
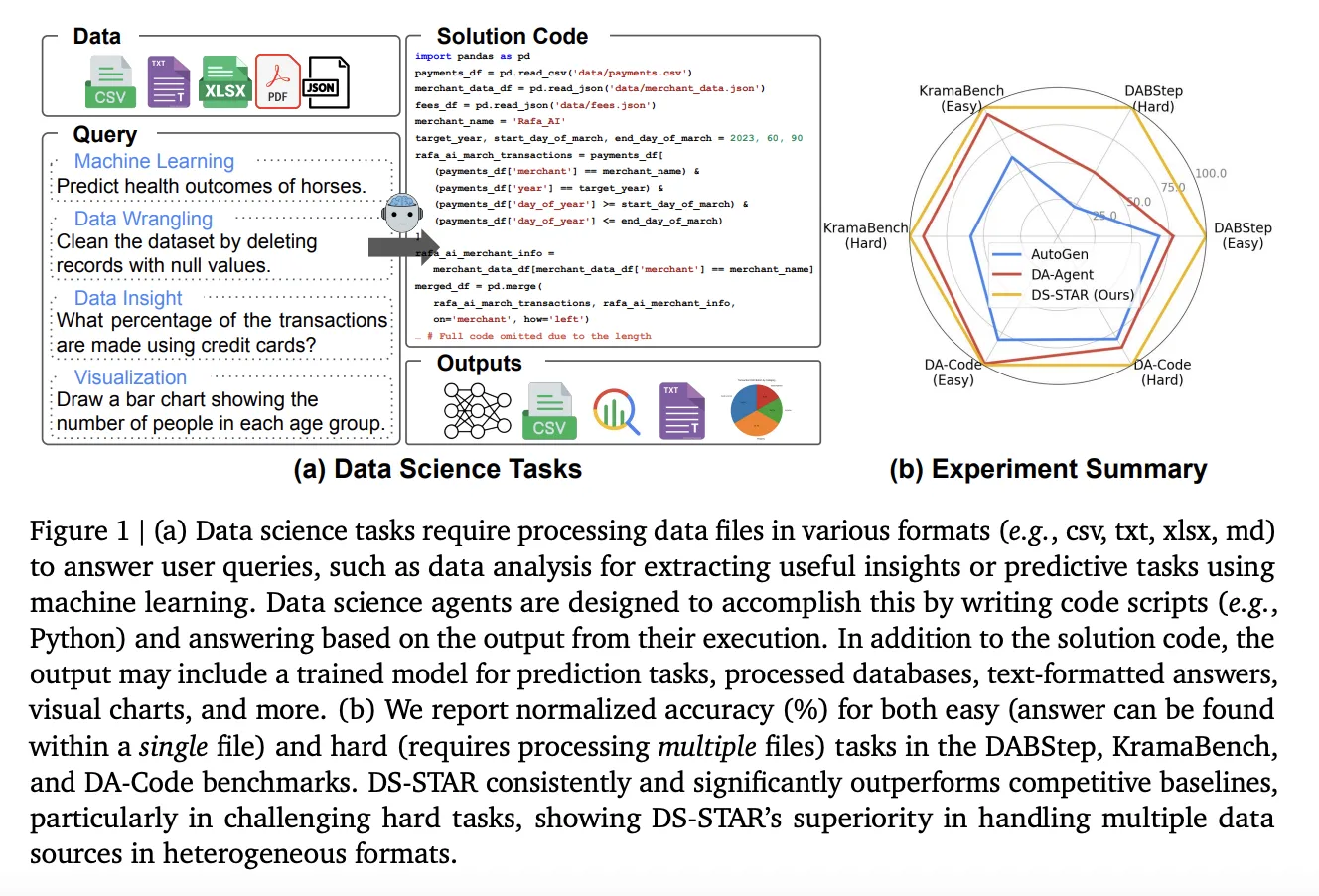
Wie wandeln Sie eine vage Geschäftsfrage über unordentliche CSV-, JSON- und Textordner in zuverlässigen Python-Code um, ohne dass ein menschlicher Analyst auf dem Laufenden ist? Google-Forscher stellen vor DS STAR (Knowledge Science Agent durch iterative Planung und Verifizierung), ein Multi-Agent-Framework, das offene datenwissenschaftliche Fragen in ausführbare Python-Skripte über heterogene Dateien umwandelt. Anstatt von einer sauberen SQL-Datenbank und einer einzelnen Abfrage auszugehen, behandelt DS STAR das Drawback wie folgt Textual content an Python und arbeitet direkt mit gemischten Formaten wie CSV, JSON, Markdown und unstrukturiertem Textual content.
