
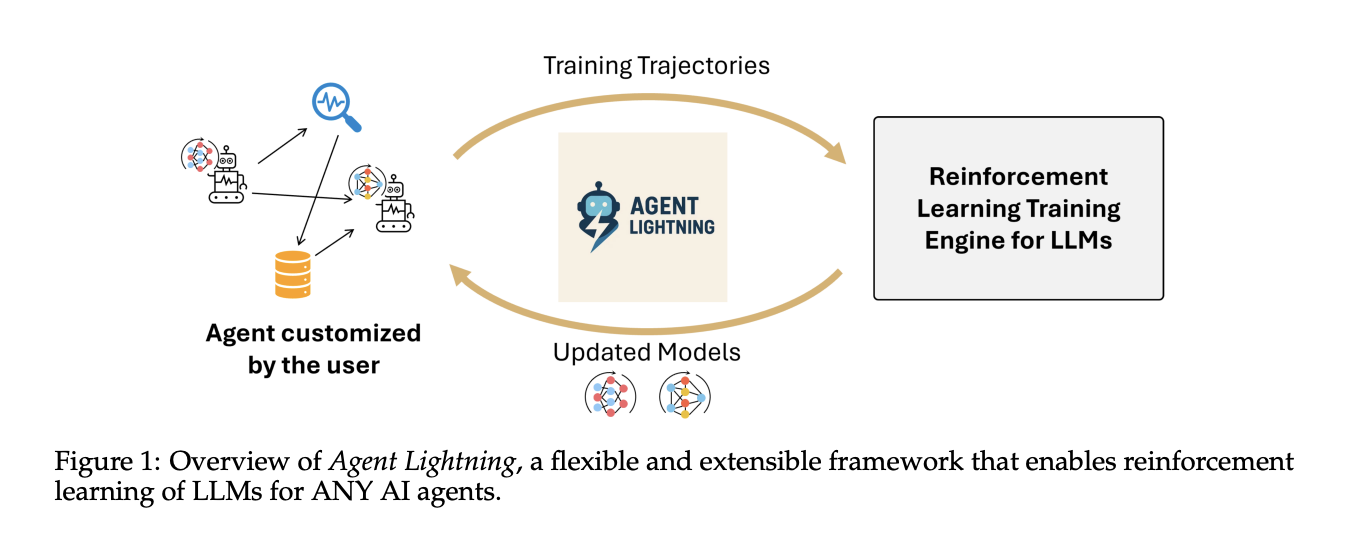
Wie wandeln Sie echte Agentenverfolgungen in Reinforcement Studying RL-Übergänge um, um Richtlinien-LLMs zu verbessern, ohne Ihren bestehenden Agentenstapel zu ändern? Veröffentlichungen des Microsoft AI-Groups Agent Lightning zur Optimierung von Multiagentensystemen. Agent Lightning ist ein Open-Supply-Framework, das Reinforcement Studying für jeden KI-Agenten ohne Umschreibungen ermöglicht. Es trennt Coaching und Ausführung, definiert ein einheitliches Hint-Format und führt LightningRL ein, eine hierarchische Methode, die komplexe Agentenläufe in Übergänge umwandelt, die standardmäßige Single-Flip-RL-Coach optimieren können.
Was Agent Lightning macht?
