
Wie erhält man Argumente auf GPT-5-Ebene für reale Workloads mit langem Kontext und Werkzeugnutzung, ohne auf die quadratische Aufmerksamkeit und die GPU-Kosten zu achten, die diese Systeme normalerweise unpraktisch machen? DeepSeek-Forschung stellt vor DeepSeek-V3.2 und DeepSeek-V3.2-Speciale. Dabei handelt es sich um Reasoning-First-Modelle, die für Agenten entwickelt wurden und auf hochwertige Argumentation, lange Kontext- und Agenten-Workflows mit offenen Gewichtungen und Produktions-APIs abzielen. Die Modelle kombinieren DeepSeek Sparse Consideration (DSA), einen skalierten GRPO-Lernstapel zur Verstärkung und ein agentennatives Instrument-Protokoll und berichten über eine mit GPT 5 vergleichbare Leistung DeepSeek-V3.2-Speciale Erreichen des Gemini 3.0 Professional-Niveaus durch Argumentation bei öffentlichen Benchmarks und Wettbewerben.
Geringe Aufmerksamkeit mit nahezu linearen Kosten für lange Kontexte
Beide DeepSeek-V3.2 und DeepSeek-V3.2-Speciale Verwenden Sie den DeepSeek-V3 Combination of Specialists-Transformator mit etwa 671 B Gesamtparametern und 37 B aktiven Parametern professional Token, geerbt von V3.1 Terminus. Die einzige strukturelle Änderung ist DeepSeek Sparse Consideration, die durch kontinuierliches Vortraining eingeführt wurde.
DeepSeek Sparse Consideration teilt die Aufmerksamkeit in 2 Komponenten. A Blitzindexer führt eine kleine Anzahl von Köpfen mit niedriger Präzision über alle Token-Paare aus und erzeugt Relevanzwerte. A Feinkörniger Selektor Behält die Prime-Ok-Schlüsselwertpositionen professional Abfrage bei, und der Hauptaufmerksamkeitspfad führt Multi-Question-Consideration und Multi-Head-Latent-Consideration für diesen spärlichen Satz aus.
Dadurch ändert sich die vorherrschende Komplexität von O(L²) zu O(kL), wobei L die Sequenzlänge und ok die Anzahl der ausgewählten Token ist und viel kleiner als L ist. Basierend auf den Benchmarks, DeepSeek-V3.2 entspricht hinsichtlich der Genauigkeit der dichten Terminus-Basislinie und reduziert gleichzeitig die Kosten für lange Kontextinferenzen um etwa 50 Prozent, mit schnellerem Durchsatz und geringerer Speichernutzung auf {Hardware} der H800-Klasse sowie auf vLLM- und SGLang-Backends.

Fortsetzung des Pre-Trainings für DeepSeek Sparse Consideration
DeepSeek spärliche Aufmerksamkeit (DSA) wird durch fortlaufende Vorschulung eingeführt DeepSeek-V3.2 Endstation. In der dichten Aufwärmphase bleibt die dichte Aufmerksamkeit aktiv, alle Spine-Parameter werden eingefroren und nur der Lightning-Indexer wird mit einem Kullback-Leibler-Verlust trainiert, um der dichten Aufmerksamkeitsverteilung in 128K-Kontextsequenzen zu entsprechen. In dieser Section werden nur wenige Schritte und etwa 2 Milliarden Token benötigt, was ausreicht, damit der Indexer nützliche Ergebnisse erlernen kann.
In der Sparse-Section behält der Selektor 2048 Schlüsselwerteinträge professional Abfrage bei, das Spine wird freigegeben und das Modell trainiert weiter mit etwa 944 B Tokens. Steigungen für den Indexierer ergeben sich immer noch nur aus dem Ausrichtungsverlust bei starker Aufmerksamkeit auf die ausgewählten Positionen. Dieser Zeitplan macht DeepSeek spärliche Aufmerksamkeit (DSA) verhalten sich als Ersatz für dichte Aufmerksamkeit mit ähnlicher Qualität und geringeren langfristigen Kontextkosten.

GRPO mit mehr als 10 Prozent RL Compute
Zusätzlich zur spärlichen Architektur verwendet DeepSeek-V3.2 Group Relative Coverage Optimization (GRPO) als wichtigste Methode des verstärkenden Lernens. Das Forschungsteam gibt an, dass nach dem Coaching Verstärkungslernen Die RL-Rechenleistung übersteigt 10 Prozent der Rechenleistung vor dem Coaching.
