Wie viel Kapazität kann ein spärlicher 8.3B-Parameter MoE mit einem ~1,5B aktiver Pfad auf Ihrem Telefon liefern, ohne Latenz oder Speicher zu verschwenden? Liquid AI wurde veröffentlicht LFM2-8B-A1B, ein kleines Combination-of-Specialists-Modell (MoE), das für die Ausführung auf dem Gerät unter engen Speicher-, Latenz- und Energiebudgets entwickelt wurde. Im Gegensatz zu den meisten MoE-Arbeiten, die für die Cloud-Batch-Bereitstellung optimiert sind, zielt LFM2-8B-A1B auf Telefone, Laptops und eingebettete Systeme ab. Es zeigt 8,3B Gesamtparameter aber nur aktiviert ~1,5B Parameter professional Tokenwobei Sparse-Professional-Routing verwendet wird, um einen kleinen Rechenpfad beizubehalten und gleichzeitig die Darstellungskapazität zu erhöhen. Das Modell ist unter der veröffentlicht LFM Open License v1.0 (lfm1.0)
Die Architektur verstehen
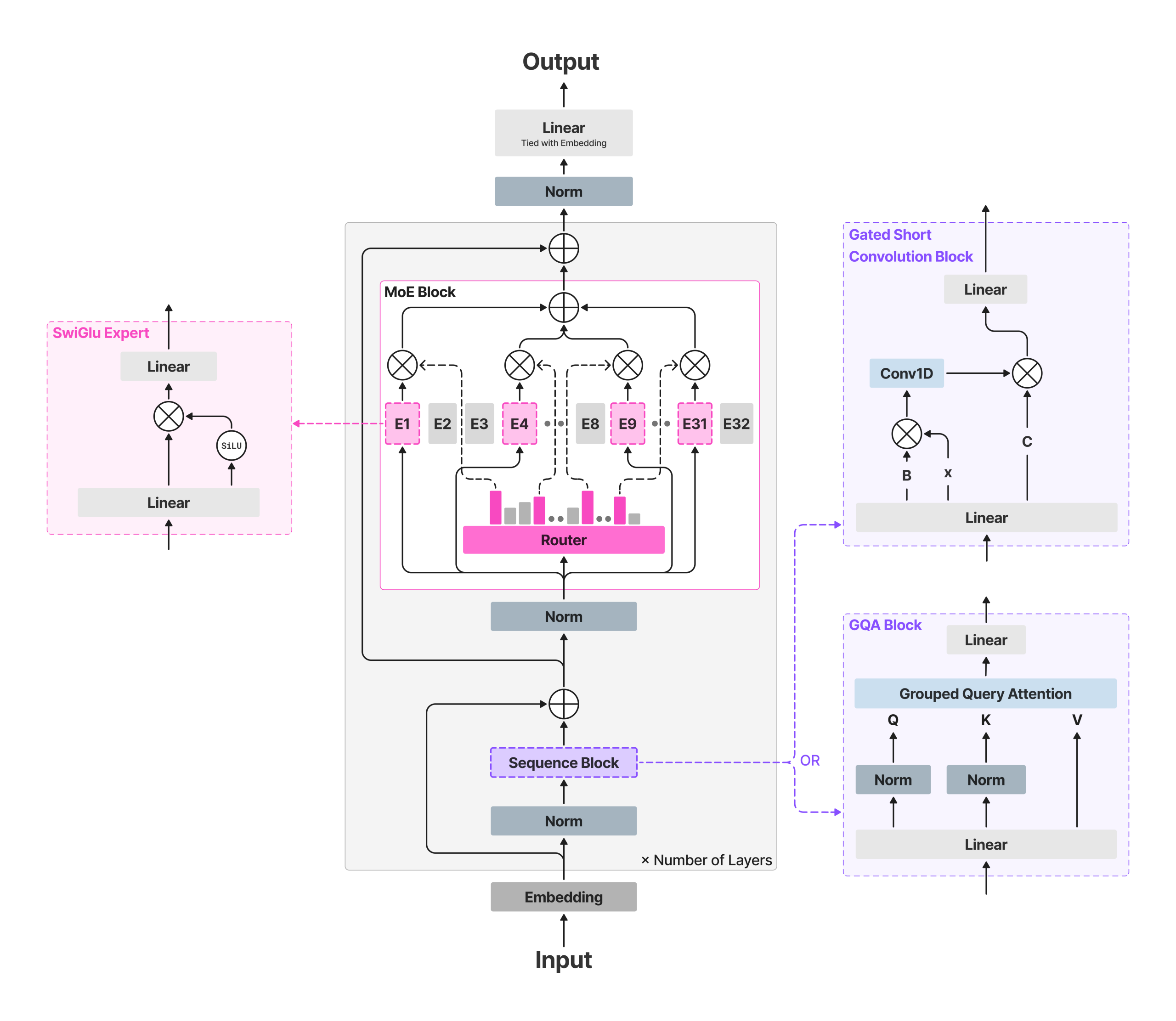
LFM2-8B-A1B behält das „schnelle Spine“ von LFM2 bei und fügt spärliche MoE-Feed-Ahead-Blöcke ein, um die Kapazität zu erhöhen, ohne die aktive Rechenleistung wesentlich zu erhöhen. Das Rückgrat nutzt 18 geschlossene Kurzfaltungsblöcke Und 6 Grouped-Question Consideration (GQA)-Blöcke. Alle Schichten außer den ersten beiden einen MoE-Block einschließen; Die ersten beiden bleiben aus Stabilitätsgründen dicht. Jeder MoE-Block definiert 32 Experten; Der Router wählt Prime-4-Experten