Verbesserung produktübergreifender Erkenntnisse innerhalb von DBT-Workflows
Für Unternehmen mit mehreren Produkten ist häufig die sogenannte „produktübergreifende Akzeptanz“ eine entscheidende Kennzahl. (d. h. verstehen, wie Benutzer mit mehreren Angeboten in einem bestimmten Produktportfolio interagieren)
Eine vorgeschlagene Maßnahme zur Berechnung der produkt- oder funktionsübergreifenden Nutzung im beliebten Buch Wachstum hacken (1) ist die Jaccard-Index. Der Jaccard-Index wird traditionell zur Messung der Ähnlichkeit zwischen zwei Mengen verwendet und kann auch als leistungsstarkes Instrument zur Bewertung von Produktakzeptanzmustern dienen. Dies geschieht durch die Quantifizierung der Überschneidungen bei den Benutzern zwischen den Produkten, anhand derer sich produktübergreifende Synergien und Wachstumschancen ermitteln lassen.
Das dbt-Paket dbt_set_similarity soll die Berechnung festgelegter Ähnlichkeitsmetriken direkt innerhalb eines Analyse-Workflows vereinfachen. Dieses Paket bietet eine Methode zur Berechnung der Jaccard-Indizes innerhalb von SQL-Transformationsschichten.
Um dieses Paket in Ihr dbt-Projekt zu importieren, fügen Sie Folgendes hinzu packages.yml Datei. Für die Zwecke dieses Artikelbeispiels benötigen wir auch dbt_utils. Führen Sie a aus dbt deps Befehl in Ihrem Projekt, um das Paket zu installieren.
packages:
- bundle: Matts52/dbt_set_similarity
model: 0.1.1
- bundle: dbt-labs/dbt_utils
model: 1.3.0
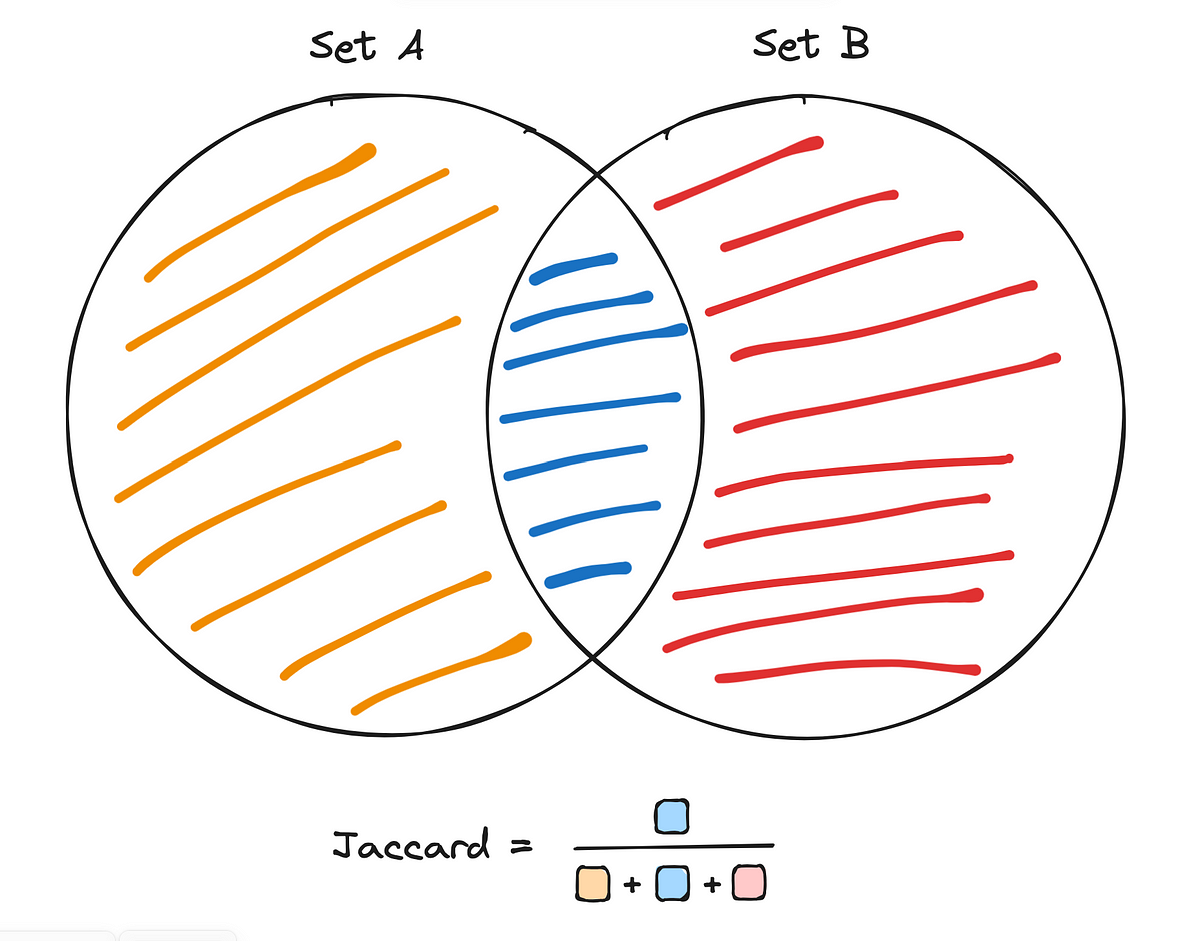
Der Jaccard-Index, auch bekannt als Jaccard-Ähnlichkeitskoeffizient, ist eine Metrik zur Messung der Ähnlichkeit zwischen zwei Mengen. Sie ist definiert als die Größe der Schnittmenge der Mengen dividiert durch die Größe ihrer Vereinigung.
Mathematisch kann es ausgedrückt werden als:

Wo:
- A Und B sind zwei Gruppen (z. B. Benutzer von Produkt A und Produkt B)
- Der Zähler repräsentiert die Anzahl der Elemente in beiden Mengen
- Der Nenner stellt die Gesamtzahl der unterschiedlichen Elemente in beiden Mengen dar

Der Jaccard-Index ist besonders nützlich im Zusammenhang mit der produktübergreifenden Einführung, weil:
- Es konzentriert sich auf die Überlappung zwischen zwei Gruppen und ist daher supreme für das Verständnis gemeinsamer Benutzerbasen
- Es berücksichtigt Unterschiede in der Gesamtgröße der Sätze und stellt sicher, dass die Ergebnisse proportional sind und nicht durch Ausreißer verzerrt werden
Zum Beispiel:
- Wenn 100 Benutzer Produkt A und 50 Produkt B übernehmen und 25 Benutzer beide verwenden, beträgt der Jaccard-Index 25 / (100 + 50 – 25) = 0,2, was auf eine 20-prozentige Überlappung zwischen den beiden Benutzerbasen durch den Jaccard-Index hinweist.
Der Beispieldatensatz, den wir verwenden werden, ist ein fiktives SaaS-Unternehmen, das Speicherplatz als Produkt für Verbraucher anbietet. Dieses Unternehmen bietet zwei unterschiedliche Speicherprodukte an: Dokumentenspeicher (doc_storage) und Fotospeicher (photo_storage). Diese sind entweder wahr, was bedeutet, dass das Produkt übernommen wurde, oder falsch, was bedeutet, dass das Produkt nicht übernommen wurde.
Darüber hinaus sind die demografischen Daten (Benutzerkategorie), die dieses Unternehmen bedient, sind entweder Technikbegeisterte oder Hausbesitzer.
Für dieses Beispiel lesen wir diese CSV-Datei als „Seed“-Modell mit dem Namen ein seed_example innerhalb des dbt-Projekts.
Nehmen wir nun an, wir möchten den Jaccard-Index (Kreuzadoption) zwischen unseren Dokumentenspeicher- und Fotospeicherprodukten berechnen. Zuerst müssen wir ein Array (Liste) der Benutzer erstellen, die über das Dokumentspeicherprodukt verfügen, sowie ein Array der Benutzer, die über das Fotospeicherprodukt verfügen. Im zweiten cte wenden wir das an jaccard_coef Funktion aus dem dbt_set_similarity Paket, das uns hilft, den Jaccard-Koeffizienten zwischen den beiden Arrays von Benutzer-IDs einfach zu berechnen.
with product_users as (
choose
array_agg(user_id) filter (the place doc_storage = true)
as doc_storage_users,
array_agg(user_id) filter (the place photo_storage = true)
as photo_storage_users
from {{ ref('seed_example') }}
)choose
doc_storage_users,
photo_storage_users,
{{
dbt_set_similarity.jaccard_coef(
'doc_storage_users',
'photo_storage_users'
)
}} as cross_product_jaccard_coef
from product_users

