
DeepSeek-AI hat 3B DeepSeek-OCR veröffentlicht, ein Finish-to-Finish-OCR- und Dokumentenparsing-Imaginative and prescient-Language-Mannequin-(VLM)-System, das langen Textual content in einen kleinen Satz von Imaginative and prescient-Tokens komprimiert und diese Token dann mit einem Sprachmodell dekodiert. Die Methode ist einfach: Bilder enthalten kompakte Textdarstellungen, was die Sequenzlänge für den Decoder reduziert. Das Forschungsteam berichtet von einer Dekodierungsgenauigkeit von 97 %, wenn Textual content-Tokens innerhalb des 10-fachen Bereichs der Imaginative and prescient-Tokens im Fox-Benchmark liegen, und von einem nützlichen Verhalten selbst bei 20-facher Komprimierung. Es werden auch Wettbewerbsergebnisse auf OmniDocBench mit weitaus weniger Token als bei herkömmlichen Basiswerten gemeldet.
Architektur, was ist eigentlich neu?
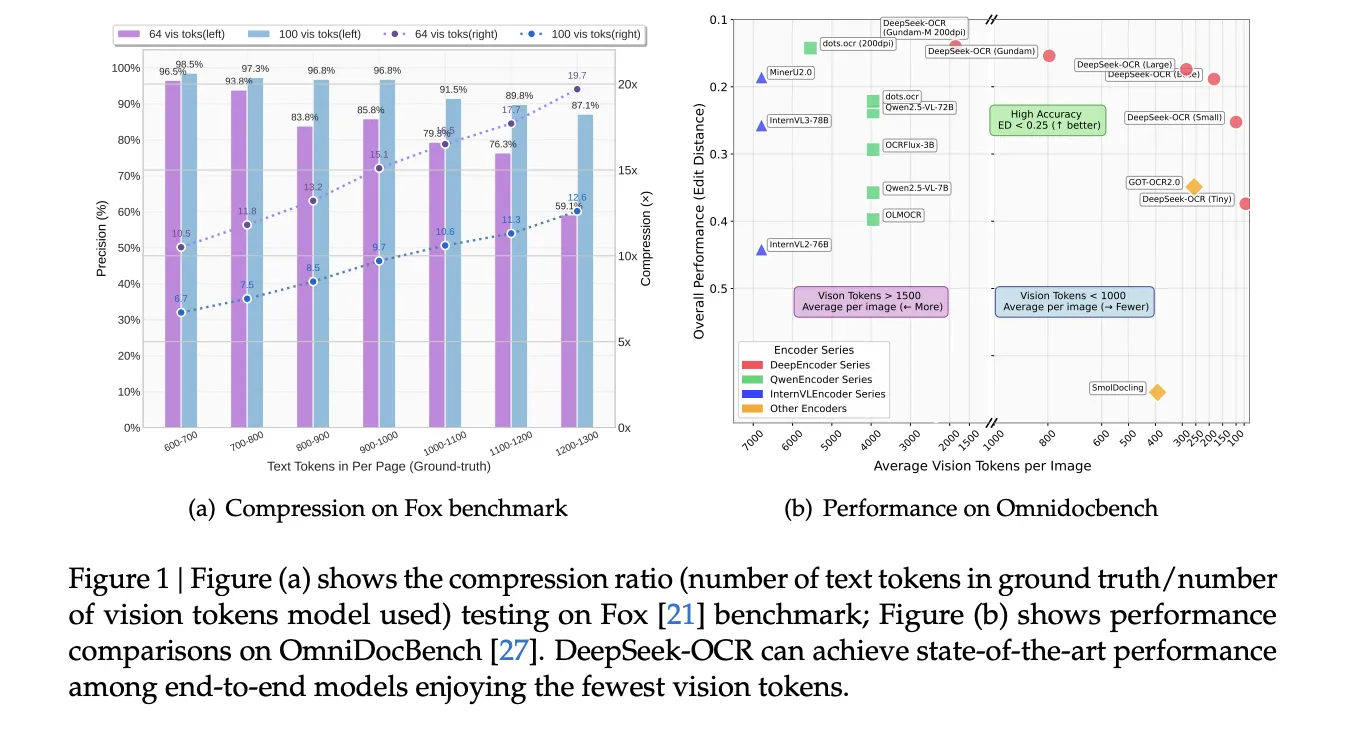
DeepSeek-OCR-3B besteht aus zwei Komponenten, einem Imaginative and prescient-Encoder namens DeepEncoder und einem Combination of Specialists-Decoder namens DeepSeek3B-MoE-A570M. Der Encoder ist für hochauflösende Eingaben mit geringen Aktivierungskosten und wenigen Ausgabe-Tokens konzipiert. Es verwendet eine auf SAM basierende Fenster-Aufmerksamkeitsstufe für die lokale Wahrnehmung, einen zweischichtigen Faltungskompressor für 16-faches Token-Downsampling und eine dichte globale Aufmerksamkeitsstufe auf Foundation von CLIP für die visuelle Wissensaggregation. Durch dieses Design wird der Aktivierungsspeicher bei hoher Auflösung kontrolliert und die Anzahl der Imaginative and prescient-Tokens niedrig gehalten. Der Decoder ist ein 3B-Parameter-MoE-Modell (genannt als DeepSeek3B-MoE-A570M) mit etwa 570 Millionen aktiven Parametern professional Token.