professional Token mit einem normalisiertes Sigmoid-Gate Und Adaptive Routing-Voreingenommenheit um die Belastung auszugleichen und das Coaching zu stabilisieren. Die Kontextlänge beträgt 32.768 Token; Wortschatzgröße 65.536; gemeldetes Vorschulungsbudget ~12T-Token.
Dieser Ansatz hält die FLOPs professional Token und das Cache-Wachstum durch den aktiven Pfad (Aufmerksamkeit + vier Experten-MLPs) begrenzt, während die Gesamtkapazität eine Spezialisierung über Domänen wie mehrsprachiges Wissen, Mathematik und Code hinweg ermöglicht – Anwendungsfälle, die sich oft auf sehr kleine dichte Modelle zurückführen lassen.
Leistungssignale
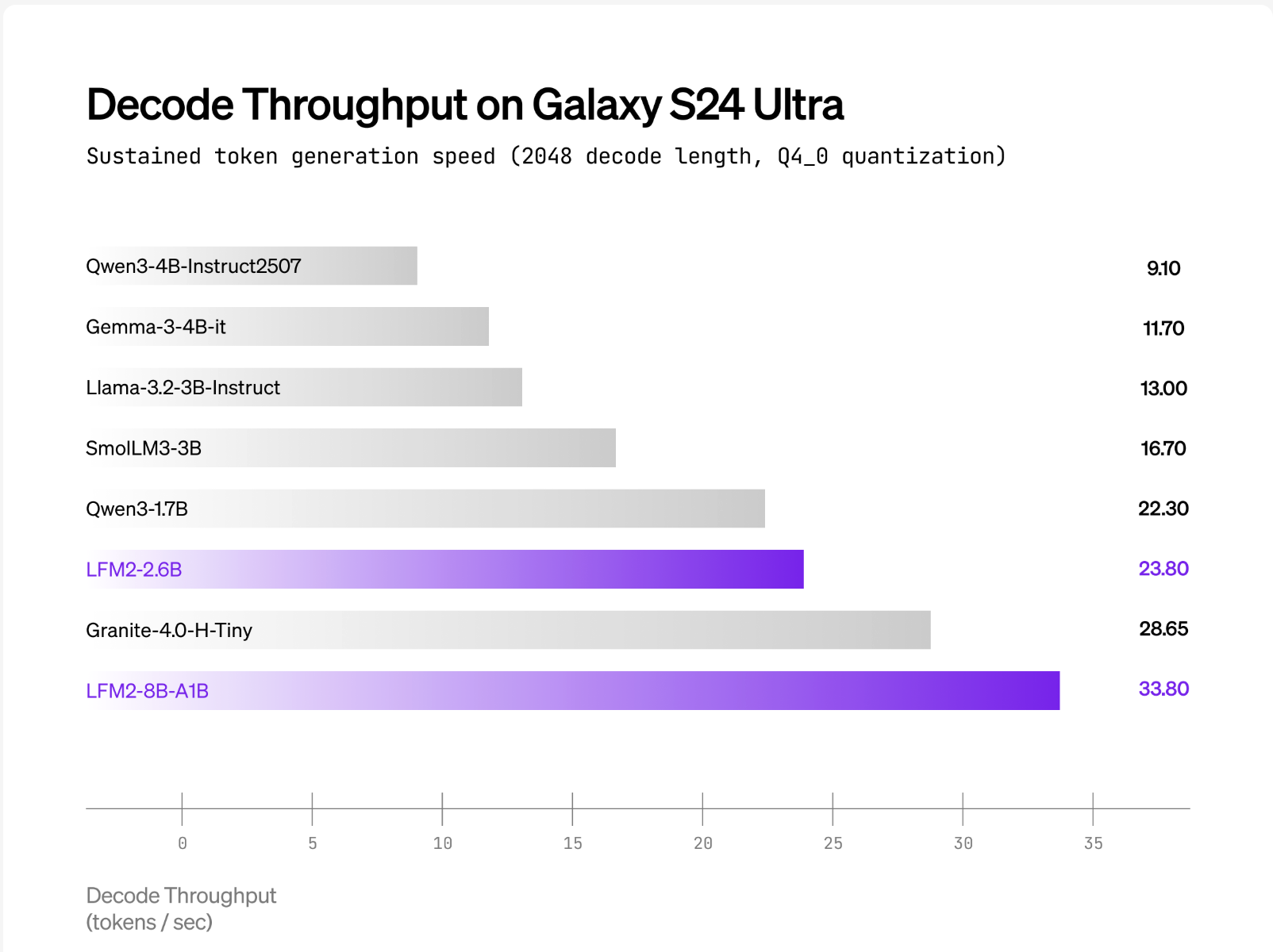
