
Wie würde sich Ihr Agenten-Stack verändern, wenn eine Richtlinie ausschließlich anhand ihrer eigenen ergebnisorientierten Rollouts trainieren könnte – keine Belohnungen, keine Demos – und dennoch das Nachahmungslernen in acht Benchmarks übertreffen könnte? Meta Superintelligence Labs schlagen vor:Frühe Erfahrung‚, ein belohnungsfreier Trainingsansatz, der das Coverage-Lernen bei Sprachagenten ohne große menschliche Demonstrationssätze und ohne Reinforcement Studying (RL) in der Hauptschleife verbessert. Die Kernidee ist einfach: Lassen Sie den Agenten von Expertenzuständen abzweigen, seine eigenen Maßnahmen ergreifen und die sammeln resultierende zukünftige Zuständeund diese Konsequenzen in Aufsicht umwandeln. Das Forschungsteam konkretisiert dies mit zwei konkreten Strategien:Implizite Weltmodellierung (IWM) Und Selbstreflexion (SR)– und meldet konsistente Gewinne über acht Umgebungen und mehrere Basismodelle hinweg.
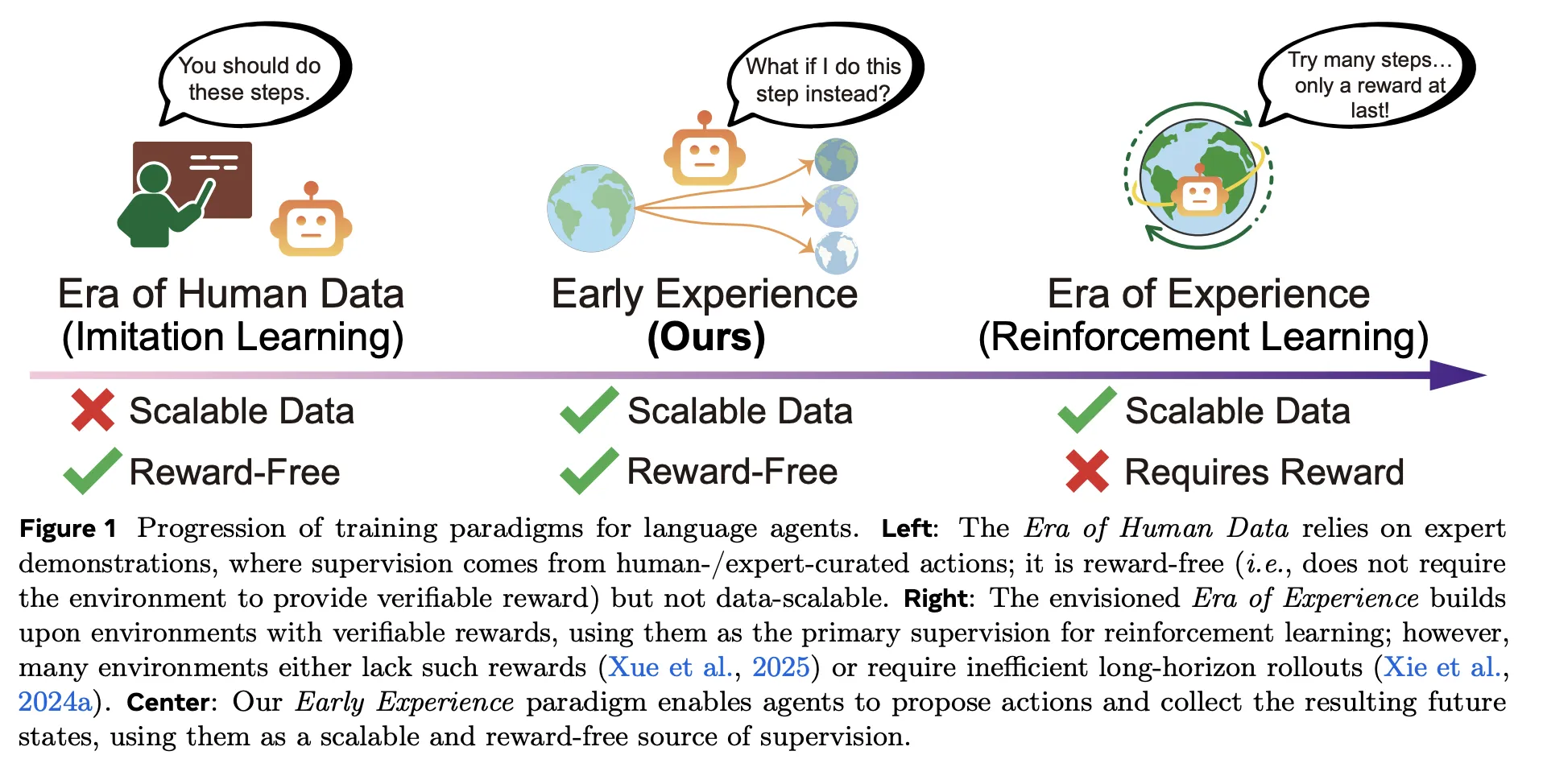
Welche frühen Erfahrungen ändern sich?