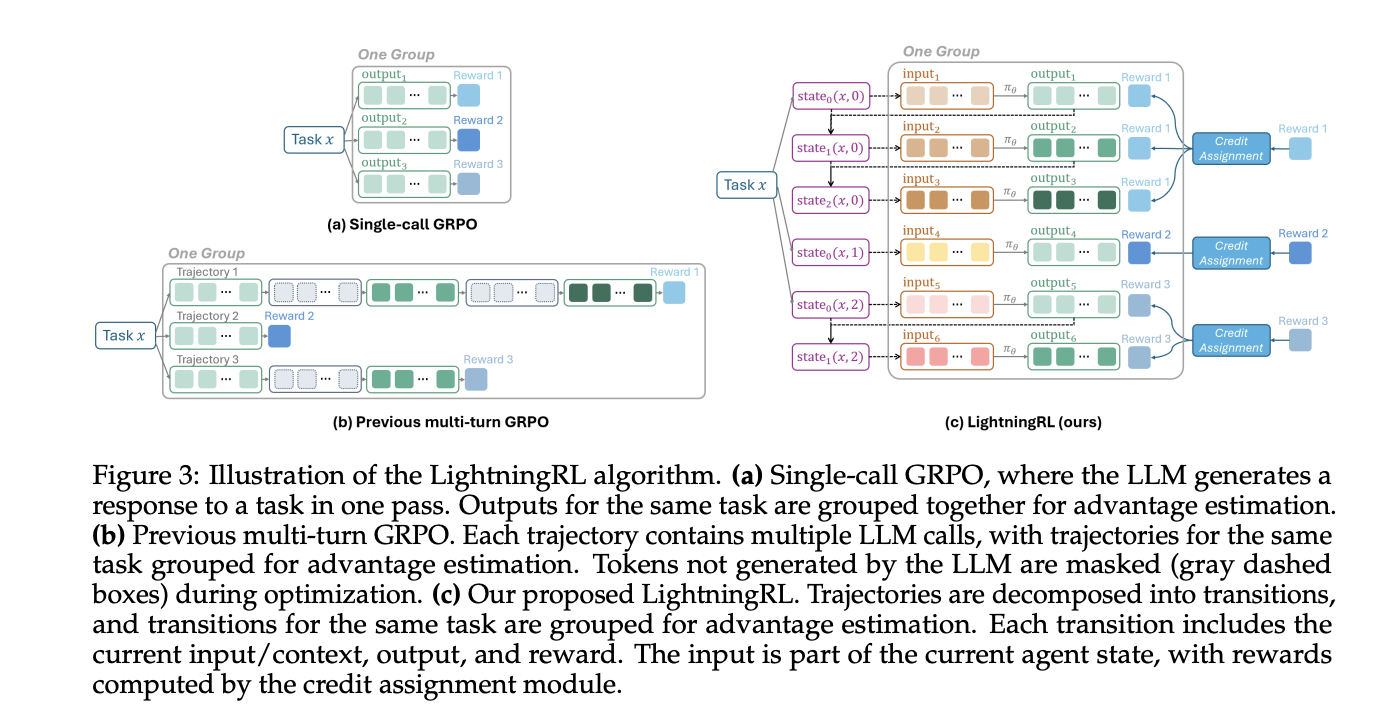
Das Framework modelliert einen Agenten als Entscheidungsprozess. Es formalisiert den Agenten als einen teilweise beobachtbaren Markov-Entscheidungsprozess, bei dem die Beobachtung die aktuelle Eingabe in das Richtlinien-LLM ist, die Aktion der Modellaufruf ist und die Belohnung terminaler oder intermediärer Natur sein kann. Aus jedem Lauf werden nur die vom Richtlinienmodell getätigten Aufrufe sowie Eingaben, Ausgaben und Belohnungen extrahiert. Dadurch werden andere Rahmengeräusche entfernt und saubere Übergänge für das Coaching erzielt.
LightningRL führt die Kreditzuweisung über mehrstufige Episoden hinweg durch und optimiert dann die Richtlinie mit einem einzigen RL-Ziel. Das Forschungsteam beschreibt die Kompatibilität mit Single-Flip-RL-Methoden. In der Praxis nutzen Groups häufig Coach, die PPO oder GRPO implementieren, wie z. B. VeRL, das zu dieser Schnittstelle passt.
