Nvidia hat die Nemotron-Nano 2-Familie vorgestellt und eine Linie von hybriden Mamba-Transformator-Großsprachenmodellen (LLMs) eingeführt, die nicht nur hochmoderne Argumentationsgenauigkeit, sondern auch einen Durchsatz von bis zu 6 × höherer Inferenz liefern als Modelle ähnlicher Größe. Diese Veröffentlichung fällt mit beispielloser Transparenz in Daten und Methodik ab, da Nvidia neben Modellkontrollpunkten für die Neighborhood den größten Teil des Trainingskorpus und Rezepte bereitstellt. Kritischerweise halten diese Modelle eine large 128-km-Kontext-Fähigkeit bei einer einzelnen Midrange-GPU bei, wodurch die Hindernisse für das Langzeit-Argumentieren und die Bereitstellung realer Welt erheblich verringert werden.
Schlüsselhighlights
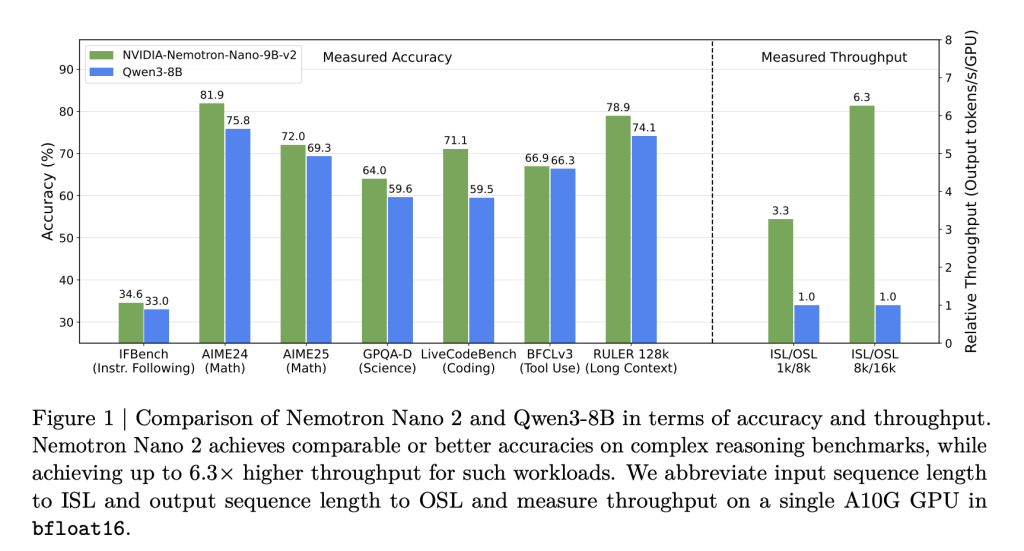
- 6 × Durchsatz im Vergleich zu Modellen in ähnlicher Größe: Nemotron-Nano-2-Modelle liefern bis zu 6,3 × die Geschwindigkeit der Token-Technology von Modellen wie Qwen3-8b in argumentationsstörenden Szenarien-ohne die Genauigkeit der Opferung.
- Überlegene Genauigkeit für Argumentation, Codierung und mehrsprachige Aufgaben: Benchmarks zeigen On-Par- oder bessere Ergebnisse im Vergleich zu wettbewerbsfähigen offenen Modellen, die Friends in Mathematik-, Code-, Instruments-Gebrauchs- und langkontextübergreifenden Aufgaben insbesondere übertreffen.
- 128k Kontextlänge auf einer einzelnen GPU: Effizientes Beschneiden und Hybridarchitektur ermöglichen es, 128.000 Token -Inferenz für eine einzelne NVIDIA A10G -GPU (22GIB) zu betreiben.
- Öffnen Sie Daten und Gewichte: Die meisten Datensätze für Vorab- und Nachtraining, einschließlich Code, Mathematik, mehrsprachiger, synthetischer SFT und Argumentationsdaten, werden mit zulässiger Lizenzierung auf dem Umarmungsgesicht veröffentlicht.
