
Agentische KI-Systeme basieren auf großen Sprachmodellen und stellen eine Verbindung zu Instruments, Speicher und externen Umgebungen her. Sie unterstützen bereits wissenschaftliche Entdeckungen, Softwareentwicklung und klinische Forschung, kämpfen jedoch immer noch mit unzuverlässiger Werkzeugnutzung, schwacher langfristiger Planung und schlechter Verallgemeinerung. Die neueste Forschungsarbeit ‚Anpassung der Agenten-KIVon Stanford, Harvard, UC Berkeley schlägt Caltech eine einheitliche Sicht darauf vor, wie sich diese Systeme anpassen sollten, und ordnet vorhandene Methoden einem kompakten, mathematisch definierten Rahmen zu.
Wie diese Forschungsarbeit ein Agenten-KI-System modelliert?
Die Forschungsumfrage modelliert ein Agenten-KI-System als Basismodellagenten zusammen mit drei Schlüsselkomponenten. Ein Planungsmodul zerlegt Ziele in Handlungssequenzen und verwendet dabei statische Verfahren wie Chain-of-Thought und Tree-of-Thought oder dynamische Verfahren wie ReAct und Reflexion, die auf Suggestions reagieren. Ein Instrument-Nutzungsmodul verbindet den Agenten mit Websuchmaschinen, APIs, Codeausführungsumgebungen, Modellkontextprotokollen und Browserautomatisierung. Ein Speichermodul speichert kurzfristigen Kontext und langfristiges Wissen, auf das durch Retrieval Augmented Era zugegriffen wird. Die Anpassung ändert Eingabeaufforderungen oder