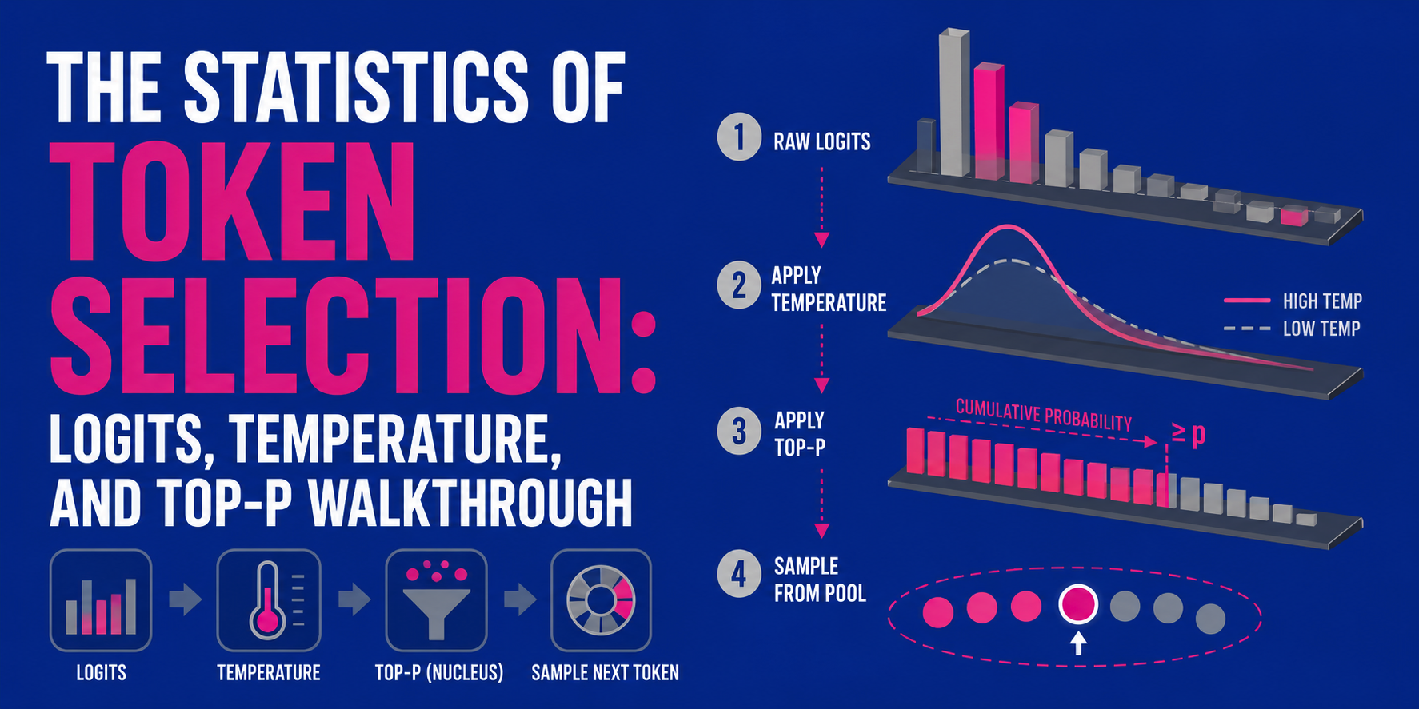
In diesem Artikel erfahren Sie, wie Logits, Temperatur und High-P-Sampling zusammenarbeiten, um die Vorhersage des nächsten Tokens in großen Sprachmodellen zu steuern.
Zu den Themen, die wir behandeln werden, gehören:
- Was Logits sind und wie sie von der letzten linearen Schicht eines Transformators erzeugt werden.
- Wie Temperatur und High-P (Kernprobenahme) die Wahrscheinlichkeitsverteilung beeinflussen, die für die Token-Auswahl verwendet wird.
- Wie diese drei Komponenten in eine sequentielle Pipeline passen, die die LLM-Ausgabegenerierung steuert.
