
Forscher von Cornell und Google stellen ein einheitliches Regressionssprachmodell (RLM) ein, das numerische Ergebnisse direkt aus Code-Saiten-Bekämpfung der GPU-Kernellatenz, der Nutzung des Programms und sogar der Genauigkeit des neuronalen Netzwerks-ohne handgefertigte Merkmale vorhersagt. Ein 300 m-Parameter-Encoder-Decoder, der aus T5-Gemma initialisiert wurde, erreicht starke Rangkorrelationen über heterogene Aufgaben und Sprachen hinweg unter Verwendung eines einzelnen Decoders von Textual content zu Quantity, der Ziffern mit eingeschränkter Decodierung emittiert.
Was genau ist neu?
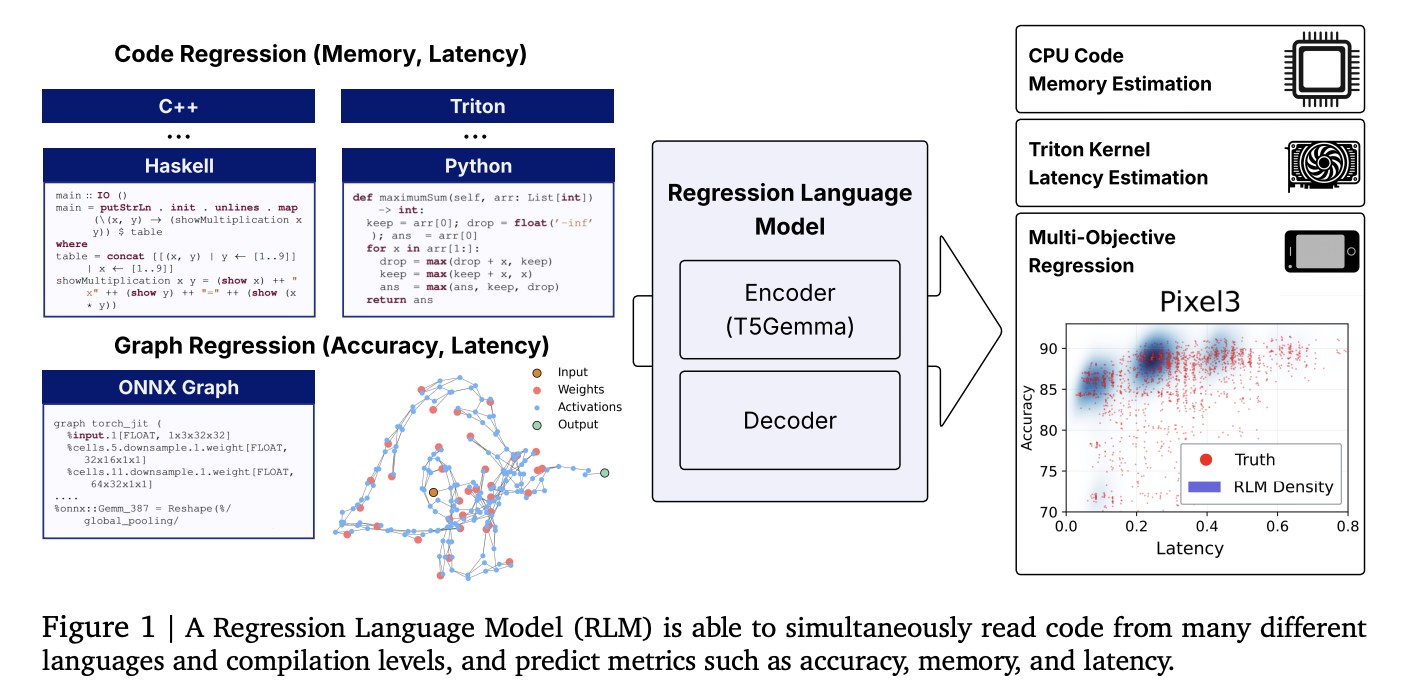
- Einheitliche Regression von Code-zu-Metrie: Ein RLM prognostiziert (i) Peak-Speicher aus dem Code auf hohem Niveau (Python/C/C ++ und mehr), (ii) Latenz für Triton-GPU-Kernel und (iii) Genauigkeit und {Hardware}-spezifische Latenz aus ONNX-Graphmen-durch das Lesen von Rohtextdarstellungen und dekodierenden numerischen Ausgaben. Es sind keine Function Engineering, Graph-Encoder oder Null-Kosten-Proxys erforderlich.
