
Wenn man sich nur automatisierte Partituren ansieht, scheinen die meisten LLMs großartig zu sein – bis sie etwas subtil Falsches, Riskantes oder Falsches schreiben. Das ist die Lücke zwischen dem, was statische Benchmarks messen, und dem, was Ihre Benutzer tatsächlich benötigen. In diesem Leitfaden zeigen wir, wie Sie menschliches Urteilsvermögen (HITL) mit Automatisierung kombinieren können LLM-Benchmarking spiegelt Wahrhaftigkeit, Sicherheit und Domänenanpassung wider – nicht nur die Genauigkeit auf Token-Ebene.
Was LLM-Benchmarking wirklich misst
Automatisierte Metriken und Bestenlisten sind schnell und wiederholbar. Genauigkeit bei A number of-Alternative-Aufgaben, BLEU/ROUGE für Textähnlichkeit und Ratlosigkeit bei der Sprachmodellierung geben Richtungssignale. Aber sie vermissen oft Argumentationsketten, sachliche Grundlage und die Einhaltung von Richtlinien – insbesondere in Kontexten, in denen viel auf dem Spiel steht. Deshalb legen moderne Programme Wert auf multimetrische, transparente Berichterstattung und Szenariorealismus.
Automatisierte Metriken und statische Testsätze
Stellen Sie sich klassische Kennzahlen als eine vor Tachometer– ultimate, um Ihnen zu sagen, wie schnell Sie auf einer glatten Autobahn fahren. Sie sagen Ihnen aber nicht, ob die Bremsen bei Regen funktionieren. BLEU/ROUGE/perplexity helfen bei der Vergleichbarkeit, können aber durch Auswendiglernen oder oberflächliche Zuordnung ausgetrickst werden.
Wo sie zu kurz kommen
Echte Benutzer bringen Unklarheiten, Fachjargon, widersprüchliche Ziele und sich ändernde Vorschriften mit sich. Statische Testsätze erfassen dies selten. Daher überschätzen rein automatisierte Benchmarks die Modellbereitschaft für komplexe Unternehmensaufgaben. Gemeinschaftsinitiativen wie HELM/AIR-Bench gehen dieses Downside an, indem sie weitere Dimensionen abdecken (Robustheit, Sicherheit, Offenlegung) und transparente, sich weiterentwickelnde Suiten veröffentlichen.
Das Argument für die menschliche Bewertung in LLM-Benchmarks
Einige Eigenschaften bleiben hartnäckig menschlich: Ton, Hilfsbereitschaft, subtile Korrektheit, kulturelle Angemessenheit und Risikobereitschaft. Menschliche Gutachter – entsprechend ausgebildet und kalibriert – sind hierfür die besten Instrumente, die uns zur Verfügung stehen. Der Trick besteht darin, sie zu nutzen gezielt und systematischSo bleiben die Kosten überschaubar und die Qualität hoch.
Wann man Menschen einbeziehen sollte

- Mehrdeutigkeit: Anweisungen lassen mehrere believable Antworten zu.
- Hohes Risiko: Gesundheitswesen, Finanzen, rechtliche, sicherheitskritische Unterstützung.
- Area-Nuance: Fachjargon, Fachargumentation.
- Uneinigkeitssignale: Automatische Bewertungen stehen im Konflikt oder variieren stark.
Entwerfen von Rubriken und Kalibrierung (einfaches Beispiel)
Beginnen Sie mit einer Skala von 1–5 für Richtigkeit, BodenständigkeitUnd politische Ausrichtung. Geben Sie professional Partitur zwei bis drei kommentierte Beispiele an. Kurz laufen Kalibrierungsrunden: Bewerter bewerten eine gemeinsame Cost und vergleichen dann die Begründungen, um die Konsistenz zu verbessern. Verfolgen Sie die Vereinbarung zwischen den Gutachtern und fordern Sie bei Grenzfällen eine gerichtliche Entscheidung ein.
Methoden: Vom LLM-als-Richter zum echten HITL
LLM-as-a-Decide (Verwendung eines Modells zur Bewertung eines anderen Modells) ist nützlich für Triage: Es ist schnell, günstig und eignet sich intestine für unkomplizierte Kontrollen. Aber es kann dieselben blinden Flecken aufweisen – Halluzinationen, falsche Korrelationen oder „Gradinflation“. Benutze es, um priorisieren Fälle zur menschlichen Überprüfung, nicht um sie zu ersetzen.
