
Einbettungge Ist das neue offene Texteinbettungsmodell von Google für On-Machine-KI optimiert, um die Effizienz mit modernster Abrufleistung in Einklang zu bringen.
Wie kompakt ist ein Emettdinggeemma im Vergleich zu anderen Modellen?
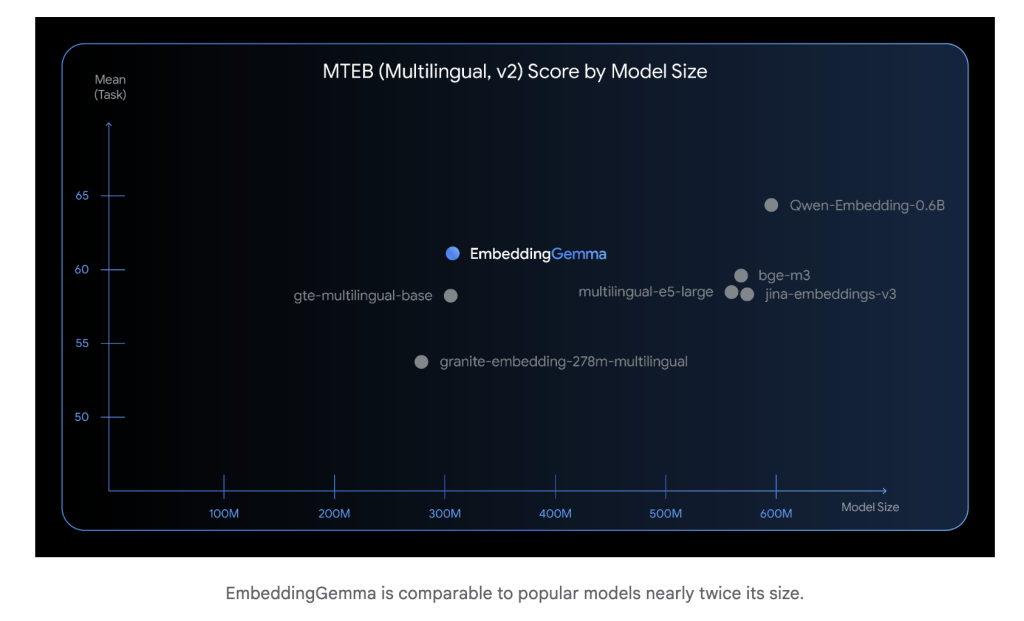
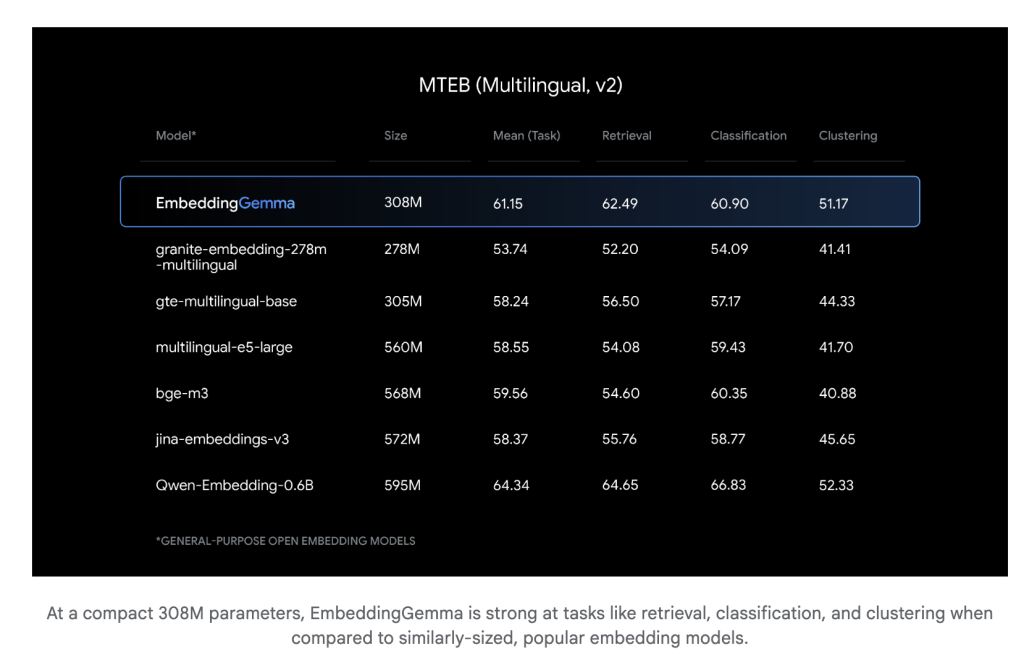
Bei gerecht 308 Millionen ParameterDas Einbettungsgemma ist leicht genug, um auf mobilen Geräten und Offline -Umgebungen auszuführen. Trotz seiner Größe führt es wettbewerbsfähig mit viel größeren Einbettungsmodellen. Die Inferenzlatenz ist niedrig (unter 15 ms für 256 Token auf EdgetPU), was es für Echtzeitanwendungen geeignet ist.
Wie intestine funktioniert es bei mehrsprachigen Benchmarks?
