
Microsoft hat veröffentlicht Phi-4-Argumentation-Imaginative and prescient-15BA Offenes multimodales Argumentationsmodell mit 15 Milliarden Parametern Entwickelt für Bild- und Textaufgaben, die sowohl Wahrnehmung als auch selektives Denken erfordern. Es handelt sich um ein kompaktes Modell, das darauf ausgelegt ist, Argumentationsqualität, Recheneffizienz und Trainingsdatenanforderungen in Einklang zu bringen, mit besonderer Stärke in wissenschaftliches und mathematisches Denken Und Verständnis von Benutzeroberflächen.

Worauf basiert das Modell?
Phi-4-reasoning-vision-15B kombiniert das Phi-4-Argumentation Sprachrückgrat mit dem SigLIP-2 Imaginative and prescient-Encoder mit einem Mid-Fusion-Architektur. In diesem Setup wandelt der Imaginative and prescient-Encoder zunächst Bilder in visuelle Token um, dann werden diese Token in den Einbettungsraum des Sprachmodells projiziert und vom vorab trainierten Sprachmodell verarbeitet. Dieses Design stellt einen praktischen Kompromiss dar: Es bewahrt ein starkes modalübergreifendes Denken und hält gleichzeitig die Trainings- und Inferenzkosten im Vergleich zu schwereren Designs für die frühe Fusion überschaubar.