Von Textual content zu Python über heterogene Daten
Bestehende Knowledge-Science-Agenten verlassen sich häufig auf Textual content-to-SQL statt auf relationale Datenbanken. Diese Einschränkung beschränkt sie auf strukturierte Tabellen und einfache Schemata, was nicht für viele Unternehmensumgebungen geeignet ist, in denen Daten über Dokumente, Tabellenkalkulationen und Protokolle verteilt sind.
DS STAR verändert die Abstraktion. Es generiert Python-Code, der alle vom Benchmark bereitgestellten Dateien lädt und kombiniert. Das System fasst zunächst jede Datei zusammen und verwendet dann diesen Kontext, um eine mehrstufige Lösung zu planen, umzusetzen und zu überprüfen. Dieses Design ermöglicht es DS STAR, an Benchmarks wie zu arbeiten DABStep, KramaBank Und DA-Codedie eine mehrstufige Analyse verschiedener Dateitypen erwarten und Antworten in strengen Formaten erfordern.

Stufe 1: Datendateianalyse mit Aanalyzer
In der ersten Part wird eine strukturierte Ansicht des Knowledge Lake erstellt. Für jede Datei (Dᵢ), die Ein Analysator Der Agent generiert ein Python-Skript (sᵢ_desc), das die Datei analysiert und wichtige Informationen wie Spaltennamen, Datentypen, Metadaten und Textzusammenfassungen ausgibt. DS STAR führt dieses Skript aus und erfasst die Ausgabe als prägnante Beschreibung (dᵢ).
Dieser Prozess funktioniert sowohl für strukturierte als auch für unstrukturierte Daten. CSV-Dateien liefern Statistiken und Beispiele auf Spaltenebene, während JSON- oder Textdateien strukturelle Zusammenfassungen und Schlüsselausschnitte liefern. Die Sammlung {dᵢ} wird zum gemeinsamen Kontext für alle späteren Agenten.

Stufe 2: Iterative Planung, Codierung und Überprüfung
Nach der Dateianalyse führt DS STAR eine iterative Schleife aus, die widerspiegelt, wie ein Mensch ein Pocket book verwendet.
- Ein Planer erstellt anhand der Abfrage und der Dateibeschreibungen einen ersten ausführbaren Schritt (p₀), beispielsweise das Laden einer relevanten Tabelle.
- Acoder wandelt den aktuellen Plan (p) in Python-Code(s) um. DS STAR führt diesen Code aus, um eine Beobachtung (r) zu erhalten.
- Mittelwerter ist ein LLM-basierter Richter. Es empfängt den kumulativen Plan, die Abfrage, den aktuellen Code und sein Ausführungsergebnis und gibt eine binäre Entscheidung zurück, ausreichend oder unzureichend.
- Wenn der Plan nicht ausreicht, Arouter entscheidet, wie es verfeinert wird. Es gibt entweder das Token aus Schritt hinzufügendas einen neuen Schritt oder einen Index eines fehlerhaften Schritts anhängt, der abgeschnitten und neu generiert werden soll.
Aplanner ist vom letzten Ausführungsergebnis (rₖ) abhängig, sodass jeder neue Schritt explizit auf das reagiert, was beim vorherigen Versuch schief gelaufen ist. Die Schleife aus Routing, Planung, Codierung, Ausführung und Überprüfung wird fortgesetzt, bis Averifier den Plan als ausreichend markiert oder das System maximal 20 Verfeinerungsrunden erreicht.
