
Wie halten Sie synthetische Daten für moderne KI-Modelle aktuell und vielfältig, ohne dass eine einzige Orchestrierungspipeline zum Engpass wird? Meta-KI-Forscher stellen vor Matrixein dezentrales Framework, in dem sowohl Kontrolle als auch Datenfluss in Nachrichten serialisiert werden, die sich durch verteilte Warteschlangen bewegen. Da das LLM-Coaching zunehmend auf synthetischen Gesprächen, Instrument-Traces und Argumentationsketten basiert, sind die meisten bestehenden Systeme immer noch auf einen zentralen Controller oder domänenspezifische Setups angewiesen, was GPU-Kapazität verschwendet, den Koordinationsaufwand erhöht und die Datenvielfalt einschränkt. Matrix nutzt stattdessen Peer-to-Peer-Agentenplanung auf einem Ray-Cluster und liefert einen 2- bis 15-mal höheren Token-Durchsatz bei realen Arbeitslasten bei gleichbleibender Qualität.
Von zentralisierten Controllern bis hin zu Peer-to-Peer-Agenten
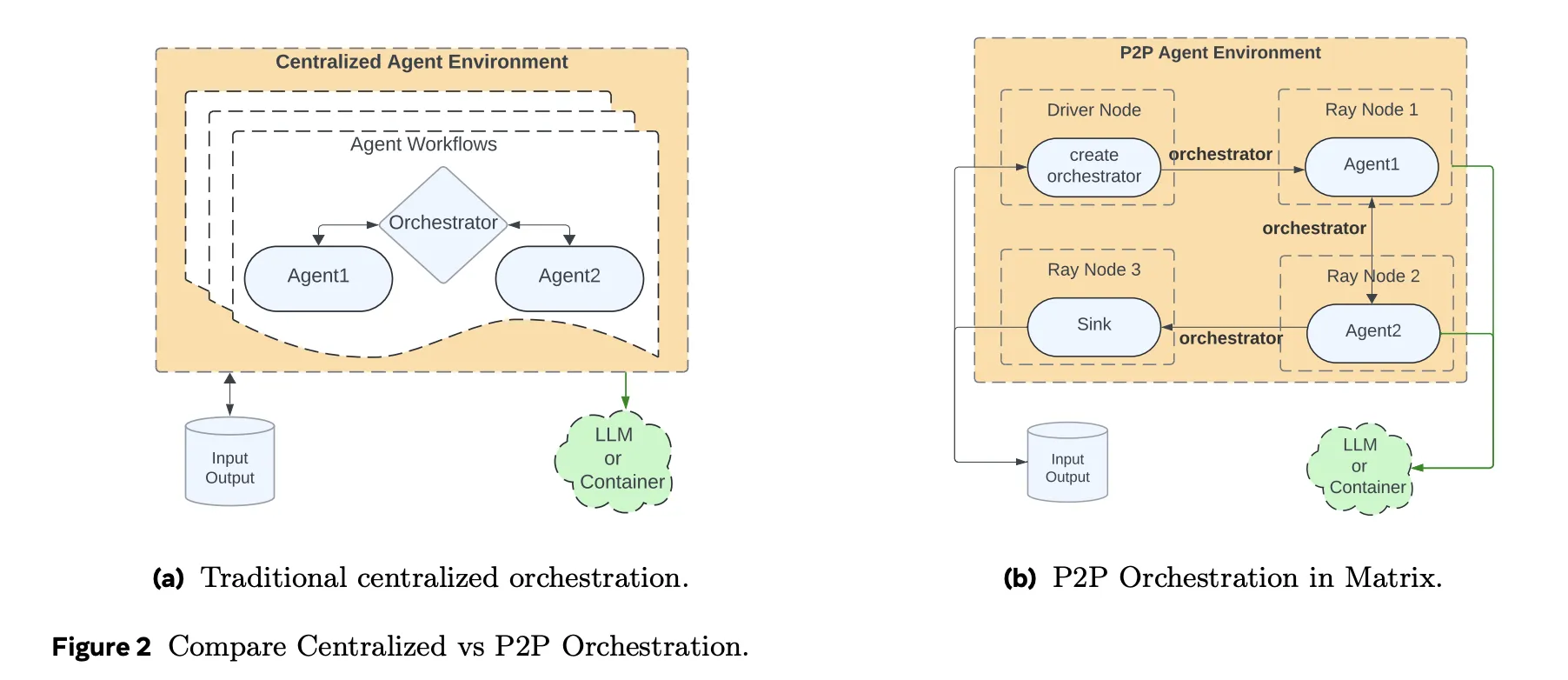
Herkömmliche Agenten-Frameworks behalten den Workflow-Standing und die Kontrolllogik in einem zentralen Orchestrator. Jeder Agentenaufruf, Toolaufruf und jeder Wiederholungsversuch läuft über diesen Controller. Über dieses Modell lässt sich leicht nachdenken, es lässt sich jedoch nicht intestine skalieren, wenn Sie Zehntausende gleichzeitiger synthetischer Dialoge oder Werkzeugtrajektorien benötigen.