Eine praktische Hybridpipeline
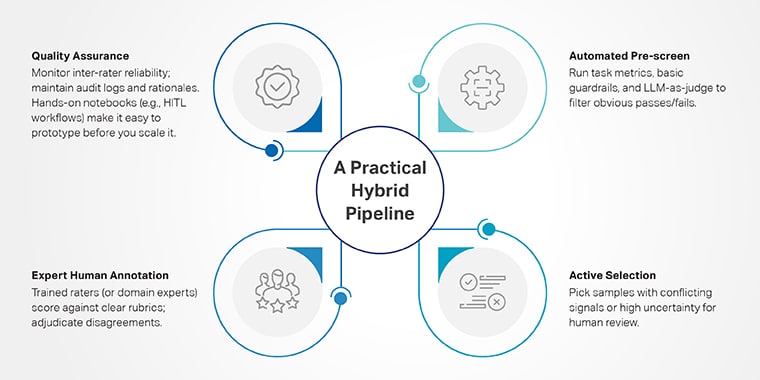
- Automatisierte Vorprüfung: Führen Sie Aufgabenmetriken, grundlegende Leitplanken und LLM als Richter aus, um offensichtliche bestandene/nicht bestandene Aufgaben herauszufiltern.
- Aktive Auswahl: Wählen Sie Proben mit widersprüchlichen Signalen oder hoher Unsicherheit für die menschliche Überprüfung aus.
- Expertenkommentare von Menschen: geschulte Bewerter (oder Fachexperten) bewerten anhand klarer Rubriken; bei Meinungsverschiedenheiten entscheiden.
- Qualitätssicherung: Überwachung der Zuverlässigkeit zwischen Bewertern; Pflegen Sie Prüfprotokolle und Begründungen. Mit praktischen Notebooks (z. B. HITL-Workflows) können Sie ganz einfach Prototypen dieser Schleife erstellen, bevor Sie sie skalieren.
Vergleichstabelle: Automatisiert vs. LLM-as-Decide vs. HITL
Sicherheits- und Risiko-Benchmarks sind unterschiedlich
Regulierungsbehörden und Normungsgremien erwarten Bewertungen, die Risiken dokumentieren und prüfen realistisch Szenarien und demonstrieren die Übersicht. Der NIST AI RMF (GenAI-Profil 2024) stellt ein gemeinsames Vokabular und gemeinsame Praktiken bereit; Die NIST GenAI-Bewertung Das Programm führt domänenspezifische Exams durch. Und HELM/AIR-Financial institution hebt multimetrische, transparente Ergebnisse hervor. Nutzen Sie diese, um Ihr Governance-Narrativ zu verankern.
Was Sie für Sicherheitsaudits sammeln sollten
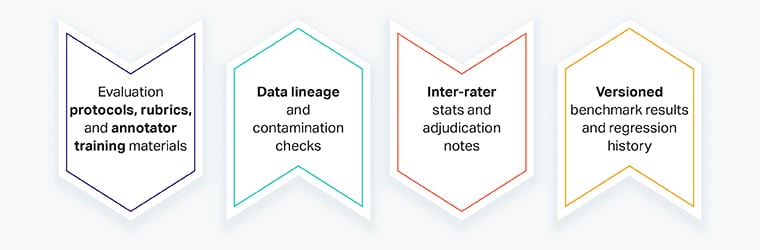
- Auswertung Protokolle, RubrikenUnd Schulung zum Kommentator Materialien
- Datenherkunft und Kontaminationskontrollen
- Inter-Bewerter Statistiken und Entscheidungsnotizen
- Versioniert Benchmark-Ergebnisse und Regressionsverlauf
Mini-Story: Falschmeldungen im KYC-Banking reduzieren
Das KYC-Analystenteam einer Financial institution testete zwei Modelle zur Zusammenfassung von Compliance-Warnungen. Automatisierte Ergebnisse waren identisch. Während eines HITL-Exams haben die Bewerter darauf hingewiesen Modell A häufig fallen gelassen Negativ Qualifikationsmerkmale („keine vorherigen Sanktionen“), Bedeutungen umkehren. Nach dem Urteil entschied sich die Financial institution Modell B und aktualisierte Eingabeaufforderungen. Die Falschmeldungen gingen innerhalb einer Woche um 18 % zurück, sodass die Analysten mehr Zeit für echte Untersuchungen haben. (Die Lektion: Automatisierte Bewertungen haben einen subtilen, schwerwiegenden Fehler übersehen; HITL hat ihn erkannt.)