Systemarchitektur
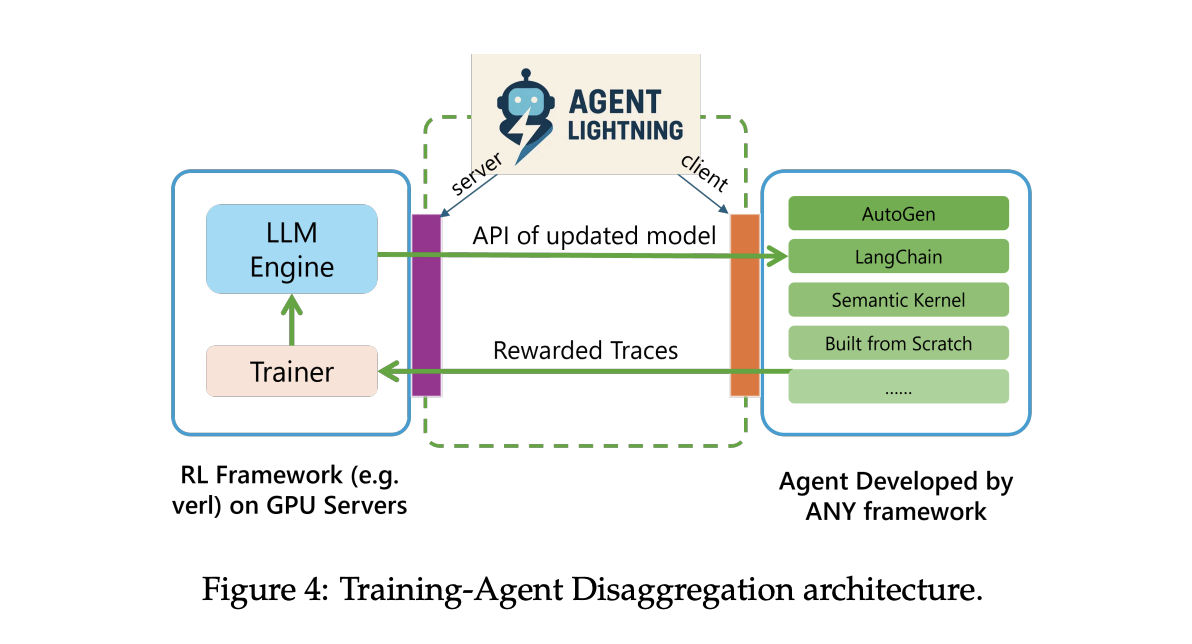
Agent Lightning verwendet Coaching Agent Disaggregation. Ein Blitz Server führt Coaching und Bereitstellung durch und stellt eine OpenAI-ähnliche API für das aktualisierte Modell bereit. Ein Lightning-Consumer führt die Agentenlaufzeit dort aus, wo sie sich bereits befindet, erfasst Spuren von Eingabeaufforderungen, Toolaufrufen und Belohnungen und streamt sie zurück an den Server. Dadurch bleiben Instruments, Browser, Shells und andere Abhängigkeiten nah an der Produktion, während das GPU-Coaching auf der Serverebene verbleibt.
Die Laufzeit unterstützt zwei Ablaufverfolgungspfade. Ein Standardpfad verwendet OpenTelemetry-Spans, sodass Sie Agententelemetrie über Standardkollektoren