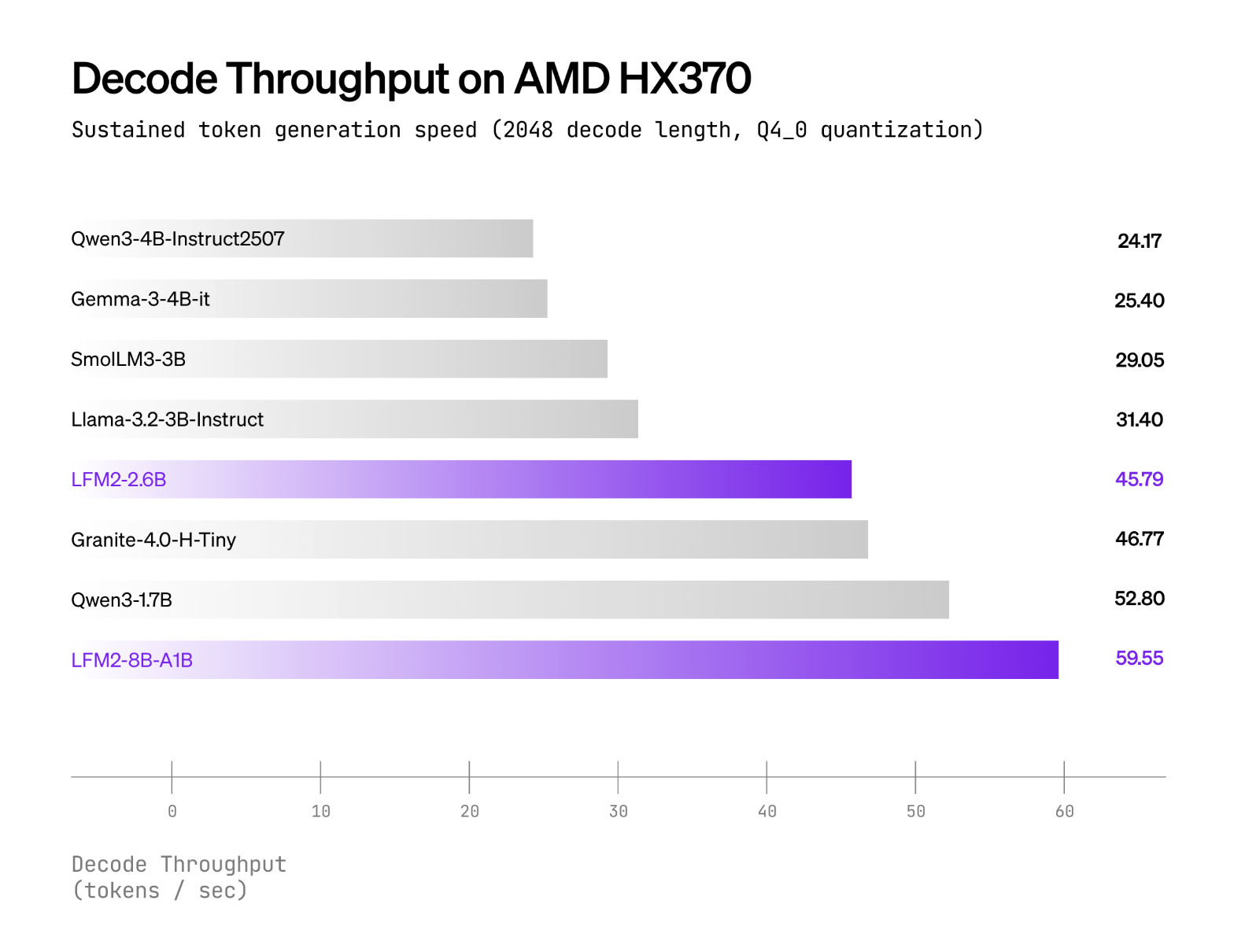
Liquid AI meldet, dass LFM2-8B-A1B läuft deutlich schneller als Qwen3-1.7B unter CPU-Checks mit einem internen XNNPACK-basierten Stack und einem benutzerdefinierten CPU-MoE-Kernel. Die öffentlichen Grundstücke umfassen int4-Quantisierung mit dynamischen int8-Aktivierungen An AMD Ryzen AI 9 HX370 Und Samsung Galaxy S24 Extremely. Das Liquid AI-Workforce positioniert Qualität als vergleichbar mit 3–4B dichte Modellewährend die aktive Rechenleistung in der Nähe bleibt 1,5B. Es werden keine herstellerübergreifenden „×-schneller“-Headline-Multiplikatoren veröffentlicht; Die Behauptungen sind als Vergleiche professional Gerät mit ähnlich aktiven Modellen formuliert.