Modi mit mehreren Auflösungen, entwickelt für Token-Budgets
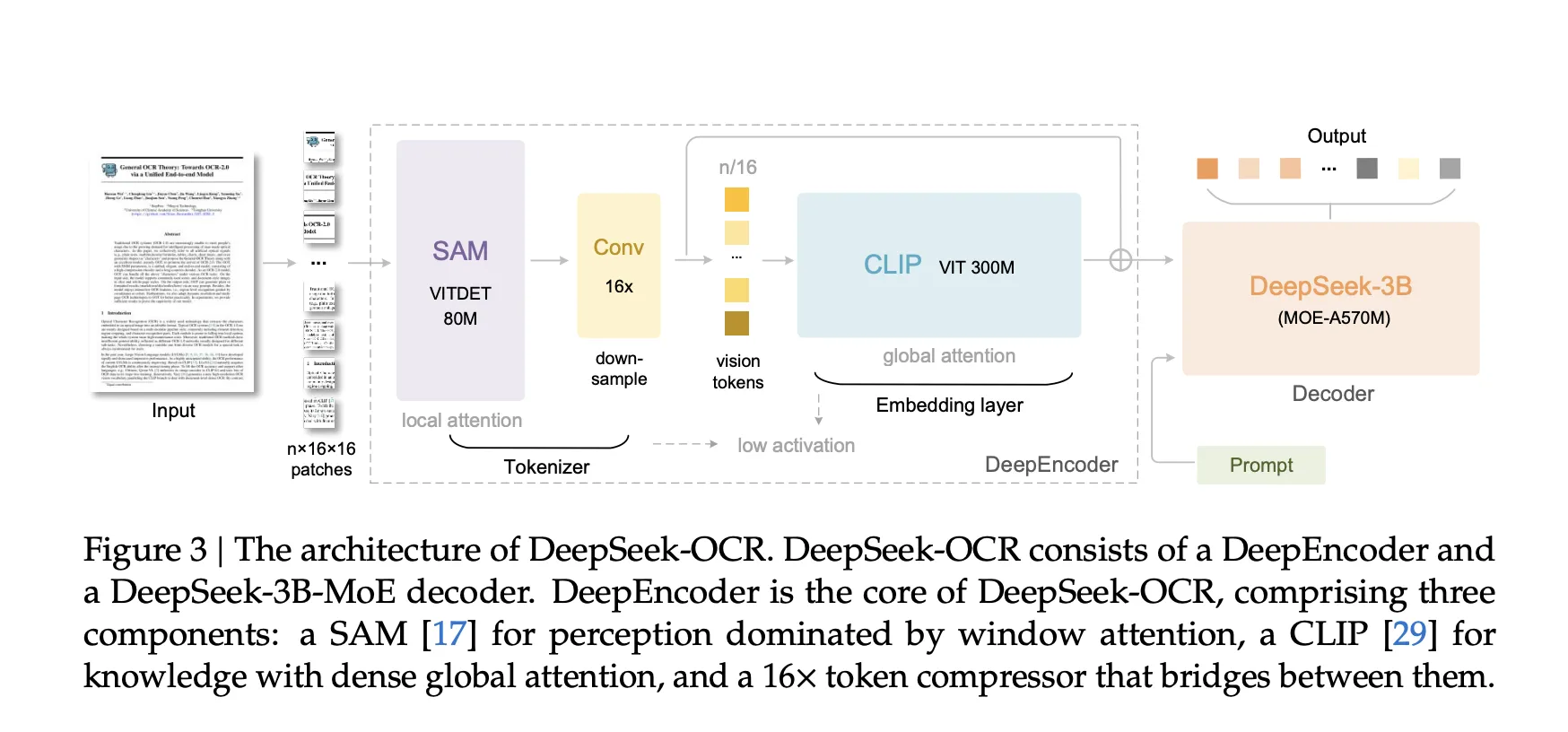
DeepEncoder unterstützt native Modi und dynamische Modi. Native Modi sind Tiny mit 64 Token bei 512 x 512 Pixeln, Small mit 100 Token bei 640 x 640, Base mit 256 Token bei 1024 x 1024 und Giant mit 400 Token bei 1280 x 1280. Dynamische Modi namens Gundam und Gundam-Grasp mischen gekachelte lokale Ansichten mit einer globalen Ansicht. Gundam ergibt n×100 plus 256 Token oder n×256 plus 400 Token, wobei n im Bereich von 2 bis 9 liegt. Für gepolsterte Modi gibt das Forschungsteam eine Formel für gültige Token an, die niedriger ist als die rohe Tokenanzahl und vom Seitenverhältnis abhängt. Mit diesen Modi können KI-Entwickler und -Forscher die Token-Budgets an die Seitenkomplexität anpassen.

Komprimierungsergebnisse, was die Zahlen sagen…..
