
Große Sprachmodelle benötigen riesige menschliche Datensätze. Was passiert additionally, wenn das Modell seinen gesamten Lehrplan selbst erstellen und sich selbst den Umgang mit Werkzeugen beibringen muss? Ein Forscherteam von UNC-Chapel Hill, Salesforce Analysis und der Stanford College stellt „Agent0“ vor, ein vollständig autonomes Framework, das leistungsstarke Agenten ohne externe Daten durch mehrstufige Co-Evolution und nahtlose Instrument-Integration entwickelt
Agent0 zielt auf mathematisches und allgemeines Denken ab. Es zeigt, dass eine sorgfältige Aufgabengenerierung und werkzeugintegrierte Rollouts ein Basismodell über seine ursprünglichen Fähigkeiten hinaus in zehn Benchmarks bringen können.
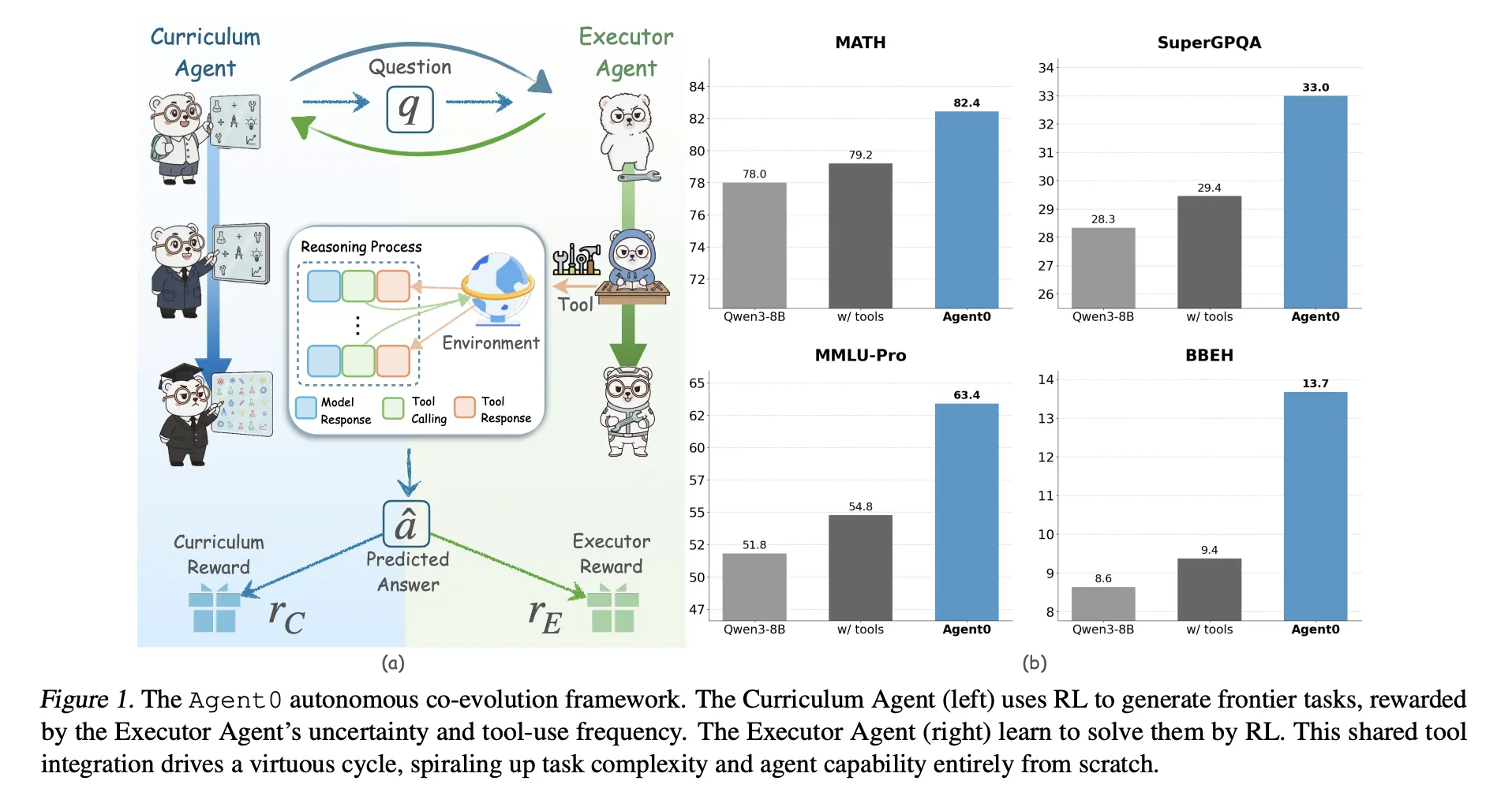
Zwei Agenten aus einem Basismodell
Agent0 beginnt beispielsweise mit einer Basisrichtlinie π_base Qwen3 4B Foundation oder Qwen3 8B Foundation. Es klont diese Richtlinie in:
- A Lehrplanagent πθ, das Aufgaben generiert,
- ein Testamentsvollstrecker πϕ, das diese Aufgaben mit einem Python-Instrument löst.