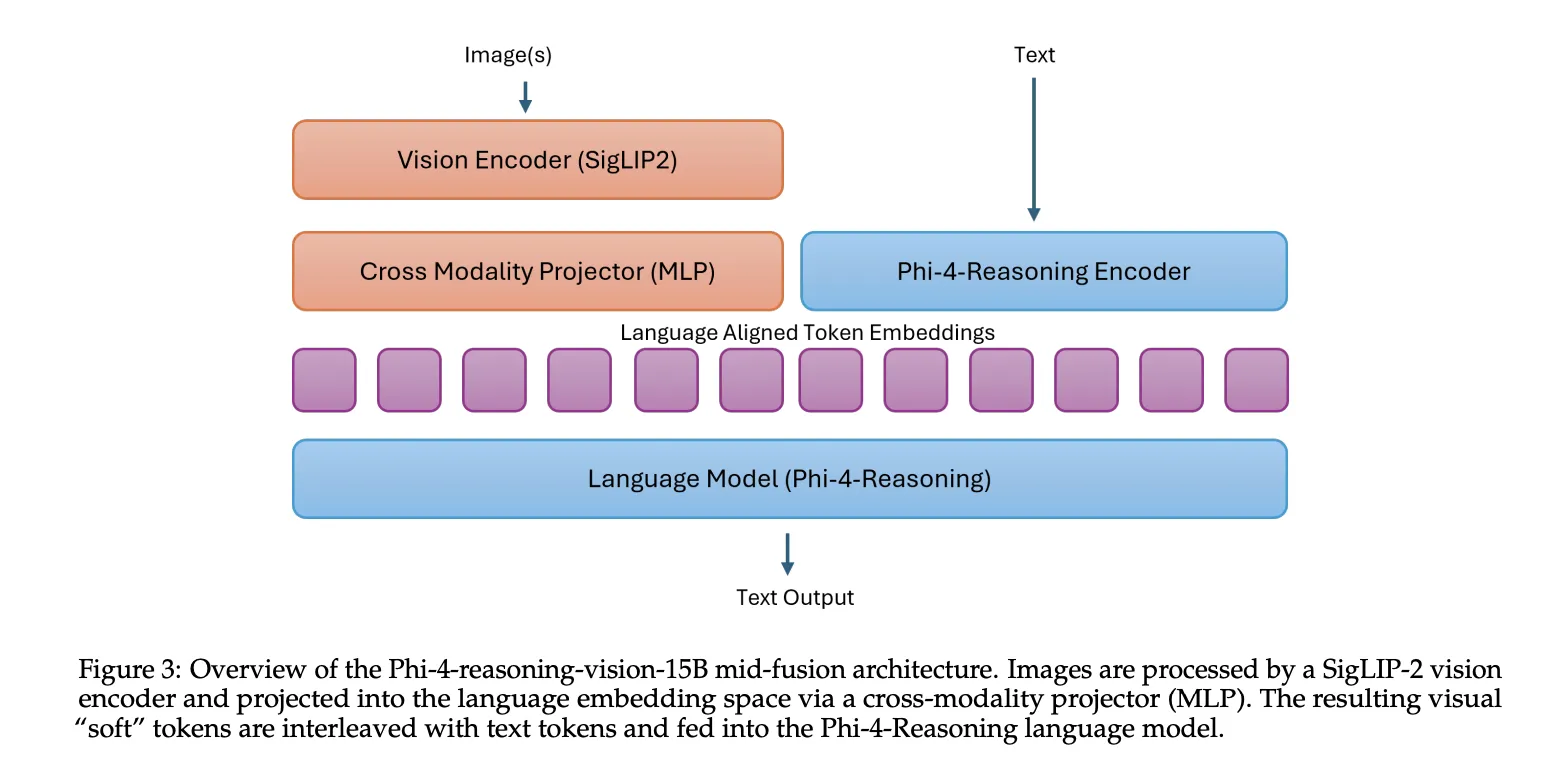
Warum Microsoft den Weg des kleineren Modells gewählt hat?
Bei vielen neueren Imaginative and prescient-Language-Modellen ist die Parameteranzahl und Token-Nutzung gestiegen, was sowohl die Latenz als auch die Bereitstellungskosten erhöht. Phi-4-reasoning-vision-15B wurde als kleinere Different entwickelt, die dennoch gängige multimodale Arbeitslasten bewältigt, ohne auf extrem große Trainingsdatensätze oder eine übermäßige Inferenzzeit-Token-Generierung angewiesen zu sein. Das Modell wurde trainiert 200 Milliarden multimodale Tokenaufbauend auf Phi-4-Argumentationauf dem trainiert wurde 16 Milliarden Tokenund letztendlich auf der Phi-4 Basismodell, auf dem trainiert wurde 400 Milliarden einzigartige Token. Microsoft stellt das dem gegenüber mehr als 1 Billion Token Wird zum Trainieren mehrerer neuerer multimodaler Modelle verwendet, z Qwen 2,5 VL, Qwen 3 VL, Kimi-VLUnd Gemma 3.
