
Liquid AI hat LFM2-2.6B-Exp eingeführt, einen experimentellen Prüfpunkt seines LFM2-2.6B-Sprachmodells, der mit reinem Verstärkungslernen auf dem bestehenden LFM2-Stack trainiert wird. Das Ziel ist einfach: Die Befolgung von Anweisungen, Wissensaufgaben und Mathematik für ein kleines 3B-Klassenmodell zu verbessern, das immer noch auf die Geräte- und Edge-Bereitstellung abzielt.
Wo LFM2-2.6B-Exp in die LFM2-Familie passt?
LFM2 ist die zweite Technology der Liquid Basis-Modelle. Es ist für den effizienten Einsatz auf Telefonen, Laptops und anderen Edge-Geräten konzipiert. Liquid AI beschreibt LFM2 als ein Hybridmodell, das LIV-Faltungsblöcke mit kurzer Reichweite mit gruppierten Abfrageaufmerksamkeitsblöcken kombiniert, die durch multiplikative Gatter gesteuert werden.
Die Familie umfasst vier dichte Größen: LFM2-350M, LFM2-700M, LFM2-1.2B und LFM2-2.6B. Alle haben eine Kontextlänge von 32.768 Token, eine Vokabulargröße von 65.536 und eine bfloat16-Präzision. Das 2.6B-Modell verwendet 30 Schichten, davon 22 Faltungsschichten und 8 Aufmerksamkeitsschichten. Jede Größe wird mit einem Price range von 10 Billionen Token trainiert.
LFM2-2.6B ist bereits als hocheffizientes Modell positioniert. Es erreicht 82,41 Prozent bei GSM8K und 79,56 Prozent bei IFEval. Damit liegt es in diesen Benchmarks vor mehreren Modellen der 3B-Klasse wie Llama 3.2 3B Instruct, Gemma 3 4B it und SmolLM3 3B.
LFM2-2.6B-Exp behält diese Architektur bei. Es verwendet dieselbe Tokenisierung, dasselbe Kontextfenster und dasselbe Hardwareprofil wieder. Der Checkpoint konzentriert sich nur auf die Verhaltensänderung durch eine verstärkende Lernphase.
Reines RL auf einer vortrainierten, ausgerichteten Foundation
Dieser Prüfpunkt basiert auf LFM2-2.6B und nutzt reines Verstärkungslernen. Es wird speziell auf die Befolgung von Anweisungen, Wissen und Mathematik geschult.
Der zugrunde liegende LFM2-Trainingsstapel kombiniert mehrere Stufen. Es umfasst eine sehr groß angelegte überwachte Feinabstimmung einer Mischung aus nachgelagerten Aufgaben und allgemeinen Domänen, benutzerdefinierte direkte Präferenzoptimierung mit Längennormalisierung, iterative Modellzusammenführung und verstärkendes Lernen mit überprüfbaren Belohnungen.
Aber genau bedeutet „reines Verstärkungslernen“? LFM2-2.6B-Exp startet am bestehenden LFM2-2.6B-Kontrollpunkt und durchläuft dann einen sequentiellen RL-Trainingsplan. Es beginnt mit der Befolgung von Anweisungen und erweitert dann das RL-Coaching auf wissensorientierte Eingabeaufforderungen, Mathematik und einen kleinen Teil der Werkzeugnutzung, ohne dass in dieser letzten Section ein zusätzlicher SFT-Aufwärm- oder Destillationsschritt erforderlich ist.
Der wichtige Punkt ist, dass LFM2-2.6B-Exp weder die Basisarchitektur noch das Vortraining verändert. Es ändert die Richtlinie durch eine RL-Section, die überprüfbare Belohnungen für eine gezielte Gruppe von Domänen verwendet, zusätzlich zu einem Modell, das bereits überwacht und an Präferenzen ausgerichtet ist.
