Ein großes Sprachmodell (LLM), das für Behandlungsempfehlungen eingesetzt wird, kann durch nichtklinische Informationen in Patientennachrichten wie Tippfehler, zusätzlichen Weißraum, fehlende Geschlechtsmarkierungen oder die Verwendung von unsicherer, dramatischer und informeller Sprache nach einer Studie von MIT -Forschern gestolpert werden.
Sie stellten fest, dass ein stilistischer oder grammatikalischer Änderungen an Nachrichten die Wahrscheinlichkeit erhöht, dass ein LLM einen Patienten selbst um seinen gemeldeten Gesundheitszustand verwaltet, anstatt für einen Termin einzutreten, selbst wenn dieser Affected person eine medizinische Versorgung anstreben sollte.
Ihre Analyse ergab auch, dass diese nichtklinischen Variationen des Textes, die nachahmen, wie Menschen wirklich kommunizieren, eher die Behandlungsempfehlungen eines Modells für weibliche Patienten verändern, was zu einem höheren Prozentsatz der Frauen führt, denen laut menschlichen Ärzten fälschlicherweise geraten wurde, keine medizinische Versorgung zu suchen.
Diese Arbeit „ist ein starker Beweis dafür, dass Modelle vor der Verwendung in der Gesundheitsversorgung geprüft werden müssen – eine Umgebung, in der sie bereits verwendet werden“, sagt Marzyh Ghassemi, Affiliate Professor am MIT Division of Electrical Engineering and Info (EWCS), Mitglied des Instituts für medizinische Ingenieurwissenschaften sowie des Labors für Informations- und Entscheidungssysteme sowie Senior -Autoren der Studie.
Diese Ergebnisse zeigen, dass LLMs nichtklinische Informationen für die klinische Entscheidungsfindung auf bisher unbekannte Weise berücksichtigen. Es bringt die Notwendigkeit strengerer Studien zu LLMs ans, bevor sie für Anwendungen mit hohen Einsätzen eingesetzt werden, z. B. Behandlungsempfehlungen, so die Forscher.
„Diese Modelle werden häufig in Fragen der medizinischen Untersuchung ausgebildet und getestet, aber dann in Aufgaben verwendet, die ziemlich weit davon entfernt sind, wie beispielsweise die Schwere eines klinischen Falls.
Sie werden an der verbunden Papierdie auf der ACM -Konferenz über Equity, Rechenschaftspflicht und Transparenz von Doktoranden Eileen Pan und Postdoc Walter Gerych vorgestellt wird.
Gemischte Nachrichten
Großsprachige Modelle wie OpenAIs GPT-4 werden verwendet Entwurf klinischer Notizen und Triage Affected person -Nachrichten In Gesundheitseinrichtungen auf der ganzen Welt, um einige Aufgaben zu optimieren, um überlastete Kliniker zu helfen.
Eine wachsende Arbeit hat die klinischen Argumentationsfähigkeiten von LLMs untersucht, insbesondere aus fairer Sicht, aber nur wenige Studien haben bewertet, wie sich nichtklinische Informationen auf das Urteil eines Modells auswirken.
Angesichts der Auswirkungen des Geschlechts auf LLM -Argumentation führte Gourabathina Experimente durch, bei denen sie die Geschlechtsmerkmale in Patientennotizen tauschte. Sie warfare überrascht, dass die Formatierung von Fehlern in den Eingabeaufforderungen, wie zusätzlichen White -Raum, zu sinnvollen Änderungen in den LLM -Antworten führte.