weiterleiten können. Es gibt auch einen leichtgewichtigen eingebetteten Tracer für Groups, die OpenTelemetry nicht einsetzen möchten. Beide Wege enden zum Coaching im selben Laden.
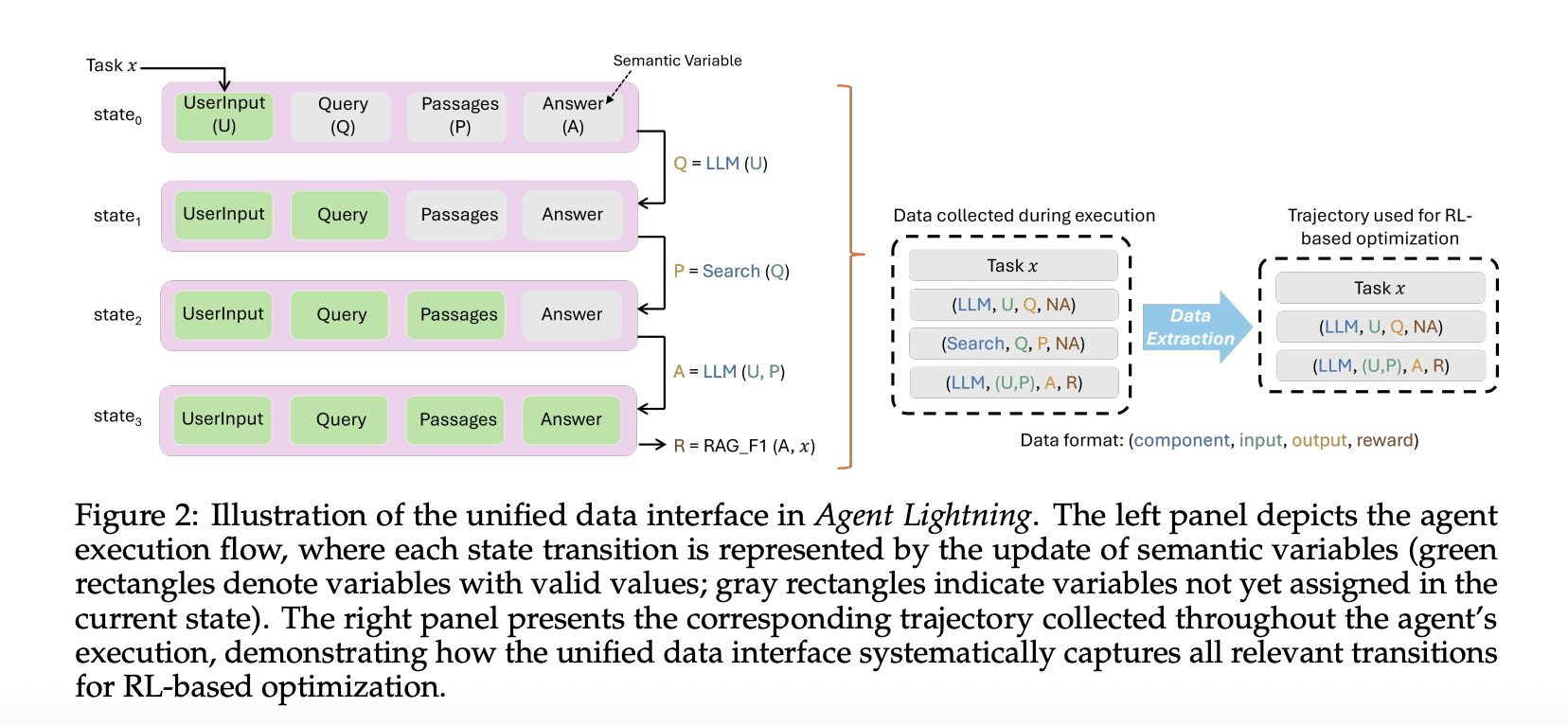
Einheitliche Datenschnittstelle
Agent Lightning zeichnet jeden Modellaufruf und jeden Toolaufruf als Spanne mit Eingaben, Ausgaben und Metadaten auf. Die Algorithmusschicht passt Spannen in geordnete Tripletts aus Aufforderung, Antwort und Belohnung an. Durch diese selektive Extraktion können Sie einen Agenten in einem Multi-Agenten-Workflow oder mehrere Agenten gleichzeitig optimieren, ohne den Orchestrierungscode zu berühren. Dieselben Spuren können auch eine automatische Immediate-Optimierung oder eine überwachte Feinabstimmung vorantreiben.