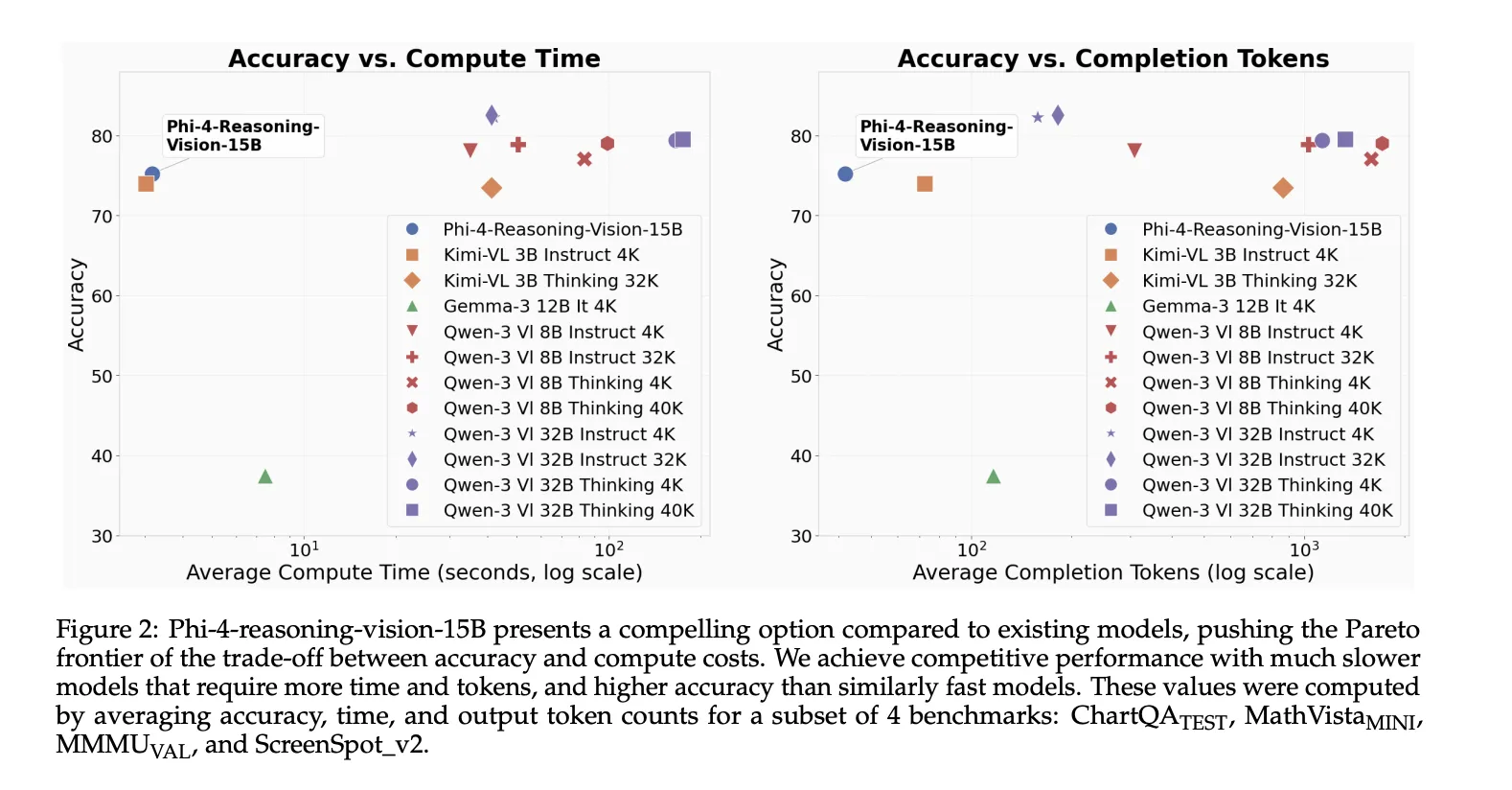
Die hochauflösende Wahrnehmung battle eine zentrale Designentscheidung
Das Microsoft-Crew erklärt in seinem technischen Bericht eine der nützlicheren technischen Lektionen, dass multimodales Denken oft scheitert, weil die Wahrnehmung zuerst scheitert. Modelle können die Antwort nicht finden, weil es ihnen an logischem Denken mangelt, sondern weil es ihnen nicht gelingt, die relevanten visuellen Particulars aus dichten Bildern wie Screenshots, Dokumenten oder Schnittstellen mit kleinen interaktiven Elementen zu extrahieren.
Phi-4-reasoning-vision-15B verwendet a Imaginative and prescient-Encoder mit dynamischer Auflösung und bis zu 3.600 visuellen Tokendas das hochauflösende Verständnis für Aufgaben wie unterstützen soll GUI-Erdung Und Feingranulare Dokumentenanalyse. Das gibt das Microsoft-Crew bekannt hochauflösende, dynamisch auflösende Encoder sorgen für kontinuierliche Verbesserungenund weist ausdrücklich darauf hin Eine genaue Wahrnehmung ist eine Voraussetzung für hochwertiges Denken.
