Die technische Abteilung hasst Sie im Second. Das tun sie wirklich. Letzten Dienstag saß ich in einer Besprechung mit einem leitenden Systemarchitekten eines großen SaaS-Unternehmens. Er sah völlig besiegt aus. Er rief seine Staging-Umgebung auf und zeigte auf eine völlig kaputte Webseite. Das CSS battle völlig zerstört. Die Seitenleiste schwebte in der Mitte des Bildschirms. Der Fußzeilentext battle umfangreich.
Er sah mich an und seufzte. Der Advertising and marketing Die Mannschaft hatte erneut zugeschlagen.
Ein Junior-Vermarkter entdeckte eine einfache Chat-Oberfläche. Sie dachten, sie hätten absolutes Gold gefunden. Sie erstellten einen dreitausend Worte umfassenden Leitfaden zur Datenarchitektur. Sie kopierten die rohe Maschinenausgabe. Sie haben es direkt in das Unternehmens-CMS eingefügt. Sie klicken auf „Veröffentlichen“. Sie gingen zum Mittagessen und dachten, sie seien ein Genie.
Sie haben die Inhaltsproduktion nicht gelöst. Sie haben eine digitale Zeitbombe gebaut.
Meine heiße Meinung ist, kreative Vermarkter und Hype-Händler gleichermaßen zu verärgern. Das Generieren von Wörtern ist keine Fähigkeit mehr. Textual content ist jetzt völlig wertlos. Rohe Chat-Protokolle direkt in eine Stay-Datenbank zu pumpen, ist reiner Systemmissbrauch. Ihre Administratorrechte müssen sofort widerrufen werden.
Sie stellen Ihren Benutzern fehlerhaften Code zur Verfügung. Du bist Fütterung der Suchmaschinen-Crawler mit digitalem Giftmüll. Sie müssen aufhören, sich wie ein Zeitschriftenredakteur zu verhalten, und stattdessen anfangen, sich wie ein Datenbankadministrator zu verhalten.
Der Rohtextwahn
Wir müssen unsere Denkweise über Suchmaschinen völlig umstellen. Google ist kein menschlicher Bibliothekar, der einen Roman liest. Suchbots lesen keine englische Prosa. Sie analysieren Dokumentobjektmodelle. Sie bewerten Knotenhierarchien.
Vermarkter leiden unter einer massiven Wahnvorstellung. Sie glauben, dass eine riesige Wand aus grammatikalisch korrektem Textual content ein wertvolles Intestine ist. Das ist es nicht.
Wenn ein Crawler-Bot auf eine bestimmte URL trifft, erwartet er eine perfekt verschachtelte Architekturhierarchie. Es sucht nach einem einzelnen H1-Tag, um die Kernentität festzulegen. Es sucht nach verschachtelten H2- und H3-Tags, um eine thematische Karte der Seite zu erstellen. Es möchte saubere HTML-Tabellen sehen, die komplexe Daten darstellen. Es erfordert ordnungsgemäße ungeordnete Hear mit tatsächlichen Listenelement-Tags.
Diese Elemente sind keine dekorativen Optionen. Sie sind semantische Marker. Sie beweisen dem Algorithmus, dass die Seite organisiert, umfassend und für den Benutzernutzen konzipiert ist.
Wenn Ihr automatisierter Workflow nur dreißig unformatierte Absatz-Tags auf einer Seite ablegt, springt der Crawler-Bot zurück. Es wird davon ausgegangen, dass der Inhalt völlig wertlos ist. Der Algorithmus markiert die gesamte Domäne als Ausgabe mit geringer Qualität. Die Seite ist tatsächlich nicht im Suchindex vorhanden.
Sie können eine Million Wörter professional Tag generieren. Wenn ihnen die strukturelle Syntax fehlt, sind Sie völlig unsichtbar.
Halluzination der Architektur
Schauen wir uns die eigentliche Mechanik generativer Modelle an. Sie sind prädiktive Textual content-Engines. Sie berechnen Token-Wahrscheinlichkeiten. Sie sind keine Frontend-Entwickler.
Sie bitten ein Standardmodell, einen umfassenden Vergleich von Cloud-Speicheranbietern zu verfassen. Es spuckt den Textual content aus. In Ihrem Terminalfenster sieht es völlig intestine aus. Die technischen Punkte sind überraschend genau.
Aber dann leiten Sie diese rohe Nutzlast direkt in Ihre Anwendung weiter. Es entsteht totales Chaos.
Generative Modelle halluzinieren ständig HTML. Sie vergessen, div-Tags zu schließen. Sie fügen zufällig seltsame Markdown-Artefakte mitten in einen Satz ein. Sie beschließen, einen ganz normalen Absatz ohne jeglichen logischen Grund in einen vorformatierten Textblock zu packen.