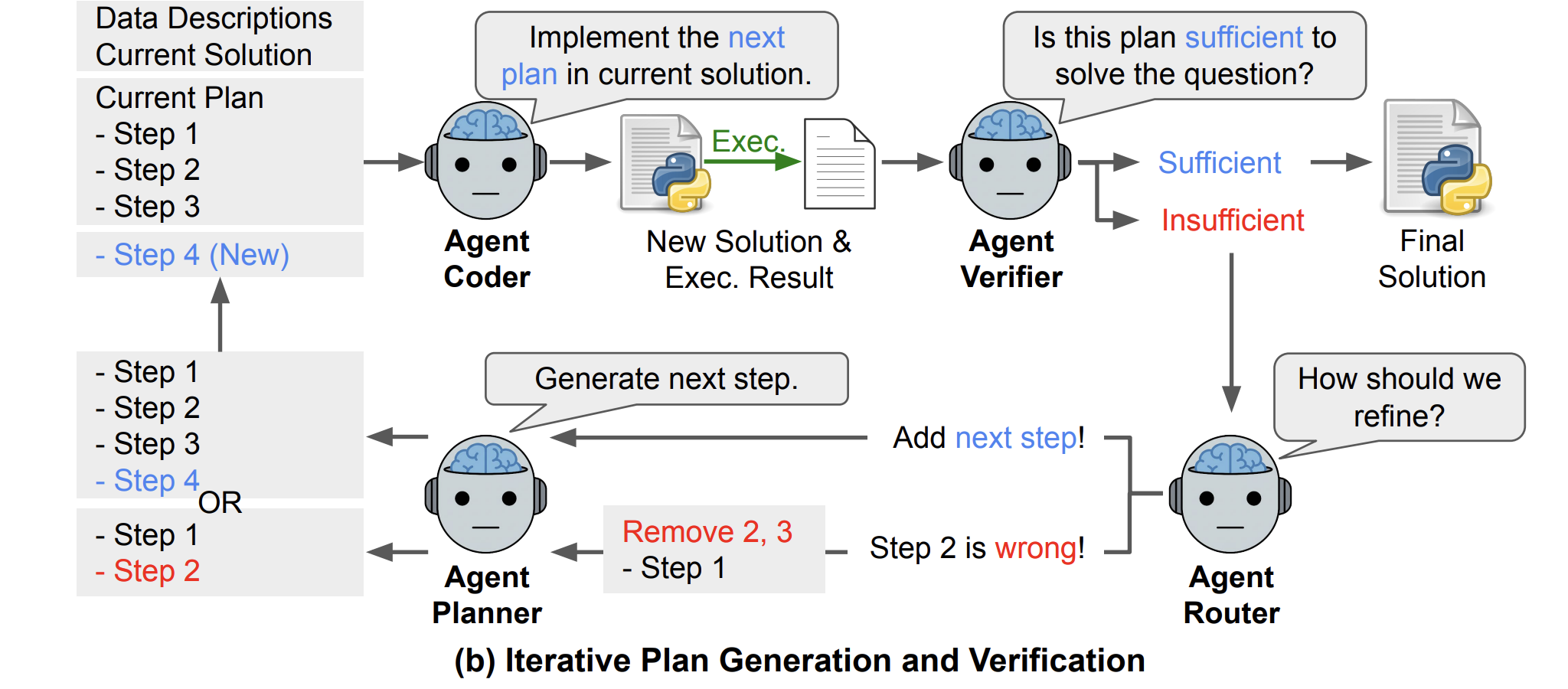
Um strenge Benchmark-Formate zu erfüllen, ist ein separates Ein Finalyzer Der Agent wandelt den endgültigen Plan in Lösungscode um, der Regeln wie Rundung und CSV-Ausgabe durchsetzt.
Robustheitsmodule, Adebugger und Retriever
Realistische Pipelines schlagen aufgrund von Schemadrift und fehlenden Spalten fehl. DS STAR fügt hinzu Adebugger um defekte Skripte zu reparieren. Wenn der Code fehlschlägt, erhält Adebugger das Skript, das Traceback und die Analysebeschreibungen {dᵢ}. Durch die Konditionierung aller drei Signale wird ein korrigiertes Skript generiert. Dies ist wichtig, da viele datenzentrische Fehler Kenntnisse über Spaltenüberschriften, Blattnamen oder Schemata und nicht nur über den Stack-Hint erfordern.