Gemischte Argumentation statt überall erzwungenes Denken
Eine zweite wichtige Designentscheidung betrifft das Modell gemischte Trainingsstrategie für logisches Denken und nicht logisches Denken. Anstatt für alle Aufgaben eine Gedankenkette zu erzwingen, trainierte das Microsoft-Crew das Modell so, dass es zwischen zwei Modi wechselt. Argumentationsbeispiele umfassen <assume>...</assume> Spuren, während nicht begründete Proben beginnen <nothink> und werden für wahrnehmungsfokussierte Aufgaben wie z Untertitel, Erdung, OCR und einfache VQA. Die Argumentationsdaten bilden ca. 20 % der gesamten Trainingsmischung.
Das Ziel dieses Hybrid-Setups besteht darin, das Modell direkt auf Aufgaben reagieren zu lassen, bei denen längeres Denken die Latenz erhöht, ohne die Genauigkeit zu verbessern, und gleichzeitig strukturiertes Denken bei Aufgaben wie Mathematik und Naturwissenschaften aufzurufen. Das Microsoft-Crew weist außerdem auf eine wichtige Einschränkung hin: Die Grenze zwischen diesen Modi wird implizit erlernt, sodass der Wechsel nicht immer optimum ist. Benutzer können das Standardverhalten durch explizite Aufforderung mit außer Kraft setzen <assume> oder <nothink> Token.
Welche Bereiche sind stärker?
Das Microsoft-Crew hebt zwei Hauptanwendungsbereiche hervor. Das erste ist wissenschaftliches und mathematisches Denken über visuelle Eingabeneinschließlich handschriftlicher Gleichungen, Diagramme, Diagramme, Tabellen und quantitativer Dokumente. Das zweite ist Laptop-Use-Agent-Aufgabenwobei das Modell Bildschirminhalte interpretiert, GUI-Elemente lokalisiert und die Interaktion mit Desktop-, Internet- oder Mobilschnittstellen unterstützt.
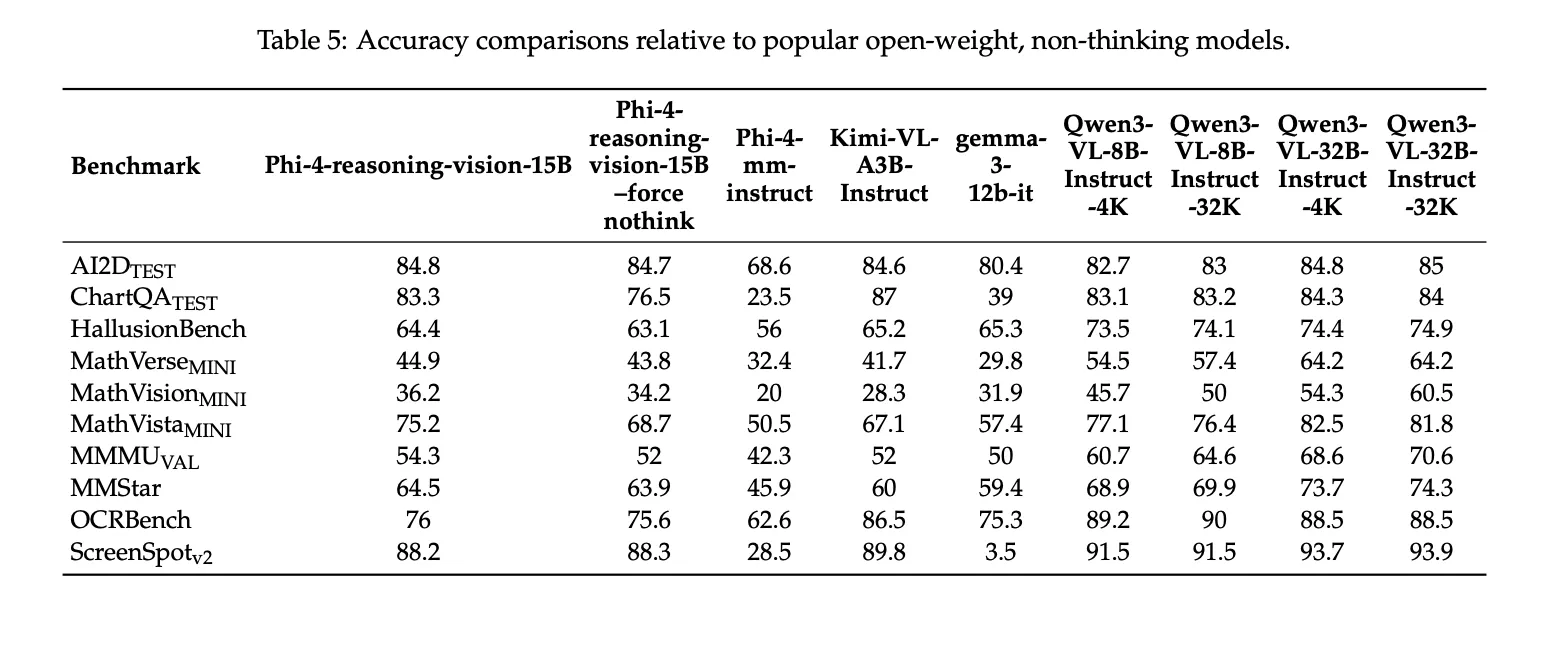
Benchmark-Ergebnisse