Ihr Frontend empfängt diese beschädigte Nutzlast. Ihre sorgfältig gestaltete globale CSS-Vererbung bricht völlig zusammen. Die Zeilenhöhe spielt verrückt. Die Polsterung verschwindet vollständig. Ein zufälliges, nicht geschlossenes Tag blutet aus dem Artikelcontainer und zerstört Ihr gesamtes Navigationsmenü. Die Seite wirkt wie eine absolute Katastrophe.
Sie haben fünfzigtausend Greenback für den Aufbau einer blitzschnellen Unternehmenswebsite ausgegeben. Dann lassen Sie eine Wahrscheinlichkeitsmaschine unstrukturierten Textual content über die gesamte Benutzeroberfläche spucken.
Das Middleware-Mandat
Sie können der generativen Rohausgabe nicht vertrauen. Immer.
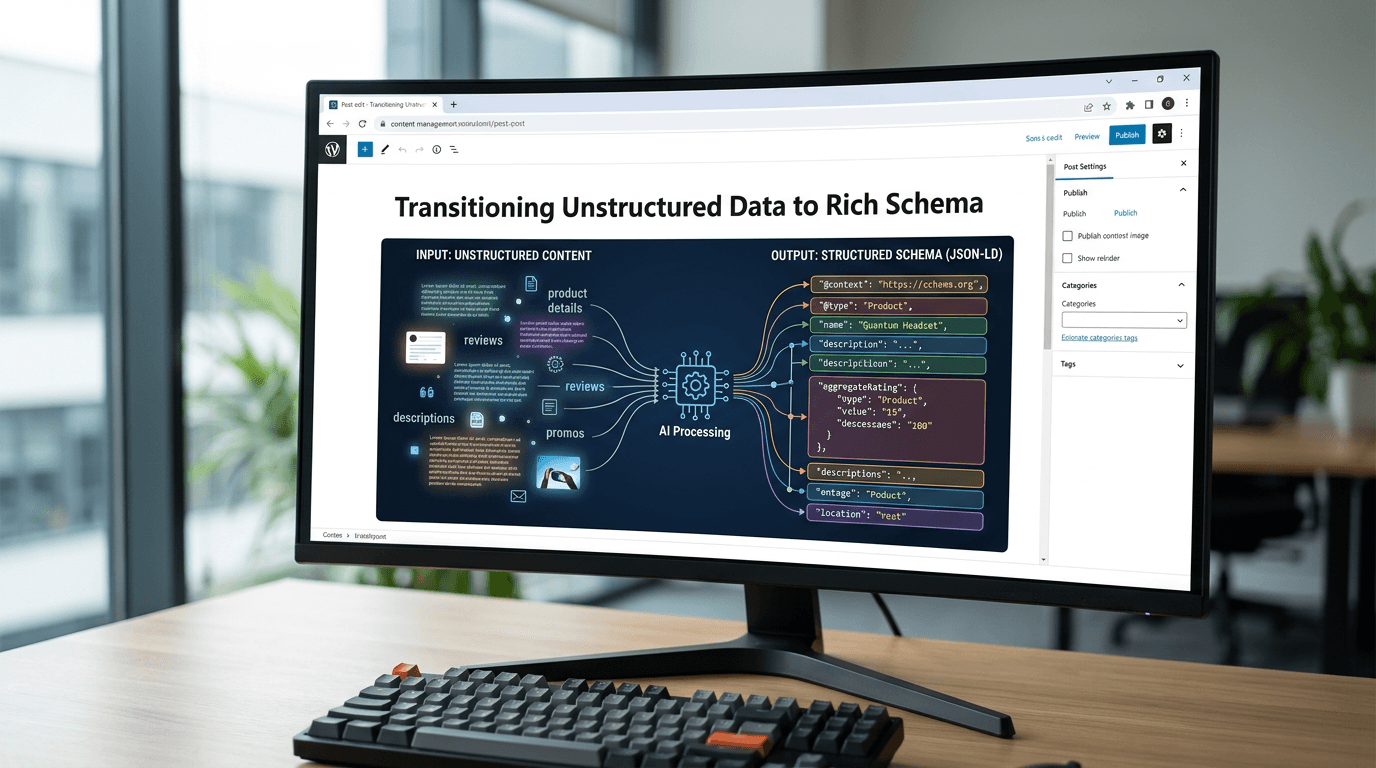
Sie brauchen strenge architektonische Grenzen. Hier scheitern die Skript-Kiddies und die eigentlichen Systemarchitekten gewinnen. Sie müssen einen strikten Compiler zwischen dem Rohsprachmodell und Ihrer Produktionsdatenbank einfügen.