KramaBench stellt eine weitere Herausforderung dar: Tausende Kandidatendateien professional Area. DS STAR erledigt dies mit einem Retriever. Das System bettet die Benutzerabfrage und jede Beschreibung (dᵢ) mithilfe eines vorab trainierten Einbettungsmodells ein und wählt die 100 ähnlichsten Dateien für den Agentenkontext aus oder alle Dateien, wenn es weniger als 100 gibt. Bei der Implementierung verwendete das Forschungsteam Zwillinge Einbettung 001 zur Ähnlichkeitssuche.
Benchmark-Ergebnisse für DABStep, KramaBench und DA-Code
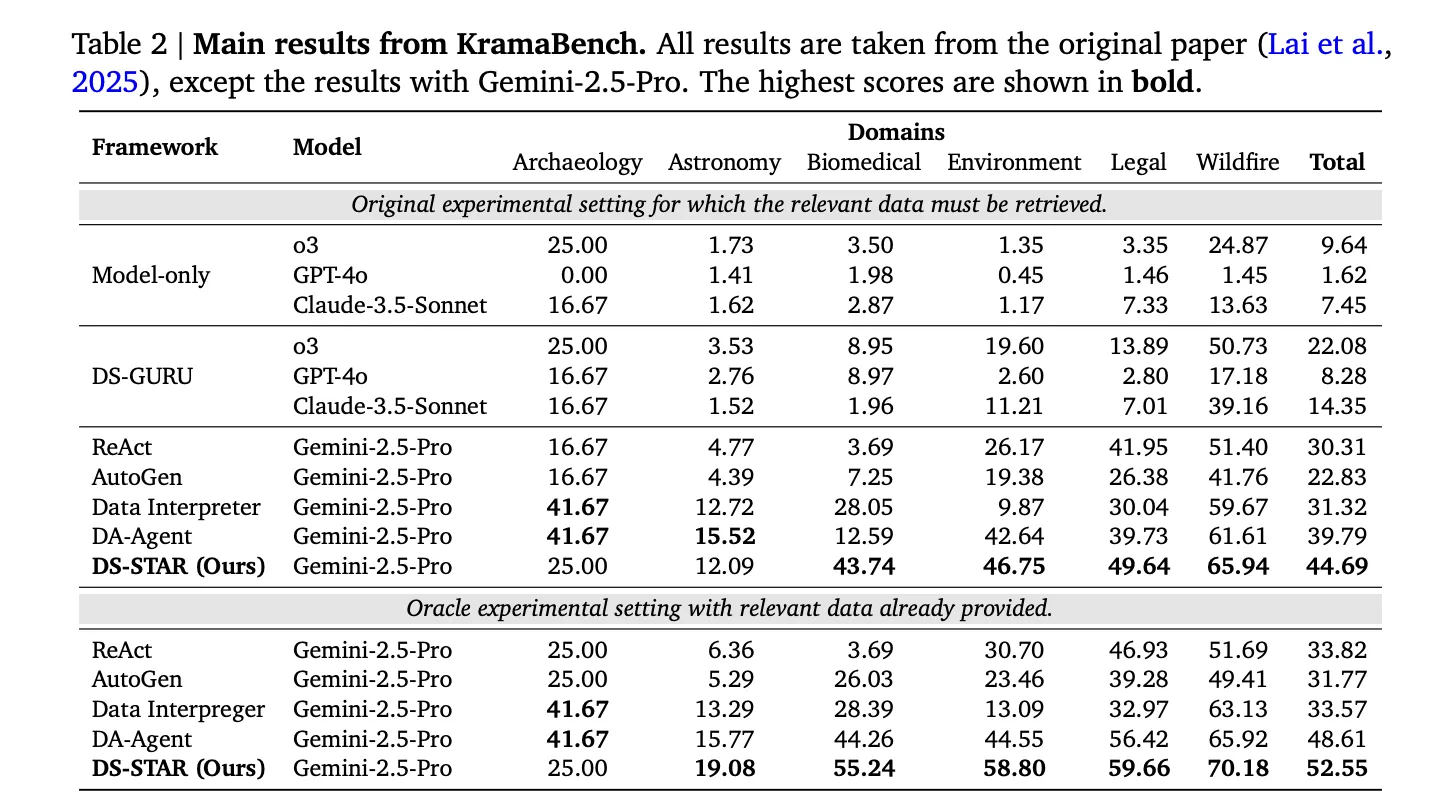
Alle Hauptexperimente laufen mit DS STAR Gemini 2.5 Professional als Foundation-LLM und ermöglicht bis zu 20 Verfeinerungsrunden professional Aufgabe.