Parameter für diese Komponenten mithilfe überwachter Feinabstimmung, präferenzbasierter Methoden wie der direkten Präferenzoptimierung, Methoden des verstärkenden Lernens wie der Optimierung der Proximalrichtlinie und der Optimierung der relativen Gruppenrichtlinie sowie parametereffizienter Techniken wie der Adaption niedriger Ränge.
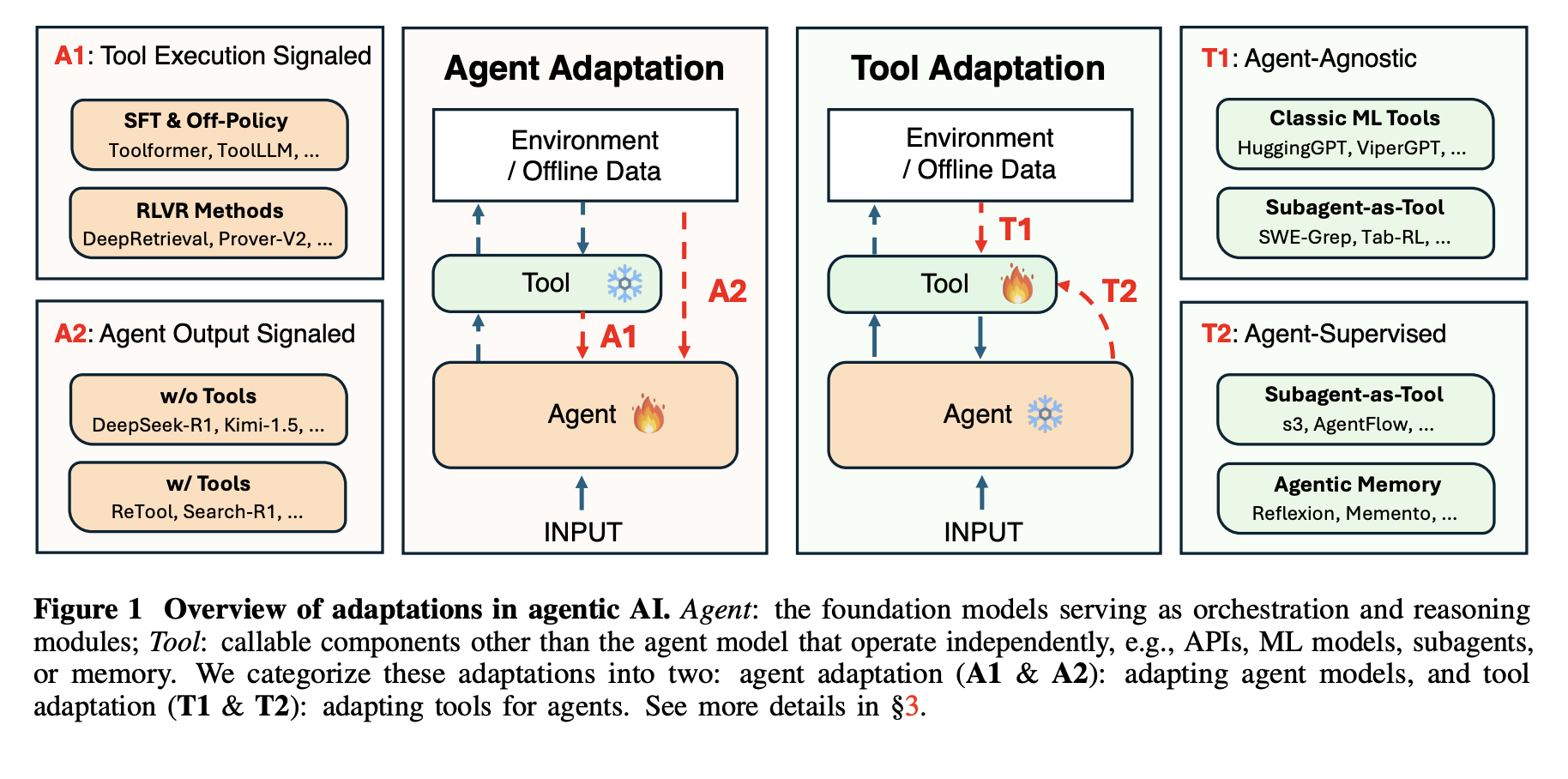
Vier Anpassungsparadigmen
Das Framework definiert 4 Anpassungsparadigmen durch die Kombination von 2 binären Entscheidungen. Die erste Dimension ist das Ziel, Agentenanpassung versus Werkzeuganpassung. Die zweite Dimension ist das Überwachungssignal, die Instrument-Ausführung im Vergleich zur Agenten-Ausgabe. Daraus ergeben sich A1 und A2 für die Anpassung des Agenten und T1 und T2 für die Anpassung der Werkzeuge.
A1, Instrument Execution Signaled Agent Adaptation, optimiert den Agenten mithilfe von Suggestions aus der Toolausführung. A2, Agent Output Signaled Agent Adaptation, optimiert den Agenten mithilfe eines Indicators, das nur an seinen endgültigen Ausgängen definiert ist. T1, Agent-Agnostic Instrument Adaptation, optimiert Instruments, ohne sich auf einen bestimmten Agenten zu beziehen. T2, Agent-Supervised Instrument Adaptation, optimiert Instruments unter Aufsicht eines festen Agenten.
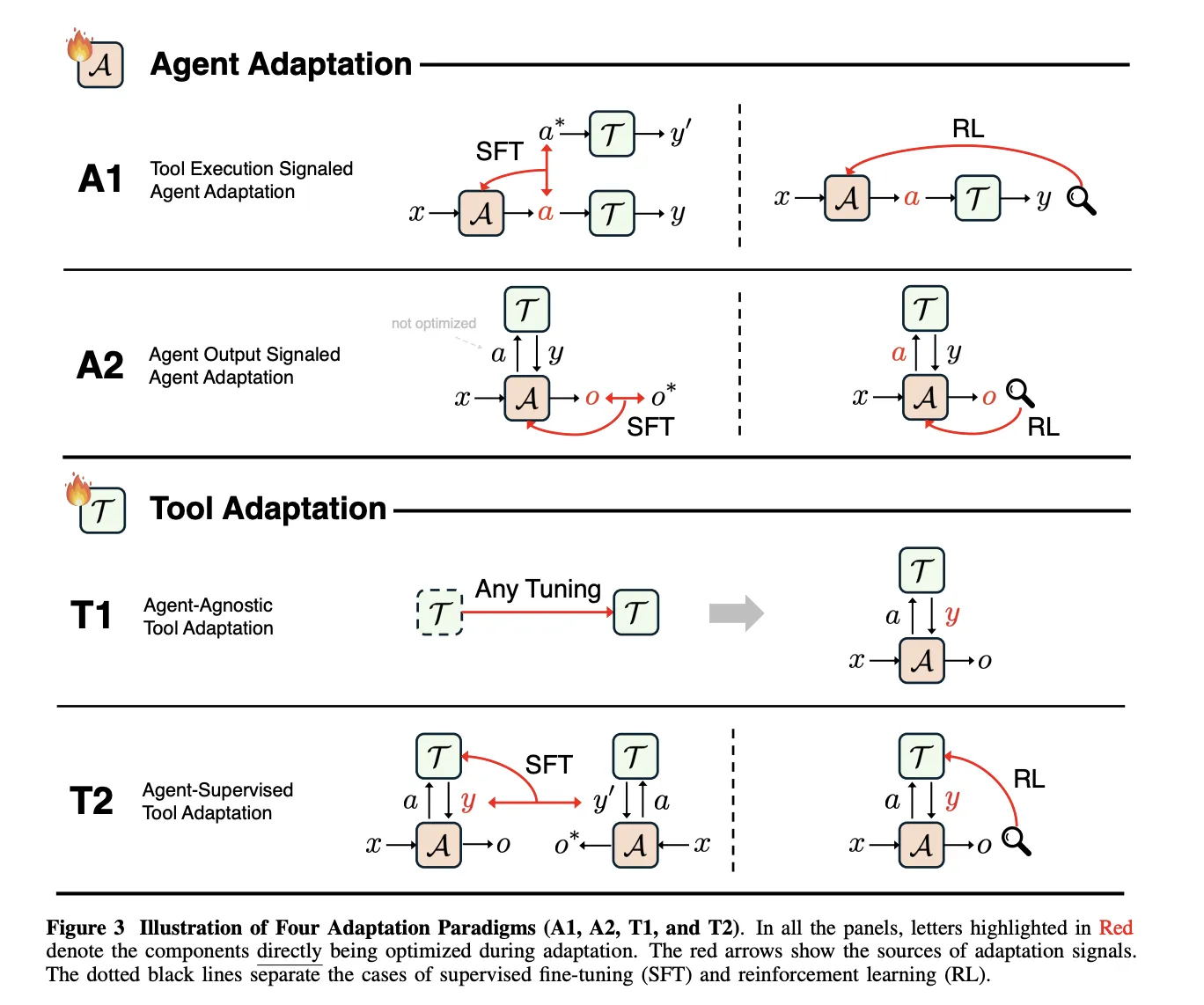
A1, Lernen aus überprüfbarem Instrument-Suggestions