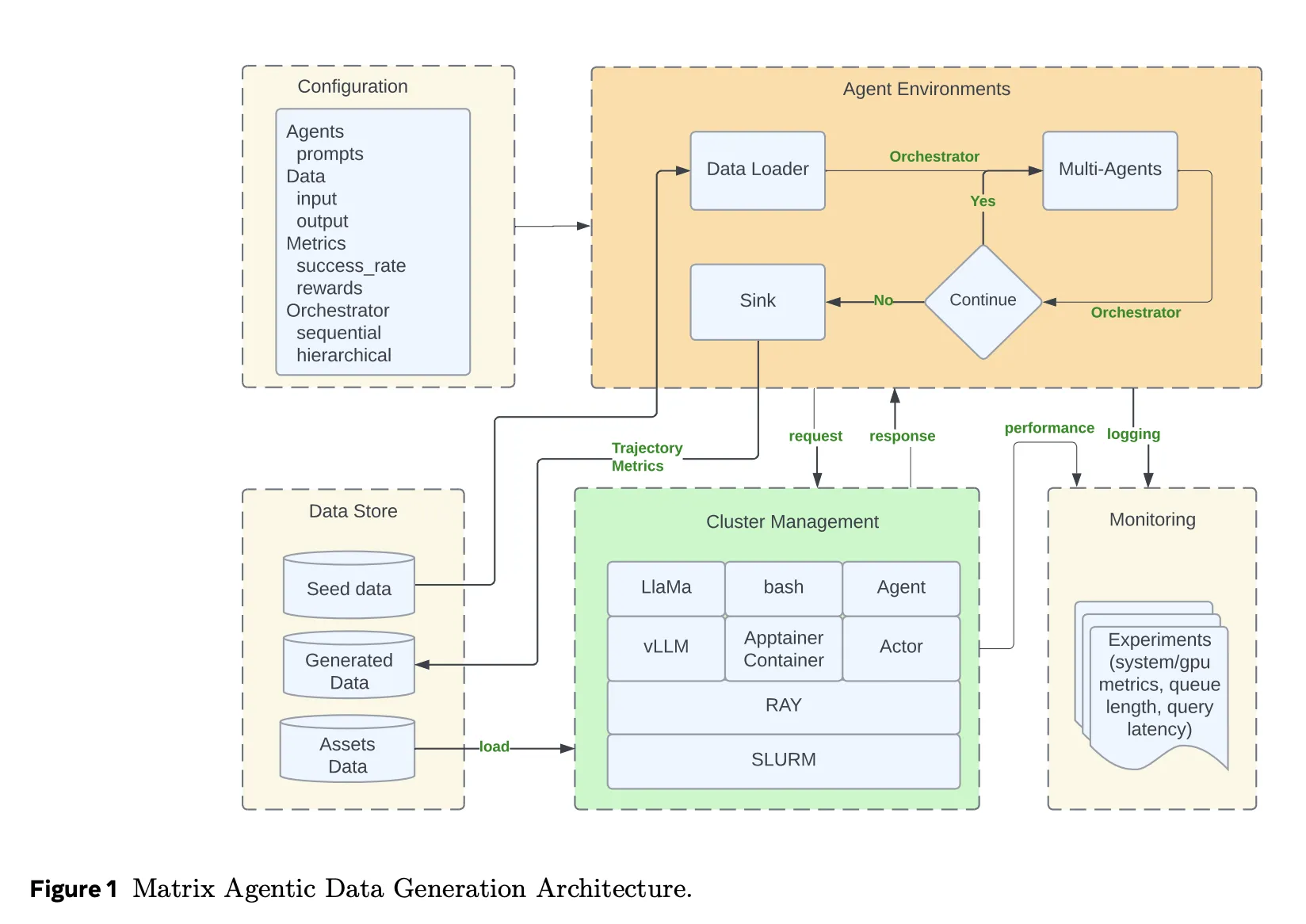
Matrix verfolgt einen anderen Ansatz. Es serialisiert sowohl den Kontrollfluss als auch den Datenfluss in ein Nachrichtenobjekt, das als Orchestrator bezeichnet wird. Der Orchestrator speichert den Aufgabenstatus, einschließlich Konversationsverlauf, Zwischenergebnisse und Routing-Logik. Zustandslose Agenten, die als Ray-Akteure implementiert sind, ziehen einen Orchestrator aus einer verteilten Warteschlange, wenden ihre rollenspezifische Logik an, aktualisieren den Standing und senden ihn dann direkt an den nächsten vom Orchestrator ausgewählten Agenten. Es gibt keinen zentralen Scheduler in der inneren Schleife. Jede Aufgabe schreitet unabhängig auf Zeilenebene voran, anstatt wie in Spark oder Ray Knowledge auf Barrieren auf Batch-Ebene zu warten.