An DABStepNur das Modell Gemini 2.5 Professional erreicht eine Genauigkeit von 12,70 Prozent auf hartem Niveau. DS STAR erreicht mit dem gleichen Modell 45,24 Prozent bei schweren Aufgaben und 87,50 Prozent bei leichten Aufgaben. Dies ist ein absoluter Zuwachs von mehr als 32 Prozentpunkten gegenüber der harten Aufteilung und übertrifft andere Agenten wie ReAct, AutoGen, Knowledge Interpreter, DA Agent und mehrere kommerzielle Systeme, die in der öffentlichen Bestenliste aufgeführt sind.

Das Google-Forschungsteam berichtet, dass DS STAR im Vergleich zum besten Alternativsystem bei jedem Benchmark die Gesamtgenauigkeit von 41,0 Prozent auf 45,2 Prozent bei DABStep, von 39,8 Prozent auf 44,7 Prozent bei KramaBench und von 37,0 Prozent auf 38,5 Prozent bei DA Code verbessert.

Für KramaBankwas das Abrufen relevanter Dateien aus großen domänenspezifischen Knowledge Lakes erfordert, erreichen DS STAR mit Retrieval und Gemini 2.5 Professional einen normalisierten Gesamtwert von 44,69. Die stärkste Basislinie, DA Agent mit demselben Modell, erreicht 39,79.
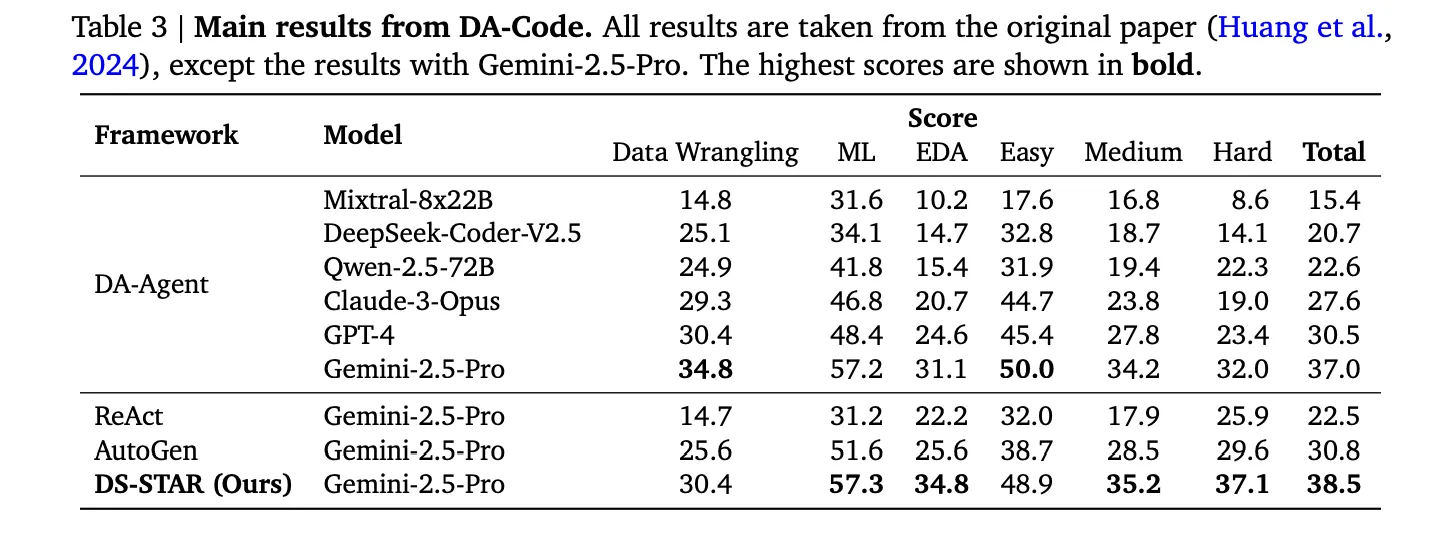
An DA-CodeDS STAR schlägt erneut DA Agent. Bei schwierigen Aufgaben erreicht DS STAR eine Genauigkeit von 37,1 Prozent gegenüber 32,0 Prozent für DA Agent, wenn beide Gemini 2.5 Professional verwenden.
