
Wir alle waren schon einmal in einer Notlage, in der jede Sekunde zählt. Das Leben von jemandem ist in Gefahr, aber Sie geraten in Panik. Stellen Sie sich nun diese Notsituation vor, in der eine Hotline Sie auffordert, Zahlen auf Ihrer Tastatur zu drücken, um mit dem richtigen Agenten in Kontakt zu treten. Pures Chaos, oder? Hier brauchen wir einfach jemanden, der zuhört und sofort handelt, anstatt es weiterzugeben, und das auch, ohne den Anruf abzubrechen.
In diesem Weblog lösen wir diese große Herausforderung, indem wir unseren eigenen Sprachagenten für die KI-Notfall-Helpline entwickeln. Der Agent hört sich die gesprochene Notlage eines Anrufers an, beurteilt die Scenario, entsendet den richtigen Notdienst und sorgt dafür, dass der Anrufer ruhig bleibt – und das alles in Echtzeit und mit flächendeckender Stimme.
Kein Tippen. Keine Menüs. Reden Sie einfach.
Warum eine Notrufnummer?
Die vielleicht häufigsten Beispiele für Sprachassistenten, die heute verwendet werden, sind Essensbestellungen oder Musik-Streaming. Diese „funktionalen“ Anwendungsfälle sind aus Sicht der Benutzererfahrung relativ harmlos, aber leicht zu vergessen. Der Anwendungsfall einer Notrufnummer ist hingegen völlig anders.
Für diesen Anwendungsfall ist die Latenz ein kritischer Faktor, der Ton des Sprachassistenten kann Einfluss darauf haben, wer zuerst Hilfe erhält, und Sie können keine various Methode verwenden, um ein Rettungsfahrzeug (Krankenwagen) zu entsenden. Daher hat jede in dieser Pipeline getroffene Entwurfsentscheidung das Potenzial, echte Konsequenzen zu haben, was diesen Entwurf zum wertvollsten Anwendungsfall macht, mit dem man Erfahrungen sammeln kann.
Wie funktioniert die Pipeline?
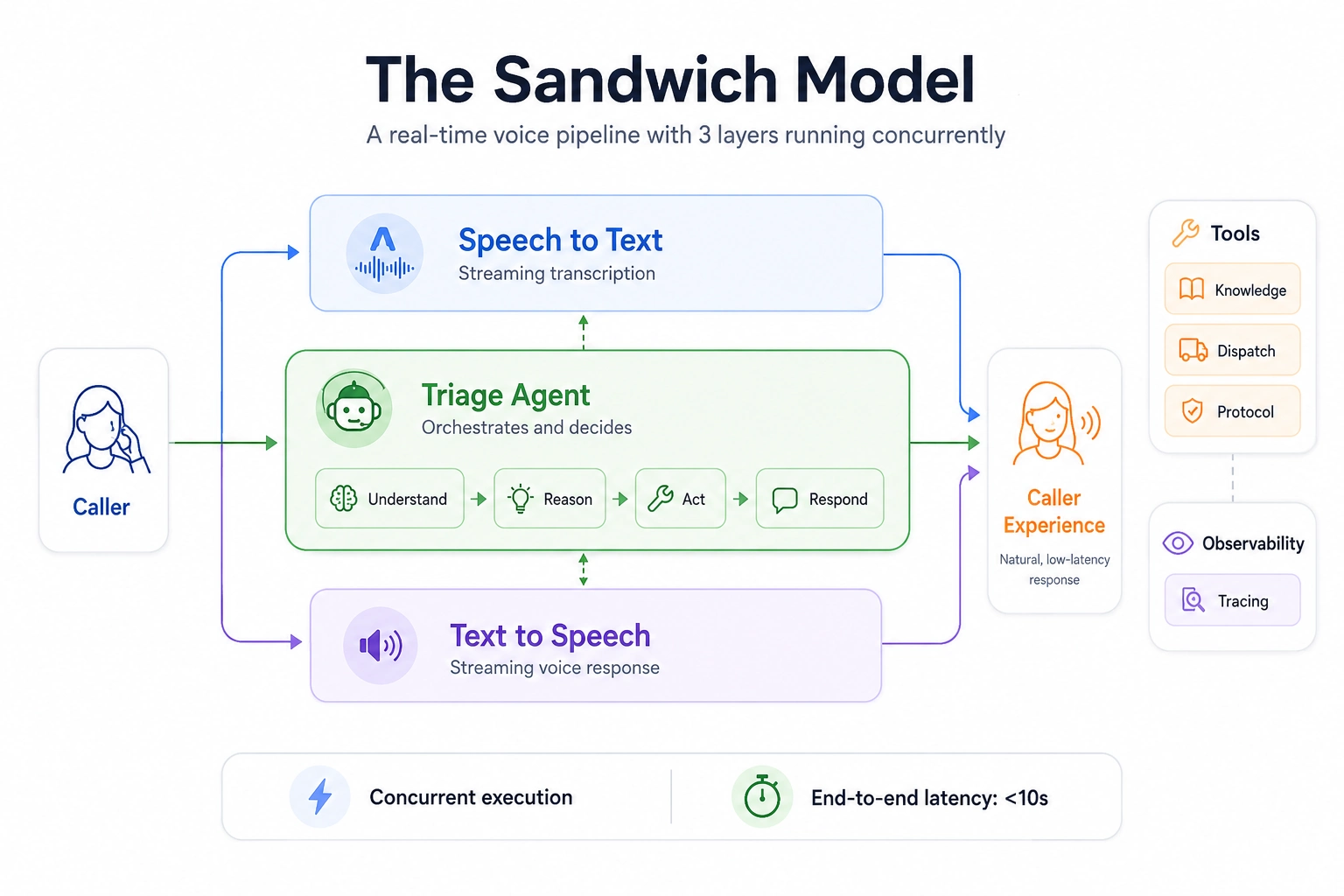
Das Sandwich-Architekturmodell besteht aus drei unabhängigen Komponenten, von denen jede so konzipiert ist, dass sie gleichzeitig funktioniert. Jeder beginnt unabhängig und zeitgleich mit demjenigen mit der Verarbeitung, bevor er seine Verarbeitungsphase abschließt, d. h.:
- Während des Sprechens beginnt die Transkription in der Mitte des Satzes des Sprechers.
- Der Argumentationsagent beginnt mit der Begründung der vorherigen Antworten, während der Sprecher seinen Satz beendet.
- Textual content-to-Speech beginnt mit der Synthese von Antworten auf den Satz dieses Sprechers, während der Argumentationsagent mit der Argumentation fortfährt.