Dieses Design reduziert die Leerlaufzeit, wenn verschiedene Flugbahnen sehr unterschiedliche Längen haben. Dadurch wird die Fehlerbehandlung auch lokal für eine Aufgabe ermöglicht. Wenn ein Orchestrator ausfällt, wird ein Batch nicht angehalten.
Systemstapel und Dienste
Matrix läuft auf einem Ray-Cluster, der normalerweise auf SLURM gestartet wird. Ray stellt verteilte Akteure und Warteschlangen bereit. Ray Serve stellt LLM-Endpunkte hinter vLLM und SGLang bereit und kann auch über Proxyserver an externe APIs wie Azure OpenAI oder Gemini weiterleiten.
Toolaufrufe und andere komplexe Dienste werden in Apptainer-Containern ausgeführt. Dadurch wird die Agentenlaufzeit von Sandboxes zur Codeausführung, HTTP-Instruments oder benutzerdefinierten Evaluatoren isoliert. Hydra verwaltet die Konfiguration für Agentenrollen, Orchestratortypen, Ressourcenzuweisungen und I- oder O-Schemata. Grafana lässt sich in Ray-Metriken integrieren, um die Warteschlangenlänge, ausstehende Aufgaben, den Token-Durchsatz und die GPU-Auslastung in Echtzeit zu verfolgen.
Matrix führt auch das Offloading von Nachrichten ein. Wenn der Konversationsverlauf einen Größenschwellenwert überschreitet, werden große Nutzlasten im Objektspeicher von Ray gespeichert und im Orchestrator werden nur Objektkennungen gespeichert. Dadurch wird die Clusterbandbreite reduziert, während die Agenten dennoch bei Bedarf Eingabeaufforderungen rekonstruieren können.
Fallstudie 1: Kollaborativer Denker
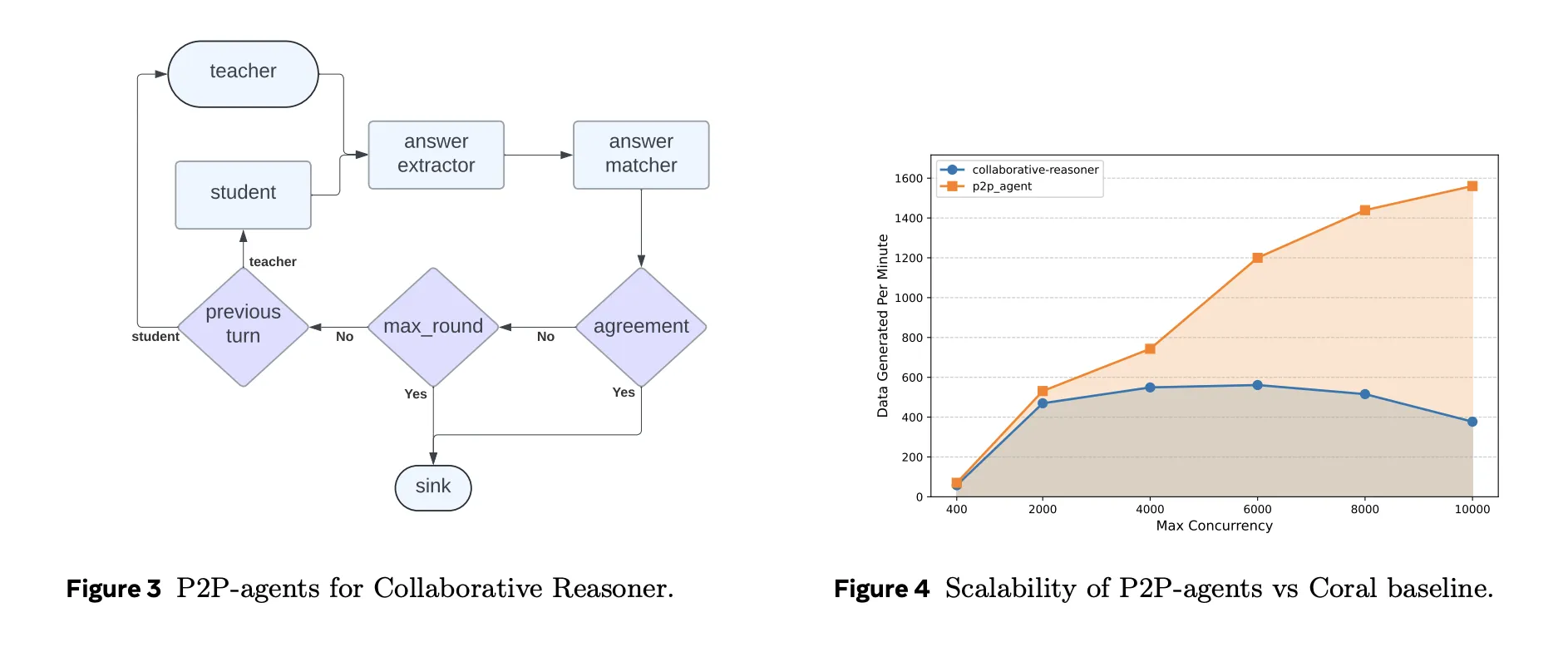
Collaborative Reasoner, auch bekannt als Coral, wertet den Multi-Agenten-Dialog aus, bei dem zwei LLM-Agenten eine Frage diskutieren, bei Bedarf anderer Meinung sind und eine endgültige Antwort finden. In der ursprünglichen Implementierung verwaltet ein zentraler Controller Tausende von Trajektorien für die Selbstkollaboration. Matrix implementiert dasselbe Protokoll mithilfe von Peer-to-Peer-Orchestratoren und zustandslosen Agenten erneut.