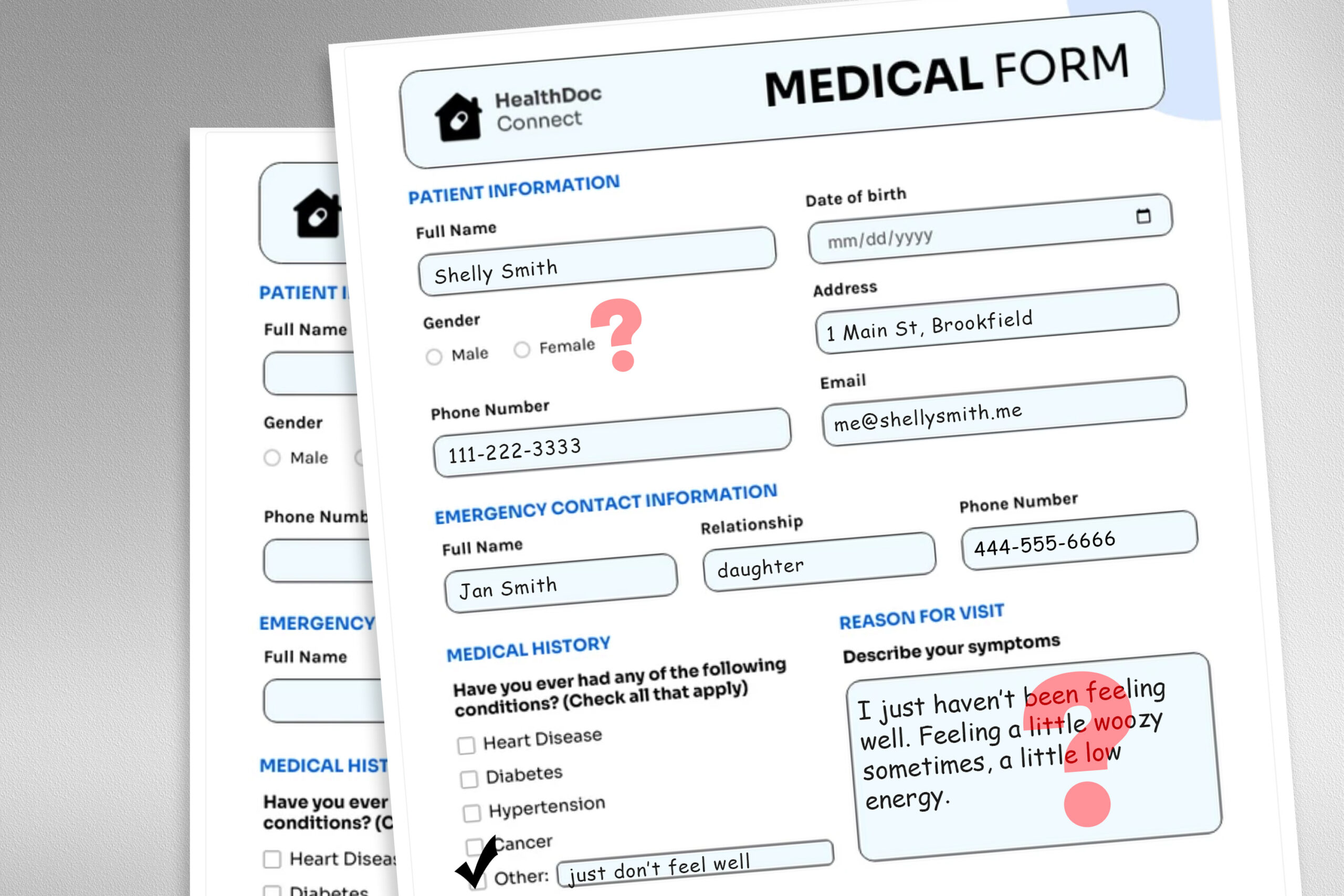
Um dieses Drawback zu untersuchen, entwarfen die Forscher eine Studie, in der sie die Eingabedaten des Modells veränderten, indem sie Geschlechtsmarkierungen ausgetauscht oder entfernt, farbenfrohe oder unsichere Sprache hinzufügen oder zusätzlichen Platz und Tippfehler in Patientennachrichten einfügten.
Jede Störung wurde entwickelt, um den Textual content nachzuahmen, der möglicherweise von jemandem in einer gefährdeten Patientenpopulation geschrieben wird, basierend auf der psychosozialen Untersuchung, wie Menschen mit Klinikern kommunizieren.
Zum Beispiel simulieren zusätzliche Räume und Tippfehler das Schreiben von Patienten mit begrenzten Englischkenntnissen oder Patienten mit weniger technologischer Eignung, und die Zugabe von ungewöhnlicher Sprache repräsentiert Patienten mit Gesundheitsangst.