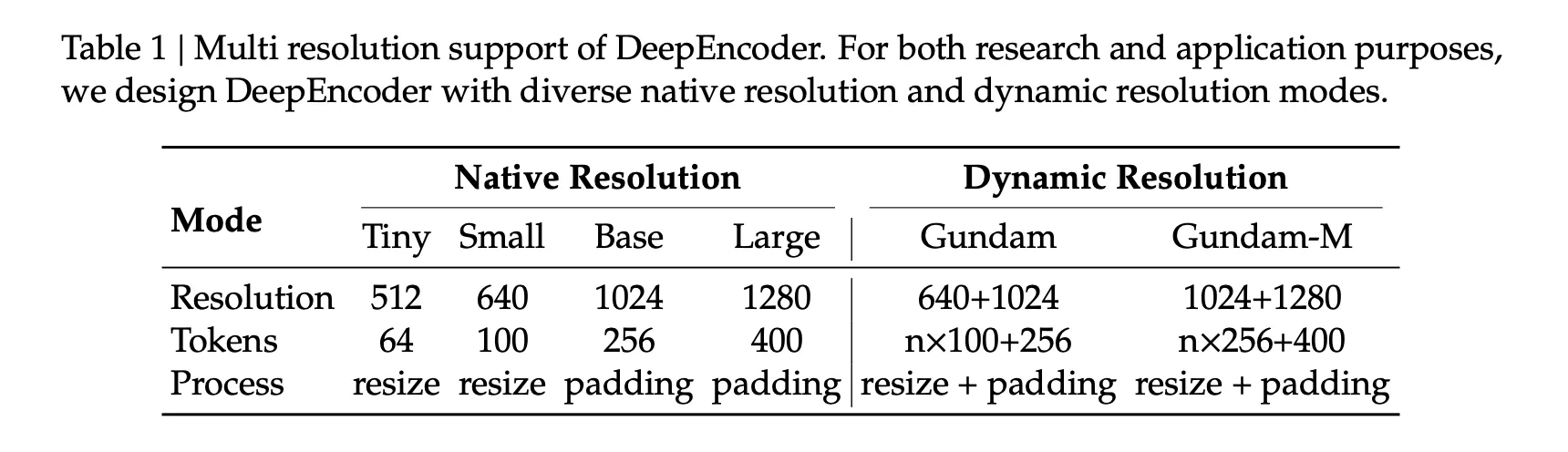
Die Fox-Benchmark-Studie misst die Präzision als exakte Textübereinstimmung nach der Dekodierung. Mit 100 Imaginative and prescient-Tokens erreichen Seiten mit 600 bis 700 Textual content-Tokens eine Genauigkeit von 98,5 % bei 6,7-facher Komprimierung. Seiten mit 900 bis 1000 Textual content-Tokens erreichen eine Genauigkeit von 96,8 % bei 9,7-facher Komprimierung. Bei 64 Imaginative and prescient-Tokens nimmt die Präzision mit zunehmender Komprimierung ab, beispielsweise 59,1 % bei etwa 19,7× für 1200 bis 1300 Textual content-Tokens. Diese Werte stammen direkt aus Tabelle 2.
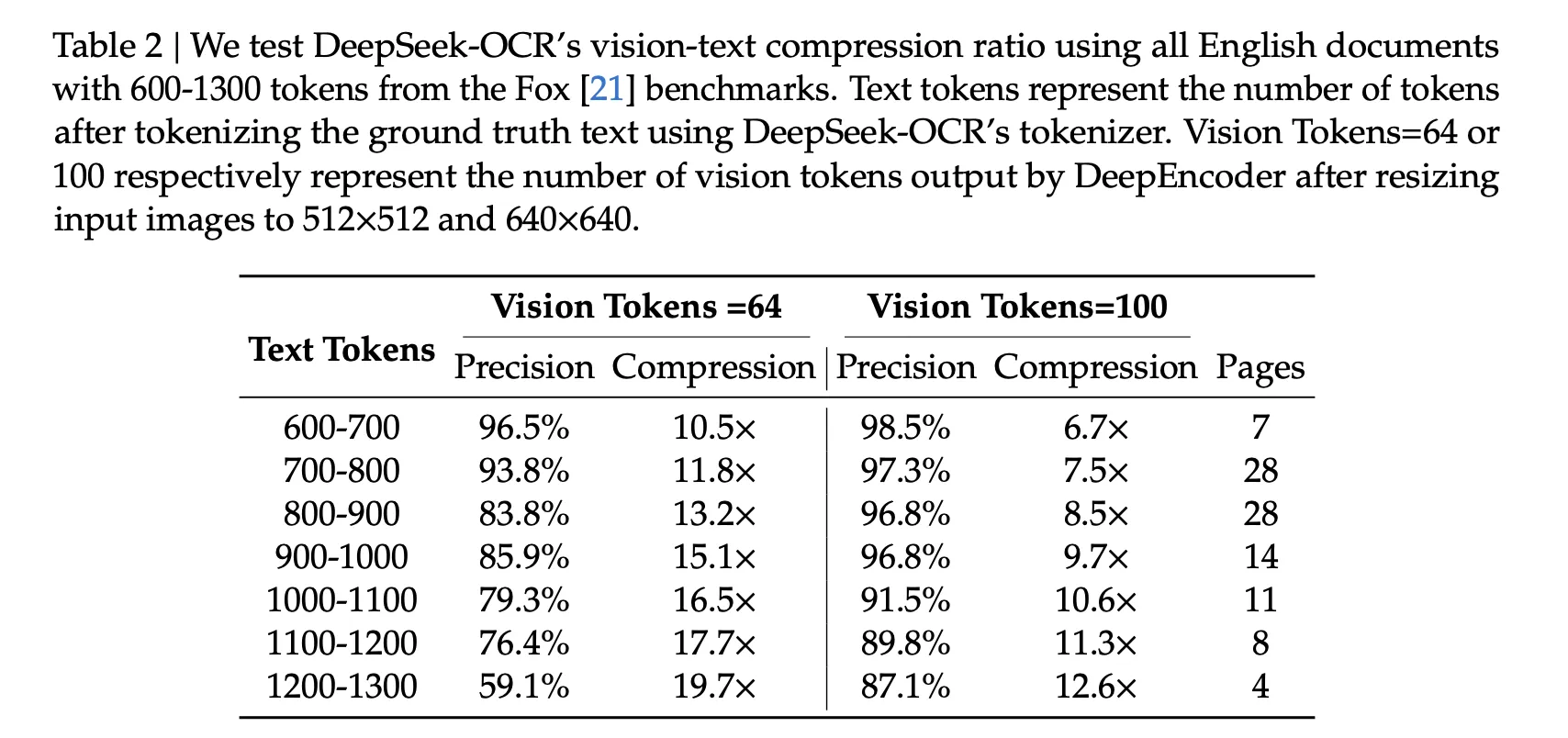
Auf OmniDocBench berichtet die Zusammenfassung, dass DeepSeek-OCR GOT-OCR 2.0 übertrifft, wenn nur 100 Imaginative and prescient-Tokens professional Seite verwendet werden, und dass es bei weniger