Das Coaching erfolgt in Iterationen mit zwei Phasen professional Iteration:
- Lehrplanentwicklung: Der Lehrplanagent generiert einen Stapel von Aufgaben. Für jede Aufgabe prüft der Ausführende mehrere Antworten. Eine zusammengesetzte Belohnung misst, wie unsicher der Ausführende ist, wie oft er das Instrument nutzt und wie vielfältig die Cost ist. πθ wird mit aktualisiert Gruppenrelative Richtlinienoptimierung (GRPO) diese Belohnung nutzen.
- Weiterentwicklung des Testamentsvollstreckers: Der geschulte Curriculum-Agent ist eingefroren. Es generiert einen großen Pool an Aufgaben. Agent0 filtert diesen Pool, um nur Aufgaben in der Nähe der Fähigkeitsgrenze des Ausführenden zu behalten, und schult den Ausführenden dann für diese Aufgaben mithilfe eines mehrdeutigkeitsbewussten RL-Ziels namens Ambiguity Dynamic Coverage Optimization (ADPO).
Diese Schleife erzeugt einen Suggestions-Zyklus. Da der Ausführende durch die Verwendung des Code-Interpreters stärker wird, muss der Lehrplan komplexere, werkzeugabhängige Probleme generieren, um seinen Nutzen hoch zu halten.

Wie der Lehrplanagent Aufgaben bewertet?
Die Lehrplanbelohnung kombiniert drei Signale:
Unsicherheitsbelohnung: Für jede generierte Aufgabe x prüft der Ausführende ok Antworten und stimmt mehrheitlich für eine Pseudoantwort ab. Die Selbstkonsistenz p̂(x) ist der Anteil der Antworten, die dieser Mehrheit zustimmen. Die Belohnung ist maximal, wenn p̂ nahe bei 0,5 liegt, und niedrig, wenn die Aufgaben zu einfach oder zu schwer sind. Dies fördert Aufgaben, die für den aktuellen Ausführenden herausfordernd, aber dennoch lösbar sind.
Belohnung für Werkzeugnutzung: Der Executor kann mithilfe von einen Sandbox-Code-Interpreter auslösen python markiert und erhält Ergebnisse, die als markiert sind output. Agent0 zählt die Anzahl der Werkzeugaufrufe in einer Flugbahn und gibt eine skalierte, begrenzte Belohnung aus, wobei die Obergrenze C in Experimenten auf 4 festgelegt ist. Dies begünstigt Aufgaben, die tatsächlich Instrument-Aufrufe erfordern, statt reines Kopfrechnen.
Wiederholungsstrafe: Innerhalb jedes Lehrplanstapels misst Agent0 die paarweise Ähnlichkeit zwischen Aufgaben mithilfe einer BLEU-basierten Distanz. Aufgaben werden geclustert und ein Strafzeitraum erhöht sich mit der Clustergröße. Dadurch wird verhindert, dass der Lehrplan viele Beinahe-Duplikate erzeugt.
Eine zusammengesetzte Belohnung multipliziert eine Formatprüfung mit einer gewichteten Summe aus Unsicherheit und Instrument-Belohnungen abzüglich der Wiederholungsstrafe. Dieser zusammengesetzte Wert wird in GRPO eingespeist, um πθ zu aktualisieren.
Wie der Testamentsvollstrecker aus lauten Selbstbezeichnungen lernt?
