
NVIDIA hat die Veröffentlichung von angekündigt Nemotron-Kaskade 2ein offenes Gewicht 30B Combination-of-Consultants (MoE) Modell mit 3B aktivierte Parameter. Das Modell konzentriert sich auf die Maximierung der „Intelligenzdichte“ und bietet erweiterte Denkfähigkeiten auf einem Bruchteil der Parameterskala, die von Grenzmodellen verwendet wird. Nemotron-Cascade 2 ist das zweite Open-Weight-LLM, das erreicht wurde Leistung auf Goldmedaillen-Niveau bei der Internationalen Mathematikolympiade 2025 (IMO), der Internationalen Informatikolympiade (IOI) und den ICPC-Weltfinals.
Gezielte Leistung und strategische Kompromisse
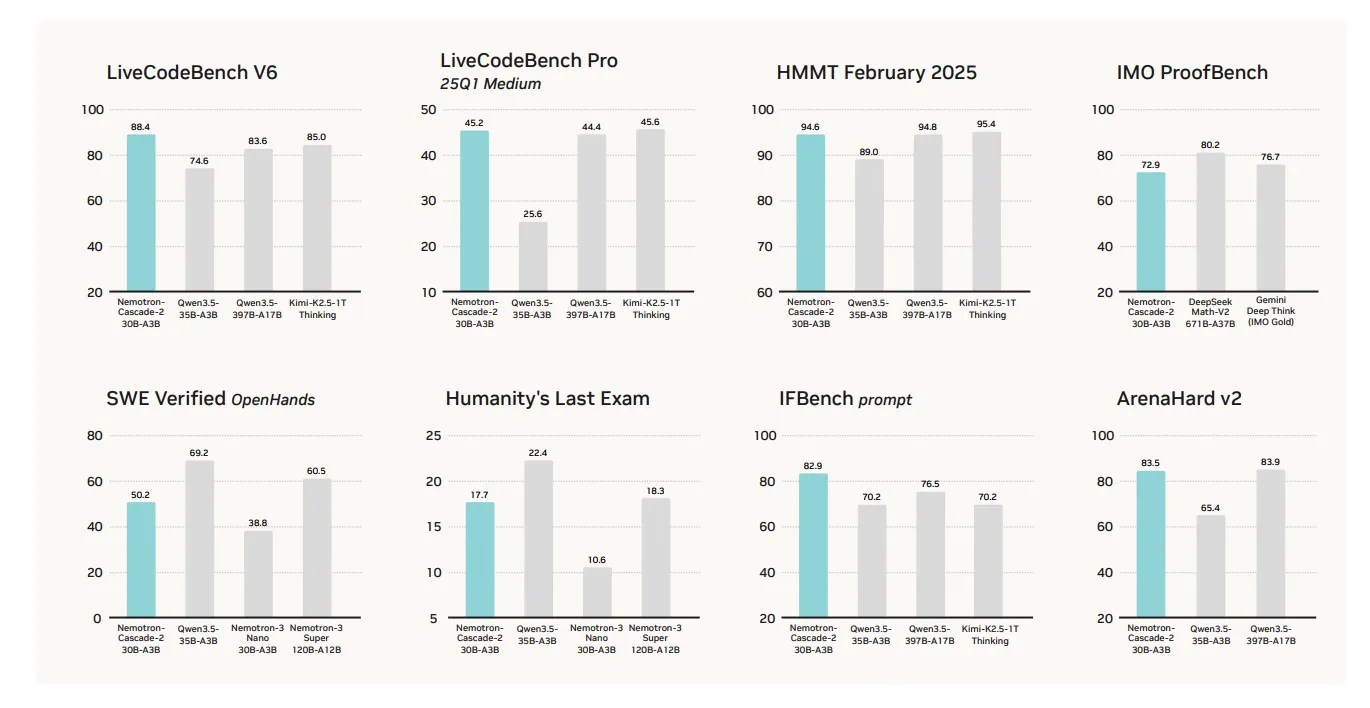
Das primäre Wertversprechen von Nemotron-Cascade 2 ist seine spezialisierte Leistung in den Bereichen mathematisches Denken, Kodierung, Ausrichtung und Befehlsbefolgung. Obwohl es in diesen Schlüsselbereichen, in denen es auf die Argumentation ankommt, Spitzenergebnisse erzielt, ist es sicherlich kein „pauschalen Sieg“ bei allen Benchmarks.