als 800 Imaginative and prescient-Tokens MinerU 2.0 übertrifft, das im Durchschnitt über 6000 Tokens professional Seite verwendet. Der Benchmark-Bereich stellt die Gesamtleistung in Bezug auf die Bearbeitungsentfernung dar.
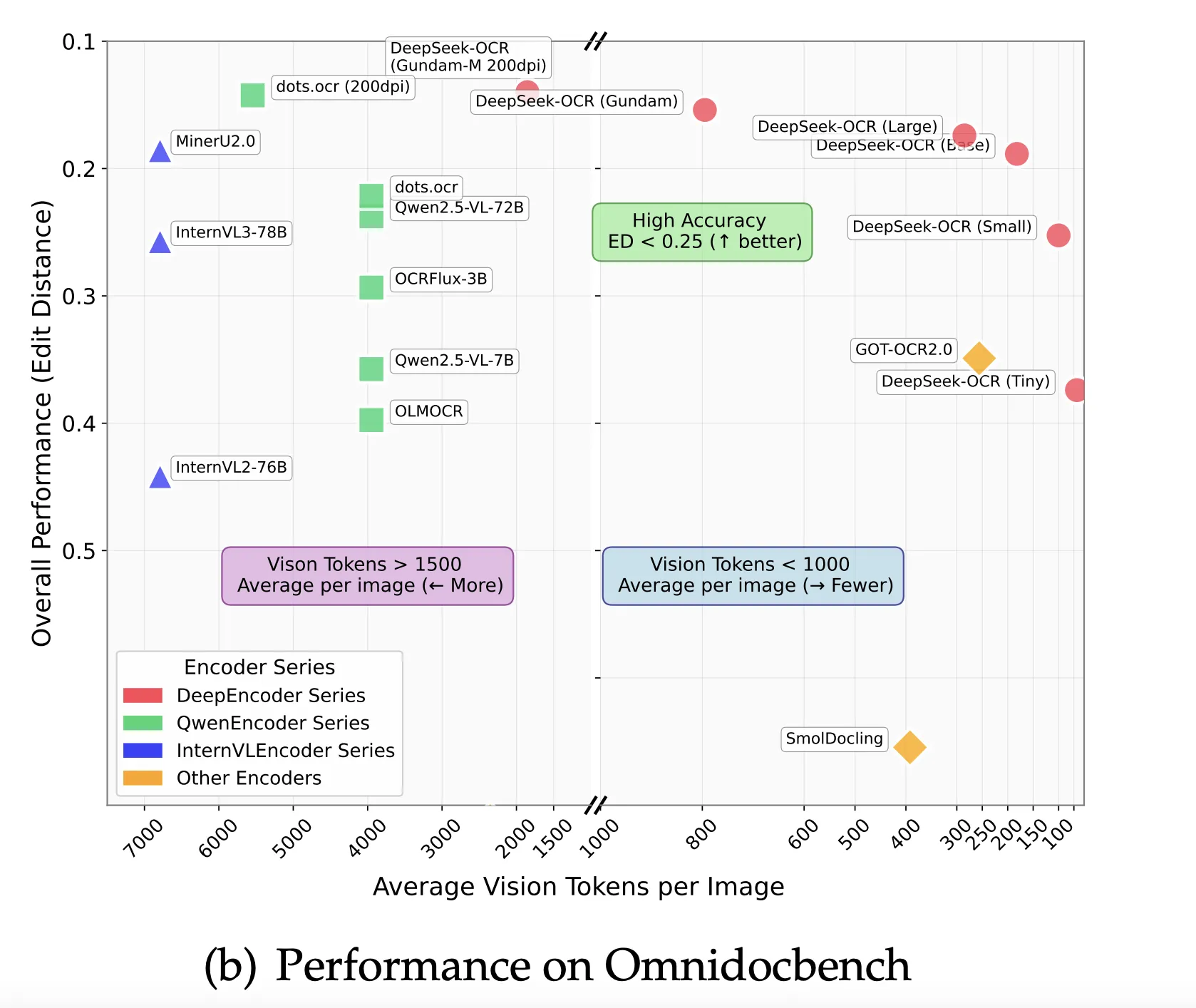
Trainingsdetails, die wichtig sind….
Das Forschungsteam beschreibt eine zweiphasige Trainingspipeline. Es trainiert DeepEncoder zunächst mit der nächsten Token-Vorhersage für OCR 1.0- und OCR 2.0-Daten und 100 Millionen LAION-Proben und trainiert dann das gesamte System mit Pipeline-Parallelität über 4 Partitionen. Als {Hardware} nutzte der Lauf 20 Knoten mit jeweils 8 A100 40G-GPUs und AdamW. Das Staff meldet eine Trainingsgeschwindigkeit von 90 Milliarden Token professional Tag für reine Textdaten und 70 Milliarden Token professional Tag für multimodale Daten. In der Produktion wird die Fähigkeit gemeldet, über 200.000 Seiten professional Tag auf einem einzigen A100 40G-Knoten zu generieren.
So bewerten Sie es in einem praktischen Stapel
Wenn es sich bei Ihren Zieldokumenten um typische Berichte oder Bücher handelt, beginnen Sie mit dem kleinen Modus bei 100 Token und passen Sie ihn dann nur dann nach oben an, wenn der Bearbeitungsabstand nicht akzeptabel ist. Wenn Ihre Seiten dichte kleine Schriftarten oder eine sehr hohe Token-Anzahl enthalten, verwenden Sie einen Gundam-Modus, da dieser globale und lokale Sichtfelder mit expliziter Token-Budgetierung kombiniert. Wenn Ihre Arbeitslast Diagramme, Tabellen oder chemische Strukturen umfasst, lesen Sie den qualitativen Abschnitt „Deep Parsing“, der Konvertierungen in HTML-Tabellen und SMILES sowie strukturierte Geometrie zeigt, und entwerfen Sie dann Ausgaben, die leicht zu validieren sind.