Die Statistik der Token-Auswahl: Protokolle, Temperatur und High-P-Komplettlösung
Einführung
Wenn große Sprachmodelle, kurz LLMs, Ergebnisse produzieren, stehen mehrere Kriterien auf dem Spiel, darunter nicht nur die allgemeine Antwortrelevanz, sondern auch Kohärenz und Kreativität. Da die Modelle tief im Inneren arbeiten, indem sie ihre Antwort Wort für Wort – oder genauer gesagt Token für Token – aufbauen, ist die Erfassung dieser wünschenswerten Eigenschaften eine Frage der mathematischen Anpassung der Ausgabewahrscheinlichkeitsverteilungen, die den Vorhersageprozess für den nächsten Token steuern.
In diesem Artikel werden die Mechanismen hinter LLM-Dekodierungsstrategien aus statistischer Sicht vorgestellt. Insbesondere werden wir untersuchen, wie das Rohmodell punktet, bekannt als Protokollemit zwei anderen Modelleinstellungen interagieren – Temperatur Und top-p – das sind drei Schlüsselparameter, die zur Steuerung des Token-Auswahlprozesses verwendet werden.
Während wir uns darauf konzentrieren werden, zu untersuchen, was in den allerletzten Phasen der zugrunde liegenden Architektur der LLMs, auch bekannt als Transformator, passiert, können Sie dies überprüfen dieser Artikel wenn Sie einen prägnanten Überblick über den gesamten Prozess und die Reise der Token von Anfang bis Ende benötigen.
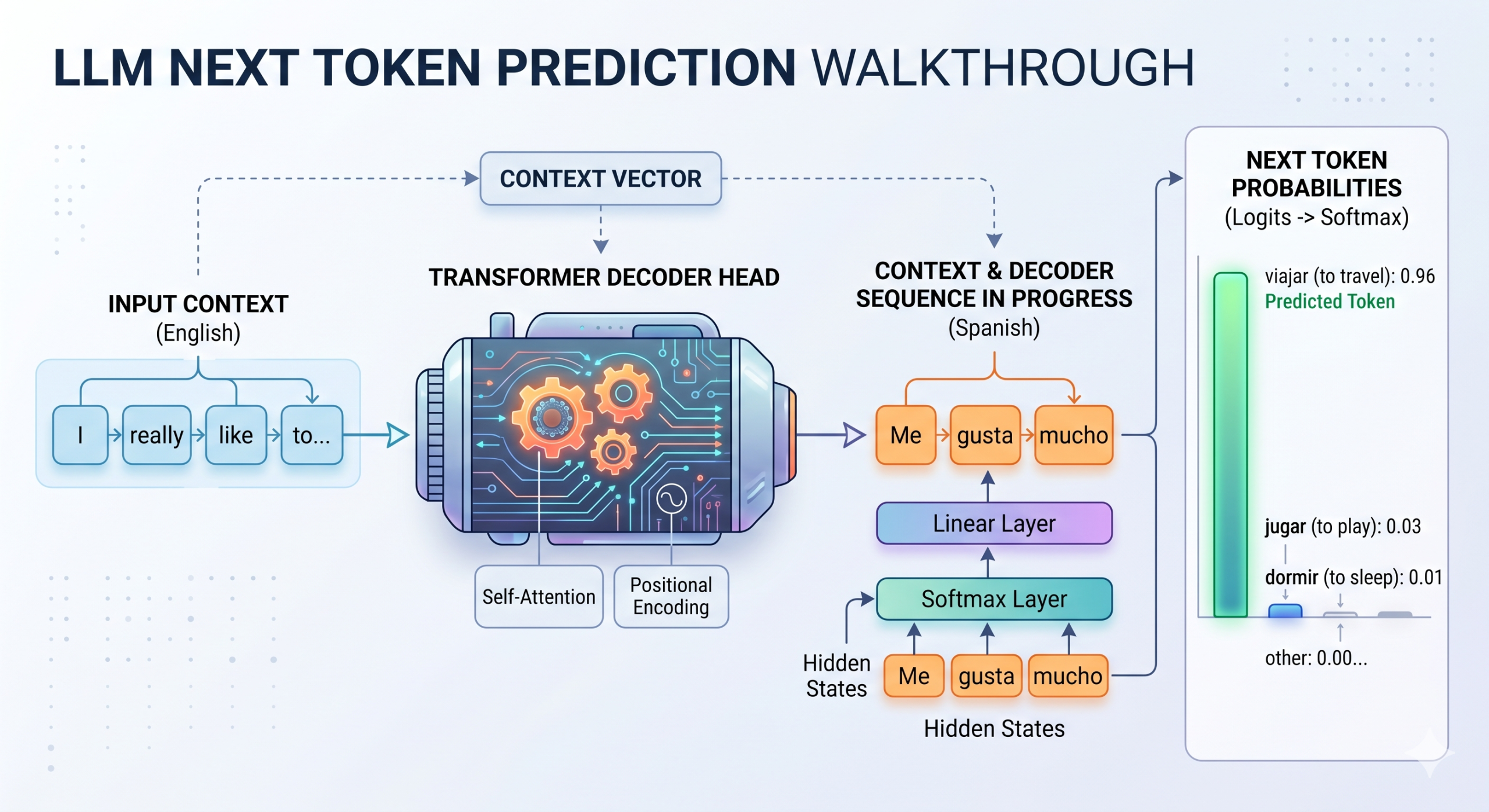
Token-Auswahlprozess in LLMs
Was sind Logits?
In neuronalen Netzen werden die rohen, nicht normalisierten Ergebnisse, die (normalerweise in den letzten linearen Schichten) erzeugt werden, bevor sie in Wahrscheinlichkeiten möglicher Ergebnisse (z. B. Klassen) umgewandelt werden, als Logits bezeichnet. Während Logits seit der Ära