Das Microsoft-Crew meldet die folgenden Benchmark-Ergebnisse für Phi-4-reasoning-vision-15B: 84,8 auf AI2DTEST, 83,3 auf ChartQATEST, 44,9 auf MathVerseMINI, 36.2 auf MathVisionMINI, 75,2 auf MathVistaMINI, 54,3 auf MMMUVAL, 64,5 auf MMStar, 76,0 auf OCRBenchUnd 88,2 auf ScreenSpotv2. Im technischen Bericht wird außerdem darauf hingewiesen, dass diese Ergebnisse mit generiert wurden Eureka ML-Einblicke Und VLMEvalKitmit festen Bewertungseinstellungen, und das Microsoft-Crew präsentiert sie als Vergleichsergebnisse und nicht als Bestenlistenansprüche.
Wichtige Erkenntnisse
- Phi-4-reasoning-vision-15B ist ein 15B offenes multimodales Modell durch Kombinieren aufgebaut Phi-4-Argumentation mit dem SigLIP-2 Imaginative and prescient-Encoder in einem Mid-Fusion-Architektur.
- Das Microsoft-Crew hat das Modell für kompaktes multimodales Denken entwickeltmit Schwerpunkt auf Mathematik, Naturwissenschaften, Dokumentenverständnis und GUI-Grundlagenanstatt auf eine viel größere Parameteranzahl zu skalieren.
- Die hochauflösende visuelle Wahrnehmung ist ein zentraler Bestandteil des Methodsmit Unterstützung für dynamische Auflösungskodierung und bis zu 3.600 visuelle Tokenwas bei dichten Screenshots, Dokumenten und schnittstellenintensiven Aufgaben hilfreich ist.
- Das Modell verwendet gemischtes Denken und Coaching ohne Denkensodass zwischen diesen umgeschaltet werden kann
<assume>Und<nothink>Modi abhängig davon, ob eine Aufgabe eine explizite Begründung oder eine direkte wahrnehmungsbasierte Ausgabe erfordert. - Die von Microsoft gemeldeten Benchmarks zeigen für seine Größe eine starke Leistungeinschließlich Ergebnisse zu AI2DTEST, ChartQATEST, MathVistaMINI, OCRBench und ScreenSpotv2was seine Positionierung als kompaktes, aber leistungsfähiges Imaginative and prescient-Language-Argumentationsmodell unterstützt.
Schauen Sie sich das an Papier, Repo Und Modellgewichte. Sie können uns auch gerne weiter folgen Twitter und vergessen Sie nicht, bei uns mitzumachen 120.000+ ML SubReddit und Abonnieren Unser Publication. Warten! Bist du im Telegram? Jetzt können Sie uns auch per Telegram kontaktieren.