Der Testamentsvollstrecker wird ebenfalls mit GRPO geschult, jedoch mit Multiturn-, werkzeugintegrierten Trajektorien und Pseudo-Labels anstelle von Floor-Reality-Antworten.
Aufbau von Grenzdatensätzen: Nach der Lehrplanschulung in einer Iteration generiert der eingefrorene Lehrplan einen großen Kandidatenpool. Für jede Aufgabe berechnet Agent0 die Selbstkonsistenz p̂(x) mit dem aktuellen Ausführenden und behält nur Aufgaben bei, bei denen p̂ in einem informativen Bereich liegt, beispielsweise zwischen 0,3 und 0,8. Dies definiert einen herausfordernden Grenzdatensatz, der triviale oder unmögliche Probleme vermeidet.
Integrierte Rollouts mit mehreren Drehwerkzeugen: Für jede Grenzaufgabe generiert der Ausführende eine Flugbahn, die Folgendes verschachteln kann:
- Token für natürliches Denken,
pythonCodesegmente,outputWerkzeug-Suggestions.
Die Generierung pausiert, wenn ein Instrument-Aufruf erscheint, und führt den Code in einem darauf aufbauenden Sandbox-Interpreter aus VeRL-Instrumentund wird dann je nach Ergebnis fortgesetzt. Die Flugbahn endet, wenn das Modell im Inneren eine endgültige Antwort liefert {boxed ...} Tags.
Eine Mehrheitsentscheidung über die erfassten Trajektorien hinweg definiert ein Pseudo-Label und eine Endbelohnung für jede Trajektorie.
ADPO, mehrdeutigkeitsbewusster RL: Normal-GRPO behandelt alle Proben gleich, was instabil ist, wenn Bezeichnungen aus Mehrheitsabstimmungen über mehrdeutige Aufgaben stammen. ADPO modifiziert GRPO auf zwei Arten unter Verwendung von p̂ als Mehrdeutigkeitssignal.
- Es skaliert den normalisierten Vorteil mit einem Faktor, der mit der Selbstkonsistenz zunimmt, sodass Trajektorien aus Aufgaben mit geringem Vertrauen weniger beitragen.
- Es legt eine dynamische Obergrenze für das Wichtigkeitsverhältnis fest, die von der Selbstkonsistenz abhängt. Die empirische Analyse zeigt, dass das feste obere Clipping hauptsächlich Token mit geringer Wahrscheinlichkeit betrifft. ADPO lockert diese Grenze adaptiv, was die Erkundung unsicherer Aufgaben verbessert, wie durch das visualisiert heraufgestufte Token-Wahrscheinlichkeit Statistiken.

Ergebnisse zum mathematischen und allgemeinen Denken
Darüber hinaus wird Agent0 implementiert VeRL und ausgewertet Qwen3 4B Foundation Und Qwen3 8B Foundation. Es verwendet einen Sandbox-Python-Interpreter als einziges externes Instrument.
Das Forschungsteam bewertet anhand von zehn Benchmarks:
- Mathematische Argumentation: AMC, Minerva, MATH, GSM8K, Olympiad Bench, AIME24, AIME25.
- Allgemeine Begründung: SuperGPQA, MMLU Professional, BBEH.
Sie melden „go@1“ für die meisten Datensätze und „imply@32“ für AMC- und AIME-Aufgaben.
Für Qwen3 8B FoundationAgent0 erreicht:
- Mathe-Durchschnitt 58,2 gegenüber 49,2 für das Basismodell,
- allgemeiner Gesamtdurchschnitt 42,1 gegenüber 34,5 beim Basismodell.
Agent0 verbessert sich auch gegenüber starken datenfreien Baselines wie z R Null, Absoluter Nullpunkt, SPIRAL Und Sokratischer Nullpunktsowohl mit als auch ohne Werkzeug. Beim Qwen3 8B übertrifft er R Zero um 6,4 Prozentpunkte und Absolute Zero um 10,6 Punkte im Gesamtdurchschnitt. Es übertrifft auch Socratic Zero, das auf externen OpenAI-APIs basiert.