In A1 empfängt der Agent eine Eingabe x, erzeugt einen strukturierten Instrument-Aufruf a, die Instruments geben ein Ergebnis y zurück und das Lernziel O_tool misst den Instrument-Erfolg, zum Beispiel die Richtigkeit der Ausführung oder die Qualität des Abrufs. Der Artikel behandelt sowohl die überwachte Nachahmung erfolgreicher Werkzeugverläufe als auch das verstärkende Lernen, bei dem überprüfbare Werkzeugergebnisse als Belohnung verwendet werden.
Toolformer, ToolAlpaca und Gorilla veranschaulichen überwachte A1-Methoden, da jede Ausführungsergebnisse realer Instruments verwendet, um Trainingsspuren vor der Nachahmung zu erstellen oder zu filtern. Bei allen bleibt das Überwachungssignal auf der Ebene des Werkzeugverhaltens definiert, nicht auf der Ebene der endgültigen Antwort.
DeepRetrieval ist ein zentrales Beispiel für verstärktes A1-Lernen. Es stellt die Abfrageneuformulierung als einen Markov-Entscheidungsprozess dar, bei dem der Standing die Benutzerabfrage ist, die Aktion eine umgeschriebene Abfrage ist und die Belohnung Abrufmetriken wie Recall und nDCG, einen Formatbegriff, und, für Textual content zu SQL, SQL-Ausführungsgenauigkeit kombiniert. Die Richtlinie wird mit KL-regularisierter Proximal-Richtlinienoptimierung trainiert und das gleiche Ziel umfasst die Literatursuche, die Beantwortung von Korpusfragen und die Textausgabe in SQL.