Die Leistung des Modells übertrifft in mehreren Zielkategorien die Leistung des kürzlich veröffentlichten Modells Qwen3.5-35B-A3B (Februar 2026) und die größere Nemotron-3-Tremendous-120B-A12B:
- Mathematische Argumentation: Übertrifft Qwen3.5-35B-A3B AIME 2025 (92,4 vs. 91,9) und HMMT 25. Februar (94,6 vs. 89,0).
- Codierung: Führt weiter LiveCodeBench v6 (87,2 vs. 74,6) und IOI 2025 (439,28 vs. 348,6+).
- Ausrichtung und Anleitung: Punkte deutlich höher ArenaHard v2 (83,5 vs. 65,4+) und IFBench (82,9 vs. 70,2).
Technische Architektur: Cascade RL und Multi-Area-On-Coverage-Destillation (MOPD)
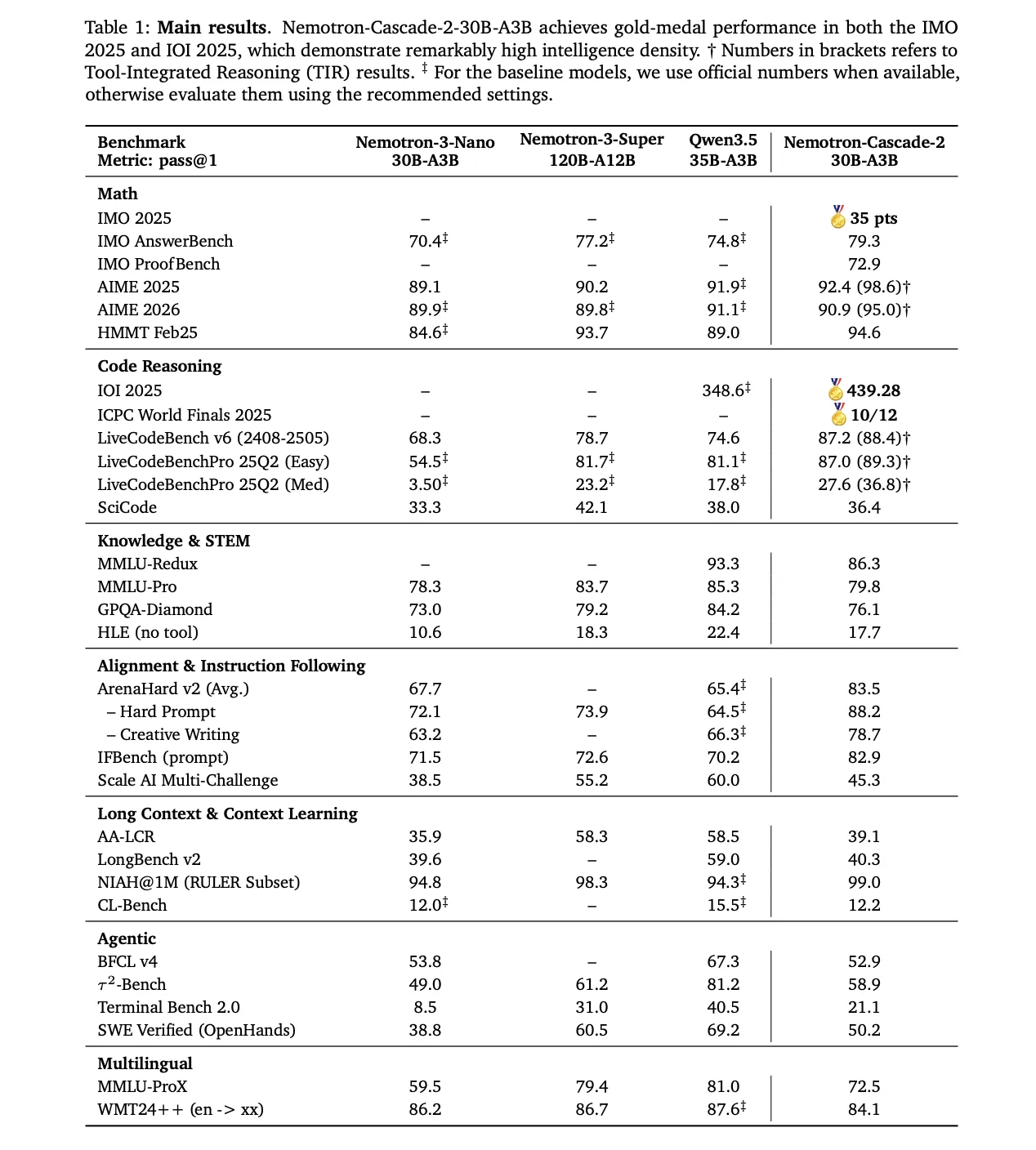
Die Argumentationsfähigkeiten des Modells stammen aus seiner Publish-Coaching-Pipeline, beginnend mit dem Nemotron-3-Nano-30B-A3B-Foundation Modell.
1. Überwachte Feinabstimmung (SFT)
Während der SFT nutzte das NVIDIA-Forschungsteam einen sorgfältig kuratierten Datensatz, in dem Proben in Sequenzen von bis zu gepackt wurden 256.000 Token. Der Datensatz umfasste:
- 1,9 Mio. Python-Argumentationsspuren und 1,3 Millionen Python-Toolaufrufbeispiele für wettbewerbsfähige Codierung.
- 816.000 Proben für mathematische Beweise in natürlicher Sprache.
- Ein Spezialist Mischung aus Software program Engineering (SWE). bestehend aus 125.000 agentenbasierten und 389.000 agentenlosen Proben.