Über drei Co-Evolution-Iterationen hinweg steigt die durchschnittliche Mathematikleistung auf Qwen3 8B von 55,1 auf 58,2 und auch das allgemeine Denken verbessert sich professional Iteration. Dies bestätigt eher eine stabile Selbstverbesserung als einen Zusammenbruch.
Qualitative Beispiele zeigen, dass sich Lehrplanaufgaben von grundlegenden Geometriefragen zu komplexen Problemen der Erfüllung von Randbedingungen entwickeln, während die Trajektorien des Ausführenden Begründungstext mit Python-Aufrufen mischen, um zu korrekten Antworten zu gelangen.
Wichtige Erkenntnisse
- Völlig datenfreie Co-Evolution: Agent0 eliminiert externe Datensätze und menschliche Anmerkungen. Zwei Agenten, ein Curriculum-Agent und ein Executor-Agent, werden von demselben Foundation-LLM initialisiert und entwickeln sich nur über Reinforcement Studying und ein Python-Instrument gemeinsam weiter.
- Grenzlehrplan aus Selbstunsicherheit: Der Lehrplanagent nutzt die Selbstkonsistenz und die Werkzeugnutzung des Ausführenden, um Aufgaben zu bewerten. Es lernt, Grenzaufgaben zu generieren, die weder trivial noch unmöglich sind und die explizit werkzeugintegriertes Denken erfordern.
- ADPO stabilisiert RL mit Pseudoetiketten: Der Ausführende ist mit Ambiguity Dynamic Coverage Optimization geschult. ADPO verringert die Gewichtung sehr mehrdeutiger Aufgaben und passt den Clipping-Bereich basierend auf der Selbstkonsistenz an, wodurch Aktualisierungen im GRPO-Stil stabil bleiben, wenn Belohnungen von Pseudo-Labels mit Mehrheitsabstimmung kommen.
- Kontinuierliche Fortschritte in Mathematik und allgemeinem Denken: Auf Qwen3 8B Base verbessert Agent0 die mathematischen Benchmarks von durchschnittlich 49,2 auf 58,2 und das allgemeine Denken von 34,5 auf 42,1, was relativen Zuwächsen von etwa 18 Prozent bzw. 24 Prozent entspricht.
- Übertrifft frühere Zero-Knowledge-Frameworks: In zehn Benchmarks übertrifft Agent0 frühere sich selbst entwickelnde Methoden wie R Zero, Absolute Zero, SPIRAL und Socratic Zero, einschließlich derjenigen, die bereits Instruments oder externe APIs verwenden. Dies zeigt, dass das Design der Co-Evolution plus Werkzeugintegration einen sinnvollen Schritt über frühere Einzelrunden-Selbstspielansätze hinaus darstellt.
Redaktionelle Anmerkungen
Agent0 ist ein wichtiger Schritt in Richtung praktisches, datenfreies Verstärkungslernen für werkzeugintegriertes Denken. Es zeigt, dass ein Foundation-LLM sowohl als Curriculum-Agent als auch als Executor-Agent fungieren kann und dass GRPO mit ADPO und dem VeRL-Instrument eine stabile Verbesserung gegenüber Pseudo-Labels mit Mehrheitsabstimmung bewirken kann. Die Methode zeigt auch, dass die werkzeugintegrierte Co-Evolution frühere Zero-Knowledge-Frameworks wie R Zero und Absolute Zero auf starken Qwen3-Basislinien übertreffen kann. Agent0 ist ein starkes Argument dafür, dass sich selbst entwickelnde, in Instruments integrierte LLM-Agenten zu einem realistischen Trainingsparadigma werden.
Schauen Sie sich das an PAPIER Und Repo. Schauen Sie sich gerne bei uns um GitHub-Seite für Tutorials, Codes und Notebooks. Sie können uns auch gerne weiter folgen Twitter und vergessen Sie nicht, bei uns mitzumachen 100.000+ ML SubReddit und Abonnieren Unser Publication. Warten! Bist du im Telegram? Jetzt können Sie uns auch per Telegram kontaktieren.

Michal Sutter ist ein Knowledge-Science-Experte mit einem Grasp of Science in Knowledge Science von der Universität Padua. Mit einer soliden Grundlage in statistischer Analyse, maschinellem Lernen und Datentechnik ist Michal hervorragend darin, komplexe Datensätze in umsetzbare Erkenntnisse umzuwandeln.