Experimente und Datensätze
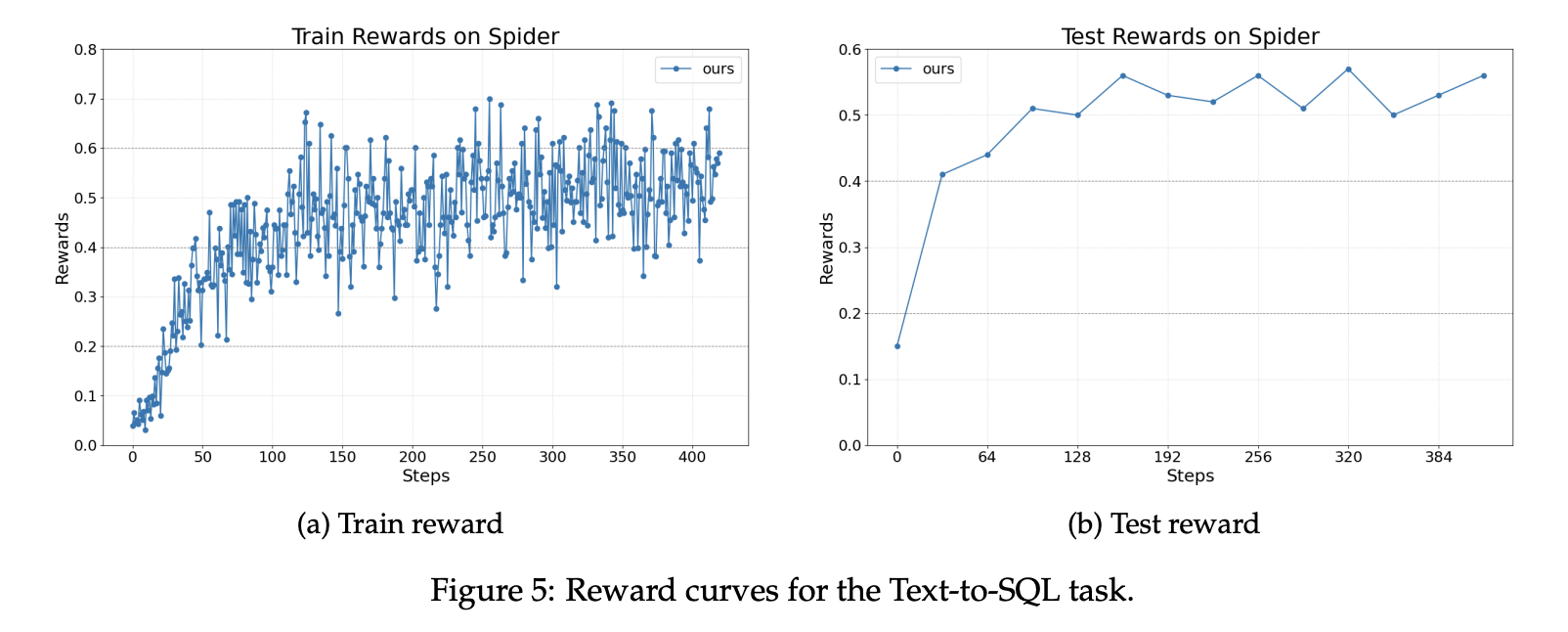
Das Forschungsteam meldet drei Aufgaben. Für Textual content-to-SQL verwendet das Group den Spider-Benchmark. Spider enthält mehr als 10.000 Fragen in 200 Datenbanken, die 138 Bereiche umfassen. Das Richtlinienmodell ist Llama 3.2 3B Instruct. Die Implementierung verwendet LangChain mit einem Author-Agenten, einem Rewriter-Agenten und einem Checker. Der Author und der Rewriter werden optimiert und der Checker bleibt unverändert. Die Belohnungen verbessern sich während des Trainings und zur Prüfungszeit stetig.
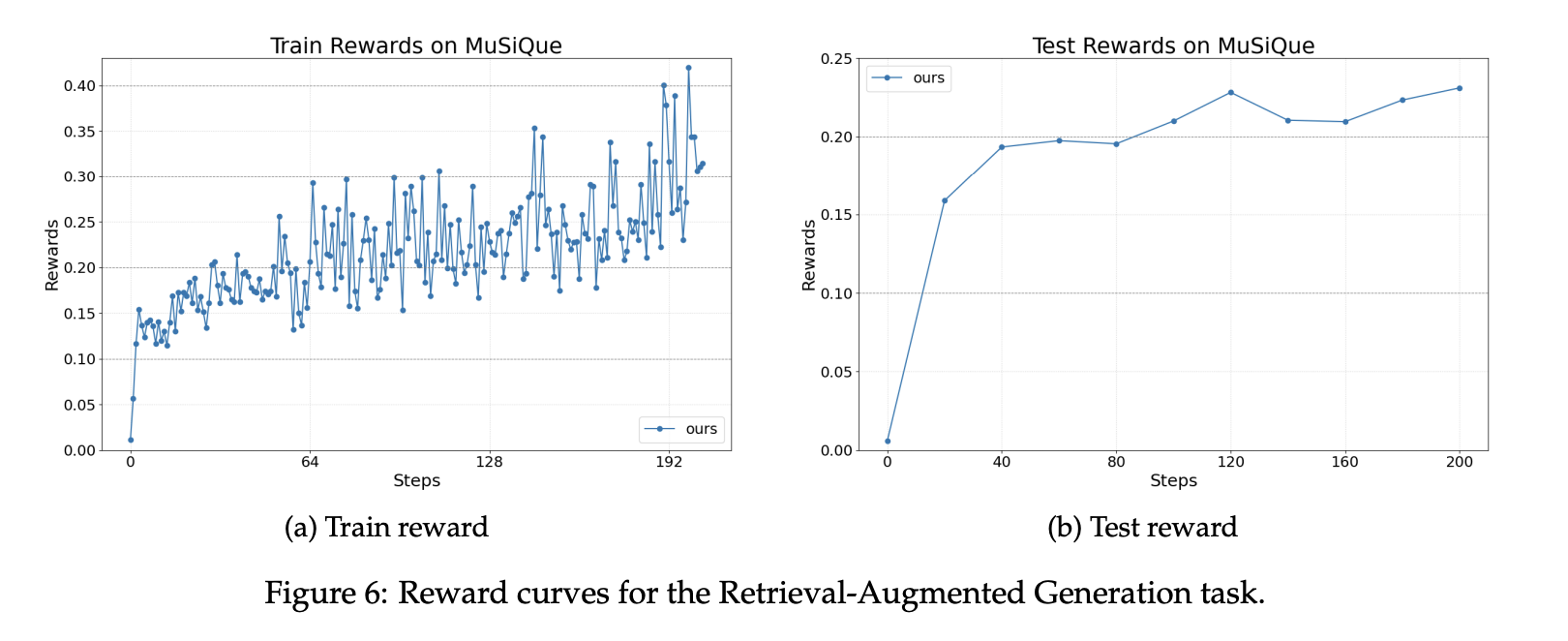
