Der Mythos der Datenzentralisierung: Warum Transformation eine kontrollierte Dezentralisierung erfordert
Unternehmen geben Millionen für Lagerhäuser, Lakehouses und Governance-Ebenen aus und fragen sich dann, warum Entscheidungen immer noch durch Ausschüsse und Ticketwarteschlangen erfolgen. Eine größere Plattform behebt selten ein langsames Geschäft. Der Engpass liegt darin, wer auf die Daten reagieren kann, und nicht darin, wo die Daten gespeichert sind.
Zentralisierte Daten lösen Infrastrukturprobleme, keine organisatorischen
Zentralisierte Datenplattformen lösen echte Probleme. Gartner definiert Daten-Governance so, dass sie Eigentum, Verwaltung, Richtlinien, Requirements, Qualität, Sicherheit, Datenschutz, Lebenszyklusmanagement, Instruments und Compliance umfasst und eine starke Governance mit höherer Genauigkeit, schnelleren Entscheidungen und geringerem Risiko verbindet. Gemäß Artikel 30 der DSGVO sind Verantwortliche und Auftragsverarbeiter verpflichtet, Aufzeichnungen über Verarbeitungsaktivitäten zu führen und diese auf Anfrage den Aufsichtsbehörden vorzulegen, sodass geregelte Dokumentationen und Prüfpfade tatsächlich von Bedeutung für die Einhaltung der Vorschriften sind. Ein geregeltes Supply-of-Reality-Modell kann auch dazu führen, dass die Finanzberichterstattung weniger fragmentiert wird, da Finanz- und Rechtsteams mit gemeinsamen Definitionen und überprüfbaren Zugriffskontrollen arbeiten und nicht mit verstreuten regionalen Tabellenkalkulationen. Keine Arbeit allein bringt eine einzige Entscheidung schneller voran.
Eine Einzelhandelskette kann Verkaufs-, Bestands- und Kundendaten in einem Lakehouse zentralisieren und einen Regionalmanager trotzdem drei Wochen auf einen benutzerdefinierten Bericht warten lassen. Der konsolidierte Speicher der Plattform. Das Urteil wurde dadurch nicht gefestigt.
Am schnellsten wird die Lücke in den Genehmigungswarteschlangen sichtbar. Die 2025 State of Analytics-Studie von Sisense, die mit UserEvidence unter mehr als 500 Befragten durchgeführt wurde, ergab, dass 76 Prozent eine Geschäftsentscheidung getroffen hatten, ohne die verfügbaren Daten zu konsultieren, weil der Zugriff darauf zu schwierig conflict. Ein Lager conflict nicht der Grund für die Entscheidung, Daten zu überspringen. Die Genehmigungskette vor dem Lager tat es.
Transformation erfordert, dass Daten näher an Entscheidungen heranrücken
Vertriebs-, Produkt-, Finanz-, Betriebs- und Risikoteams benötigen zeitnahen Zugriff auf relevante Daten und nicht letztendlich Zugriff auf alle Daten. Ein Vertriebsmitarbeiter, der das Abwanderungsrisiko vor einem Verlängerungsanruf prüfen kann, arbeitet anders als jemand, der ein Ticket einreicht und wartet. Ein Werksleiter, der Ertragsdaten in Echtzeit abrufen kann, erkennt einen Defekt, bevor eine Lieferung ausgeht, anstatt ihn in einer Obduktion zu lesen.
Geschwindigkeitsmischungen. IBM hat es deutlich zum Ausdruck gebracht: Verzögerungen beim Zugriff auf Geschäftsdaten von ein bis vier Wochen verlangsamen die Entscheidungsgeschwindigkeit, untergraben das Vertrauen und bremsen KI-Initiativen aus. Vier Wochen reichen für einen Mitbewerber aus, um zuerst die Funktion auszuliefern, das Konto zu schließen oder den Fehler zu beheben.