Auf 31 A100-Knoten konfiguriert Matrix mit LLaMA 3.1 8B Instruct die Parallelität als 248 GPUs mit 50 Abfragen professional GPU, additionally 12.400 gleichzeitige Gespräche. Die Coral-Basislinie wird mit der optimalen Parallelität von 5.000 ausgeführt. Unter identischer {Hardware} generiert Matrix etwa 2 Milliarden Token in etwa 4 Stunden, während Coral etwa 0,62 Milliarden Token in etwa 9 Stunden produziert. Das ist eine 6,8-fache Steigerung des Token-Durchsatzes bei nahezu identischer Übereinstimmungskorrektheit um 0,47.
Fallstudie 2: NaturalReasoning Internet-Datenkuration
NaturalReasoning erstellt einen Argumentationsdatensatz aus großen Webkorpora. Matrix modelliert die Pipeline mit drei Agenten. Ein Filteragent verwendet ein kleineres Klassifikationsmodell, um englische Passagen auszuwählen, die wahrscheinlich Begründungen enthalten. Ein Rating-Agent verwendet ein größeres, auf Anweisungen abgestimmtes Modell, um Qualitätsbewertungen zuzuweisen. Ein Frageagent extrahiert Fragen, Antworten und Argumentationsketten.
Von 25 Millionen DCLM-Webdokumenten überleben nur etwa 5,45 Prozent alle Filter, was etwa 1,19 Millionen Frage-Antwort-Paare mit zugehörigen Argumentationsschritten ergibt. Matrix vergleicht dann verschiedene Parallelitätsstrategien für eine Teilmenge von 500.000 Dokumenten. Die beste Konfiguration kombiniert Datenparallelität und Aufgabenparallelität mit 20 Datenpartitionen und 700 gleichzeitigen Aufgaben professional Partition. Dadurch wird ein etwa 1,61-mal höherer Durchsatz erreicht als mit einer Einstellung, die nur die Aufgabengleichzeitigkeit skaliert.