Für die Retrieval-Augmented-Generierung verwendet das Setup den MuSiQue-Benchmark und einen Wikipedia-Skalenindex mit etwa 21 Millionen Dokumenten. Der Retriever verwendet BGE-Einbettungen mit Kosinusähnlichkeit. Der Agent wird mit dem OpenAI Brokers SDK erstellt. Die Belohnung ist eine gewichtete Summe aus einem Format-Rating und einem F1-Korrektheits-Rating. Belohnungskurven zeigen stabile Zuwächse während des Trainings und der Bewertung mit demselben Basismodell.
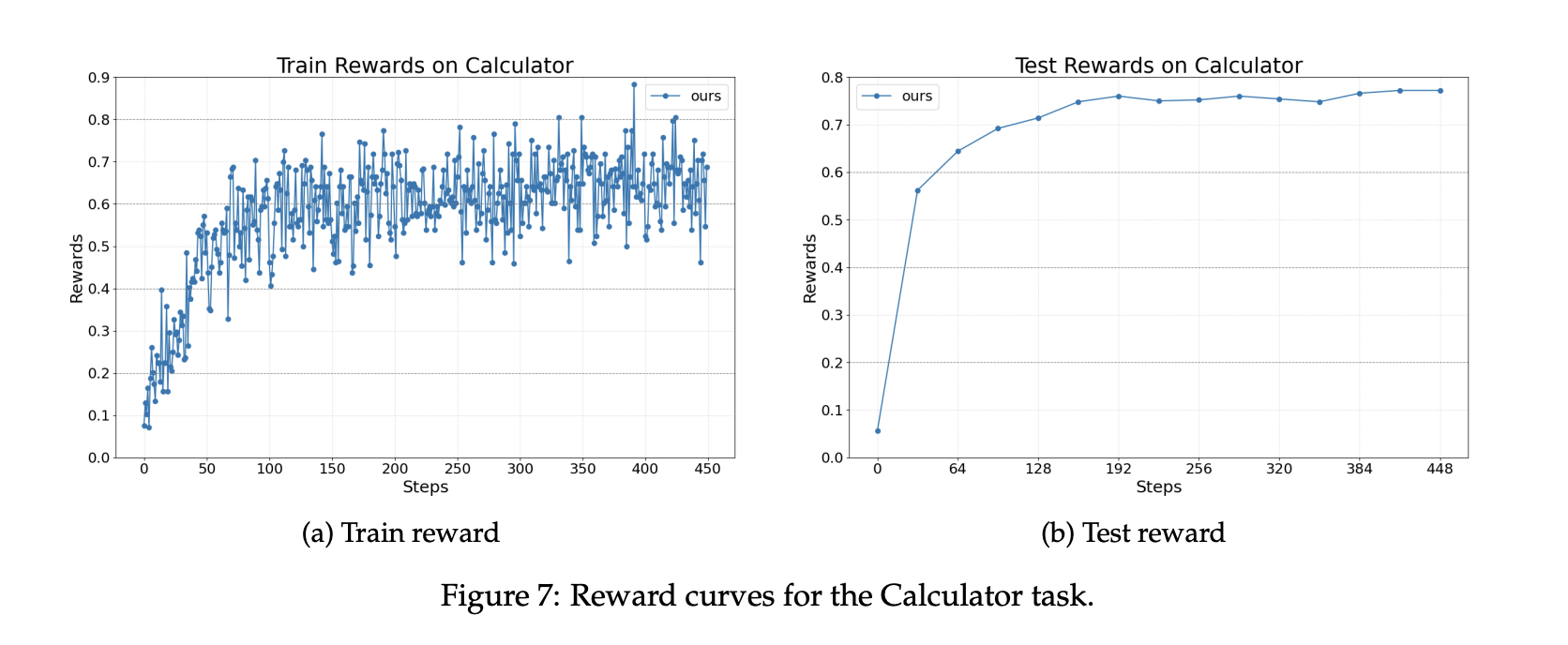
Für die Beantwortung mathematischer Fragen mithilfe eines Instruments wird der Agent mit AutoGen implementiert und ruft ein Taschenrechnertool auf. Der Datensatz ist Calc X. Das Basismodell ist wiederum Llama 3.2 3B Instruct. Das Coaching verbessert die Fähigkeit, Instruments korrekt aufzurufen und Ergebnisse in endgültige Antworten zu integrieren.