klassischer Klassifizierungsmodelle für maschinelles Lernen wie der Softmax-Regression verwendet werden, gilt das gleiche Prinzip immer noch für die letzte lineare Schicht von Transformatormodellen. Diese letzte Schicht verarbeitet verborgene Zustände – die nach und nach angesammeltes linguistisches Wissen über den im gesamten Transformator gesammelten Eingabetext enthalten – und gibt einen Vektor von Logits aus. Wie viele? So viele wie die Vokabulargröße des Modells, dh die Anzahl möglicher Token, die das Modell generieren kann.
Sehen Sie sich zum Beispiel das Diagramm oben an. Wenn ein LLM, der für die Übersetzung vom Englischen ins Spanische geschult ist, das nächste Wort nach der generierten Sequenz „me gusta mucho“ (die Übersetzung von „Ich magazine es wirklich“) vorhersagt, könnte er einen rohen Logit-Wert von 12,5 für „viajar“ (Reisen), 8,2 für „jugar“ (Spielen) und -3,1 für „dormir“ (Schlaf) ausgeben. Diese Rohwerte sind unbegrenzt und daher schwer direkt zu interpretieren; Daher wird eine Softmax-Funktion auf die endgültige lineare Ebene angewendet, um diese Logits in eine standardmäßige, interpretierbare Wahrscheinlichkeitsverteilung über Vokabular-Tokens umzuwandeln, sodass alle Werte 1 ergeben.
Was sind Temperatur und High-p?
Sobald wir eine Wahrscheinlichkeitsverteilung über das Zielvokabular haben, wählen LLMs dann einfach den Token mit der höchsten Wahrscheinlichkeit als nächsten zu generieren aus? Nicht ganz, aber der wahre Prozess ähnelt stark diesem Szenario. Der nächste Token wird aus der Verteilung abgetastet, und wie diese Abtastung funktioniert, hängt von mehreren Decodierungsparametern ab, zwei der wichtigsten sind Temperatur und High-P.