2. Kaskadenverstärkendes Lernen
Im Anschluss an SFT wurde das Modell einer Prüfung unterzogen Kaskade RLdas sequentielles, domänenbezogenes Coaching anwendet. Dies verhindert katastrophales Vergessen, indem Hyperparameter auf bestimmte Domänen zugeschnitten werden können, ohne andere zu destabilisieren. Die Pipeline umfasst Stufen für Anweisungsfolge (IF-RL), Multi-Area-RL, RLHF, Lengthy-Context-RL sowie spezialisierten Code und SWE RL.
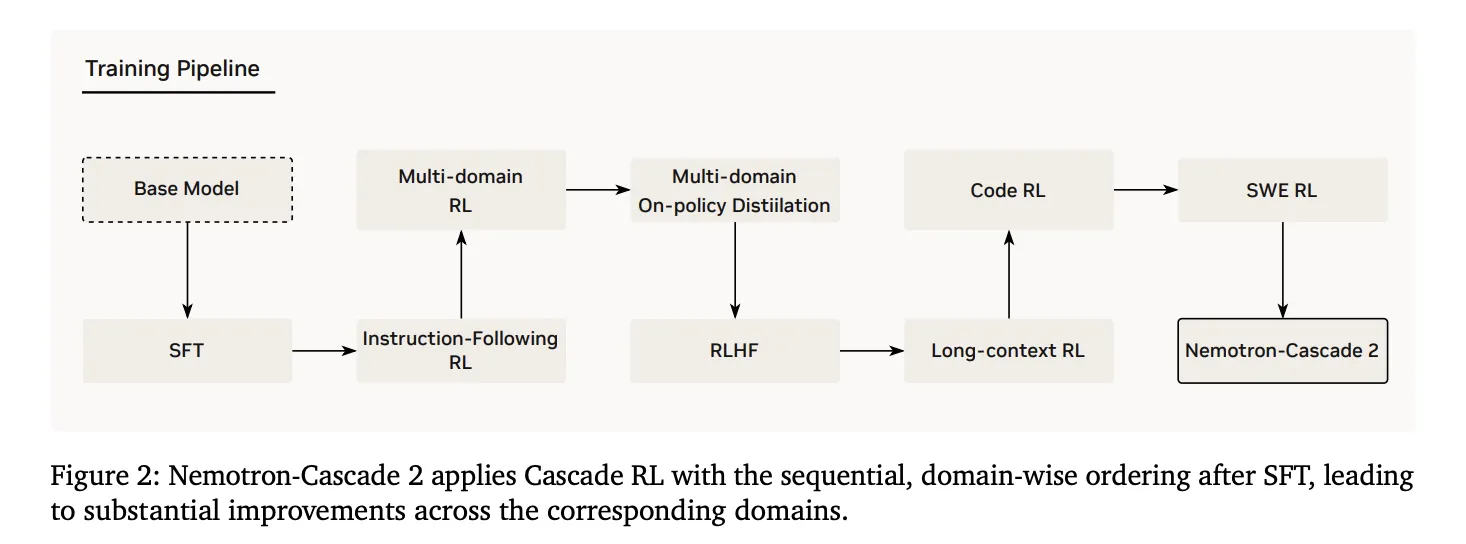
3. Multi-Area-On-Coverage-Destillation (MOPD)
Eine entscheidende Innovation in Nemotron-Cascade 2 ist die Integration von MOPD während des Cascade RL-Prozesses. Die MOPD-Meeting verwendet die leistungsstärksten „Lehrer“-Zwischenmodelle, die bereits aus derselben SFT-Initialisierung abgeleitet wurden, um einen Destillationsvorteil auf dichter Token-Ebene zu erzielen. Dieser Vorteil wird mathematisch definiert als:
$$a_{t}^{MOPD}=log~pi^{domain_{t}}(y_{t}|s_{t})-log~pi^{practice}(y_{t}|s_{t})$$
Das Forschungsteam stellte fest, dass MOPD wesentlich stichprobeneffizienter ist als vergleichbare Belohnungsalgorithmen auf Sequenzebene Gruppenrelative Richtlinienoptimierung (GRPO). Zum Beispiel am AIME25MOPD erreichte innerhalb von 30 Schritten eine Leistung auf Lehrerniveau (92,0), während GRPO nach Erreichen dieser Schritte nur 91,0 erreichte.