A2, Lernen aus den endgültigen Agentenausgaben
A2 deckt Fälle ab, in denen das Optimierungsziel O_Agent nur von der endgültigen Ausgabe o abhängt, die vom Agenten erzeugt wird, selbst wenn der Agent intern Instruments verwendet. Die Umfrage zeigt, dass die alleinige Überwachung von o nicht ausreicht, um Werkzeuge beizubringen, da der Agent Werkzeuge ignorieren und dennoch die Wahrscheinlichkeit verbessern kann. Effektive A2-Systeme kombinieren daher die Überwachung von Instrument-Aufrufen mit der Überwachung von endgültigen Antworten oder weisen o spärliche Belohnungen zu, wie z. B. die Genauigkeit der exakten Übereinstimmung, und verbreiten sie über die gesamte Flugbahn zurück.
T1, agentenunabhängiges Instrument-Coaching
T1 friert den Hauptagenten ein und optimiert die Instruments, sodass sie weitgehend wiederverwendbar sind. Das Ziel O_tool hängt nur von den Werkzeugausgaben ab und wird anhand von Metriken wie Abrufgenauigkeit, Rating-Qualität, Simulationstreue oder Erfolg nachgelagerter Aufgaben gemessen. Von A1 trainierte Suchrichtlinien wie DeepRetrieval können später als T1-Instruments in neuen Agentensystemen wiederverwendet werden, ohne den Hauptagenten zu ändern.
T2, Werkzeuge optimiert unter einem gefrorenen Agenten
T2 geht von einem leistungsstarken, aber festen Agenten A aus, was häufig der Fall ist, wenn es sich bei dem Agenten um ein Closed-Supply-Grundmodell handelt. Das Instrument führt Aufrufe aus und gibt Ergebnisse zurück, die der Agent dann zur Erstellung von o verwendet. Das Optimierungsziel lebt wieder von O_agent, aber die trainierbaren Parameter gehören zum Instrument. Das Papier beschreibt qualitätsgewichtetes Coaching, zielbasiertes Coaching und Reinforcement-Studying-Varianten, die alle Lernsignale für das Instrument aus den endgültigen Agentenausgaben ableiten.
Die Umfrage behandelt das Langzeitgedächtnis als Sonderfall von T2. Der Speicher ist ein externer Speicher, der durch gelernte Funktionen geschrieben und gelesen wird, und der Agent bleibt eingefroren. Zu den jüngsten T2-Systemen gehören s3, das einen 7-Milliarden-Parametersucher trainiert, der eine durch einen eingefrorenen Generator definierte Acquire-Past-RAG-Belohnung maximiert, und AgentFlow, das einen Planer trainiert, größtenteils eingefrorene Qwen2.5-basierte Module mithilfe von Circulate GRPO zu orchestrieren.