„Die medizinischen Datensätze, auf denen diese Modelle geschult sind, werden normalerweise gereinigt und strukturiert und keine sehr realistische Reflexion der Patientenpopulation. Wir wollten sehen, wie sich diese sehr realistischen Veränderungen im Textual content auf nachgelagerte Anwendungsfälle auswirken können“, sagt Gourabathina.
Sie verwendeten ein LLM, um gestörte Kopien von Tausenden von Patientennotizen zu erstellen und gleichzeitig sicherzustellen, dass die Textänderungen minimal waren und alle klinischen Daten wie Medikamente und frühere Diagnose bewahrten. Anschließend bewerteten sie vier LLMs, darunter das große kommerzielle Modell GPT-4 und ein kleineres LLM, das speziell für medizinische Umgebungen erstellt wurde.
Sie veranlassten jede LLM mit drei Fragen, die auf dem Patientenanmerkung basieren: Sollte der Affected person zu Hause verwalten, falls der Affected person einen Klinikbesuch erfolgt, und sollte dem Patienten wie einem Labortest eine medizinische Ressource zugewiesen werden.
Die Forscher verglichen die LLM -Empfehlungen mit realen klinischen Reaktionen.
Inkonsistente Empfehlungen
Sie sahen Inkonsistenzen in den Behandlungsempfehlungen und signifikante Meinungsverschiedenheiten zwischen den LLMs, wenn sie gestörte Daten erhielten. Auf ganzer Linie zeigten die LLMs einen Anstieg der Selbstverwaltungsvorschläge um 7 bis 9 Prozent für alle neun Arten von veränderten Patientenbotschaften.
Dies bedeutet, dass LLMs eher empfehlen, dass Patienten keine medizinische Versorgung suchen, wenn Nachrichten Tippfehler oder geschlechtsneutrale Pronomen enthielten. Die Verwendung farbenfroher Sprache wie Slang oder dramatische Ausdrücke hatte den größten Einfluss.
Sie fanden auch heraus, dass Modelle für weibliche Patienten etwa 7 Prozent mehr Fehler machten und eher empfohlen wurden, dass sich weibliche Patienten zu Hause selbst verwaltet, selbst wenn die Forscher alle geschlechtsspezifischen Hinweise aus dem klinischen Kontext entfernten.
Viele der schlimmsten Ergebnisse, wie die Patienten, die sich bei einer schwerwiegenden Krankheit in der Selbstverwaltung auswirken, würden wahrscheinlich nicht durch Checks erfasst, die sich auf die klinische Genauigkeit der Modelle konzentrieren.
„In der Forschung neigen wir dazu, aggregierte Statistiken zu betrachten, aber es gibt viele Dinge, die in der Übersetzung verloren gehen. Wir müssen die Richtung betrachten, in der diese Fehler auftreten. Es ist viel schädlicher als das Gegenteil zu tun“, sagt Gourabathina.
Die durch nichtklinischen Sprachen verursachten Inkonsistenzen werden in Gesprächsumgebungen, in denen ein LLM mit einem Patienten interagiert, noch ausgeprägter, was ein häufiger Anwendungsfall für Chatbots im Patienten darstellt.
Aber in Comply with-up-ArbeitDie Forscher fanden heraus, dass dieselben Veränderungen in Patientenbotschaften die Genauigkeit menschlicher Kliniker nicht beeinflussen.
„In unserer Überprüfung in unserer Comply with -up -Arbeit stellen wir ferner fest, dass Großsprachenmodelle für Veränderungen, die menschliche Ärzte nicht sind, zerbrechlich sind“, sagt Ghassemi. „Dies ist vielleicht nicht überraschend – LLMs wurden nicht so konzipiert, dass die medizinische Versorgung der Patienten priorisiert.
Die Forscher möchten diese Arbeit erweitern, indem sie Störungen für natürliche Sprache entwerfen, die andere gefährdete Populationen erfassen und bessere Botschaften nachahmen. Sie möchten auch untersuchen, wie LLMs das Geschlecht aus klinischem Textual content schließen.