Hybridarchitektur: Mamba trifft Transformator
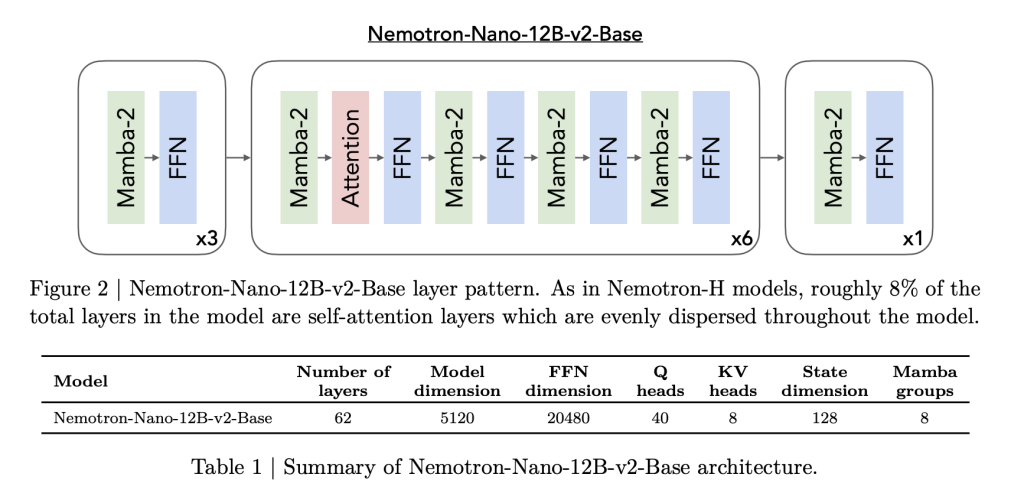
Nemotron Nano 2 basiert auf einem Hybrid-Mamba-Transformator-Rückgrat, das von der Nemotron-H-Architektur inspiriert ist. Die meisten traditionellen Selbstbekämpfungsschichten werden durch effiziente MAMBA-2-Schichten ersetzt, wobei nur etwa 8% der Gesamtschichten Selbstbekämpfung unterliegen. Diese Architektur wird sorgfältig gefertigt:
- Modelldetails: Das 9B-Parameter-Modell verfügt über 56 Schichten (aus einem vorgebliebenen 62), einer versteckten Größe von 4480 mit Aufmerksamkeit mit Gruppiergraden und Raumschichten von Mamba-2-Staaten, die sowohl Skalierbarkeit als auch lange Sequenzretention erleichtert.
- Mamba-2-Innovationen: Diese staatlichen Raumschichten, die kürzlich als Hochdurchsatz-Sequenzmodelle populär gemacht wurden, sind mit einer spärlichen Selbstbekämpfung (zur Erhaltung von Abhängigkeiten von Langstrecken) und großen Feed-Ahead-Netzwerken verschachtelt.
Diese Struktur ermöglicht einen hohen Durchsatz bei den Argumentationsaufgaben, die „Denkspuren“ erfordern-langwierige Generationen, die auf langen, kontextbezogenen Eingaben basieren-, bei denen herkömmliche transformatorbasierte Architekturen häufig verlangsamen oder das Gedächtnis verlassen.
Trainingsrezept: Large Datenvielfalt, Open Sourcing
Nemotron-Nano-2-Modelle werden aus einem 12B-Parameter-Lehrermodell unter Verwendung eines umfangreichen, hochwertigen Korpus geschult und destilliert. Die beispiellose Datentransparenz von Nvidia ist ein Spotlight:
- 20t Tokens Vorbereitung: Zu den Datenquellen gehören kuratierte und synthetische Korpora für Net-, Mathematik-, Code-, mehrsprachige, akademische und STEM -Domänen.
- Hauptdatensätze veröffentlicht:
- Nemotron-CC-V2: Mehrsprachiger Webcrawl (15 Sprachen), synthetische Q & A -Reformierung, Deduplizierung.
- Nemotron-cc-Math: 133B -Token von Mathematikinhalten, standardisiert auf Latex, über 52B „höchste Qualität“ -Subset.
- Nemotron-Pretraining-Code: Kuratierter und qualitativ hochwertiger Github-Quellcode; strenge Dekontamination und Deduplizierung.
- Nemotron-Pretraining-Sft: Synthetische, Anweisungsverfolgungsdatensätze in den Bereichen STEM, Argumentation und allgemeine Bereiche.