Benchmark-Sign, insbesondere auf IFBench
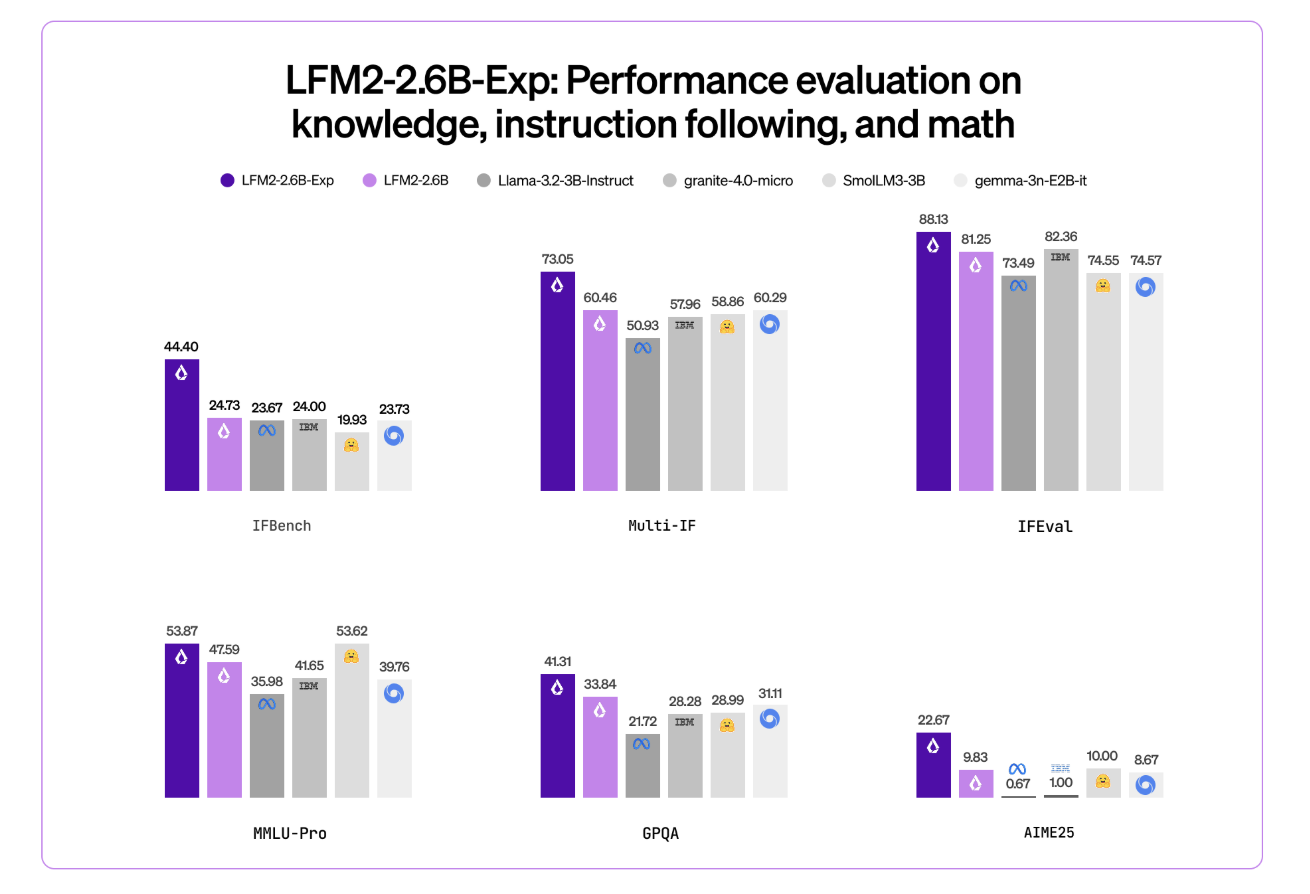
Das Liquid AI-Crew hebt IFBench als wichtigste Schlagzeilenmetrik hervor. IFBench ist ein Anweisungsfolge-Benchmark, der überprüft, wie zuverlässig ein Modell komplexen, eingeschränkten Anweisungen folgt. Bei diesem Benchmark übertrifft LFM2-2.6B-Exp DeepSeek R1-0528, dessen Parameteranzahl 263-mal größer sein soll.
LFM2-Modelle bieten eine starke Leistung bei einem Standardsatz von Benchmarks wie MMLU, GPQA, IFEval, GSM8K und verwandten Suiten. Das 2.6B-Basismodell konkurriert bereits intestine im 3B-Phase. Der RL-Kontrollpunkt treibt dann die Befehlsfolge und die Mathematik weiter voran, während das gleiche 3B-Parameterbudget beibehalten wird.