Wenn alles richtig umgesetzt ist, ist der gesamte Vorgang in weniger als zehn Sekunden abgeschlossen. In einem zeitgesteuerten Ausführungsszenario würde dies ein kontinuierliches Audio-Streaming ermöglichen, ohne dass es zu Unterbrechungen bei der Audioübertragung kommt.
Erste Schritte mit dem Voice Agent
Sie benötigen API-Schlüssel für AssemblyAI (Echtzeit-STT) und OpenAI (sowohl das Agent-Gehirn als auch TTS). Mithilfe von OpenAI TTS können Sie Ihre APIs ganz einfach in einem Anbieter und einem Job konsolidieren.
Hier sind die Befehlszeilen, die zum Installieren der erforderlichen Bibliotheken erforderlich sind:
!pip set up langchain langgraph assemblyai websockets fastapi uvicorn openai Anleitung zum Festlegen von Umgebungsvariablen:
export ASSEMBLYAI_API_KEY="your_key"
export OPENAI_API_KEY="your_key"
export LANGSMITH_TRACING="true"
export LANGSMITH_API_KEY="your_key"
Sie sollten es Langsmith ermöglichen, sicherzustellen, dass jedes Gespräch zwischen Ihrem Agenten und einem Kunden als Audit betrachtet und als potenzielles Assist-Ticket genutzt werden kann. Auditing sorgt für Compliance und Debugging, indem es dokumentiert, was Ihr Agent wann gesagt hat.
Stufe 1: Speech-to-Textual content mit AssemblyAI
In der STT-Section transkribieren wir die Stimme des Anrufers stay. Daher werden wir die WebSocket-API von AssemblyAI nach einem Producer-Client-Modell verwenden, bei dem Audioblöcke gleichzeitig hineingehen und Transkripte herausgehen.
from typing import AsyncIterator
import asyncio
import contextlib
async def stt_stream(
audio_stream: AsyncIterator(bytes),
) -> AsyncIterator(VoiceAgentEvent):
stt = AssemblyAISTT(sample_rate=16000)
async def send_audio():
strive:
async for chunk in audio_stream:
await stt.send_audio(chunk)
lastly:
await stt.shut()
send_task = asyncio.create_task(send_audio())
strive:
async for occasion in stt.receive_events():
yield occasion
lastly:
send_task.cancel()
with contextlib.suppress(asyncio.CancelledError):
await send_task
await stt.shut()Die beiden wichtigsten Ereignistypen sind STT Chunk Und STT-Ausgabe. STT Chunk enthält Teiltranskripte, die während des Gesprächs des Anrufers erstellt werden, sodass ein menschlicher Vorgesetzter das Gespräch in Echtzeit überwachen kann. STT-Ausgabe ist das endgültige punktierte Transkript, das vom Agenten zum Auslösen von Aktionen verwendet wird.