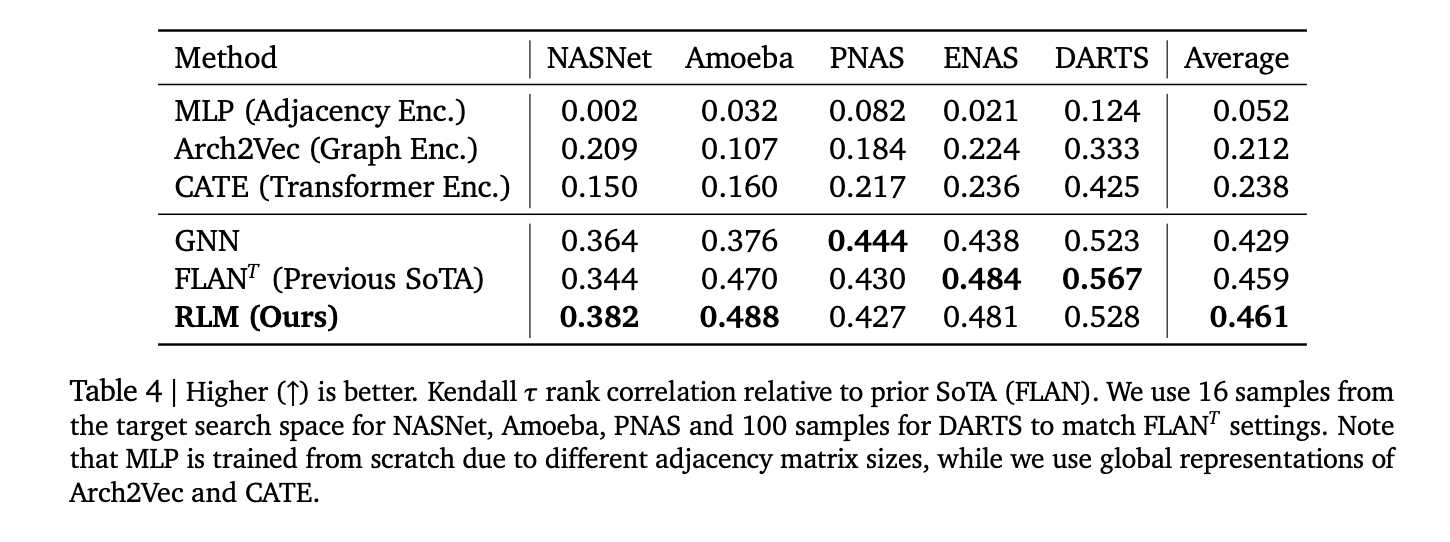
- Konkrete Ergebnisse: Berichtete Korrelationen umfassen Spearman ρ ≈ 0,93 In Apps Leetcode -Speicher, ρ ≈ 0,52 Für Triton Kernel Latenz, ρ> 0,5 Durchschnittsüberschreitend 17 CodenetsprachenUnd Kendall τ ≈ 0,46 In fünf klassischen NAS-Räumen-wettbewerbsfähig mit und in einigen Fällen, die grafische Prädiktoren übertreffen.
- Multi-Objektivdekodierung: Weil der Decoder autoregressiv ist, die Modellbedingungen spätere Metriken früherer (z. B. Latenzen von Genauigkeit → professional Gerät), wobei realistische Kompromisse entlang von Pareto-Fronten erfasst werden.
Warum ist das wichtig?
Efficiency Prediction Pipelines in Compilern, GPU -Kernelauswahl und NAS beruhen typischerweise auf maßgeschneiderten Merkmale, Syntaxbäume oder GNN -Encoder, die für neue OPs/Sprachen spröde sind. Regression behandeln als Nächste Vorhersage über Zahlen Standardisiert den Stapel: Tokenize-Eingänge als einfacher Textual content (Quellcode, Triton IR, ONNX) und dann kalibrierte numerische Zeichenfolgen digital mit eingeschränkter Probenahme entschlüsseln. Dies senkt die Wartungskosten und verbessert die Übertragung auf neue Aufgaben durch Feinabstimmung.
Daten und Benchmarks
- Code-Regressionsdatensatz (HF): Kuratiert zur Unterstützung Code-zu-Metrik Aufgaben über Apps/Leetcode-Ausführungen, Triton-Kernel-Latenzen (Kernelbook-abgeleitet) und Codenet-Speicher-Fußabdrücke.
- Nas/Onnx Suite: Architekturen von Nasbench-101/201, FBNET, einmal für All (MB/PN/RN), Twopath, Hiaml, Inception und ND Onnx -Textual content Genauigkeit und Gerätespezifische Latenz vorherzusagen.
Wie funktioniert es?
- Rückgrat: Encoder -Decoder mit a T5-Gemma Encoder -Initialisierung (~ 300m Parames). Eingänge sind rohe Zeichenfolgen (Code oder ONNX). Ausgänge sind Zahlen als emittiert als Zeichen/Exponent/Mantissa -Ziffern -Token; Die eingeschränkte Dekodierung erzwingt gültige Ziffern und unterstützt die Unsicherheit durch Stichproben.