Einbettungsgemma wurde übertrifft Über 100 Sprachen und erreichte die Höchstes Rang für den massiven Textbettverbindungs -Benchmark (MTEB) Unter den Modellen unter 500 m Parametern. Seine Leistungsrivalen oder übertrifft die Einbettungsmodelle quick doppelt so groß wie bei der regelwendenden Wiederholung und semantischer Suche.
Was ist die zugrunde liegende Architektur?
Einbettungsgemma basiert auf einem Gemma 3 -basiertes Encoder -Rückgrat mit mittlerem Pooling. Wichtig ist, dass die Architektur nicht die multimodalspezifischen bidirektionalen Aufmerksamkeitsebenen verwendet, die Gemma 3 für Bildeingaben gilt. Stattdessen setzt Embedinggeemma a Standardtransformator-Encoder-Stapel mit Selbstbeziehung voller Sequenzwas typisch für Texteinbettungsmodelle ist.
Dieser Encoder produziert 768-dimensionale Einbettungen und unterstützt Sequenzen bis zu 2.048 Tokendamit es intestine geeignet ist, um die Era (RAG) und die Langdokumentsuche zu ärgern. Der mittlere Pooling-Schritt sorgt unabhängig von der Eingangsgröße mit festen Länge Vektor-Darstellungen.
Was macht seine Einbettungen flexibel?
Einbettunggeemma beschäftigt Matryoshka Repräsentation Lernen (MRL). Auf diese Weise können Einbettungen von 768 Abmessungen auf 512, 256 oder sogar 128 Dimensionen mit minimalem Qualitätsverlust abgeschnitten werden. Entwickler können den Kompromiss zwischen Speicherungseffizienz und Abrufpräzision ohne Umschulung einstellen.
Kann es völlig offline laufen?
Ja. Einbettunggeemma wurde speziell für die Auseinandersetzung für On-Machine, Offline-First-Anwendungsfälle. Da teilt es einen Tokenizer mit Gemma 3nDie gleichen Einbettungen können die Pipelinien für lokale Lappen direkt kompakte Abrufpipelines direkt mit Strom versorgen, wobei die Privatsphäre von der Vermeidung von Cloud -Inferenz profitiert.
Welche Instruments und Frameworks unterstützen das Emettdinggeemma?
Es integriert nahtlos in:
- Umarmtes Gesicht (Transformatoren, Satztransformer, Transformatoren.js)
- Langchain Und Llamaindex Für Lag -Pipelines
- Waviate und andere Vektor -Datenbanken
- Onnx -Laufzeit Für eine optimierte Bereitstellung über Plattformen hinweg eine optimierte Bereitstellung
Dieses Ökosystem stellt sicher, dass Entwickler es direkt in vorhandene Workflows versetzen können.
Wie kann es in der Praxis implementiert werden?
(1) Belastung und Einbettung
from sentence_transformers import SentenceTransformer
mannequin = SentenceTransformer("google/embeddinggemma-300m")
emb = mannequin.encode(("instance textual content to embed"))
(2) Einbettungsgröße einstellen
Verwenden Sie volle 768 Dims für maximale Genauigkeit oder verkürzen sich auf 512/256/128 DIMs für niedrigere Speicher oder schnelleres Abrufen.
(3) in Lappen integrieren
Führen Sie die Ähnlichkeitssuche lokal aus (Cosinus -Ähnlichkeit) und füttern Sie Prime -Ergebnisse in Gemma 3n für Era. Dies ermöglicht eine vollständige Offline -Lappenpipeline.

Warum Einbettunggeemma?
- Effizienz in Skala – hohe mehrsprachige Abrufgenauigkeit in einem kompakten Fußabdruck.
- Flexibilität – Einstellbare Einbettungsabmessungen über MRL.
- Privatsphäre -Finish-to-Finish-Offline-Pipelines ohne externe Abhängigkeiten.
- Zugänglichkeit – Öffnen Sie Gewichte, zulässige Lizenzierung und starke Unterstützung für Ökosysteme.
Einbettunggeemma beweist das Kleinere Einbettungsmodelle können eine erstklassige Abrufleistung erzielen während sie leicht genug für den Offline -Bereitstellen sind. Es markiert einen wichtigen Schritt in Richtung effizienter, Privatsphäre und skalierbarer Einsatz-KI.
Schauen Sie sich das an Modell Und Technische Particulars. Fühlen Sie sich frei, unsere zu überprüfen Github -Seite für Tutorials, Codes und Notizbücher. Fühlen Sie sich auch frei, uns zu folgen Twitter Und vergessen Sie nicht, sich unserer anzuschließen 100k+ ml Subreddit und abonnieren Unser Publication.
Asif Razzaq ist der CEO von Marktechpost Media Inc. Sein jüngstes Bestreben ist die Einführung einer Medienplattform für künstliche Intelligenz, Marktechpost, die sich durch die ausführliche Berichterstattung über maschinelles Lernen und Deep-Studying-Nachrichten auszeichnet, die von einem breiten Publikum technisch intestine und leicht verständlich sind. Die Plattform verfügt über über 2 Millionen monatliche Ansichten und veranschaulicht ihre Beliebtheit des Publikums.