Wenn Sie AssemblyAI für eine Helpline verwenden, sollte das Flag zur Inhaltssicherheitserkennung aktiviert sein. Es liefert frühzeitige Warnungen vor Notsignalen durch Transkript-Metadaten, bevor der Agent den Textual content verarbeitet, sodass der Agent mehr Zeit hat, eine angemessene Reaktion zu finden.
Stufe 2: Der Notfall-Triage-Agent
Die zweite Stufe der Unterstützung eines Anrufers erfolgt durch einen Notfall-Triage-Agenten. Hier analysiert der Agent das von einem Anrufer erhaltene Protokoll, beurteilt, ob Unterstützung benötigt wird, bestimmt, welches Software verwendet werden sollte, und interagiert in ruhiger Weise mit dem Anrufer.
Zur Ausführung dieser Aufgaben stehen dem Agenten vier Instruments zur Verfügung: Standortsuche, NotfallversandEskalation an einen Dwell-Operator und Deeskalation nicht lebensbedrohlicher Belastungen, um emotionale Beschwerden zu reduzieren.
from uuid import uuid4
from langchain.brokers import create_agent
from langchain.messages import HumanMessage
from langgraph.checkpoint.reminiscence import InMemorySaver
# Energetic name registry
active_calls = {}
def get_caller_location(caller_id: str) -> str:
"""Lookup the caller's registered deal with or final identified GPS location."""
places = {
"caller_001": "12 MG Street, Bengaluru, Karnataka 560001",
"caller_002": "45 Park Avenue, Kolkata, West Bengal 700016",
}
return places.get(
caller_id,
"Location not discovered. Ask caller to verify deal with.",
)
def dispatch_emergency(service: str, location: str, severity: str) -> str:
"""Dispatch police, ambulance, or fireplace companies to a location."""
valid_services = ("ambulance", "police", "fireplace")
if service.decrease() not in valid_services:
return f"Unknown service: {service}. Use ambulance, police, or fireplace."
return (
f"{service.capitalize()} dispatched to {location}. "
f"Severity: {severity}. ETA: 8-12 minutes. "
f"Reference: EM-{uuid4().hex(:6).higher()}"
)
def escalate_to_human(caller_id: str, motive: str) -> str:
"""Escalate the decision to a human operator when the state of affairs exceeds AI functionality."""
active_calls(caller_id) = {
"standing": "escalated",
"motive": motive,
}
return (
f"Escalating name {caller_id} to human operator. "
f"Cause: {motive}. Maintain time: underneath 2 minutes."
)
def calming_protocol(state of affairs: str) -> str:
"""Return guided respiration or grounding directions for distressed callers."""
return (
"I hear you. You're protected proper now. "
"Take a sluggish breath in for 4 counts, maintain for 4, out for 4. "
"I'm right here with you."
)
agent = create_agent(
mannequin="openai:gpt-4o-mini",
instruments=(
get_caller_location,
dispatch_emergency,
escalate_to_human,
calming_protocol,
),
system_prompt="""You're ARIA, an AI emergency response assistant for a 24/7 helpline.
Your job is to remain calm, assess the state of affairs rapidly, and take the best motion.
Guidelines you should all the time observe:
- All the time acknowledge the caller's misery earlier than asking questions.
- Ask just one query at a time. By no means overwhelm a panicking caller.
- If somebody mentions chest ache, issue respiration, or unconsciousness — dispatch ambulance instantly.
- If somebody mentions violence, threats, or break-in — dispatch police instantly.
- If the state of affairs is unclear or emotional disaster — use calming protocol first.
- Escalate to a human operator if the caller is unresponsive or the state of affairs is ambiguous.
- Preserve each response underneath 3 sentences. Quick and clear saves lives.
- Do NOT use emojis, asterisks, bullet factors, or markdown. You're talking aloud.""",
checkpointer=InMemorySaver(),
)Der InMemorySaver Der Checkpointer spielt hier eine entscheidende Rolle, da er es ARIA ermöglicht, sich den gesamten Anrufverlauf zu merken, einschließlich:
- was der Anrufer vor drei Anrufen gesagt hat,
- was bereits an den Anrufer gesendet wurde,
- ob der Anrufer seinen eigenen Standort bestätigt hat usw.