Wie wir interpretieren können, Es scheint, dass etwas mehr als die Hälfte (60 %) der Benutzer, die eines der Produkte angenommen haben, auch beide angenommen haben. Wir können unser Ergebnis grafisch überprüfen, indem wir die Benutzer-ID-Sätze in ein Venn-Diagramm einfügen. Dort sehen wir, dass drei Benutzer von insgesamt fünf Benutzern beide Produkte übernommen haben: 3/5 = 0,6.

Mit der dbt_set_similarity Paket sollte die Erstellung segmentierter Jaccard-Indizes für unsere verschiedenen Benutzerkategorien ziemlich natürlich sein. Wir folgen dem gleichen Muster wie zuvor, gruppieren unsere Aggregationen jedoch einfach nach der Benutzerkategorie, zu der ein Benutzer gehört.
with product_users as (
choose
user_category,
array_agg(user_id) filter (the place doc_storage = true)
as doc_storage_users,
array_agg(user_id) filter (the place photo_storage = true)
as photo_storage_users
from {{ ref('seed_example') }}
group by user_category
)choose
user_category,
doc_storage_users,
photo_storage_users,
{{
dbt_set_similarity.jaccard_coef(
'doc_storage_users',
'photo_storage_users'
)
}} as cross_product_jaccard_coef
from product_users

Aus den Daten können wir ersehen, dass bei Eigenheimbesitzern die produktübergreifende Akzeptanz höher ist, wenn man Jaccard-Indizes berücksichtigt. Wie aus der Ausgabe hervorgeht, haben alle Hausbesitzer, die eines der Produkte übernommen haben, auch beide übernommen. Mittlerweile hat nur ein Drittel der Technikbegeisterten, die ein Produkt übernommen haben, beide Produkte übernommen. Daher ist in unserem sehr kleinen Datensatz die produktübergreifende Akzeptanz bei Hausbesitzern höher als bei Technikbegeisterten.
Wir können die Ausgabe grafisch überprüfen, indem wir erneut ein Venn-Diagramm erstellen:

dbt_set_similarity bietet eine einfache und effiziente Möglichkeit, produktübergreifende Akzeptanzmetriken wie den Jaccard-Index direkt in einem DBT-Workflow zu berechnen. Durch die Anwendung dieser Methode Multiproduktunternehmen können wertvolle Einblicke in das Benutzerverhalten und die Akzeptanzmuster in ihrem gesamten Produktportfolio gewinnen. In unserem Beispiel haben wir die Berechnung der gesamten produktübergreifenden Akzeptanz sowie der segmentierten Akzeptanz für verschiedene Benutzerkategorien demonstriert.
Die Verwendung des Pakets für die produktübergreifende Einführung ist einfach eine unkomplizierte Anwendung. Tatsächlich gibt es unzählige weitere potenzielle Anwendungen dieser Technik, einige Bereiche sind beispielsweise:
- Analyse der Funktionsnutzung
- Wirkungsanalyse von Marketingkampagnen
- Assist-Analyse
Zusätzlich, Diese Artwork der Analyse ist sicherlich nicht nur auf SaaS beschränktkann aber auf praktisch jede Branche angewendet werden. Viel Spaß beim Jackardieren!
Referenzen
(1) Sean Ellis und Morgan Brown, Wachstum hacken (2017)