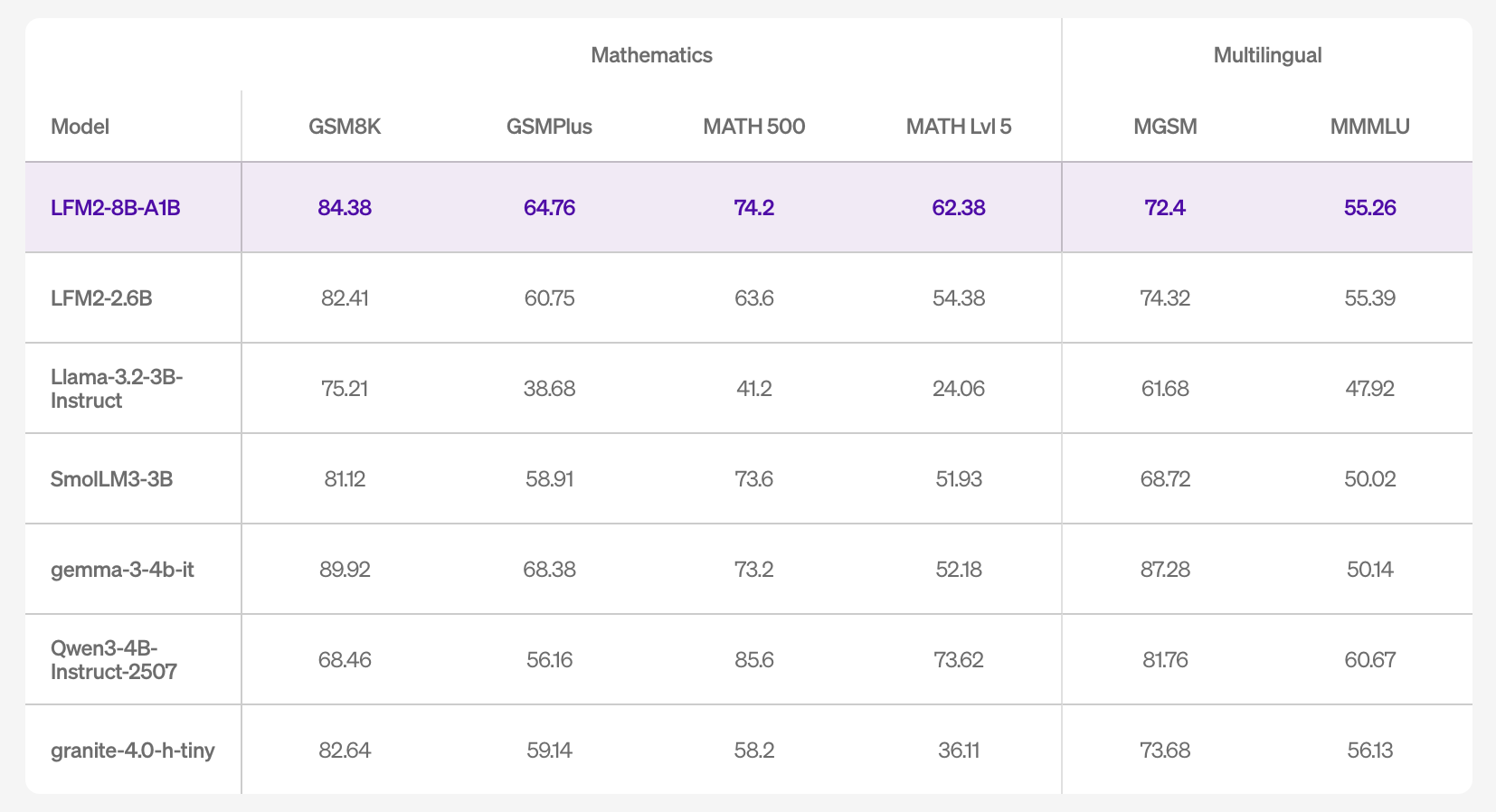
In Bezug auf die Genauigkeit listet die Modellkarte Ergebnisse für 16 Benchmarks auf, darunter MMLU/MMLU-Professional/GPQA (Wissen), IFEval/IFBench/Multi-IF (Anweisungen befolgen), GSM8K/GSMPlus/MATH500/MATH-Lvl-5 (Mathematik) und MGSM/MMMLU (mehrsprachig). Die Zahlen deuten auf eine konkurrenzfähige Unterrichtsbefolgung und Mathematikleistung innerhalb des kleinen Modellbereichs sowie eine verbesserte Wissenskapazität im Vergleich zu LFM2-2.6B hin, was mit dem größeren Gesamtparameterbudget übereinstimmt.