Traditionelle Pipelines lehnen sich an Nachahmungslernen (IL) über Expertentrajektorien, die günstig zu optimieren, aber schwer zu skalieren und spröde außerhalb der Verteilung sind; Verstärkungslernen (RL) verspricht Lernen aus Erfahrung, benötigt aber nachprüfbare Belohnungen und eine stabile Infrastruktur – was in Internet- und Multitool-Umgebungen oft fehlt. Frühe Erfahrung sitzt zwischen ihnen: es ist belohnungsfrei wie Nachahmungslernen (IL)aber die Aufsicht ist verankert Folgen des eigenen Handelns des Agentennicht nur Expertenaktionen. Kurz gesagt: Der Agent macht Vorschläge, handelt und lernt aus dem, was tatsächlich als nächstes passiert – es ist keine Belohnungsfunktion erforderlich.
- Implizite Weltmodellierung (IWM): Trainieren Sie das Modell, um das vorherzusagen nächste Beobachtung Angesichts des Zustands und der gewählten Aktion wird das interne Modell der Umgebungsdynamik des Agenten gestrafft und Abweichungen von der Richtlinie verringert.
- Selbstreflexion (SR): Präsentieren Sie Experten- und Alternativklagen im selben Staat. Lassen Sie sich das Modell erklären warum die Expertenaktion besser ist Verwenden Sie die beobachteten Ergebnisse und optimieren Sie dann die Richtlinie anhand dieses kontrastierenden Alerts.
Beide Strategien verwenden dieselben Budgets und Decodierungseinstellungen wie IL; Lediglich die Datenquelle unterscheidet sich (vom Agenten generierte Zweige anstelle von Expertenverläufen).
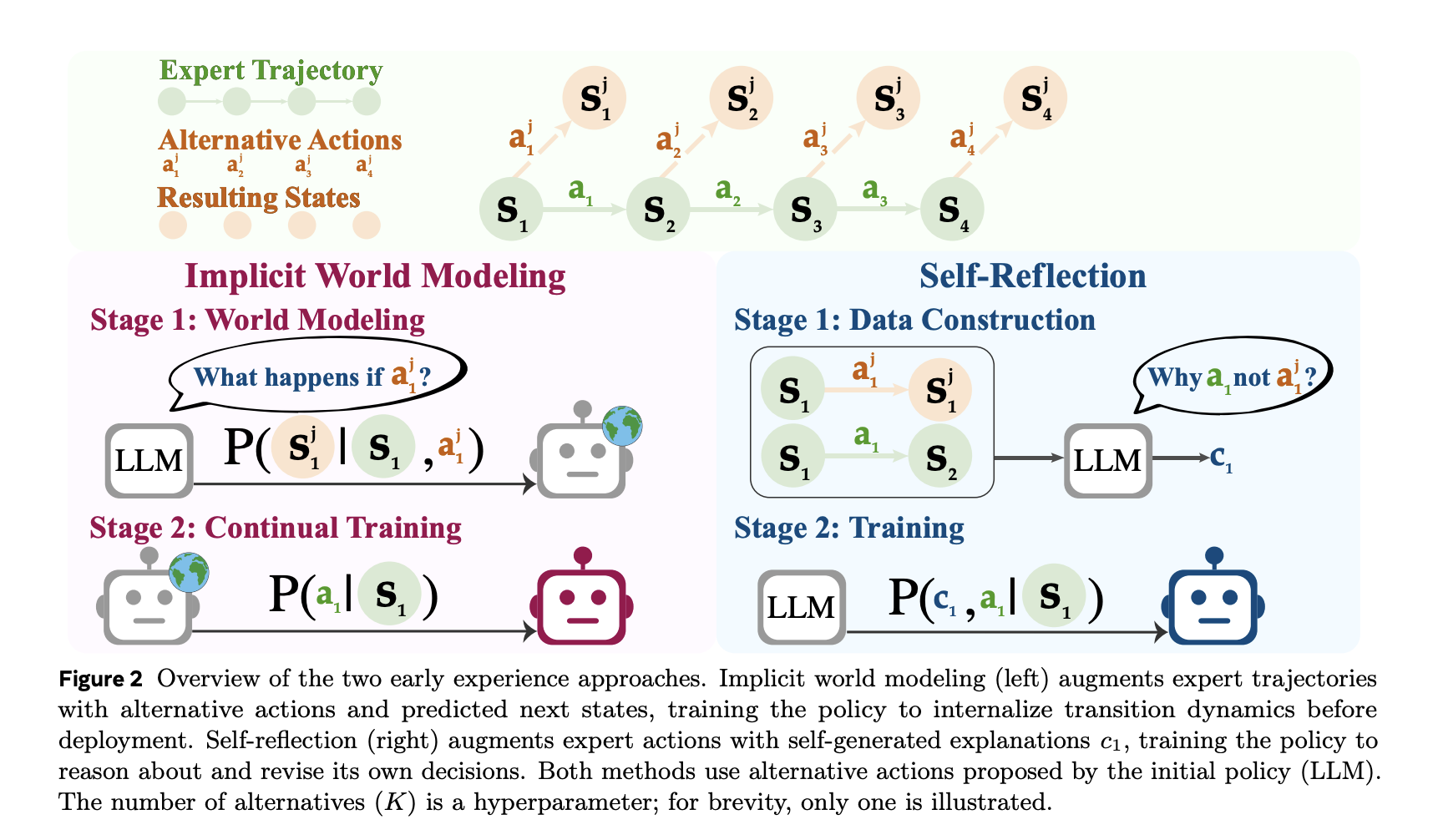
Die Benchmarks verstehen