Wichtige Erkenntnisse
- Agent Lightning nutzt Coaching Agent Disaggregation und eine einheitliche Hint-Schnittstelle, sodass bestehende Agenten in LangChain, OpenAI Brokers SDK, AutoGen oder CrewAI nahezu ohne Codeänderungen verbunden werden können.
- LightningRL wandelt Flugbahnen in Übergänge um. Es wendet die Kreditzuweisung auf mehrstufige Läufe an und optimiert dann die Richtlinie mit Single-Flip-RL-Methoden wie PPO oder GRPO in Standardtrainern.
- Automated Intermediate Rewarding, AIR, liefert dichtes Suggestions. AIR wandelt Systemsignale wie den Standing der Werkzeugrückgabe in Zwischenbelohnungen um, um Probleme mit spärlichen Belohnungen in langen Arbeitsabläufen zu reduzieren.
- Die Forschung wertet Textual content nach SQL auf Spider, RAG auf MuSiQue mit einem Wikipedia-Skalenindex unter Verwendung von BGE-Einbettungen und Kosinusähnlichkeit sowie die Verwendung von Mathematiktools auf Calc X aus, alles mit Llama 3.2 3B Instruct als Basismodell.
- Die Laufzeit zeichnet Traces über OpenTelemetry auf, streamt sie an den Trainingsserver und stellt einen OpenAI-kompatiblen Endpunkt für aktualisierte Modelle bereit, wodurch skalierbare Rollouts ohne das Verschieben von Instruments ermöglicht werden.
Agent Lightning ist eine praktische Brücke zwischen der Agentenausführung und dem verstärkenden Lernen und nicht eine weitere Neufassung des Frameworks. Es formalisiert Agentenläufe als Markov-Entscheidungsprozess (MDP), führt LightningRL für die Kreditzuweisung ein und extrahiert Übergänge, die in Single-Flip-RL-Coach eingefügt werden. Das Coaching Agent Disaggregation-Design trennt einen Consumer, der den Agent ausführt, von einem Server, der einen OpenAI-kompatiblen Endpunkt trainiert und bedient, sodass Groups vorhandene Stacks behalten. Die automatische Zwischenbelohnung wandelt Laufzeitsignale in dichtes Suggestions um und reduziert so spärliche Belohnungen in langen Arbeitsabläufen. Insgesamt ist Agent Lightning ein sauberer Weg mit minimaler Integration, der es Agenten ermöglicht, aus ihren eigenen Spuren zu lernen.
Schauen Sie sich das an Papier Und Repo. Schauen Sie sich gerne bei uns um GitHub-Seite für Tutorials, Codes und Notebooks. Sie können uns auch gerne weiter folgen Twitter und vergessen Sie nicht, bei uns mitzumachen 100.000+ ML SubReddit und Abonnieren Unser E-newsletter. Warten! Bist du im Telegram? Jetzt können Sie uns auch per Telegram kontaktieren.

Michal Sutter ist ein Knowledge-Science-Experte mit einem Grasp of Science in Knowledge Science von der Universität Padua. Mit einer soliden Grundlage in statistischer Analyse, maschinellem Lernen und Datentechnik ist Michal hervorragend darin, komplexe Datensätze in umsetzbare Erkenntnisse umzuwandeln.