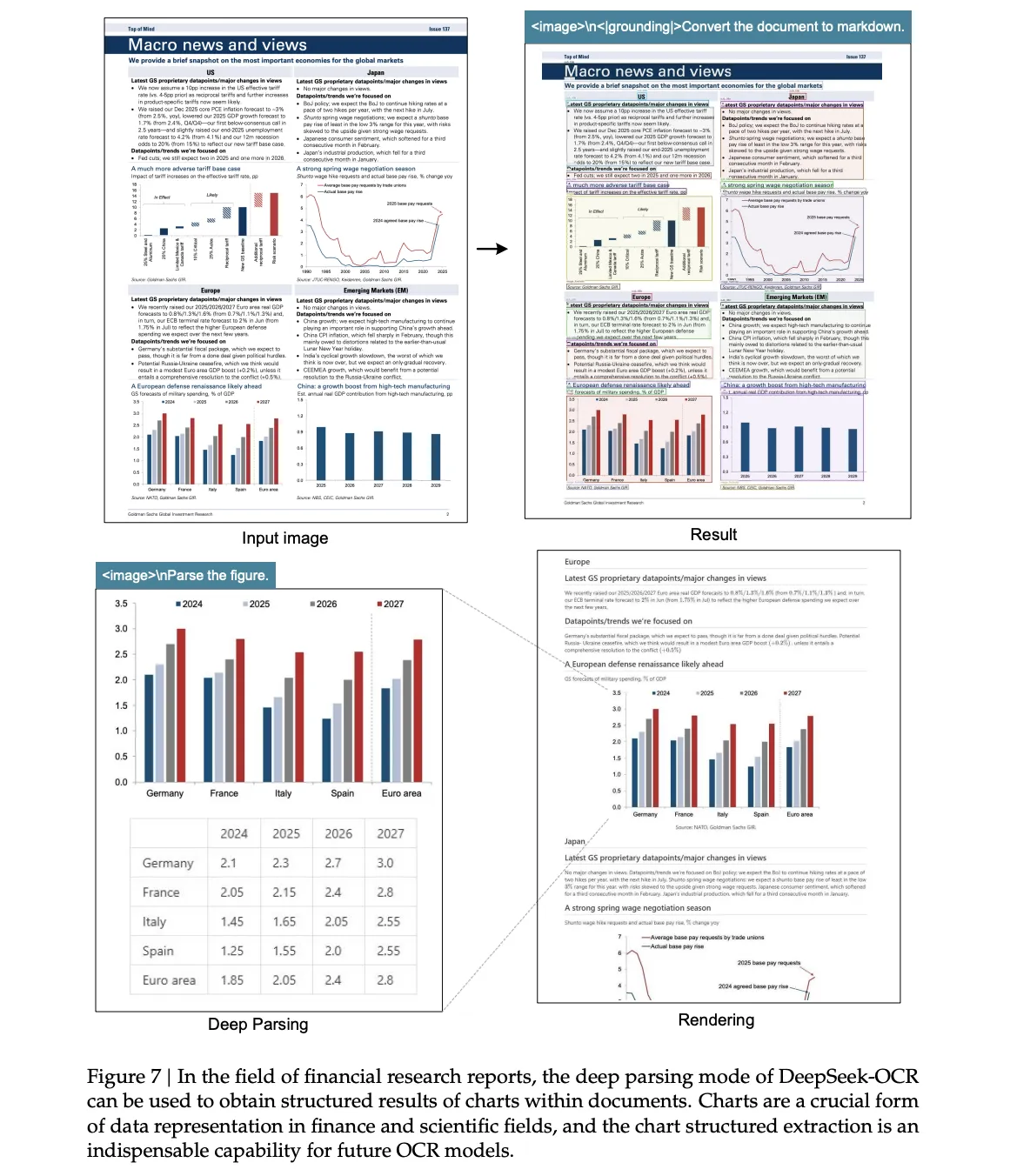
Wichtige Erkenntnisse
- DeepSeek OCR zielt auf die Token-Effizienz durch optische Kontextkomprimierung mit nahezu verlustfreier Dekodierung bei etwa 10-facher Komprimierung und etwa 60 Prozent Präzision bei etwa 20-facher Komprimierung ab.