RL ist nach Fachgebieten organisiert. Das Forschungsteam trainiert spezielle Läufe für Mathematik, Wettbewerbsprogrammierung, allgemeines logisches Denken, Shopping und Agentenaufgaben sowie Sicherheit und destilliert diese Spezialisten dann in die gemeinsame 685B-Parameterbasis für DeepSeek-V3.2 und DeepSeek-V3.2-Speciale. GRPO wird mit einem unvoreingenommenen KL-Schätzer, Off-Coverage-Sequenzmaskierung und Mechanismen zur Beibehaltung implementiert Mischung aus Experten (MoE) Routing- und Sampling-Masken, die zwischen Coaching und Sampling konsistent sind.

Agentendaten, Denkmodus und Toolprotokoll
Das DeepSeek-Forschungsteam erstellt einen großen Datensatz synthetischer Agenten, indem es mehr als 1.800 Umgebungen und mehr als 85.000 Aufgaben für Code-Agenten, Suchagenten, allgemeine Instruments und Code-Interpreter-Setups generiert. Aufgaben sind so konstruiert, dass sie schwer zu lösen und leicht zu überprüfen sind, und werden zusammen mit echten Codierungs- und Suchspuren als RL-Ziele verwendet.
Zum Zeitpunkt der Schlussfolgerung DeepSeek-V3.2 führt explizite Denk- und Nicht-Denkmodi ein. Der Deepseek-Reasoner-Endpunkt stellt standardmäßig den Denkmodus bereit, bei dem das Modell vor der endgültigen Antwort eine interne Gedankenkette erzeugt. Der Leitfaden „Denken mit Instruments“ beschreibt, wie Argumentationsinhalte über alle Instrument-Aufrufe hinweg beibehalten und gelöscht werden, wenn eine neue Benutzernachricht eintrifft, und wie Instrument-Aufrufe und Instrument-Ergebnisse im Kontext bleiben, selbst wenn der Argumentationstext auf das Price range gekürzt wird.
Die Chat-Vorlage wird entsprechend diesem Verhalten aktualisiert. Der DeepSeek-V3.2 Speciale Das Repository liefert Python-Encoder- und -Decoder-Helfer anstelle einer Jinja-Vorlage. Nachrichten können neben dem Inhalt auch ein Feld reasoning_content enthalten, das durch einen Denkparameter gesteuert wird. Eine Entwicklerrolle ist Suchagenten vorbehalten und wird in allgemeinen Chatflows von der offiziellen API nicht akzeptiert, was diesen Kanal vor versehentlichem Missbrauch schützt.

Benchmarks, Wettbewerbe und offene Artefakte
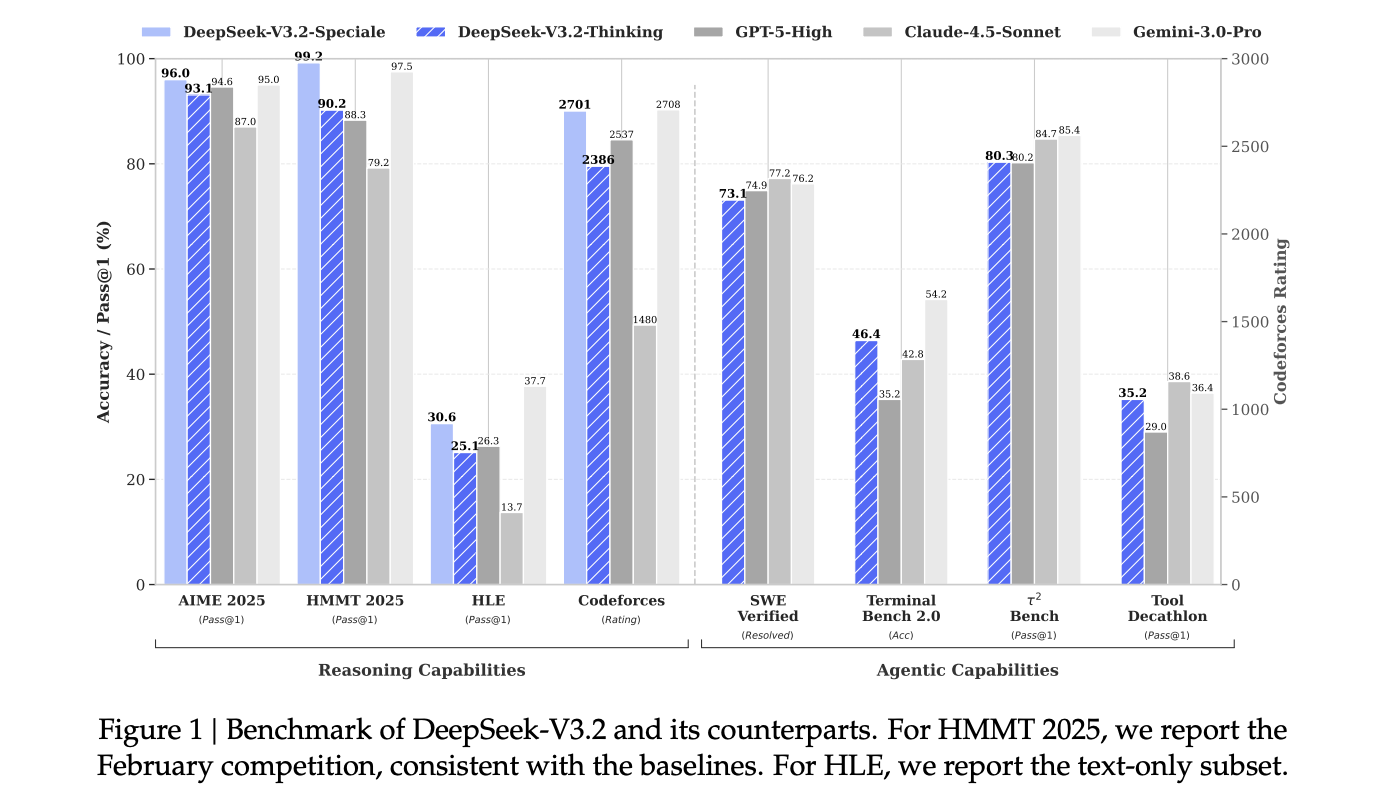
Zu Normal-Benchmarks für Argumentation und Kodierung, DeepSeek-V3.2 und vor allem DeepSeek-V3.2 Besonderes werden auf Suiten wie AIME 2025, HMMT 2025, GPQA und LiveCodeBench als vergleichbar mit GPT-5 und nahe an Gemini-3.0 Professional gemeldet, mit verbesserter Kosteneffizienz bei langen Kontext-Workloads.
