nur die Qualität der Modellantworten, sondern machte sie auch erschwinglich!
Wirtschaftskrise: Der Preiskampf
Die unmittelbarste Auswirkung von DeepSeek-V4 ist seine Preisstrategie. Es hat einen „Wettlauf nach unten“ erzwungen, der Entwicklern und Startups (uns) zugute kommt.
API-Preisvergleich (USD professional 1 Mio. Token)
| Modell | Eingabe (Cache-Miss) | Ausgabe | Kosteneffizienz im Vergleich zu GPT-5.5 |
| DeepSeek-V4-Flash | 0,14 $ | 0,28 $ | ~36x günstiger |
| GPT-5.5 (Foundation) | 5,00 $ | 30,00 $ | Referenz |
DeepSeeks Cache-Treffer Durch die Preisgestaltung (0,028 $) sind Agenten-Workflows (bei denen derselbe Kontext wiederholt abgefragt wird) nahezu kostenlos. Dies ermöglicht ewige KI-Agenten das für Cent professional Tag in einer Codebasis „leben“ kann.
ChatGPT- und Claude-Benutzer verlieren bei dieser Preisgestaltung den Verstand! Und das auch noch wenige Stunden nach der Veröffentlichung von GPT 5.5! Das sendet eindeutig eine Botschaft.
Und dieser Vorteil beschränkt sich nicht nur auf die Preisgestaltung. Die Leistung des DeepSeek V4 macht ihn eindeutig zu einer Klasse für sich.
DeepSeek-V4 vs. The Giants: Benchmarks
Während OpenAI und Anthropic traditionell in der akademischen Argumentation führend waren, hat DeepSeek-V4 diese Lücke offiziell geschlossen Angewandte Technik Und Agentenautonomie. Es geht nicht nur darum, mit der Konkurrenz mitzuhalten; In den meisten Szenarien übertrifft es sie.
1. Der technische Vorsprung: SWE-Bench verifiziert
Dies ist der Goldstandard für die KI-Codierung. Es testet die Fähigkeit eines Modells, echte GitHub-Probleme durchgängig zu beheben. DeepSeek-V4-Professional hat einen neuen Rekord aufgestellt, insbesondere bei der Verwaltung mehrerer Datei-Repositorys.
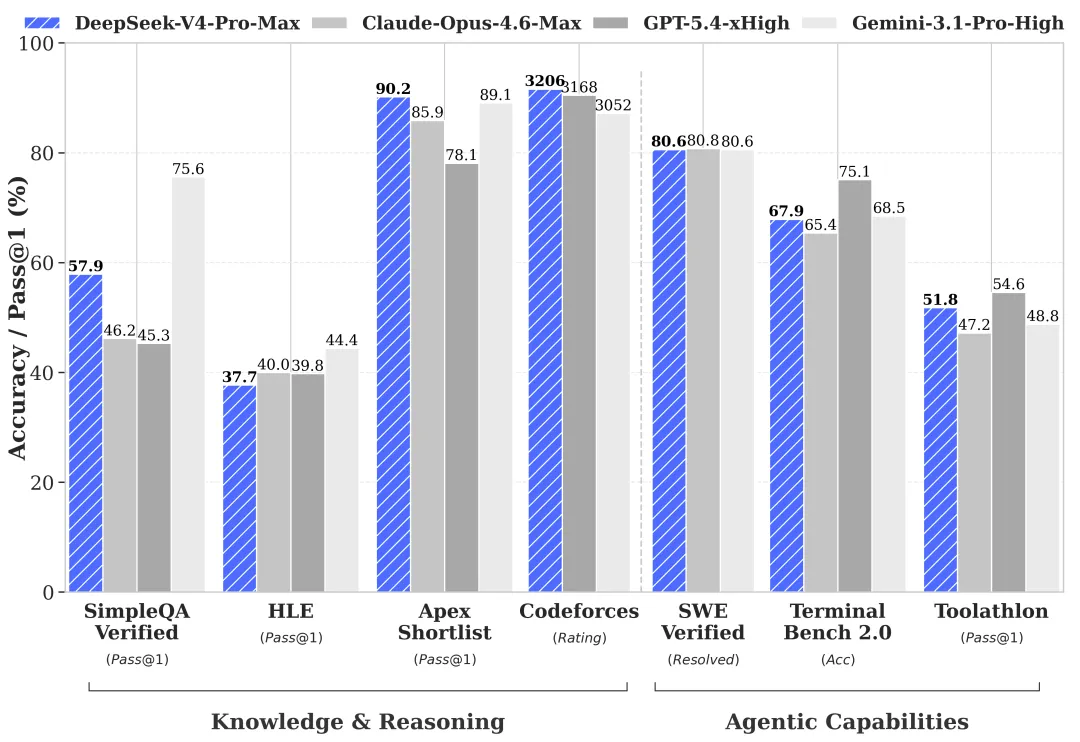
Hier ist eine Tabelle mit der Leistung im Vergleich zu anderen SOTA-Modellen:
| Modell | SWE-Bench verifiziert (Rating) | Kontextzuverlässigkeit (1 Mio. Token) |
| DeepSeek-V4 Professional | 80,6 % | 97,0 % (nahezu perfekt) |
| GPT-5.5 | 80,8 % | 82,5 % |
| Gemini 3.1 Professional | 80,6 % | 94,0 % |
2. Mathematik und Argumentation (AIME / GPQA)
In Naturwissenschaften und Wettbewerbsmathematik auf PhD-Niveau liefert sich der „Pondering Mode“ (DeepSeek-Reasoner V4) von DeepSeek-V4 nun einen Schlagabtausch mit den teuersten Modellen der „O-Serie“ von OpenAI.
