
Google veröffentlichte an Aktualisierte Model von Gemini 2.5 Flash Und Gemini 2.5 Flash-Lite Vorschau -Modelle über AI Studio Und Scheitelpunkt aiplus rollende Aliase –gemini-flash-latest Und gemini-flash-lite-latest– Dies weisen immer auf die neueste Vorschau in jeder Familie hin. Für die Produktionsstabilität empfiehlt Google, feste Zeichenfolgen festzuhalten (gemini-2.5-flashAnwesend gemini-2.5-flash-lite). Google gibt einen zweiwöchigen E-Mail-Hinweis, bevor er a -latest Alias und bemerkt das Zinsgrenzen, Funktionen und Kosten können bei Alias -Updates variieren.
Was hat sich tatsächlich geändert?
- Blitz: Verbessert Verwendung von Agentenwerkzeug und effizienteres „Denken“ (Multi-Cross-Argumentation). Google berichtet a +5 Punkt anheben SWE-Bench verifiziert vs. die Mai -Vorschau (48,9% → 54,0%) mit einer besseren Langzeitplanung/Code-Navigation.
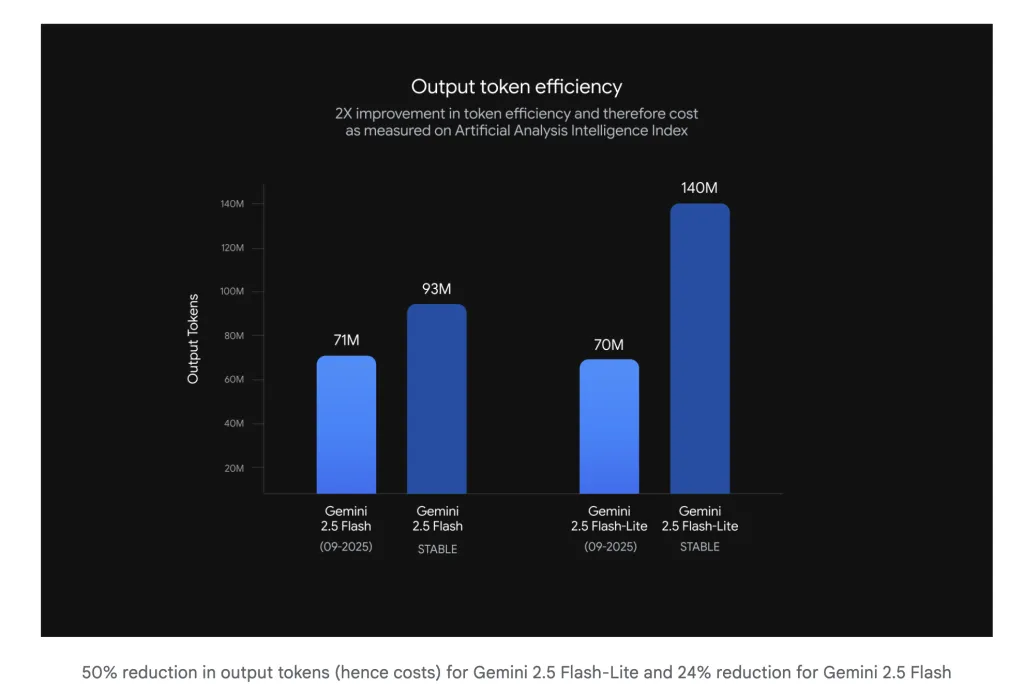
- Flash-Lite: Eingestellt für strengere Anweisung folgtAnwesend Reduzierte Ausführlichkeitund stärker Multimodal/Übersetzung. Die interne Tabelle von Google zeigt ~ 50% weniger Output -Token für Flash-Lite und ~ 24% weniger Für Flash, der die Ausgaben- und Wandverkleidungszeit in durchsatz gebundenen Diensten direkt verkürzt.
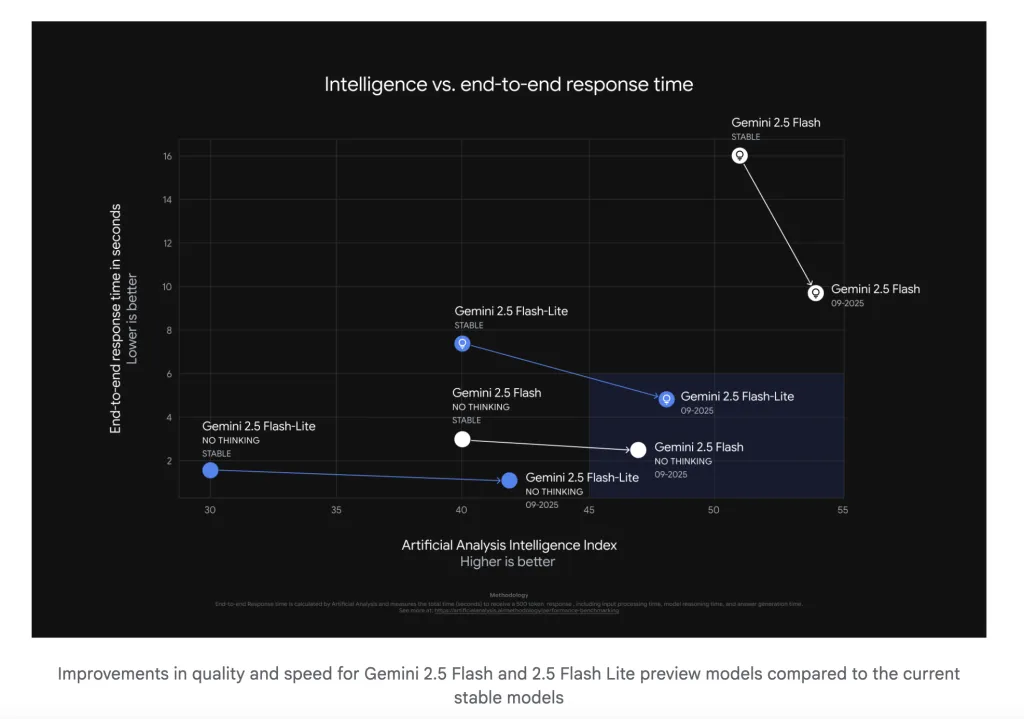
Künstliche Analyse (der Konto hinter dem AI -Benchmarking -Standort) erhalten Zugriff vor der Veröffentlichung und veröffentlichte externe Messungen über Intelligenz und Geschwindigkeit hinweg. Highlights auf den Faden- und Begleitseiten:
- Durchsatz: In Endpunkttests,, Gemini 2.5 Flash-Lite (Vorschau 09-2025, Argumentation) wird als die gemeldet schnellster proprietäres Modell Sie verfolgen herum ~ 887 Ausgangs -Token/s auf AI Studio in ihrem Setup.