Für formelle Wettbewerbe gibt das DeepSeek-Forschungsteam dies an DeepSeek-V3.2 Besonderes erreicht Leistungen auf Goldmedaillenniveau bei der Internationalen Mathematikolympiade 2025, der Chinesischen Mathematikolympiade 2025 und der Internationalen Informatikolympiade 2025 sowie wettbewerbsfähige Leistungen auf Goldmedaillenniveau bei den ICPC-Weltfinals 2025.
Wichtige Erkenntnisse
- DeepSeek-V3.2 fügt DeepSeek Sparse Consideration hinzu, was zu nahezu linearen O(kL)-Aufmerksamkeitskosten führt und etwa 50 % niedrigere API-Kosten für lange Kontexte im Vergleich zu früheren dichten DeepSeek-Modellen liefert, während die Qualität ähnlich wie bei DeepSeek-V3.1 Terminus bleibt.
- Die Modellfamilie behält das 671B-Parameter-MoE-Spine mit 37B aktiven Parametern professional Token bei und stellt ein vollständiges 128K-Kontextfenster in Produktions-APIs zur Verfügung, was lange Dokumente, mehrstufige Ketten und große Werkzeugspuren praktisch und nicht nur eine Laborfunktion darstellt.
- Nach dem Coaching kommt Group Relative Coverage Optimization (GRPO) mit einem Rechenbudget von mehr als 10 Prozent des Vortrainings zum Einsatz, wobei der Schwerpunkt auf Mathematik, Code, allgemeinem Denken, Shopping oder Agentenarbeitsbelastung und Sicherheit liegt, zusammen mit Spezialisten im Wettbewerbsstil, deren Fälle zur externen Überprüfung freigegeben werden.
- DeepSeek-V3.2 ist das erste Modell in der DeepSeek-Familie, das das Denken direkt in die Instrument-Nutzung integriert und sowohl denkende als auch nicht denkende Instrument-Modi sowie ein Protokoll unterstützt, bei dem internes Denken über alle Instrument-Aufrufe hinweg bestehen bleibt und nur bei neuen Benutzernachrichten zurückgesetzt wird.
Schauen Sie sich das an Papier Und Modellgewichte. Schauen Sie sich gerne bei uns um GitHub-Seite für Tutorials, Codes und Notebooks. Sie können uns auch gerne weiter folgen Twitter und vergessen Sie nicht, bei uns mitzumachen 100.000+ ML SubReddit und Abonnieren Unser E-newsletter. Warten! Bist du im Telegram? Jetzt können Sie uns auch per Telegram kontaktieren.
Asif Razzaq ist CEO von Marktechpost Media Inc.. Als visionärer Unternehmer und Ingenieur setzt sich Asif dafür ein, das Potenzial der künstlichen Intelligenz für das soziale Wohl zu nutzen. Sein jüngstes Unterfangen ist die Einführung einer Medienplattform für künstliche Intelligenz, Marktechpost, die sich durch eine ausführliche Berichterstattung über maschinelles Lernen und Deep-Studying-Nachrichten auszeichnet, die sowohl technisch fundiert als auch für ein breites Publikum leicht verständlich ist. Die Plattform verfügt über mehr als 2 Millionen monatliche Aufrufe, was ihre Beliebtheit beim Publikum verdeutlicht.