Architektur und Fähigkeiten, auf die es ankommt
Die Architektur verwendet 10 doppelt geschlossene LIV-Faltungsblöcke mit kurzer Reichweite und 6 gruppierte Abfrageaufmerksamkeitsblöcke, die in einem Hybridstapel angeordnet sind. Dieses Design reduziert die KV-Cache-Kosten und sorgt für schnelle Rückschlüsse auf Client-GPUs und NPUs.
Die Pre-Coaching-Mischung verwendet etwa 75 Prozent Englisch, 20 Prozent mehrsprachige Daten und 5 Prozent Code. Zu den unterstützten Sprachen gehören Englisch, Arabisch, Chinesisch, Französisch, Deutsch, Japanisch, Koreanisch und Spanisch.
LFM2-Modelle stellen eine ChatML-ähnliche Vorlage und native Instrument-Nutzungstoken bereit. Werkzeuge werden als JSON zwischen dedizierten Werkzeuglistenmarkierungen beschrieben. Das Modell gibt dann Python-ähnliche Aufrufe zwischen Werkzeugaufrufmarkierungen aus und liest Werkzeugantworten zwischen Werkzeugreaktionsmarkierungen. Durch diese Struktur eignet sich das Modell als Agentenkern für Instrument-Calling-Stacks ohne benutzerdefiniertes Immediate-Engineering.
LFM2-2.6B und damit auch LFM2-2.6B-Exp sind außerdem das einzige Modell in der Familie, das dynamisches hybrides Denken durch spezielle Denktoken für komplexe oder mehrsprachige Eingaben ermöglicht. Diese Funktion bleibt verfügbar, da der RL-Prüfpunkt weder die Tokenisierung noch die Architektur ändert.
Wichtige Erkenntnisse
- LFM2-2.6B-Exp ist ein experimenteller Prüfpunkt von LFM2-2.6B, der zusätzlich zu einer vorab trainierten, überwachten und präferenzorientierten Foundation eine reine Verstärkungslernphase hinzufügt, die auf die Befolgung von Anweisungen, Wissensaufgaben und Mathematik abzielt.
- Das LFM2-2.6B-Spine verwendet eine Hybridarchitektur, die doppelt geschlossene LIV-Faltungsblöcke mit kurzer Reichweite und gruppierte Abfrage-Aufmerksamkeitsblöcke mit 30 Schichten, 22 Faltungsschichten und 8 Aufmerksamkeitsschichten, einer Kontextlänge von 32.768 Token und einem Trainingsbudget von 10 Billionen Token bei 2,6B-Parametern kombiniert.
- LFM2-2.6B erreicht bereits starke Benchmark-Werte in der 3B-Klasse, rund 82,41 Prozent bei GSM8K und 79,56 Prozent bei IFEval, und der LFM2-2.6B-Exp RL-Checkpoint verbessert die Befehlsfolge und die Mathematikleistung weiter, ohne die Architektur oder das Speicherprofil zu ändern.
- Liquid AI berichtet, dass LFM2-2.6B-Exp im IFBench, einem Anweisungsfolge-Benchmark, DeepSeek R1-0528 übertrifft, obwohl letzterer über viel mehr Parameter verfügt, was eine starke Leistung professional Parameter für eingeschränkte Bereitstellungseinstellungen zeigt.
- LFM2-2.6B-Exp wird auf Hugging Face mit offenen Gewichten unter der LFM Open License v1.0 veröffentlicht und wird durch Transformers, vLLM, llama.cpp GGUF-Quantisierungen und ONNXRuntime unterstützt, wodurch es für Agentensysteme, strukturierte Datenextraktion, Retrieval Augmented Technology und auf Geräteassistenten geeignet ist, bei denen ein kompaktes 3B-Modell erforderlich ist.
Schauen Sie sich das an Modell hier. Sie können uns auch gerne weiter folgen Twitter und vergessen Sie nicht, bei uns mitzumachen 100.000+ ML SubReddit und Abonnieren Unser Publication. Warten! Bist du im Telegram? Jetzt können Sie uns auch per Telegram kontaktieren.
Der Beitrag LFM2-2.6B-Exp von Liquid AI nutzt reines Reinforcement Studying RL und dynamisches hybrides Denken, um das Verhalten kleiner Modelle zu verbessern erschien zuerst auf MarkTechPost.