- Temperatur ist ein Skalierungsfaktor, der vor dem Softmax-Schritt auf die Logits angewendet wird. Eine hohe Temperatur (z. B. über 1) flacht die resultierenden Wahrscheinlichkeiten ab und macht sie gleichmäßiger. Dadurch nehmen Unsicherheit und Unvorhersehbarkeit zu und das Modell verhält sich kreativer. Eine niedrige Temperatur (z. B. deutlich unter 1) verschärft die Unterschiede zwischen Token mit hoher und niedriger Wahrscheinlichkeit, erhöht die Sicherheit und begünstigt stark die wahrscheinlichsten Token in der ursprünglichen Verteilung. Mehr zum Thema Temperatur finden Sie hier verwandter Artikel.
- High-pauch genannt Kernprobenahmeist ein weiterer Ansatz zur Steuerung der Zufälligkeit der Auswahl des nächsten Tokens. Anstatt die Wahrscheinlichkeiten zu skalieren, begrenzt es den Pool der Kandidaten, aus denen die Stichprobe ausgewählt werden kann. Während ähnliche Strategien wie top-k nur die okay Token mit der höchsten Wahrscheinlichkeit berücksichtigen, identifiziert top-p den kleinsten Satz von Token, deren kumulative Wahrscheinlichkeit einen Schwellenwert p erreicht oder überschreitet, was sie anpassungsfähiger und flexibler macht. Mit anderen Worten: Wenn wir p=0,9 setzen, sortiert top-p die Token nach Wahrscheinlichkeit und fügt sie so lange einem Kandidatenpool hinzu, bis ihre kumulative Wahrscheinlichkeit 0,9 erreicht.
Die vollständige Komplettlösung: Wie hängen diese Konzepte zusammen?
Logit-zu-Wahrscheinlichkeitsberechnung, Temperatur und High-P können in einer sequentiellen mehrstufigen Pipeline kombiniert werden, um LLM-Ausgaben, d. h. Subsequent-Token-Vorhersagen, zu erzeugen.