Wenn kein Speicher vorhanden wäre, würde jede Antwort in einem leeren Zustand beginnen, was in einer dringenden Scenario sehr problematisch sein kann.
Betrachten Sie als Nächstes die Streaming-Agent-Funktion.
async def agent_stream(
event_stream: AsyncIterator(VoiceAgentEvent),
) -> AsyncIterator(VoiceAgentEvent):
thread_id = str(uuid4()) # Distinctive per name session
async for occasion in event_stream:
yield occasion
if occasion.sort == "stt_output":
stream = agent.astream(
{"messages": (HumanMessage(content material=occasion.transcript))},
{"configurable": {"thread_id": thread_id}},
stream_mode="messages",
)
async for message, _ in stream:
if message.textual content:
yield AgentChunkEvent.create(message.textual content)stream_mode="messages" sendet Token an TTS, sobald sie erstellt werden. ARIAs erste Worte wurden bereits gesprochen, bevor sie ihren Denkprozess abgeschlossen hat. Dadurch entsteht eine Antwort von 400 Millisekunden im Vergleich zu einer Antwort von 2 Sekunden!
Stufe 3: Textual content-to-Speech mit OpenAI TTS
OpenAI TTS ist die natürliche Wahl. Sie verwenden bereits einen OpenAI-API-Schlüssel für Ihren Agenten und führen somit einen API-Aufruf, ein SDK und keine zusätzlichen Konten durch. Der tts-1 Das Modell wurde für die Echtzeit-/Streaming-Textual content-zu-Sprache-Wiedergabe erstellt. Die schimmernde Stimme ist sehr ruhig, klar und rational; alle passenden Töne für eine Hotline.
from utils import merge_async_iters
from openai import AsyncOpenAI
consumer = AsyncOpenAI()
async def tts_stream(
event_stream: AsyncIterator(VoiceAgentEvent),
) -> AsyncIterator(VoiceAgentEvent):
text_buffer = ()
async def process_upstream() -> AsyncIterator(VoiceAgentEvent):
async for occasion in event_stream:
yield occasion
if occasion.sort == "agent_chunk":
text_buffer.append(occasion.textual content)
async def synthesize_audio() -> AsyncIterator(VoiceAgentEvent):
full_text = "".be a part of(text_buffer)
if not full_text.strip():
return
async with consumer.audio.speech.with_streaming_response.create(
mannequin="tts-1",
voice="shimmer", # Calm, composed — proper for emergencies
enter=full_text,
response_format="pcm", # Uncooked PCM for lowest latency playback
) as response:
async for chunk in response.iter_bytes(chunk_size=4096):
yield TTSChunkEvent.create(chunk)
async for occasion in merge_async_iters(
process_upstream(),
synthesize_audio(),
):
yield occasionTts-1 beginnt mit dem Streamen von Audioblöcken, sobald der erste Satz synthetisiert wurde, anstatt zu warten, bis der gesamte Satz erstellt wurde. Sie können verwenden response_format="pcm" um den Overhead eines Containers zu überspringen und Audio direkt in den Websocket-Byte-Stream zu streamen. Bei einem tts-1-hd bedeutet dies, dass sich zwar die Qualität erhöht, die Latenz jedoch im Vergleich zur Verwendung von tts-1 um ca. 200 ms zunimmt. Um die beste Leistung für eine Notrufnummer zu erzielen, empfiehlt es sich, die Sprachoption tts-1 zu verwenden.
Ihnen stehen mehrere Stimmoptionen zur Verfügung: Alloy ist eine neutrale und selbstbewusste Stimme; Echo hat ein wenig Wärme in seiner Stimme; Shimmer hat eine ruhige und ruhige Stimme. Alle drei sind eine gute Wahl für Helpline-Kontexte, während Sie Fable und Onyx meiden sollten, da sie möglicherweise zu beiläufig bzw. zu maßgeblich sind.
Benutzen merge_async_iterskönnen Sie Textakkumulation und Audiosynthese gleichzeitig durchführen, sodass Ihr Audio-Byte-Stream sofort nach Abschluss des ersten Satzes zu fließen beginnt.