Das Forschungsteam bewertet weiter acht Sprachagentenumgebungen, die Webnavigation, langfristige Planung, wissenschaftliche/körperliche Aufgaben und Multi-Area-API-Workflows umfassen – z. B. WebShop (Transaktionales Surfen), Reiseplaner (einschränkungsreiche Planung), ScienceWorld, ALFWorld, Tau-Financial institutionund andere. Frühe Erfahrung Erträge durchschnittlicher absoluter Gewinn von +9,6 Erfolg Und +9,4 außerhalb der Domäne (OOD) über IL über die gesamte Matrix von Aufgaben und Modellen hinweg. Diese Vorteile bleiben bestehen, wenn dieselben Kontrollpunkte verwendet werden RL initialisieren (GRPO), Verbesserung der Publish-RL-Obergrenzen um bis zu +6,4 im Vergleich zu Verstärkungslernen (RL) angefangen von Nachahmungslernen (IL).
Effizienz: weniger Expertendaten, gleiches Optimierungsbudget
Ein wichtiger praktischer Gewinn ist Demo-Effizienz. Mit einem festen Optimierungsbudget, Frühe Erfahrung entspricht oder schlägt IL mit a Fraktion von Expertendaten. An WebShop, 1/8 der Demonstrationen mit Frühe Erfahrung bereits überschritten IL trainierte auf dem voll Demo-Set; An ALFWorldParität wird erreicht 1/2 die Demos. Der Vorteil wächst mit mehr Demonstrationen, was darauf hindeutet, dass die vom Agenten generierten Zukunftszustände Überwachungssignale liefern, die Demonstrationen allein nicht erfassen.
Wie die Daten aufgebaut sind?
Die Pipeline basiert auf einer begrenzten Anzahl von Experten-Rollouts, um repräsentative Staaten zu erhalten. Bei ausgewählten Zuständen schlägt der Agent vor different Maßnahmenführt sie aus und zeichnet die auf nächste Beobachtungen.
- Für IWMdie Trainingsdaten sind Tripletts ⟨Zustand, Aktion, nächster Zustand⟩ und das Ziel ist Vorhersage des nächsten Zustands.