- Intelligence Index Deltas: Die September -Vorschau auf Blitz Und Flash-Lite Verbesserung der künstlichen Analyse ‚aggregierte „Intelligenz“ -Ergänge im Vergleich zu früheren stabilen Freisetzungen (Website-Seiten brechen die Argumentation im Vergleich zu nicht-renommierten Tracks und Mischpreisannahmen).
- Token -Effizienz: Der Thread wiederholt die eigenen Reduktionsansprüche von Google (–24% Blitz, –50% Flash-Lite) und rahmt den Sieg als Gewinn ein Kosten-pro-Absicht Verbesserungen für Budgets der engen Latenz.
Kostenoberflächen- und Kontextbudgets (für Bereitstellungsauswahl)
- Listenpreis von Flash-Lite GA Ist $ 0.10 / 1m Eingangs -Token Und $ 0,40 / 1 Mio. Ausgangstoken (Googles GA -Put up und DeepMind -Modellseite). In dieser Grundlinie führt die Ausführungsreduzierungen zu sofortigen Einsparungen.
- Kontext: Flash-Lite unterstützt ~ 1m-ten Kontext mit konfigurierbaren „Denkbudgets“ und Software-Konnektivität (Suche nach Erdung, Codeausführung)-Verwendung für Agentenstapel, die das Lesen, Planen und Multi-Software-Anrufe verschieben.
Browser-Agent-Winkel und der O3-Anspruch
In einer Umlaufansprüche heißt es, der „neue Gemini Flash hat Genauigkeit auf O3-Ebeneaber ist 2 × schneller Und 4 × billiger An Browser-Agent Aufgaben. “ Das ist Neighborhood gemeldetnicht in Googles offiziellem Beitrag. Es wird wahrscheinlich auf personal/begrenzte Job -Suiten (DOM -Navigation, Aktionsplanung) mit spezifischen Toolbudgets und -T -Zeitüberschreitungen zurückzuführen. Verwenden Sie es als Hypothese für Ihre eigenen Evals; Behandle es nicht als Cross-Bench-Wahrheit.
Praktische Anleitung für Groups
- Pin gegen Chase
-latest: Wenn Sie von strengen SLAs oder festen Grenzen angewiesen sind, Stift die stabilen Saiten. Wenn Sie kontinuierlich für Kosten/Latenz/Qualität Kanarien Kanarien sind, die-latestAliase reduzieren die Improve -Reibung (Google gibt vor dem Umschalten des Zeigers zwei Wochen bekannt). - Hoch-QPs- oder Token-Meter-Endpunkte: Beginnen Sie mit Flash-Lite-Vorschau; Die Ausführungs- und Befehlsverfolgungs-Upgrades verkleinern Ausstiegs-Token. Validieren Sie multimodale und langkontextspezifische Spuren unter Produktionsbelastung.
- Agent/Werkzeugpipelines: A/b Blitzvorschau Wenn die Verwendung von mehrstufigen Instruments die Kosten- oder Ausfallmodi dominiert; Googles SWE-Bench verifizierte die Zahlen für Auftrieb und Neighborhood-Token/s, deuten auf eine bessere Planung unter eingeschränkten Denkbudgets hin.
Modellstränge (Strom)
- Vorschau:
gemini-2.5-flash-preview-09-2025Anwesendgemini-2.5-flash-lite-preview-09-2025 - Stabil:
gemini-2.5-flashAnwesendgemini-2.5-flash-lite - Aliase rollen:
gemini-flash-latestAnwesendgemini-flash-lite-latest(Zeigersemantik; kann Merkmale/Grenzen/Preisgestaltung ändern).
Zusammenfassung
Das neue Launch -Replace von Google verschärft sich Werkzeugnutzungskompetenz (Blitz) und Token/Latenz -Effizienz (Flash-Lite) und führt ein -latest Aliase für eine schnellere Iteration. Externe Benchmarks von Künstliche Analyse angeben sinnvoll Durchsatz Und Intelligenz-Index Gewinne für die September 2025. Vorschau, wobei Flash-Lite jetzt als die getestet wird schnellster proprietäres Modell in ihrem Gurt. Überprüfen Sie Ihre Arbeitsbelastung-insbesondere Stapel von Browser-Agent-, bevor Sie sich zu den Aliase in der Produktion verpflichten.

Michal Sutter ist ein Datenwissenschaftler bei einem Grasp of Science in Knowledge Science von der College of Padova. Mit einer soliden Grundlage für statistische Analyse, maschinelles Lernen und Datentechnik setzt Michal aus, um komplexe Datensätze in umsetzbare Erkenntnisse umzuwandeln.