Über den gesamten Lauf von 25 Millionen Dokumenten erreicht Matrix 5.853 Token professional Sekunde, verglichen mit 2.778 Token professional Sekunde bei einer Ray Knowledge-Batch-Basislinie mit 14.000 gleichzeitigen Aufgaben. Das entspricht einem 2,1-fachen Durchsatzgewinn, der ausschließlich auf der Peer-to-Peer-Zeilenebenenplanung und nicht auf verschiedenen Modellen beruht.

Fallstudie 3, Verwendungsverläufe des Tau2-Bench-Werkzeugs
Tau2-Bench bewertet Konversationsagenten, die in einer Kundensupportumgebung Instruments und eine Datenbank verwenden müssen. Matrix repräsentiert diese Umgebung mit vier Agenten, einem Benutzersimulator, einem Assistenten, einem Instrument-Executor und einem Belohnungsrechner sowie einer Senke, die Metriken sammelt. Instrument-APIs und Belohnungslogik werden aus der Tau2-Referenzimplementierung wiederverwendet und in Container verpackt.
Auf einem Cluster mit 13 H100-Knoten und Dutzenden LLM-Replikaten generiert Matrix 22.800 Trajektorien in etwa 1,25 Stunden. Das entspricht etwa 41.000 Token professional Sekunde. Die grundlegende Tau2-Agent-Implementierung auf einem einzelnen Knoten, konfiguriert mit 500 gleichzeitigen Threads, erreicht etwa 2.654 Token professional Sekunde und 1.519 Trajektorien. Die durchschnittliche Belohnung bleibt in beiden Systemen nahezu unverändert, was bestätigt, dass die Beschleunigung nicht auf Abstriche in der Umgebung zurückzuführen ist. Insgesamt liefert Matrix bei diesem Benchmark einen etwa 15,4-mal höheren Token-Durchsatz.

Wichtige Erkenntnisse
- Matrix ersetzt zentralisierte Orchestratoren durch eine nachrichtengesteuerte Peer-to-Peer-Agentenarchitektur, die jede Aufgabe als unabhängige Zustandsmaschine behandelt, die sich über zustandslose Agenten bewegt.
- Das Framework basiert vollständig auf einem Open-Supply-Stack, SLURM, Ray, vLLM, SGLang und Apptainer, und lässt sich auf Zehntausende gleichzeitiger Multi-Agent-Workflows für die Generierung synthetischer Daten, Benchmarking und Datenverarbeitung skalieren.
- In drei Fallstudien, Collaborative Reasoner, NaturalReasoning und Tau2-Bench, liefert Matrix einen etwa 2- bis 15,4-mal höheren Token-Durchsatz als spezialisierte Baselines unter identischer {Hardware} und behält dabei vergleichbare Ausgabequalität und Belohnungen bei.
- Matrix verlagert große Konversationsverläufe in den Objektspeicher von Ray und speichert nur leichte Referenzen in Nachrichten, was die Spitzennetzwerkbandbreite reduziert und die LLM-Bereitstellung mit hohem Durchsatz mit gRPC-basierten Modell-Backends unterstützt.

Redaktionelle Anmerkungen
Matrix ist ein pragmatischer Systembeitrag, der die Generierung synthetischer Daten mit mehreren Agenten von maßgeschneiderten Skripten zu einer betriebsbereiten Laufzeit führt. Durch die Codierung des Kontrollflusses und des Datenflusses in Orchestratoren und die anschließende Übertragung der Ausführung an zustandslose P2P-Agenten auf Ray werden Planung, LLM-Inferenz und Instruments sauber getrennt. Die Fallstudien zu Collaborative Reasoner, NaturalReasoning und Tau2-Bench zeigen, dass sorgfältiges Systemdesign und nicht neue Modellarchitekturen heute der Haupthebel für die Skalierung synthetischer Datenpipelines sind.
Schauen Sie sich das an Papier Und Repo. Schauen Sie sich gerne bei uns um GitHub-Seite für Tutorials, Codes und Notebooks. Sie können uns auch gerne weiter folgen Twitter und vergessen Sie nicht, bei uns mitzumachen 100.000+ ML SubReddit und Abonnieren Unser E-newsletter. Warten! Bist du im Telegram? Jetzt können Sie uns auch per Telegram kontaktieren.

Michal Sutter ist ein Knowledge-Science-Experte mit einem Grasp of Science in Knowledge Science von der Universität Padua. Mit einer soliden Grundlage in statistischer Analyse, maschinellem Lernen und Datentechnik ist Michal hervorragend darin, komplexe Datensätze in umsetzbare Erkenntnisse umzuwandeln.