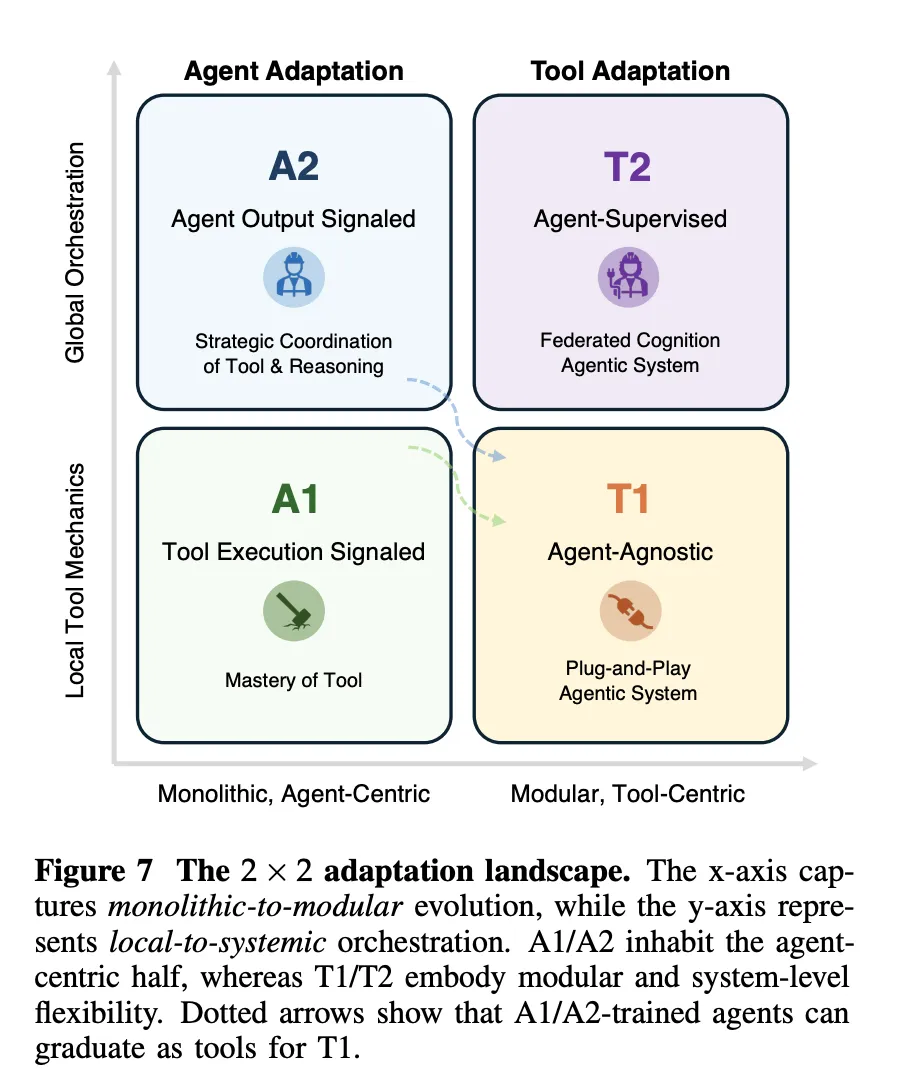
Wichtige Erkenntnisse
- Die Forschung definiert einen präzisen 4-Paradigmen-Rahmen für die Anpassung der Agenten-KI, indem sie zwei Dimensionen kreuzt: ob die Anpassung auf den Agenten oder die Instruments abzielt und ob das Überwachungssignal von der Toolausführung oder von den endgültigen Agentenausgaben kommt.
- A1-Methoden wie Toolformer, ToolAlpaca, Gorilla und DeepRetrieval passen den Agenten direkt anhand von überprüfbarem Instrument-Suggestions an, einschließlich Abrufmetriken, SQL-Ausführungsgenauigkeit und Codeausführungsergebnissen, oft optimiert mit KL-regularisierter Proximal Coverage Optimization.
- A2-Methoden optimieren den Agenten anhand von Signalen zu endgültigen Ausgaben, beispielsweise Antwortgenauigkeit, und das Papier zeigt, dass Systeme immer noch Werkzeugaufrufe überwachen oder spärliche Belohnungen über vollständige Trajektorien verbreiten müssen, andernfalls kann der Agent Werkzeuge ignorieren und gleichzeitig die Wahrscheinlichkeit erhöhen.
- T1 und T2 verlagern das Lernen auf Werkzeuge und Gedächtnis, T1 trainiert allgemein nützliche Retriever, Sucher und Simulatoren ohne einen bestimmten Agenten im Hinterkopf, während T2 Werkzeuge unter einem eingefrorenen Agenten anpasst, wie in s3 und AgentFlow, wo ein fester Generator einen erlernten Sucher und Planer überwacht.
- Das Forschungsteam stellt eine Anpassungslandschaft vor, die monolithische versus modulare und lokale versus systemische Kontrolle in Beziehung setzt, und argumentiert, dass praktische Systeme seltene A1- oder A2-Updates auf einem starken Basismodell mit häufigen T1- und T2-Anpassungen von Retrievern, Suchrichtlinien, Simulatoren und Speicher für Robustheit und Skalierbarkeit kombinieren.
Schauen Sie sich das an Papier Und GitHub-Repo. Sie können uns auch gerne weiter folgen Twitter und vergessen Sie nicht, bei uns mitzumachen 100.000+ ML SubReddit und Abonnieren Unser Publication. Warten! Bist du im Telegram? Jetzt können Sie uns auch per Telegram kontaktieren.

Michal Sutter ist ein Knowledge-Science-Experte mit einem Grasp of Science in Knowledge Science von der Universität Padua. Mit einer soliden Grundlage in statistischer Analyse, maschinellem Lernen und Datentechnik ist Michal hervorragend darin, komplexe Datensätze in umsetzbare Erkenntnisse umzuwandeln.