- Für SRZu den Eingabeaufforderungen gehören die Expertenaktion und mehrere Alternativen sowie deren beobachtete Ergebnisse. Das Modell erzeugt a fundierte Begründung Erläutern, warum die Expertenmaßnahme vorzuziehen ist, und diese Überwachung wird dann zur Verbesserung der Richtlinie genutzt.
Wo Reinforcement Studying (RL) passt?
Frühe Erfahrung Ist nicht „RL ohne Belohnungen.“ es ist ein betreut Rezept, das verwendet agentenerprobte Ergebnisse als Etiketten. In Umgebungen mit nachweisbaren Belohnungen ist das Forschungsteam einfach RL danach hinzufügen Frühe Erfahrung. Da die Initialisierung besser ist als IL, ist die Gleicher RL-Zeitplan klettert höher und schneller, mit bis +6,4 Endgültiger Erfolg gegenüber IL-initialisiertem RL in allen getesteten Domänen. Dies positioniert Early Expertise als eine Brücke: belohnungsfreies Vortraining aus Konsequenzen, gefolgt (soweit möglich) vom Commonplace Verstärkungslernen (RL).
Wichtige Erkenntnisse
- Belohnungsfreies Coaching über vom Agenten generierte zukünftige Staaten (keine Belohnungen) verwenden Implizite Weltmodellierung Und Selbstreflexion übertrifft Nachahmungslernen in acht Umgebungen.
- Gemeldete absolute Gewinne gegenüber IL: +18,4 (WebShop), +15,0 (Reiseplaner), +13,3 (ScienceWorld) unter übereinstimmenden Budgets und Einstellungen.
- Demo-Effizienz: übertrifft IL im WebShop mit 1/8 von Demonstrationen; erreicht ALFWorld-Parität mit 1/2– zu festen Optimierungskosten.
- Als Initialisierer Frühe Erfahrung steigert nachfolgende RL (GRPO)-Endpunkte um bis +6,4 gegen RL, gestartet von IL.
- Validiert auf mehreren Spine-Familien (3B–8B) mit konsistenten Verbesserungen innerhalb und außerhalb der Domäne; als Brücke dazwischen positioniert Nachahmungslernen (IL) Und Verstärkungslernen (RL).
Frühe Erfahrung ist ein pragmatischer Beitrag: Er ersetzt die brüchige, rein rationale Erweiterung durch eine ergebnisorientierte Überwachung, die ein Agent in großem Maßstab ohne Belohnungsfunktionen generieren kann. Die beiden Varianten – Implicit World Modeling (Vorhersage der nächsten Beobachtung zur Verankerung der Umgebungsdynamik) und Self-Reflection (kontrastive, ergebnisüberprüfte Begründungen gegenüber Expertenaktionen) – greifen direkt Off-Coverage-Drift und Lengthy-Horizon-Fehlerakkumulation an und erklären die konsistenten Gewinne gegenüber Nachahmungslernen in acht Umgebungen und die stärkeren RL-Obergrenzen, wenn sie als Initialisierer für GRPO verwendet werden. In Internet- und Instrument-Nutzungsumgebungen, in denen nachweisbare Belohnungen knapp sind, ist diese belohnungsfreie Überwachung das fehlende Mittel zwischen IL und RL und ist für Produktionsagentenstapel sofort umsetzbar.
Schauen Sie sich das an PAPIER hier. Schauen Sie sich gerne bei uns um GitHub-Seite für Tutorials, Codes und Notebooks. Sie können uns auch gerne weiter folgen Twitter und vergessen Sie nicht, bei uns mitzumachen 100.000+ ML SubReddit und Abonnieren Unser Publication. Warten! Bist du im Telegram? Jetzt können Sie uns auch per Telegram kontaktieren.
Asif Razzaq ist CEO von Marktechpost Media Inc.. Als visionärer Unternehmer und Ingenieur setzt sich Asif dafür ein, das Potenzial der künstlichen Intelligenz für das soziale Wohl zu nutzen. Sein jüngstes Unterfangen ist die Einführung einer Medienplattform für künstliche Intelligenz, Marktechpost, die sich durch eine ausführliche Berichterstattung über maschinelles Lernen und Deep-Studying-Nachrichten auszeichnet, die sowohl technisch fundiert als auch für ein breites Publikum leicht verständlich ist. Die Plattform verfügt über mehr als 2 Millionen monatliche Aufrufe, was ihre Beliebtheit beim Publikum verdeutlicht.