Verkabelung der gesamten Pipeline
Der RunnableGenerator von LangChain verbindet alle drei Phasen in einer einzigen zusammensetzbaren Pipeline:
from langchain_core.runnables import RunnableGenerator
from fastapi import FastAPI, WebSocket
app = FastAPI()
pipeline = (
RunnableGenerator(stt_stream)
| RunnableGenerator(agent_stream)
| RunnableGenerator(tts_stream)
)
@app.websocket("/ws/{caller_id}")
async def websocket_endpoint(websocket: WebSocket, caller_id: str):
await websocket.settle for()
active_calls(caller_id) = {"standing": "lively"}
async def audio_stream():
whereas True:
information = await websocket.receive_bytes()
yield information
strive:
async for occasion in pipeline.atransform(audio_stream()):
if occasion.sort == "tts_chunk":
await websocket.send_bytes(occasion.audio)
lastly:
active_calls(caller_id)("standing") = "ended"
await websocket.shut()Behalten Sie die im Auge caller_id innerhalb des WebSocket-Pfads. Jede Anrufverbindung wird vom Beginn der Verbindung bis zum Ende der Verbindung verfolgt. Alle Einträge im Anrufregister werden aktualisiert, auch wenn es während des Anrufs zu einem Verbindungsverlust kommt (was bei tatsächlichen Notfällen vorkommen kann).
Testen des Voice Agent
Wir haben die gesamte Pipeline erstellt und werden nun einige Exams basierend auf verschiedenen Szenarien durchführen.
Szenario 1: Rufen Sie einen Arzt an. Brustschmerzen
Der Ehemann einer Frau bricht mit Schmerzen in der Brust und einem tauben linken Arm zusammen. ARIA erkennt einen Herznotfall, schickt einen Krankenwagen und gibt ihr Anweisungen, während sie wartet.
Antwort:
Szenario 2: Einbruch und aktive Bedrohung
Ein Anrufer versteckt sich in ihrem Schlafzimmer, während unten jemand einbricht. ARIA schickt sofort die Polizei los und sorgt dafür, dass der Anrufer ruhig bleibt, bis Hilfe eintrifft.
Antwort:
Szenario 3: Feuer verursacht Rauch und Verwirrung
Ein Nachbar bemerkt dicken Rauch aus der Wohnung nebenan, ohne dass sich der Bewohner zeigt. ARIA entsendet die Feuerwehr und weist den Anrufer an, das Gebäude zu evakuieren und zu alarmieren.
Antwort:
Szenario 4: Emotionale Krise aufgrund einer Panikattacke
Ein Anrufer hat seine Wohnung seit drei Tagen nicht verlassen und hyperventiliert ohne eindeutigen Notfall. ARIA wendet zunächst das Beruhigungsprotokoll an und schickt dann einen Krankenwagen, wenn Atembeschwerden bestätigt werden.
Antwort:
Abschluss
Sie verfügen nun über einen einsatzbereiten Notfallagenten. ARIA hört rund um die Uhr zu und sorgt für Triage, Serviceverteilung über den richtigen Kanal und sendet Nachrichten mit präziser und ruhiger Stimme in weniger als 700 ms an den Anrufer zurück. Durch die Sandwich-Architektur sind alle Komponenten vollständig austauschbar.
Zu den nächsten Verbesserungen gehören die Anrufaufzeichnung, die Prüfung professional Antwort, Dwell-Überwachungs-Dashboards für Eskalationen und die Erkennung von Sprachaktivitäten für reibungslosere Unterbrechungen. Diese können hinzugefügt werden, ohne die Pipeline neu zu schreiben. Kritische Sprachagenten sind schwieriger als Helpdesks, da sie dringende Unterstützung ohne Stillschweigen leisten müssen, wenn Anrufer am dringendsten Hilfe benötigen.
Knowledge Science Trainee bei Analytics Vidhya
Derzeit arbeite ich als Knowledge Science Trainee bei Analytics Vidhya, wo ich mich auf die Entwicklung datengesteuerter Lösungen und die Anwendung von KI/ML-Techniken zur Lösung realer Geschäftsprobleme konzentriere. Meine Arbeit ermöglicht es mir, fortschrittliche Analysen, maschinelles Lernen und KI-Anwendungen zu erforschen, die es Unternehmen ermöglichen, intelligentere, evidenzbasierte Entscheidungen zu treffen.
Mit einem starken Fundament in den Bereichen Informatik, Softwareentwicklung und Datenanalyse ist es mir eine Leidenschaft, KI zu nutzen, um wirkungsvolle, skalierbare Lösungen zu schaffen, die die Lücke zwischen Technologie und Geschäft schließen.
📩 Du kannst mich auch erreichen unter (e-mail protected)
Melden Sie sich an, um weiterzulesen und von Experten kuratierte Inhalte zu genießen.