- Daten nach der Ausbildung: Beinhaltet über 80B-Token von beaufsichtigten Feinabstimmungen (SFT), RLHF, Werkzeuganhänger und mehrsprachige Datensätze, von denen die meisten zur direkten Reproduzierbarkeit offen sind.
Ausrichtung, Destillation und Komprimierung: Kosten effektive, lang Kontext-Argumentation freischalten
Der Modellkomprimierungsprozess von NVIDIA basiert auf den Frameworks „Minitron“ und Mamba -Schnitt:
- Wissensdestillation Aus dem 12B -Lehrer reduziert der Modell das Modell auf 9B -Parameter, wobei die Schichten, die FFN -Abmessungen und die Einbettungsbreite sorgfältig beschnitten werden.
- Mehrstufiger SFT und RL: Beinhaltet die Optimierung der Software-Calling-Optimierung (BFCL V3), Anweisungen (IFEVAL), DPO- und GRPO-Verstärkung sowie „Denkbudget“ -Kontrolle (Unterstützung für kontrollierbare Argumentationsbudgets bei Inferenz).
- Reminiscence-Focused NAS: Durch die Architektursuche sind die beschnittenen Modelle spezifisch so konstruiert, dass das Modell und der Schlüsselwertcache in der A10G-GPU-Speicher mit einer Kontextlänge von 128 km belegen-und bleiben-.
Das Ergebnis: Inferenzgeschwindigkeiten von bis zu 6 × schneller als offene Konkurrenten in Szenarien mit großen Eingangs-/Ausgangs -Token ohne kompromittierte Aufgabengenauigkeit.
Benchmarking: Überlegene Argumentation und mehrsprachige Fähigkeiten
In Kopf-an-Kopf-Bewertungen Excel: Nemotron Nano 2-Modelle:
| Aufgabe/Financial institution | Nemotron-Nano-9b-V2 | Qwen3-8b | Gemma3-12b |
|---|---|---|---|
| Mmlu (allgemein) | 74,5 | 76,4 | 73.6 |
| Mmlu-pro (5-shot) | 59.4 | 56,3 | 45.1 |
| GSM8K COT (Math) | 91.4 | 84.0 | 74,5 |
| MATHE | 80.5 | 55.4 | 42.4 |
| Humanerover+ | 58,5 | 57.6 | 36.7 |
| Herrscher-128K (langer Kontext) | 82.2 | – – | 80.7 |
| International-MMLU-Lite (AVG Multi) | 69.9 | 72,8 | 71,9 |
| MGSM Mehrsprachige Mathematik (AVG) | 84,8 | 64,5 | 57.1 |
- Durchsatz (Token/S/GPU) bei 8K -Eingang/16K -Ausgabe:
- Nemotron-Nano-9b-V2: bis zu 6,3 × QWEN3-8b in Argumentationsspuren.
- Hält bis zu 128K-Kontext mit Stapelgröße = 1-im Midrange-GPUs.
Abschluss
Nvidia Nemotron Nano 2 Launch ist ein wichtiger Second für offene LLM-Forschung: Es definiert das, was für eine einzelne kostengünstige GPU möglich ist-sowohl in der Geschwindigkeit als auch in der Kontextkapazität-und erhöht die Balken für Datentransparenz und Reproduzierbarkeit. Seine Hybridarchitektur, die Vorherrschaft der Durchsatz und die hochwertigen offenen Datensätze werden in die Innovation im gesamten AI-Ökosystem beschleunigt.
Schauen Sie sich das an Technische ParticularsAnwesend Papier Und Fashions auf dem Umarmung des Gesichts. Fühlen Sie sich frei, unsere zu überprüfen Github -Seite für Tutorials, Codes und Notizbücher. Fühlen Sie sich auch frei, uns zu folgen Twitter Und vergessen Sie nicht, sich unserer anzuschließen 100k+ ml Subreddit und abonnieren Unser E-newsletter.
Asif Razzaq ist der CEO von Marktechpost Media Inc. Sein jüngstes Bestreben ist die Einführung einer Medienplattform für künstliche Intelligenz, Marktechpost, die sich durch die ausführliche Berichterstattung über maschinelles Lernen und Deep-Studying-Nachrichten auszeichnet, die von einem breiten Publikum technisch intestine und leicht verständlich sind. Die Plattform verfügt über über 2 Millionen monatliche Ansichten und veranschaulicht ihre Beliebtheit des Publikums.