Zunächst generiert das Modell Rohlogits für alle möglichen Token, wie oben beschrieben. Durch die Skalierung dieser Rohlogits kommt dann die Temperatur ins Spiel – beachten Sie, dass dies geschieht vor Die Softmax-Funktion wandelt sie in Wahrscheinlichkeiten um. Je nach Temperaturwert sieht die resultierende Verteilung gleichmäßiger (hohe Temperatur, mehr Unsicherheit) oder schärfer (niedrige Temperatur, höhere Sicherheit) aus.
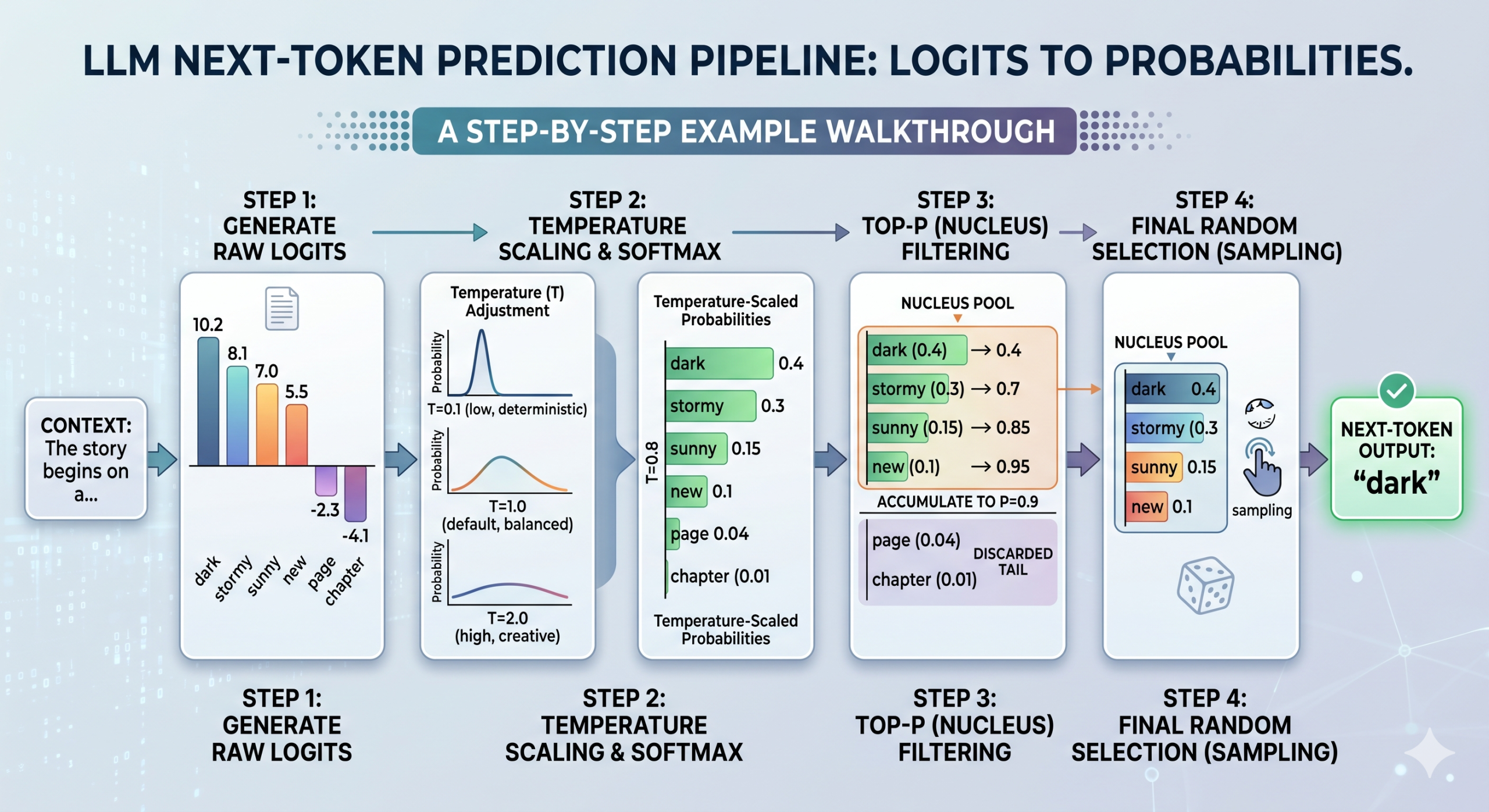
Komplettlösung zur Token-Auswahl basierend auf Logits, Temperatur und High-P
Sobald die skalierten Logits in Wahrscheinlichkeiten umgewandelt wurden, wird High-P angewendet, um die resultierende Verteilung zu filtern und kumulative Wahrscheinlichkeiten zu berechnen, um nur einen Kern-„Kernpool“ der wahrscheinlichsten Token beizubehalten (siehe Schritt 3 im Bild oben). Schließlich führt das Modell zufällige Stichproben aus diesem Pool durch, um den nächsten Token auszuwählen.
Schlussbemerkungen
Nachdem wir nun den statistischen Prozess hinter der Token-Auswahl in LLMs entmystifiziert haben, ist es nützlich zu überlegen, wie Werte für Temperatur und High-P in der Praxis ausgewählt werden. Als Entwickler möchten Sie für Ihren Anwendungsfall die richtige Steadiness zwischen Vorhersehbarkeit und Kreativität definieren. Für sachliche, hochriskante Szenarien wie Codierung oder rechtliche Analysen sind eine niedrige Temperatur und ein strengeres High-P ratsam – z t=0.1 Und p=0.5 – was zu hoch deterministischen Modellantworten führt. Für kreative Bereiche wie die Generierung von Gedichten oder Brainstorming ermöglichen eine höhere Temperatur und High-p, wie z. B. t=0,8 und p=0,95, eine größere Auswahl an Kandidaten-Tokens im Auswahlpool.