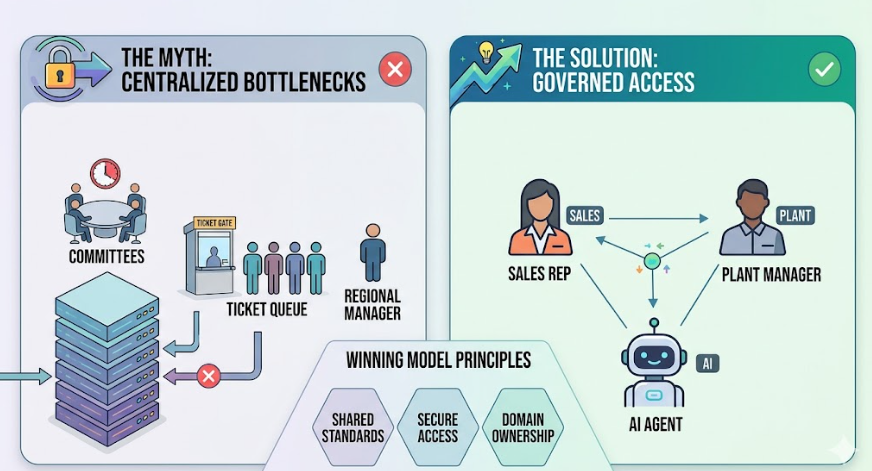
Der direkte Zugriff auf die Datenbank für jedes Staff ist nicht das Ziel. Das Ziel ist ein schneller, kontrollierter Weg zu den spezifischen Daten, von denen die Entscheidungen jedes Groups abhängen. Ein zentrales Staff, das jede Anfrage manuell genehmigt, kann nicht mit einem Unternehmen mithalten, das täglich Hunderte kleiner Entscheidungen trifft.
Dezentralisierung ohne Governance führt zum Datenchaos
Dezentralisierung löst das Geschwindigkeitsproblem und schafft schnell ein neues. Wenn jedes Staff Kennzahlen ohne gemeinsame Definitionen erstellt, melden Finanz- und Marketingabteilungen in derselben Vorstandssitzung letztendlich zwei unterschiedliche Umsatzzahlen. Niemand traut beiden Zahlen, und das zentrale Staff verbringt das nächste Quartal damit, Tabellenkalkulationen abzugleichen, anstatt etwas Neues zu erstellen.
Das Datenschutzrisiko wächst in gleicher Weise. Ein regionales Staff, das Kundendaten in einer lokalen Tabelle speichert, ohne jeglichen Prüfpfad, sorgt für eine Offenlegung, die kein Lager jemals zuvor hatte. Eine lockere Dezentralisierung sieht nicht lange nach Geschwindigkeit aus. Es sieht aus wie doppelte Berichte, widersprüchliche Dashboards und ein Compliance-Beauftragter, der fragt, wer den Zugriff auf was genehmigt hat.
Die Lösung besteht nicht darin, auf Zentralisierung zurückzugreifen. Die Lösung liegt in der geregelten Dezentralisierung: Domänenteams erhalten Autorität und Geschwindigkeit, während eine zentrale Funktion die Requirements festlegt, die jeder erfüllen muss. Zugang ohne Verantwortung ist keine Transformation. Das Risiko geht schneller voran.
Der Aufstieg des Information-Mesh-Denkens
Information Mesh, das Framework, das Thoughtworks laut Zhamak Dehghani erstmals in einem Artikel aus dem Jahr 2019 dargelegt hat, basiert auf vier Prinzipien: Domänenbesitz, Daten als Produkt, Self-Service-Dateninfrastruktur und föderierte Computerverwaltung. Domänenteams verwalten ihre Daten als Produkt. Eine Vertriebsdomäne verwaltet und veröffentlicht Verkaufsdaten. Eine Success-Area verwaltet Versanddaten. Jedes verfügt über definierte Qualitätsstandards und einen benannten Datenverwalter. Ein zentrales Plattformteam erstellt die Self-Service-Infrastruktur, nicht die Berichte: Identität, Zugriffskontrollen, Interoperabilitätsstandards und einen gemeinsamen Katalog.
In der Analyse von Thoughtworks vom Januar 2026 wird beschrieben, dass sich Information Mesh von einem Hype zu einer sogenannten hart erkämpften Reife entwickelt, wobei Unternehmen vor einem komplexen, aber erreichbaren soziotechnischen Wandel stehen und nicht vor dem Kauf einer weiteren Plattform. Die stärksten Rollouts haben ein gemeinsames Merkmal: echte domänengesteuerte Eigentümerschaft, keine umbenennten Organigramme. Eine Zahl der Gartner Information and Analytics Governance Survey 2021, die in der Datennetzanalyse immer noch häufig zitiert wird, ergab, dass nur 18 Prozent der Unternehmen über eine ausgereifte, unternehmensskalierte Daten- und Analyse-Governance verfügten. In der Praxis wird das Modell häufig hybrid: gemeinsame Plattformfunktionen und Governance-Requirements, die den Besitz auf Domänenebene unterstützen.