Sie benötigen eine Orchestrierungsebene. Genau aus diesem Grund verwenden Elite-Datenteams ein dediziertes KI-Artikelautor als ihre obligatorische Middleware.
Sie fragen die Maschine nicht nur nach Worten. Sie fordern ein bestimmtes Strukturschema. Sie zwingen die Ausgabe in eine strikte HTML-Type, bevor sie jemals Ihre Serverumgebung berührt. Die Middleware fungiert als rücksichtsloser Formatierungsvalidator. Wenn die Daten nicht genau in das Schema passen, werden sie nicht veröffentlicht. So einfach ist das.
Definieren des Datenschemas
Lassen Sie uns über die tatsächlichen Bereitstellungsmechanismen sprechen. Wie zwingt man eine kreative Maschine in eine streng analytische Field?
Sie legen die genauen Parameter innerhalb der Orchestrierungsebene fest, bevor ein einzelner Token generiert wird. Sie benötigen einen Preisvergleich für Ihren neuen Softwareratgeber. Sie definieren die Tabellenüberschriften explizit in Ihrer Eingabeaufforderungslogik. Sie definieren die genaue Syntax der Aufzählungsliste, die für die Funktionsaufschlüsselung erforderlich ist. Sie legen die Überschriftenhierarchie fest.
Die Engine verarbeitet Ihre Anfrage. Es generiert den Rohtext. Doch dann geschieht die Magie. Es kompiliert es.
Es entfernt das halluzinierte Inline-Styling. Es entfernt die seltsamen Sternchen und Hashes. Es verpackt die Rohdaten in makelloses, semantisches HTML. Die verschachtelten Überschriften-Tags werden mathematisch erstellt. Es formatiert die Tabelle mithilfe strenger Codeblöcke.
Erst dann wird die Nutzlast über die API an Ihr Headless-Setup oder Ihr herkömmliches CMS übertragen.
Ihre Datenbank erhält reine, saubere Daten. Ihr Frontend erhält einwandfreien Code. Ihr statischer Construct läuft perfekt, ohne einen einzigen Fehler auszulösen. Ihr CSS gilt genau wie beabsichtigt. Sie behalten die vollständige visuelle Kontrolle und skalieren gleichzeitig Ihre Veröffentlichungsgeschwindigkeit bis ins Unendliche.
Die Mathematik der Indexierung
Sie spielen mit scharfer Munition, wenn Sie Datenbankeinträge automatisieren. Eine einzige fehlerhafte Schleife in Ihrem Bereitstellungsskript kann im Schlaf fünfhundert fehlerhafte, unformatierte Seiten veröffentlichen.
Sie wachen mit einer zerstörten Area-Bewertung und einer riesigen Serverrechnung auf.
Suchmaschinen suchen aktiv nach Lazy Automation. Sie bestrafen unstrukturierte Datendumps sofort. Um den modernen Algorithmus zu überleben, müssen Sie die genauen technischen Einschränkungen verstehen, die für eine sichere Bereitstellung erforderlich sind. Sie sollten dies genau studieren Web optimization-Leitfaden für AI-Artikelautoren im Augenblick. Es schlüsselt die genauen Validierungsregeln auf, die Sie implementieren müssen. Es zeigt Ihnen, wie Sie die Rohdatengenerierung von der endgültigen HTML-Kompilierung trennen.
Behandeln Sie Ihre automatisierte Content material-Pipeline genau wie ein Finanzzahlungs-Gateway. Alles validieren. Desinfizieren Sie jeden einzelnen Eingang. Vertrauen Sie niemals der Rohantwort des Servers.
Wenn Ihre Datennutzlast umfangreiche Formatierungselemente enthält, validiert der Such-Crawler das Seitendienstprogramm sofort. Es belohnt das strukturierte Datenschema. Es indiziert die URL innerhalb von Stunden statt Wochen. Es verteilt die Rating-Gerechtigkeit reibungslos über Ihre gesamte Area.
Aufbau der internen Topologie
Hier liegt ein weiterer massiver Fehler bei der Rohskriptautomatisierung vor. Es entstehen digitale Geisterstädte.
Ein Skript, das isolierte Textblöcke an eine Datenbank weiterleitet, erzeugt unzusammenhängende Inseln. Ein Sprachmodell kennt die Topologie Ihrer vorhandenen Web site überhaupt nicht. Es ist nicht bekannt, dass Sie vor drei Wochen einen umfangreichen Leitfaden zur prädiktiven Analyse veröffentlicht haben. Es kann das Bindegewebe nicht aufbauen.