- Ablationen: (i) Sprachvorbereitung beschleunigt die Konvergenz und verbessert die Vorhersage der Triton -Latenz; (ii) numerische Emission nur Decoder übertrifft MSE-Regressionsköpfe auch bei Y-Normalisierung; (iii) Gelehrte Tokenisierer, die auf ONNX -Operatoren spezialisiert sind, erhöhen den effektiven Kontext; (iv) längere Kontexte helfen; (v) Skalierung zu einem größeren Gemma -Encoder verbessert die Korrelation mit angemessener Stimmung weiter.
- Trainingscode. Der Regress-lm Die Bibliothek bietet Textual content-to-Textual content-Regressions-Dienstprogramme, eingeschränkte Dekodierung und Multi-Job-Rezepte/Feinabstimmungsrezepte.
Statistiken, die zählen
- Apps (Python) Speicher: Spearman ρ> 0,9.
- Codenet (17 Sprachen) Speicher: Durchschnitt ρ> 0,5; Die stärksten Sprachen umfassen C/C ++ (~ 0,74–0,75).
- Triton -Kerne (A6000) Latenz: ρ ≈ 0,52.
- Nas -Rating: Durchschnitt Kendall τ ≈ 0,46 über Nasnet, Amöben, PNAs, Enas, Darts; wettbewerbsfähig mit Flan- und GNN -Baselines.
Key Takeaways
- Unified Code-to-Metric-Regression funktioniert. Ein einzelnes ~ 300 m-Parameter T5Gemma-initialisiertes Modell („RLM“) sagt: (a) Speicher aus Code mit hoher Ebene, (b) Triton-GPU-Kernellatenz und (c) Modellgenauigkeit + Gerätelatenz von ONNX-Regisseur aus Textual content, ohne Hand-Eingefertigte Merkmale.
- Die Forschung zeigt, dass Spearman ρ> 0,9 im Apps-Speicher, ≈0,52 auf Tritonlatenz,> 0,5 durchschnittlich über 17 Codenetsprachen und Kendall-τ ≈ 0,46 auf fünf NAS-Leerzeichen.
- Zahlen werden als Textual content mit Einschränkungen dekodiert. Anstelle eines Regressionskopfes emittiert RLM numerische Token mit eingeschränkter Decodierung und ermöglicht multi-metrische, autoregressive Ausgänge (z. B. Genauigkeit, gefolgt von Latenzen mit mehreren Geräten) und Unsicherheit durch Probenahme.
- Der Code-Regression DataSet vereint Apps/Leetcode -Speicher, Triton -Kernel -Latenz und Codenet -Speicher; Die Regress-lm Die Bibliothek bietet den Trainings-/Dekodierungsstapel.
Es ist sehr interessant, wie diese Arbeit die Leistungsvorhersage als Textual content-zu-Zahlen-Erzeugung neu bearbeitet: Ein kompaktes T5Gemma-initialisierter RLM liest Quelle (Python/C ++), Triton-Kerne oder ONNX-Diagramme und emittiert kalibrierte Numeriken über eingeschränktes Dekodieren. Die gemeldeten Korrelationen-Anpassung des Gedächtnisses (ρ> 0,9), Triton-Latenz auf RTX A6000 (~ 0,52) und Nas Kendall-τ ≈0,46-sind stark genug, um für Compiler-Heuristiken, Kernel-Beschneidungen und Multi-Objektiv-Triage ohne kochende Merkmale oder GNNs oder Multi-Objektiv-NAS-Triage eine Rolle zu spielen. Der offene Datensatz und die Bibliothek machen die Replikation einfach und senken die Barriere für die Feinabstimmung neuer {Hardware} oder Sprachen ab.
Schauen Sie sich das an PapierAnwesend Github -Seite Und Datensatzkarte. Fühlen Sie sich frei, unsere zu überprüfen Github -Seite für Tutorials, Codes und Notizbücher. Fühlen Sie sich auch frei, uns zu folgen Twitter Und vergessen Sie nicht, sich unserer anzuschließen 100k+ ml Subreddit und abonnieren Unser Publication. Warten! Bist du im Telegramm? Jetzt können Sie sich uns auch im Telegramm anschließen.
Asif Razzaq ist der CEO von Marktechpost Media Inc. Sein jüngstes Bestreben ist die Einführung einer Medienplattform für künstliche Intelligenz, Marktechpost, die sich durch die ausführliche Berichterstattung über maschinelles Lernen und Deep-Studying-Nachrichten auszeichnet, die von einem breiten Publikum technisch intestine und leicht verständlich sind. Die Plattform verfügt über über 2 Millionen monatliche Ansichten und veranschaulicht ihre Beliebtheit des Publikums.