- Die HF-Model legt explizite Token-Budgets offen: Tiny verwendet 64 Token bei 512 x 512, Small verwendet 100 Token bei 640 x 640, Base verwendet 256 Token bei 1024 x 1024, Giant verwendet 400 Token bei 1280 x 1280 und Gundam erstellt n Ansichten bei 640 x 640 plus eine globale Ansicht bei 1024 mal 1024.
- Die Systemstruktur besteht aus einem DeepEncoder, der Seiten in Imaginative and prescient-Tokens komprimiert, und einem DeepSeek3B-MoE-Decoder mit etwa 570 Millionen aktiven Parametern, wie vom Forschungsteam im technischen Bericht beschrieben.
- Die Hugging Face-Modellkarte dokumentiert ein getestetes Setup für den sofortigen Einsatz: Python 3.12.9, CUDA 11.8, PyTorch 2.6.0, Transformers 4.46.3, Tokenizers 0.20.3 und Flash Consideration 2.7.3.
DeepSeek OCR ist ein praktischer Schritt für die Dokumenten-KI. Es behandelt Seiten als kompakte optische Träger, die die Länge der Decodersequenz reduzieren, ohne die meisten Informationen zu verwerfen. Die Modellkarte und der technische Bericht beschreiben eine Decodierungsgenauigkeit von 97 Prozent bei etwa zehnfacher Komprimierung im Fox-Benchmark, was die wichtigste Aussage zum Testen in realen Arbeitslasten ist. Das veröffentlichte Modell ist ein 3B MoE-Decoder mit einem DeepEncoder-Frontend, verpackt für Transformers, mit getesteten Versionen für PyTorch 2.6.0, CUDA 11.8 und Flash Consideration 2.7.3, was die Einrichtungskosten für Ingenieure senkt. Das Repository zeigt einen einzelnen Safetensors-Shard mit 6,67 GB, der für gängige GPUs geeignet ist. Insgesamt operationalisiert DeepSeek OCR die optische Kontextkomprimierung mit einem 3B-MoE-Decoder, meldet eine Dekodierungsgenauigkeit von etwa 97 % bei 10-facher Komprimierung auf Fox, bietet explizite Token-Funds-Modi und beinhaltet ein getestetes Transformers-Setup, um den Durchsatzanspruch in Ihrer eigenen Pipeline zu validieren.
Schauen Sie sich das an Technisches Papier, Modell auf HF Und GitHub-Repo. Schauen Sie sich gerne bei uns um GitHub-Seite für Tutorials, Codes und Notebooks. Sie können uns auch gerne weiter folgen Twitter und vergessen Sie nicht, bei uns mitzumachen 100.000+ ML SubReddit und Abonnieren Unser Publication. Warten! Bist du im Telegram? Jetzt können Sie uns auch per Telegram kontaktieren.
Asif Razzaq ist CEO von Marktechpost Media Inc.. Als visionärer Unternehmer und Ingenieur setzt sich Asif dafür ein, das Potenzial der künstlichen Intelligenz für das soziale Wohl zu nutzen. Sein jüngstes Unterfangen ist die Einführung einer Medienplattform für künstliche Intelligenz, Marktechpost, die sich durch eine ausführliche Berichterstattung über maschinelles Lernen und Deep-Studying-Nachrichten auszeichnet, die sowohl technisch fundiert als auch für ein breites Publikum leicht verständlich ist. Die Plattform verfügt über mehr als 2 Millionen monatliche Aufrufe, was ihre Beliebtheit beim Publikum verdeutlicht.