Eine isolierte Webseite ist ein totes Intestine. Suchmaschinen-Spider benötigen Hyperlink-Rails, um sich durch Ihre Web site zu bewegen. Wenn ein Bot keinen fest codierten Hyperlink finden kann, der auf Ihren neuen Artikel verweist, verlässt er den Server. Die Seite verstaubt in Ihrer Datenbank.
Ihre Middleware muss die Topologie nativ abbilden. Es muss die Diagrammdatenbank verwalten.
Wenn der Compiler ein neues Tutorial zu Enterprise-Intelligence-Dashboards generiert, muss er Ihre Stay-Datenbank automatisch scannen. Es muss semantische Beziehungen identifizieren. Es muss strenge HTML-Ankertags einfügen, die direkt auf Ihren älteren relevanten Inhalt verweisen.
Dadurch entsteht ein strukturelles Gurtband. Es bindet den neuen Knoten an das bestehende Netzwerk. Dadurch wird der Suchmaschinen-Crawler gezwungen, den gesamten Cluster gleichzeitig zu indizieren. Sie hören auf, zufällige Seiten zu veröffentlichen. Sie beginnen mit der Erstellung eines lückenlosen Wissensgraphen.
Ersetzen Sie die redaktionelle Aufblähung
Denken Sie an die schiere finanzielle Hebelwirkung, die diese Pipeline Ihrem Unternehmen verschafft.
Führungskräfte in Unternehmen sind ständig auf der Suche nach einer Reduzierung der Betriebsabfälle. Traditionelle Content material-Advertising and marketing-Abteilungen sind langsam. Sie sind unglaublich teuer. Sie sind schwer zu messen. Ein Marketingleiter zahlt einem Group menschlicher Redakteure ein Vermögen, nur um die Formatierung zu korrigieren, Hyperlinks zu überprüfen und die grundlegende Markenkonformität sicherzustellen.
Sie umgehen dieses Aufblähen vollständig. Sie ersetzen den menschlichen Bearbeitungszyklus durch einen strukturellen Linter.
Ihre Kosten der verkauften Waren sinken auf nahezu Null. Ihre Erfüllungsgeschwindigkeit wird augenblicklich. Sie können jeden einzelnen obskuren technischen Suchbegriff in Ihrer Branche abdecken. Wenn ein Unternehmenskäufer nach einem unbekannten Software program-Integrationsfehler sucht, findet er Ihre Web site. Sie lesen eine perfekt formatierte technische Aufschlüsselung. Sie sehen Ihre Schnellladeoberfläche. Sie vertrauen sofort Ihrer Autorität.
Ihre Konkurrenten werden keine Ahnung haben, wie Sie so viele Marktanteile erobern. Sie gehen davon aus, dass Sie ein riesiges Group technischer Redakteure eingestellt haben. Sie werden nie merken, dass es nur Sie und eine hochentwickelte Kompilierungs-Engine sind.
Das Ausführungsultimatum
Die digitale Wirtschaft spaltet sich in zwei unterschiedliche Klassen von Betreibern.
Auf der einen Seite stehen die Schreibkräfte. Sie kopieren rohe Chat-Ausgaben und fügen sie in Wealthy-Textual content-Editoren ein. Sie kämpfen mit kaputten Layouts. Sie beobachten die Flatline ihres organischen Traffics. Sie fragen sich, warum die Suchmaschinen sich weigern, ihre riesigen Wände aus unstrukturiertem Textual content zu indizieren. Sie gehen völlig pleite.
Auf der anderen Seite stehen die Architekten. Sie verstehen, dass Inhalte nur ein struktureller Vermögenswert sind. Sie behandeln automatisierte Veröffentlichungen genau wie eine Softwarebereitstellungsschleife. Sie gießen den semantischen Konkreten programmatisch ein. Sie erzwingen strenge Datenschemata. Sie bauen riesige Netzwerke perfekt formatierter Seiten auf. Sie erbeuten das gesamte tatsächliche Geld auf dem Markt.
Sie müssen eine ganz klare Entscheidung hinsichtlich Ihrer internen Architektur treffen.
Sie können Ihr einfaches Wochenendskript weiterhin ausführen. Sie können weiterhin zulassen, dass ein rohes Sprachmodell unstrukturierten Code in Ihre schöne Datenbank spuckt. Sie können Ihre Staging-Umgebung weiterhin beschädigen.
Oder Sie können einen Compiler erstellen. Sie können strikte HTML-Schemas erzwingen. Sie können Ihr Unternehmens-CMS in eine undurchdringliche Festung strukturierter Daten verwandeln. Sie können aufhören, sich wie ein Vermarkter zu benehmen. Sie können anfangen, sich wie ein Ingenieur zu verhalten.