Netflix hat öffentlich eine Information-Mesh-Plattform beschrieben, die für die skalierte Übertragung und Verarbeitung von Daten über seine internen Systeme hinweg entwickelt wurde. Die Behauptung ist enger gefasst als ein lehrbuchmäßiges Information-Mesh-Betriebsmodell, bei dem Domänenteams durchgängig verwaltete Datenprodukte veröffentlichen, zeigt aber, wie der verteilte Datenzugriff zu einem technischen Downside wird, sobald ein Unternehmen auf Unternehmensebene agiert. Das Muster ist wichtiger als jedes einzelne Unternehmen. Die Autorität verlagert sich dorthin, wo der Kontext lebt, und eine zentrale Gruppe setzt die Interoperabilitätsstandards durch, die die einzelnen Teile zusammenhalten.
KI macht den dezentralen Datenzugriff dringlicher
Agentische KI erhöht den Einsatz erheblich. Gartner prognostiziert, dass aufgabenspezifische KI-Agenten bis 2026 in 40 Prozent der Unternehmensanwendungen auftauchen werden, gegenüber weniger als 5 Prozent im Jahr 2025, und jeder Agent benötigt kontrollierten Zugriff auf aktuelle, vertrauenswürdige Daten, die über CRM-, ERP-, Assist-, Abrechnungs- und Produktnutzungssysteme verteilt sind. Ein Modell, das mit einem veralteten Auszug aus dem Lager-Snapshot des letzten Quartals trainiert wurde, wird mit Sicherheit eine falsche Antwort liefern.
Unternehmen, die jede KI-Datenanfrage durch dieselbe Genehmigungswarteschlange leiten, was menschliche Analysten frustriert, werden an dieselbe Wand stoßen, nur schneller und mit höherem Risiko. Ein Vertriebsanalyst kann zwei Wochen auf einen Bericht warten. Ein in einen Reside-Kundenworkflow eingebetteter KI-Agent kann nicht zwei Wochen auf irgendetwas warten. Unternehmen, die nutzbare Daten hinter zentralisierten Genehmigungstoren aufbewahren, werden Schwierigkeiten haben, wenn aufgabenspezifische KI-Agenten von der frühen Einführung in gängige Unternehmensanwendungen übergehen.
Durch die gesteuerte Dezentralisierung erhalten KI-Systeme das, was sie brauchen: definierte Zugriffsgrenzen, klare Dateneigentümerschaft und einen Weg zu Betriebsdaten ohne einen menschlichen Gatekeeper für jede Abfrage. Überspringen Sie die Governance, und dieselben Agenten erstellen einen neuen Fehlermodus. Sie schöpfen aus inkonsistenten Quellen und verstärken das Chaos, das die unkontrollierte Dezentralisierung bereits unter menschlichen Groups hervorruft.
Das neue Modell besteht aus zentralisierten Requirements und dezentraler Ausführung
Das erfolgreiche Betriebsmodell liegt in keinem Extrem. Es geht nicht darum, dass jeder Datensatz auf einer Plattform landet, und nicht jedes Staff baut auf, was es will. Es kombiniert gemeinsame Governance, gemeinsame Definitionen, sicheren Zugriff und Besitz auf Domänenebene mit zentralen Groups, die Plattformen erstellen, anstatt Tickets zu bearbeiten.
Die Aufgabe eines zentralen Datenteams verlagert sich vom Gatekeeper zum Enabler: Definieren Sie die Requirements, bauen Sie die Zugriffsschicht auf, zertifizieren Sie die Datenprodukte und gehen Sie aus dem Weg. Die Aufgabe eines Domänenteams besteht darin, seine Daten zu verwalten, die Requirements einzuhalten und den erlangten Zugriff zu nutzen. Die Verantwortlichkeit muss auf jeder Seite explizit sein, sonst kollabiert das Modell wieder in Silos oder Chaos.
Die digitale Transformation beginnt nicht, wenn jeder Datensatz auf einer Plattform landet. Es beginnt, wenn vertrauenswürdige Daten die Menschen, Systeme und KI-Instruments erreichen, die tägliche Entscheidungen treffen. Zentralisierung bildet das Fundament, und kontrollierte Dezentralisierung verwandelt das Fundament in Bewegung. Unternehmen, die den Datenstandort immer noch als die gesamte Strategie betrachten, werden ein größeres Lager weiterhin mit einem schnelleren Unternehmen verwechseln.