Inferenzfunktionen und Agenteninteraktion
Nemotron-Cascade 2 unterstützt über seine Chat-Vorlage zwei primäre Betriebsmodi:
- Denkmodus: Initiiert von einem Single
<suppose>Token, gefolgt von einer neuen Zeile. Dies aktiviert ein tiefes Denken für komplexe Mathematik- und Codeaufgaben. - Nicht-Denkmodus: Aktiviert durch Voranstellen eines Leerzeichens
<suppose></suppose>Block für effizientere, direktere Antworten.
Für Agentenaufgaben nutzt das Modell ein strukturiertes Device-Aufrufprotokoll innerhalb der Systemeingabeaufforderung. Die verfügbaren Instruments sind darin aufgeführt <instruments> Tags und das Modell wird angewiesen, darin eingeschlossene Werkzeugaufrufe auszuführen <tool_call> Tags, um ein überprüfbares Ausführungsfeedback zu gewährleisten.
Durch die Konzentration auf die „Intelligenzdichte“ zeigt Nemotron-Cascade 2, dass spezielle Denkfähigkeiten, die einst als ausschließliche Domäne von Modellen im Grenzmaßstab galten, durch domänenspezifisches Verstärkungslernen auf einer 30B-Skala erreichbar sind.
Kasse Papier Und Modell auf HF. Sie können uns auch gerne weiter folgen Twitter und vergessen Sie nicht, bei uns mitzumachen 120.000+ ML SubReddit und Abonnieren Unser Publication. Warten! Bist du im Telegram? Jetzt können Sie uns auch per Telegram kontaktieren.