- GPQA (Wissenschaft auf PhD-Niveau): 91,8 % (DeepSeek-V4) vs. 93,2 % (GPT-5.5 Professional).
- AIME 2026 (Mathe): 96,4 % (DeepSeek-V4) vs. 95,0 % (Claude 4.6).
Es gibt einen klaren Wettbewerb sowohl hinsichtlich der Argumentations- als auch der mathematischen Aufgaben.
So greifen Sie auf DeepSeek-V4 zu
Sie können darauf zugreifen DeepSeek-V4 durch mehrere Methoden:
- Webinterface: Zugriff über die Plattform von DeepSeek unter chat.deepseek.com mit einer einfachen Anmeldung und Anmeldung.
- Cloud-Plattformen: Verwenden DeepSeek-V4 über cloudbasierte IDEs oder Dienste wie HuggingFace-Leerzeichen.
- Lokale Bereitstellung: Nutzen Sie Dienste wie VLLM die lokale Downloads und Nutzung von DeepSeek-V4 anbieten.
Jede Methode bietet unterschiedliche Möglichkeiten zur Integration DeepSeek-V4 in Ihren Workflow basierend auf Ihren Anforderungen integrieren. Wählen Sie Ihre Methode und betreten Sie mit diesen neuen Modellen die Grenzen.
Die Zukunft gestalten
DeepSeek-V4 stellt den Übergang der KI von a dar Abfrage-Antwort Werkzeug an einen hartnäckigen Mitarbeiter weitergeben. Seine Kombination aus Open-Supply-Zugänglichkeit, beispielloser Kontexttiefe und „Flash“-Preisen macht es zur bedeutendsten Veröffentlichung des Jahres 2026. Für Entwickler ist die Botschaft klar: Der Engpass sind nicht mehr die Kosten für Intelligenz, sondern die Vorstellungskraft der Particular person, die sie veranlasst.
Häufig gestellte Fragen
A. Ja, die Gewichte werden unter der DeepSeek-Lizenz veröffentlicht und ermöglichen eine kommerzielle Nutzung mit geringfügigen Einschränkungen bei der groß angelegten Neubereitstellung.
A: DeepSeek-V4 ist von Natur aus multimodal, unterstützt dies jedoch derzeit nicht. Die Entwickler behaupten, dass es bald eingeführt wird.
A. Es nutzt eine „destillierte“ MoE-Architektur, bei der bei jedem Inferenzschritt nur 13B der 248B Parameter aktiv sind.
Ich bin auf die Überprüfung und Verfeinerung von KI-gestützter Forschung, technischer Dokumentation und Inhalten im Zusammenhang mit neuen KI-Technologien spezialisiert. Meine Erfahrung umfasst KI-Modelltraining, Datenanalyse und Informationsabruf und ermöglicht es mir, Inhalte zu erstellen, die sowohl technisch korrekt als auch zugänglich sind.
Melden Sie sich an, um weiterzulesen und von Experten kuratierte Inhalte zu genießen.