Wichtige Erkenntnisse
- DS STAR reformatiert Knowledge-Science-Agenten als Textual content-to-Python über heterogene Dateien wie CSV, JSON, Markdown und Textual content, statt nur Textual content-to-SQL über saubere relationale Tabellen.
- Das System verwendet eine Multi-Agenten-Schleife mit Aanalyzer, Aplanner, Acoder, Averifier, Arouter und Afinalyzer, die Python-Code iterativ plant, ausführt und überprüft, bis der Verifizierer die Lösung als ausreichend markiert.
- Adebugger und ein Retriever-Modul verbessern die Robustheit, indem sie fehlerhafte Skripte mithilfe umfangreicher Schemabeschreibungen reparieren und die 100 relevantesten Dateien aus großen domänenspezifischen Datenseen auswählen.
- Mit Gemini 2.5 Professional und 20 Verfeinerungsrunden erzielt DS STAR große Fortschritte gegenüber früheren Agenten bei DABStep, KramaBench und DA Code, beispielsweise eine Erhöhung der DABStep-Laborious-Genauigkeit von 12,70 Prozent auf 45,24 Prozent.
- Ablationen zeigen, dass Analyserbeschreibungen und Routing von entscheidender Bedeutung sind, und Experimente mit GPT 5 bestätigen, dass die DS STAR-Architektur modellunabhängig ist, während iterative Verfeinerung für die Lösung schwieriger mehrstufiger Analyseaufgaben unerlässlich ist.
DS STAR zeigt, dass die praktische Knowledge-Science-Automatisierung eine explizite Struktur rund um große Sprachmodelle und nicht nur bessere Eingabeaufforderungen erfordert. Die Kombination von Aanalyzer, Averifier, Arouter und Adebugger verwandelt Freiform-Datenseen in eine kontrollierte Textual content-zu-Python-Schleife, die auf DABStep, KramaBench und DA Code messbar und auf Gemini 2.5 Professional und GPT 5 portierbar ist. Diese Arbeit bewegt Datenagenten von Tabellendemos zu Benchmark-Finish-to-Finish-Analysesystemen.
Schauen Sie sich das an Papier Und Technische Particulars. Schauen Sie sich gerne bei uns um GitHub-Seite für Tutorials, Codes und Notebooks. Sie können uns auch gerne weiter folgen Twitter und vergessen Sie nicht, bei uns mitzumachen 100.000+ ML SubReddit und Abonnieren Unser E-newsletter. Warten! Bist du im Telegram? Jetzt können Sie uns auch per Telegram kontaktieren.
Asif Razzaq ist CEO von Marktechpost Media Inc.. Als visionärer Unternehmer und Ingenieur setzt sich Asif dafür ein, das Potenzial der künstlichen Intelligenz für das soziale Wohl zu nutzen. Sein jüngstes Unterfangen ist die Einführung einer Medienplattform für künstliche Intelligenz, Marktechpost, die sich durch eine ausführliche Berichterstattung über maschinelles Lernen und Deep-Studying-Nachrichten auszeichnet, die sowohl technisch fundiert als auch für ein breites Publikum leicht verständlich ist. Die Plattform verfügt über mehr als 2 Millionen monatliche Aufrufe, was ihre Beliebtheit beim Publikum verdeutlicht.