Bereitstellung und Instruments
LFM2-8B-A1B wird mit Transformers/vLLM für GPU-Inferenz und GGUF-Builds für llama.cpp ausgeliefert; Das offizielle GGUF-Repo listet gängige Quants auf Q4_0 ≈4,7 GB bis zu F16 ≈16,7 GB für lokale Läufe, während lama.cpp erfordert einen aktuellen Construct mit lfm2moe Unterstützung (b6709+), um „unbekannte Modellarchitektur“-Fehler zu vermeiden. Die CPU-Validierung von Liquid verwendet Q4_0 mit int8 dynamische Aktivierungen An AMD Ryzen AI 9 HX370 Und Samsung Galaxy S24 Extremelywobei LFM2-8B-A1B einen höheren Dekodierungsdurchsatz aufweist als Qwen3-1.7B bei einer ähnlichen Aktivparameterklasse; ExecuTorch wird für die cell/eingebettete CPU-Bereitstellung referenziert.
Wichtige Erkenntnisse
- Architektur & Routing: LFM2-8B-A1B paart ein schnelles LFM2-Spine (18 Gated-Brief-Conv-Blöcke + 6 GQA-Blöcke) mit Sparse-MoE-FFNs professional Schicht (alle Schichten außer den ersten beiden) unter Verwendung von 32 Experten mit Prime-4-Routing über normalisiertes Sigmoid-Gating und adaptive Bias; 8,3 Milliarden Parameter insgesamt, ~1,5 Milliarden aktiv professional Token.
- Ziel auf dem Gerät: Entwickelt für Telefone, Laptops und eingebettete CPUs/GPUs; Quantisierte Varianten „passen bequem“ auf Excessive-Finish-Shopper-{Hardware} für den privaten Gebrauch mit geringer Latenz.
- Leistungspositionierung. Flüssigkeitsberichte sind LFM2-8B-A1B deutlich schneller als Qwen3-1.7B in CPU-Checks und -Zielen 3–4B-Qualität der dichten Klasse unter Beibehaltung eines aktiven Pfads von ca. 1,5 B.
LFM2-8B-A1B zeigt, dass spärliches MoE unterhalb des Üblichen praktisch sein kann Server-Skalenregime. Das Modell kombiniert ein LFM2-Conv-Consideration-Spine mit Experten-MLPs professional Schicht (mit Ausnahme der ersten beiden Schichten), um die Token-Rechenleistung nahe bei 1,5 B zu halten und gleichzeitig die Qualität in Richtung 3–4 B dichter Klassen zu steigern. Mit Normal- und GGUF-Gewichten, llama.cpp/ExecuTorch/vLLM-Pfaden und einer freizügigen Haltung auf dem Gerät ist LFM2-8B-A1B eine konkrete Possibility für den Aufbau privater Assistenten mit geringer Latenz und in Anwendungen eingebetteter Copiloten auf Verbraucher- und Edge-{Hardware}.
Schauen Sie sich das an Modell auf umarmendem Gesicht Und Technische Particulars. Schauen Sie sich gerne bei uns um GitHub-Seite für Tutorials, Codes und Notebooks. Sie können uns auch gerne weiter folgen Twitter und vergessen Sie nicht, bei uns mitzumachen 100.000+ ML SubReddit und Abonnieren Unser E-newsletter. Warten! Bist du im Telegram? Jetzt können Sie uns auch per Telegram kontaktieren.
Asif Razzaq ist CEO von Marktechpost Media Inc.. Als visionärer Unternehmer und Ingenieur setzt sich Asif dafür ein, das Potenzial der künstlichen Intelligenz für das soziale Wohl zu nutzen. Sein jüngstes Unterfangen ist die Einführung einer Medienplattform für künstliche Intelligenz, Marktechpost, die sich durch eine ausführliche Berichterstattung über maschinelles Lernen und Deep-Studying-Nachrichten auszeichnet, die sowohl technisch fundiert als auch für ein breites Publikum leicht verständlich ist. Die Plattform verfügt über mehr als 2 Millionen monatliche Aufrufe, was ihre Beliebtheit beim Publikum verdeutlicht.